Meta’s Llama 4 models, namely Llama 4 Maverick and Llama 4 Scout, represent a leap forward in multimodal AI technology. Released on April 5, 2025, these models leverage a Mixture-of-Experts (MoE) architecture, enabling efficient processing of text and images with remarkable performance-to-cost ratios. Developers can harness these capabilities through APIs provided by various platforms, making integration into applications seamless and powerful.
Understanding Llama 4 Maverick and Llama 4 Scout
Before diving into the API usage, grasp the core specifications of these models. Llama 4 introduces native multimodality, meaning it processes text and images together from the ground up. Additionally, its MoE design activates only a subset of parameters per task, boosting efficiency.
Llama 4 Scout: The Efficient Multimodal Workhorse
- Parameters: 17 billion active, 109 billion total, 16 experts.
- Context Window: Up to 10 million tokens.
- Key Features: Excels in long-context tasks like multi-document summarization and reasoning over large codebases. It fits on a single NVIDIA H100 GPU with INT4 quantization.
- Use Case: Ideal for developers needing fast, resource-efficient multimodal processing.
Llama 4 Maverick: The Versatile Powerhouse
- Parameters: 17 billion active, 400 billion total, 128 experts.
- Context Window: Up to 1 million tokens.
- Key Features: Offers high-quality text and image understanding, supporting 12 languages (e.g., English, Spanish, Hindi). It’s optimized for chat and creative writing.
- Use Case: Suited for enterprise-grade assistants and multilingual applications.
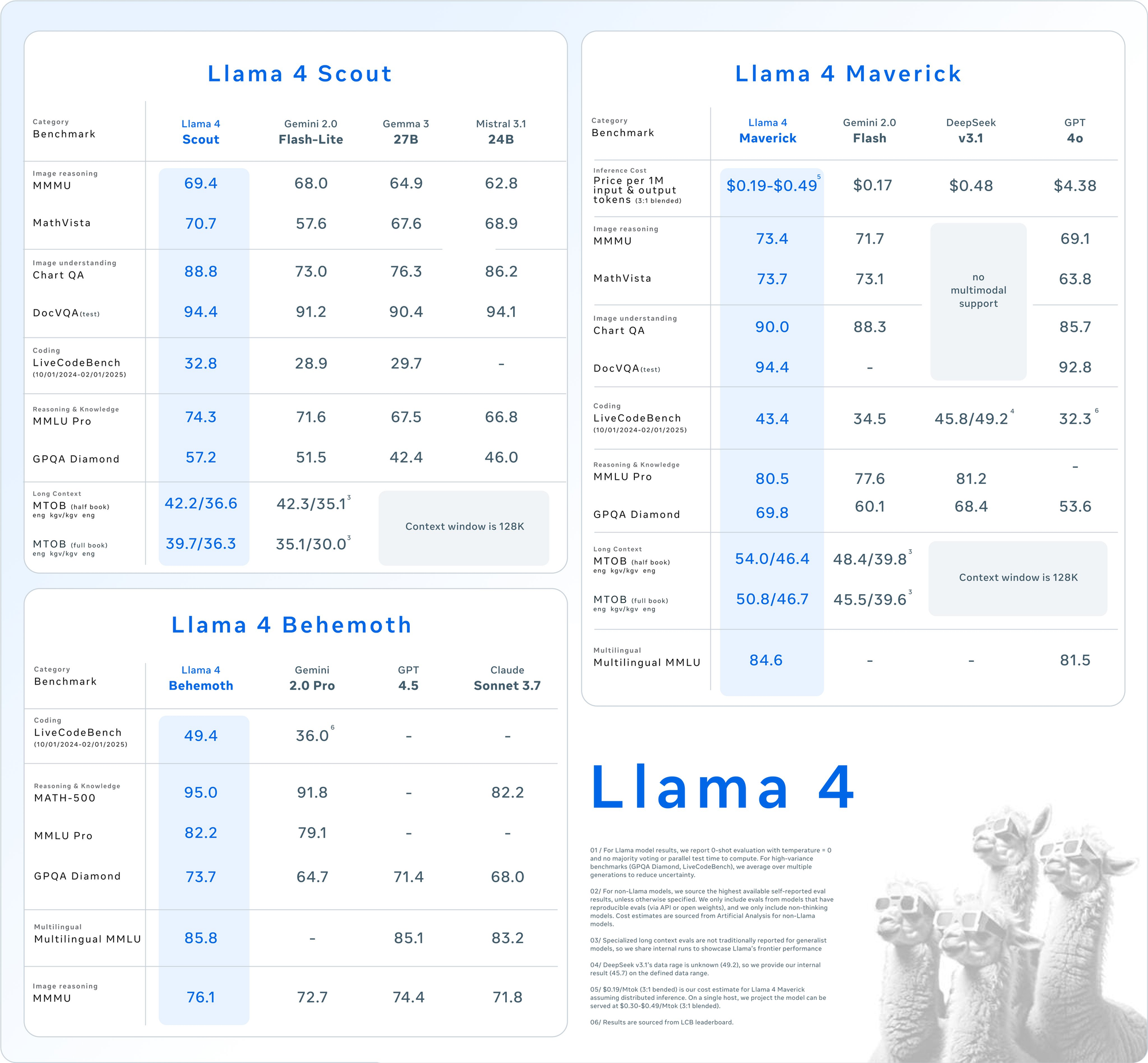
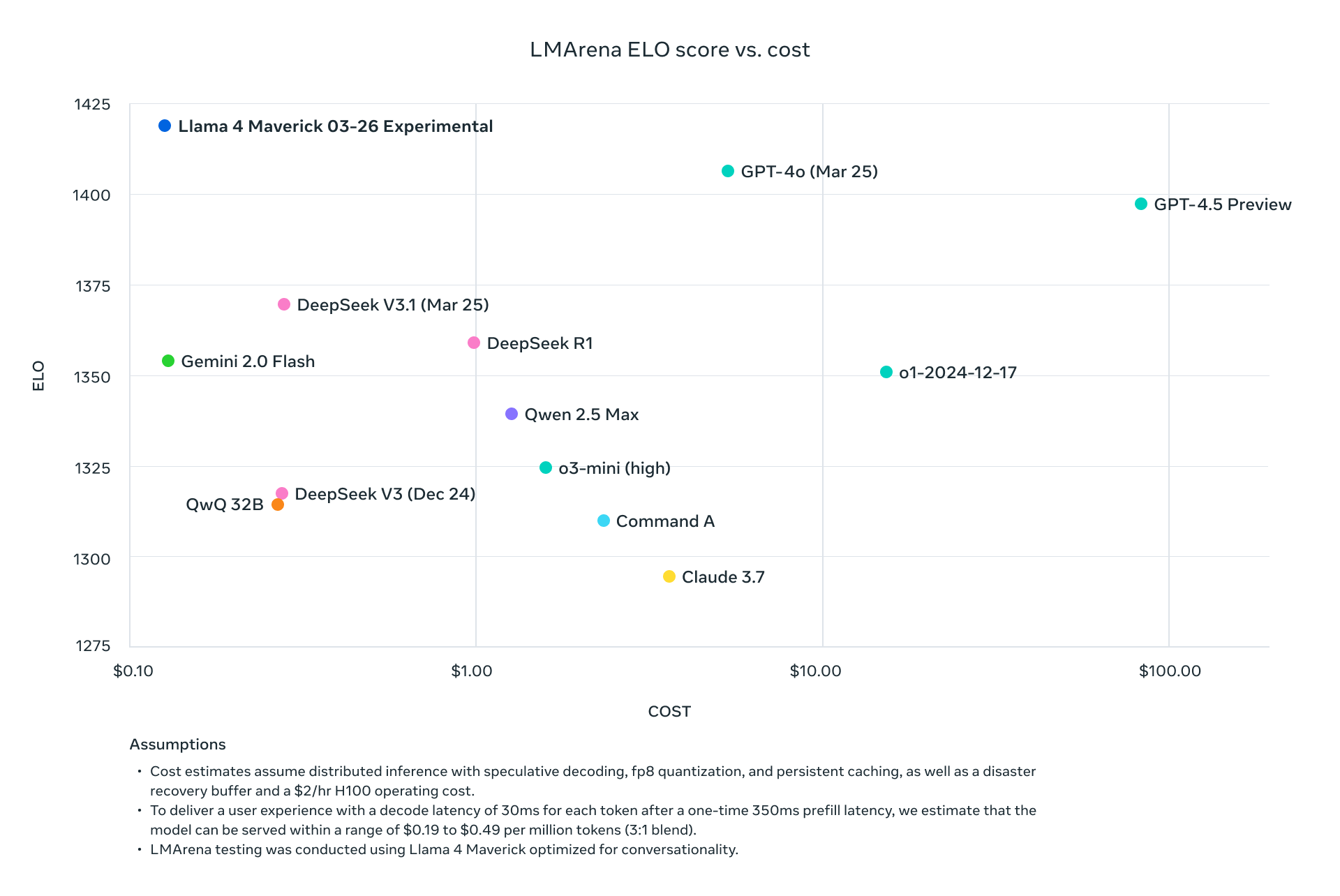
Both models outperform predecessors like Llama 3 and compete with industry giants like GPT-4o, making them compelling choices for API-driven projects.
Why Use the Llama 4 API?
Integrating Llama 4 via API eliminates the need to host these massive models locally, which often requires significant hardware (e.g., NVIDIA H100 DGX for Maverick). Instead, platforms like Groq, Together AI, and OpenRouter provide managed APIs, offering:
- Scalability: Handle varying loads without infrastructure overhead.
- Cost Efficiency: Pay per token, with rates as low as $0.11/M input tokens (Scout on Groq).
- Ease of Use: Access multimodal features with simple HTTP requests.
Next, let’s set up your environment to call these APIs.
Setting Up Your Environment for Llama 4 API Calls
To interact with Llama 4 Maverick and Llama 4 Scout via API, prepare your development environment. Follow these steps:
Step 1: Choose an API Provider
Several platforms host Llama 4 APIs. Here are popular options:
- Groq: Offers low-cost inference (Scout: $0.11/M input, Maverick: $0.50/M input).
- Together AI: Provides dedicated endpoints with custom scaling.
- OpenRouter: Free tier available, ideal for testing.
- Cloudflare Workers AI: Serverless deployment with Scout support.
For this guide, we’ll use Groq and Together AI as examples due to their robust documentation and performance.
Step 2: Obtain API Keys
- Groq: Sign up at groq.com, navigate to the Developer Console, and generate an API key.
- Together AI: Register at together.ai, then access your API key from the dashboard.
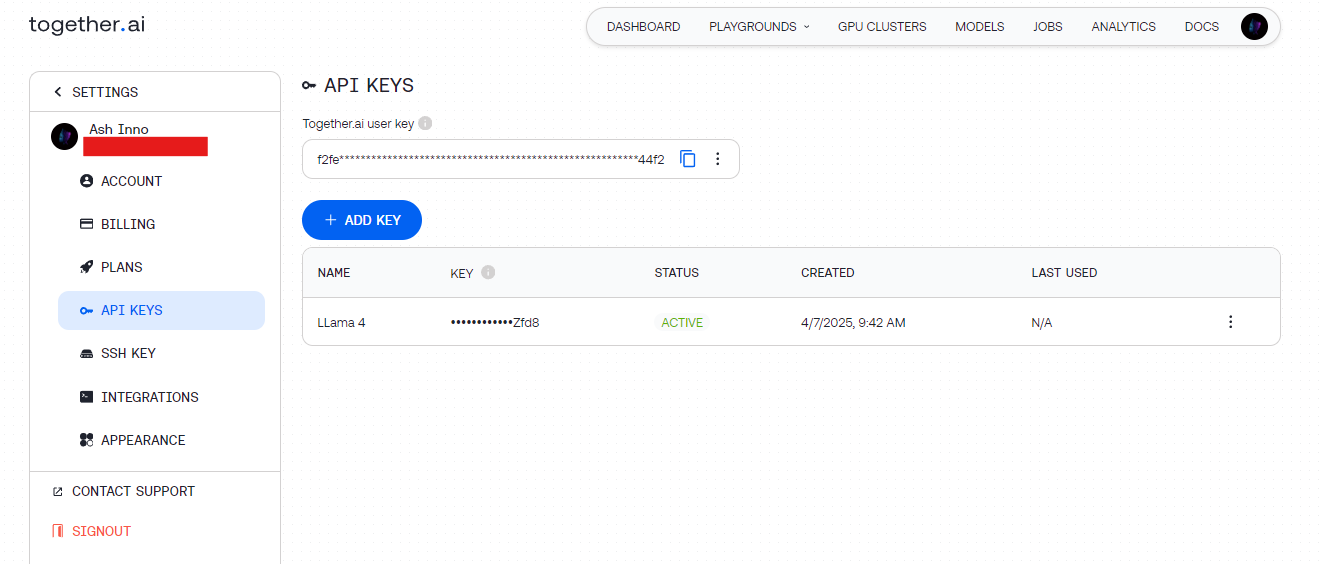
Store these keys securely (e.g., in environment variables) to avoid hardcoding them.
Step 3: Install Dependencies
Use Python for simplicity. Install the required libraries:
pip install requests
For testing, Apidog complements this setup by letting you visually debug API endpoints.
Making Your First Llama 4 API Call
With your environment ready, send a request to the Llama 4 API. Let’s start with a basic text generation example.
Example 1: Text Generation with Llama 4 Scout (Groq)
import requests
import os
# Set API key
API_KEY = os.getenv("GROQ_API_KEY")
URL = "https://api.groq.com/v1/chat/completions"
# Define payload
payload = {
"model": "meta-llama/Llama-4-Scout-17B-16E-Instruct",
"messages": [
{"role": "user", "content": "Write a short poem about AI."}
],
"max_tokens": 150,
"temperature": 0.7
}
# Set headers
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
# Send request
response = requests.post(URL, json=payload, headers=headers)
print(response.json()["choices"][0]["message"]["content"])
Output: A concise poem generated by Scout, leveraging its efficient MoE architecture.
Example 2: Multimodal Input with Llama 4 Maverick (Together AI)
Maverick shines in multimodal tasks. Here’s how to describe an image:
import requests
import os
# Set API key
API_KEY = os.getenv("TOGETHER_API_KEY")
URL = "https://api.together.ai/v1/chat/completions"
# Define payload with image and text
payload = {
"model": "meta-llama/Llama-4-Maverick-17B-128E-Instruct-FP8",
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {"url": "https://example.com/sample.jpg"}
},
{
"type": "text",
"text": "Describe this image."
}
]
}
],
"max_tokens": 200
}
# Set headers
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
# Send request
response = requests.post(URL, json=payload, headers=headers)
print(response.json()["choices"][0]["message"]["content"])
Output: A detailed description of the image, showcasing Maverick’s image-text alignment.
Optimizing API Requests for Performance
To maximize efficiency, tweak your Llama 4 API calls. Consider these techniques:
Adjust Context Length
- Scout: Use its 10M token window for long documents. Set
max_model_len(if supported) to handle large inputs. - Maverick: Limit to 1M tokens for chat applications to balance speed and quality.
Fine-Tune Parameters
- Temperature: Lower (e.g., 0.5) for factual responses, higher (e.g., 1.0) for creativity.
- Max Tokens: Cap output length to avoid unnecessary computation.
Batch Processing
Send multiple prompts in one request (if the API supports it) to reduce latency. Check provider docs for batch endpoints.
Advanced Use Cases with Llama 4 API
Now, explore advanced integrations to unlock Llama 4’s full potential.
Use Case 1: Multilingual Chatbot
Maverick supports 12 languages. Build a customer support bot:
payload = {
"model": "meta-llama/Llama-4-Maverick-17B-128E-Instruct-FP8",
"messages": [
{"role": "user", "content": "Hola, ¿cómo puedo resetear mi contraseña?"}
],
"max_tokens": 100
}
response = requests.post(URL, json=payload, headers=headers)
print(response.json()["choices"][0]["message"]["content"])
Output: A Spanish response, leveraging Maverick’s multilingual fluency.
Use Case 2: Document Summarization with Scout
Scout’s 10M token window excels at summarizing large texts:
long_text = "..." # Insert a lengthy document here
payload = {
"model": "meta-llama/Llama-4-Scout-17B-16E-Instruct",
"messages": [
{"role": "user", "content": f"Summarize this: {long_text}"}
],
"max_tokens": 300
}
response = requests.post(URL, json=payload, headers=headers)
print(response.json()["choices"][0]["message"]["content"])
Output: A concise summary, processed efficiently by Scout.
Debugging and Testing with Apidog
Testing APIs can be tricky, especially with multimodal inputs. Here’s where Apidog shines:
- Visual Interface: Build and send requests without coding.
- Error Tracking: Identify issues like rate limits or malformed payloads.
- Mock Responses: Simulate Llama 4 outputs for frontend development.
To test the above examples in Apidog:
- Open Apidog and create a new request.
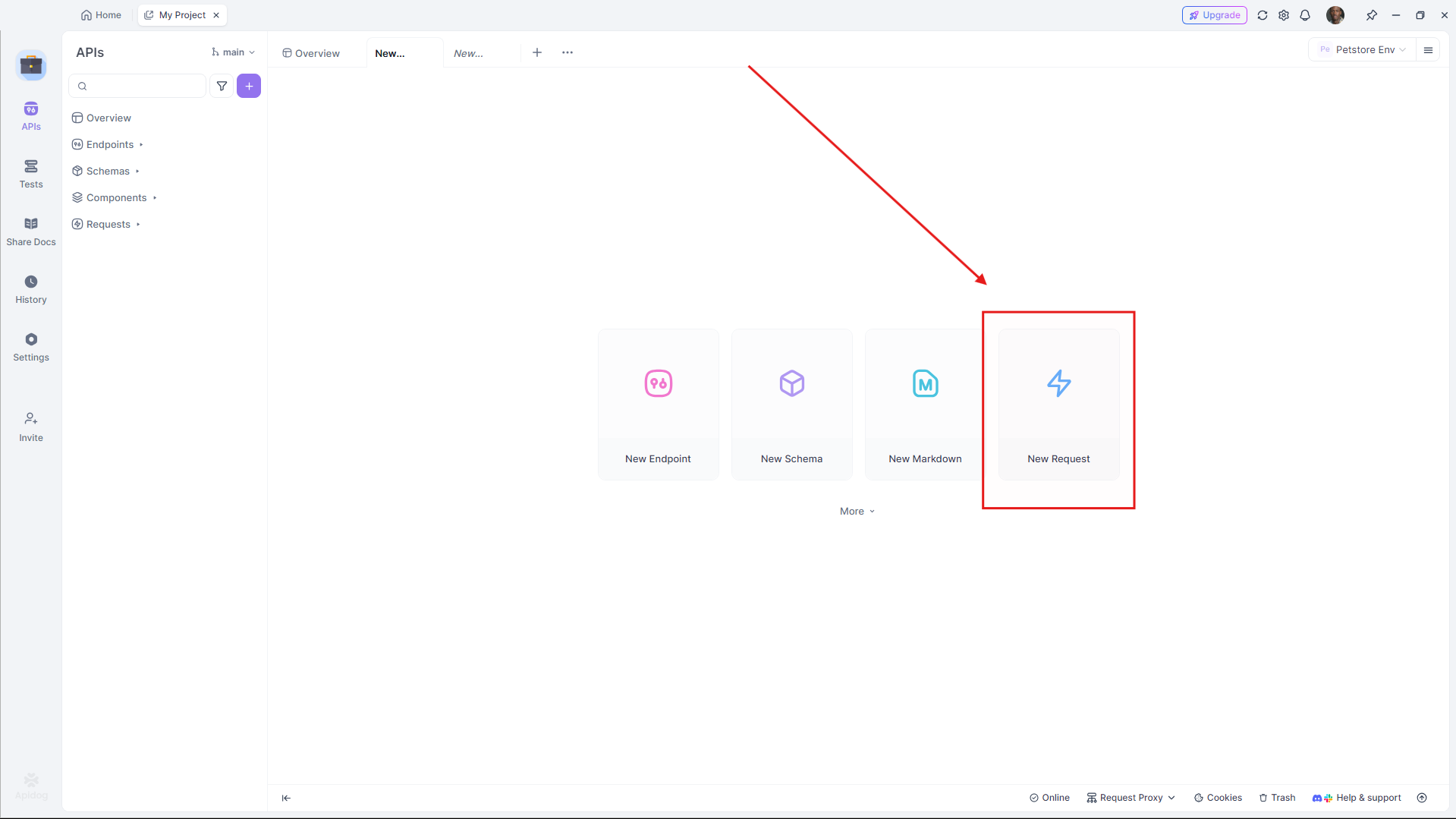
- Set the URL (e.g.,
https://api.groq.com/v1/chat/completions).

- Add headers (
Authorization,Content-Type).
- Paste the JSON payload.

- Send and review the response.

This workflow ensures your Llama 4 API integration runs smoothly.
Comparing API Providers for Llama 4
Choosing the right provider impacts cost and performance. Here’s a breakdown:
| Provider | Model Support | Pricing (Input/Output per M) | Context Limit | Notes |
|---|---|---|---|---|
| Groq | Scout, Maverick | $0.11/$0.34 (Scout), $0.50/$0.77 (Maverick) | 128K ( extensible) | Lowest cost, high speed |
| Together AI | Scout, Maverick | Custom (dedicated endpoints) | 1M (Maverick) | Scalable, enterprise-focused |
| OpenRouter | Both | Free tier available | 128K | Great for testing |
| Cloudflare | Scout | Usage-based | 131K | Serverless simplicity |
Select based on your project’s scale and budget. For prototyping, start with OpenRouter’s free tier, then scale with Groq or Together AI.
Best Practices for Llama 4 API Integration
To ensure robust integration, follow these guidelines:
- Rate Limiting: Respect provider limits (e.g., Groq’s 100 requests/minute). Implement exponential backoff for retries.
- Error Handling: Catch HTTP errors (e.g., 429 Too Many Requests) and log them.
- Security: Encrypt API keys and use HTTPS endpoints.
- Monitoring: Track token usage to manage costs, especially with Maverick’s higher rates.
Troubleshooting Common API Issues
Encounter problems? Address them quickly:
- 401 Unauthorized: Verify your API key.
- 429 Rate Limit Exceeded: Reduce request frequency or upgrade your plan.
- Payload Errors: Ensure JSON format matches provider specs (e.g.,
messagesarray).
Apidog helps diagnose these issues visually, saving time.
Conclusion
Integrating Llama 4 Maverick and Llama 4 Scout via API empowers developers to build cutting-edge applications with minimal overhead. Whether you need Scout’s long-context efficiency or Maverick’s multilingual prowess, these models deliver top-tier performance through accessible endpoints. By following this guide, you can set up, optimize, and troubleshoot your API calls effectively.
Ready to dive deeper? Experiment with providers like Groq and Together AI, and leverage Apidog to refine your workflow. The future of multimodal AI is here—start building today!