
Introduction
As data volumes continue to grow, one common approach in training machine learning models is batch training. This method involves splitting a dataset into smaller subsets or "batches," which are fed into the model one at a time.
In this post, we shall explore three different techniques for splitting datasets into batches:
- Creating a large tensor
- Loading partial data with HDF5
- Using Python generators
To illustrate, we will assume the model is a sound-based detector, but the methods discussed are broadly applicable. Although this example is specific, the core steps—splitting, preprocessing, and iterating over data are universally relevant. These techniques can be used with various data sources, such as image files, tables from a SQL query, or an HTTP response. The focus here is the process itself.
We will evaluate each method by considering the following factors:
- Code quality
- Memory usage
- Time efficiency
Before we get started, if you are doing API Testing that needs a eligible replacement for Postman (Which is getting more expensive and providing less features), APIDog is your ideal choice!

Apidog is a collaborative platform designed for API management and testing, similar to Postman, but with additional features that make handling dates easier. Here’s how it can help:
What is a Batch in the Context of Datasets
A batch is generally an input-output pair (X[i], y[i]), representing a subset of the data. For our sound-based detector, the model takes a processed audio sequence as input and outputs the probability of a particular event occurring. In this case, a batch consists of:
- X[t] - a matrix representing the processed audio track sampled over a time window
- y[t] - a binary label indicating the event’s occurrence.
Here, t refers to the time window (figure 1).
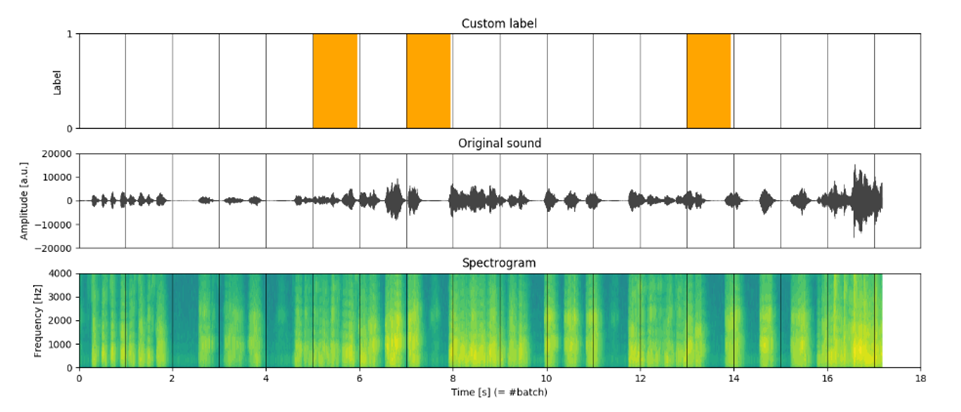
Comparing Different Approaches to Split Datasets
Approach #1 - Using a Large Tensor
The model receives input in the form of a 2D tensor. To accommodate batch processing, we can increase the tensor's rank, using the third dimension to represent batch size. The steps in this process are as follows:
- Load the input data (X).
- Load the corresponding labels (y).
- Divide X and y into smaller batches.
- Extract features for each batch (e.g., the spectrogram).
- Combine the processed batches of X[t] and y[t].
However, why might this approach not be ideal? Let’s explore an example implementation to understand better.
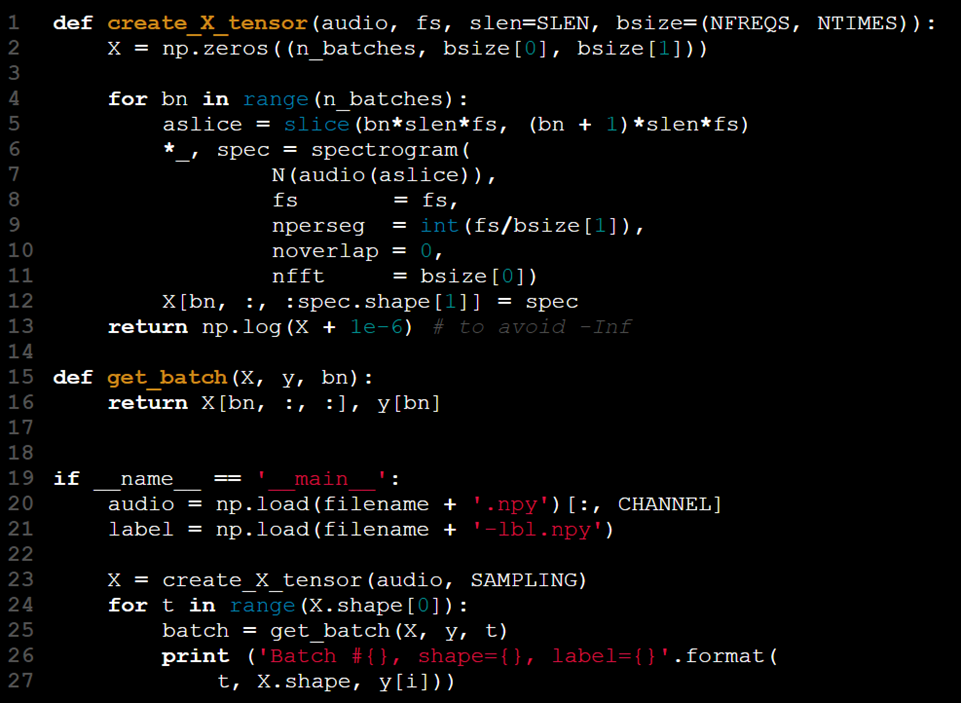
This approach can be summarized as "load everything at once and deal with the consequences later."
Pros and Cons of the "Large Tensor" Approach
While treating X as a self-contained dataset might seem advantageous, there are several drawbacks to this method:
1.Memory limitations: Loading the entire dataset into RAM can cause issues, especially if the available memory isn’t sufficient to hold all the data.
2.Batch dimension rigidity: The first dimension of X is used to represent batch size, but this is merely a convention. If someone decides to change this order (e.g., use the last dimension for batches), the code would need adjustments.
3.Tracking batches: Although X.shape[0] gives the exact number of batches, you still need an auxiliary variable (e.g., t) to track the current batch, adding complexity to the code.
4.Redundant function: This design requires a get_batch function, which only serves to slice and combine X and y for batching, making the code unnecessarily convoluted.
Approach #2 - Loading Batches Using HDF5
One way to address the issue of loading all data into RAM is by loading only portions of the data as needed. If the data is stored in a file, it makes sense to load and work with small sections instead of the entire dataset.
In the case of CSV files, using the skiprows and nrows arguments in Pandas' read_csv function allows you to load specific portions of the file.
But does this method really catches the wind of all scnearios? Let's say that we want to handle some very large, very complex data, i.e. audio files, it might not be fitting to handle them using skiprows or nrow using pandas' read_csv fucntion. That's why here is another way: Hierarchical Data Format (HDF5).
This format supports the storage of multiple arrays and provides a convenient way to access and manipulate them similar to NumPy arrays.
For instance, you can work with datasets named 'audio' and 'label' stored in an HDF5 file. The Python library h5py is a helpful tool for managing this format.
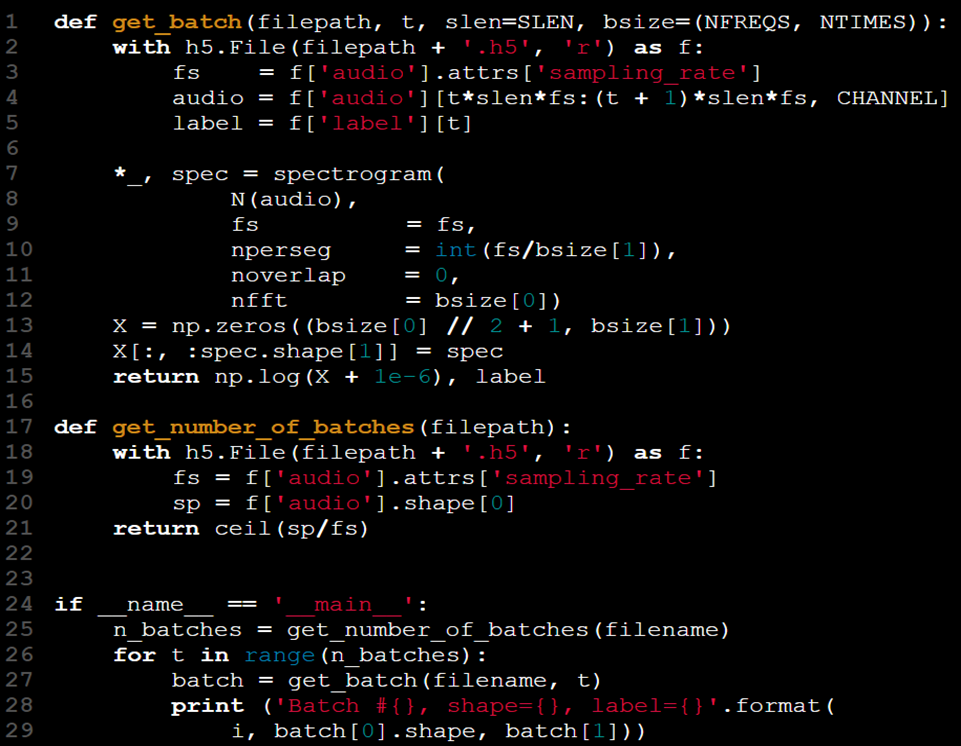
Now that our data is more manageable, we’ve also improved its overall quality:
- The previous get_batch function has been replaced with a more practical version that computes and retrieves the data efficiently.
- There’s no longer a need to modify the X tensor artificially.
- By changing get_batch(X, y, t) to get_batch(filename, t), we've abstracted data access and eliminated the need to keep X and y in the namespace.
- The dataset is now consolidated into a single file, making it unnecessary to source data and labels from separate files.
- The sampling rate (fs) is included as part of the dataset file through HDF5 attributes, eliminating the need to pass it as a separate argument.
Despite these improvements, two challenges remain:
- The new get_batch function does not track its state, so we still rely on using a loop to control t. There’s no built-in way for the function to know how large the loop should be, requiring us to check the data size in advance. This necessitates the creation of a second function: get_number_of_batches.
- While this setup is better, it still lacks the elegance of a fully state-preserving get_batch function, which could further simplify the process.
Approach #3 – Using Generators
What are Generators?
Generators are functions that return iterator objects. Instead of computing all results upfront, these iterators provide data one piece at a time, waiting for the next request to proceed. This makes them an ideal choice for handling large datasets efficiently.
Let's identify the recurring pattern:
We only need to access, process, and deliver portions of data sequentially, rather than loading everything at once. Python offers a solution for this in the form of generators.
Generators can be implemented in three ways:
Using a generator expression, similar to a list comprehension but with parentheses instead of square brackets (e.g., (i for i in iterable)).
Creating a generator function by using yield in place of return.
Defining a class with custom_ iter_ (or getitem_ ) and _next _ methods.
In this scenario, the yield keyword is a natural fit for our needs, allowing us to process and return data in manageable chunks.
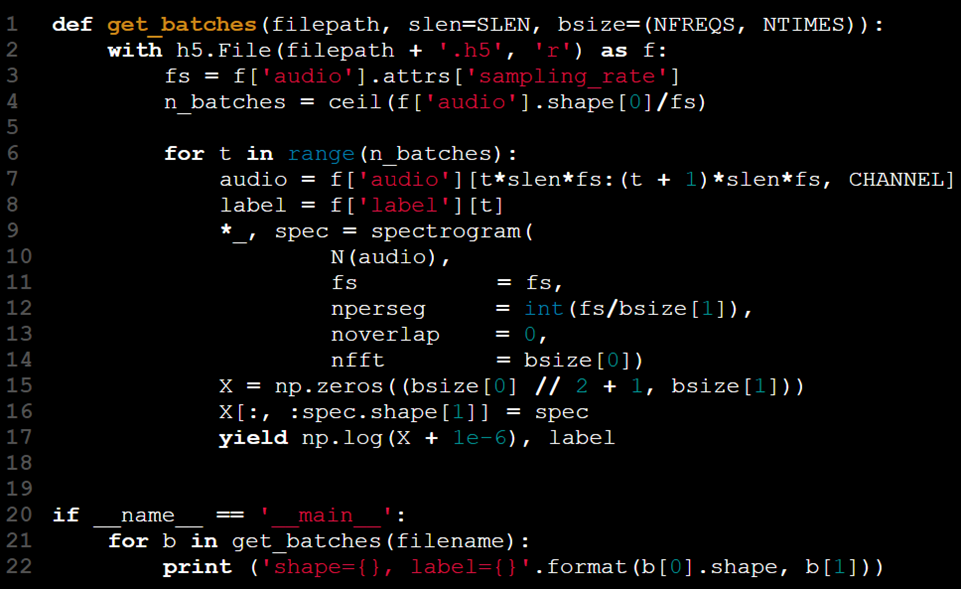
The loop is now contained within the function. By using the yield statement, the pair (X[t], y[t]) is returned only when get_batches has been called t - 1 times. This removes the need for the model training code to manage the loop’s state. The function retains its state between calls, allowing the user to simply iterate through the batches without needing a manual batch index.
Generator iterators can be compared to containers that gradually empty as data is processed. Since batches are retrieved with each iteration, the process continues until all data is consumed, eliminating the need for explicit indexing or stop conditions.
Performance: Time and Memory
We began by focusing on code quality, as it closely aligns with the way our solution has developed. However, it's equally important to consider resource limitations, particularly when handling large datasets.
Figure 2 shows the time required to deliver batches using the three methods we discussed. As observed, the time to process and transfer data remains almost the same across all methods. Whether we load all the data at once and then split it into batches, or process it incrementally from the start, the overall time to obtain the result is nearly identical. This could partly be due to using SSDs, which offer quicker data access. Nonetheless, the chosen approach appears to have minimal effect on overall time performance.
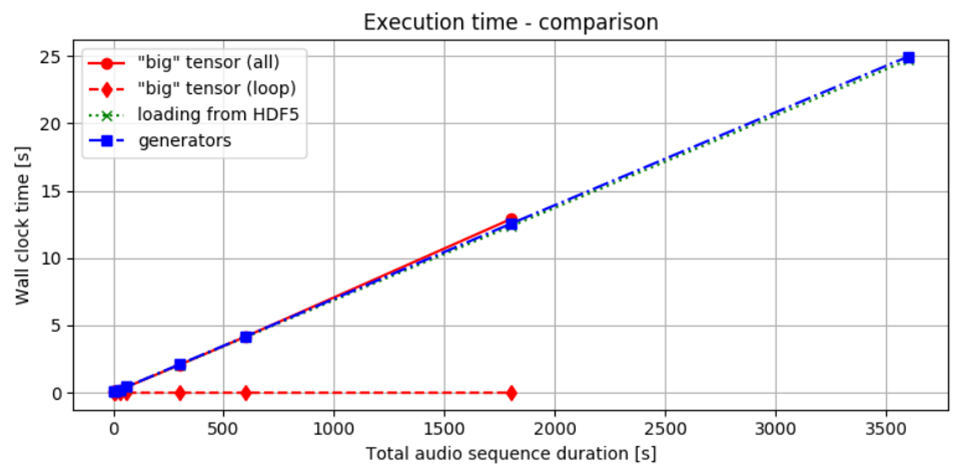
Figure 2. Time Performance Comparison: The red solid line indicates the time taken to both load data into memory and perform computations. The red dotted line represents the time spent solely on the loop that processes slices, assuming data has already been precomputed.
The green dotted line shows the timing for loading batches from an HDF5 file, while the blue dashed-dotted line illustrates the performance using a generator. Comparing the red lines, it is evident that accessing data once it is loaded into RAM incurs minimal additional cost. When data is local, the differences between the various methods are relatively small.
Figure 3. Memory Usage Comparison: The first approach demonstrates the highest memory consumption, leading to a Memory Error when handling a 1-hour long audio sample. In contrast, the chunk-based loading method controls memory allocation based on batch size, ensuring that RAM usage remains within safe limits.
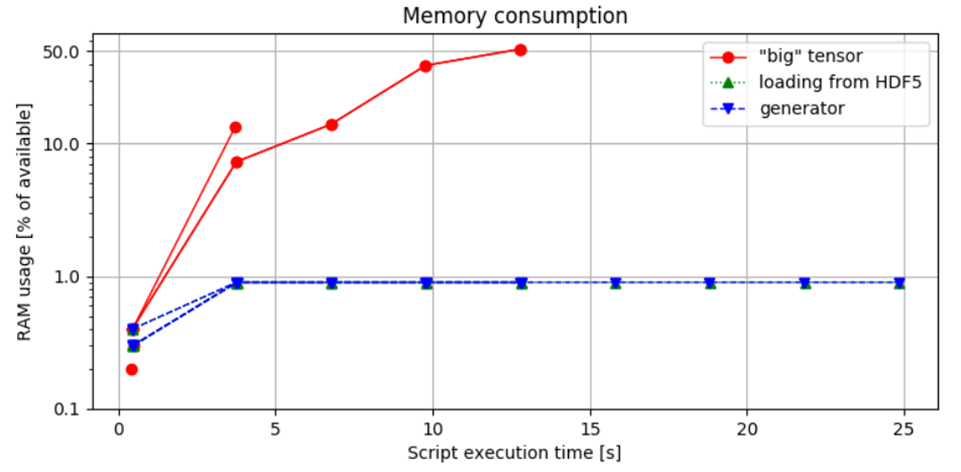
Figure 3. Comparison of Memory Consumption: This figure illustrates the percentage of available RAM used by the Python script, measured by running the script with the command:
python idea.py & top -b -n 10 > capture.log;cat capture.log | egrep python > analysis.log, and subsequently analyzed.
Observations and Insights:
The comparison between the second and third methods shows no significant difference in memory usage, indicating that the choice to implement a generator iterator does not impact memory footprint. This finding underscores an important point: while generators are often recommended for their efficiency in managing time and memory, they do not inherently reduce resource consumption.
The key factor is the efficiency of data access and the ability to handle data in manageable portions.
Utilizing HDF5 files is advantageous as it allows for quick data access and the flexibility to avoid loading all data at once. Meanwhile, incorporating a generator enhances code readability and quality.
Combining the use of HDF5 for partial data loading with generator iterators appears to be the most effective approach, as demonstrated by the third method. This combination optimizes both memory management and code clarity.
How to Split Datasets in Python (Examples)
Remember in Python, you can split a dataset into batches using a variety of methods, depending on the data type and framework you're working with. Below are several common approaches:
- Only Python: Use a simple loop or a generator to split lists or arrays.
- NumPy: Use numpy.array_split for splitting arrays.
- PyTorch: Use DataLoader for efficient batching in neural networks.
- TensorFlow: Use tf.data.Dataset for efficient batching and data pipelines.
- Pandas: Use list comprehensions or loops to split DataFrames.
1. Using a Simple Python Function
If you have a dataset in the form of a list or NumPy array, you can use a custom function to split the data into batches.
def split_into_batches(data, batch_size):
"""Split data into batches of a specified size."""
for i in range(0, len(data), batch_size):
yield data[i:i + batch_size]
# Example usage
dataset = [i for i in range(100)] # Example dataset
batch_size = 10
batches = list(split_into_batches(dataset, batch_size))
# Print batches
for batch in batches:
print(batch)2. Using numpy.array_split
If your dataset is in the form of a NumPy array, you can use the numpy.array_split() function to split the dataset into batches.
import numpy as np
# Example dataset
dataset = np.arange(100)
# Split into batches
batch_size = 10
batches = np.array_split(dataset, len(dataset) // batch_size)
# Print batches
for batch in batches:
print(batch)3. Using torch.utils.data.DataLoader (PyTorch)
If you are working with PyTorch, you can easily batch your dataset using DataLoader, which can shuffle and batch your data.
import torch
from torch.utils.data import DataLoader, TensorDataset
# Example dataset
data = torch.arange(100)
labels = torch.arange(100) # Suppose you have labels as well
# Create a TensorDataset
dataset = TensorDataset(data, labels)
# Split into batches using DataLoader
batch_size = 10
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
# Print batches
for batch_data, batch_labels in dataloader:
print(batch_data, batch_labels)Example: A simple list for achieving the indexer
import math
import torch
import torch.nn as nn
X = torch.rand(1000,10, 4)
batch_size = 64
num_batches = math.ceil(X.size()[0]/batch_size)
X_list = [X[batch_size*y:batch_size*(y+1),:,:] for y in range(num_batches)]
print(X_list[0].size())4. Using tensorflow.data.Dataset (TensorFlow)
For TensorFlow, the tf.data.Dataset API provides a high-performance way to batch datasets.
import tensorflow as tf
# Example dataset
dataset = tf.data.Dataset.range(100)
# Split into batches
batch_size = 10
batched_dataset = dataset.batch(batch_size)
# Print batches
for batch in batched_dataset:
print(batch.numpy())5. Using pandas for DataFrames
If your dataset is a pandas DataFrame, you can split it into batches by chunking it.
import pandas as pd
# Example dataset
data = pd.DataFrame({'A': range(100), 'B': range(100)})
# Split into batches
batch_size = 10
batches = [data[i:i+batch_size] for i in range(0, data.shape[0], batch_size)]
# Print batches
for batch in batches:
print(batch)Final Thoughts
In this post, we explored three methods for splitting and processing data in batches, comparing their performance and overall code quality. We observed that while generators alone do not necessarily enhance efficiency, they contribute to a more elegant and readable solution. Ultimately, the effectiveness of each approach is influenced by time and memory constraints.
Which approach do you find most appealing?
Choose the method that best fits your data format and processing needs.
Good luck!
FAQs About Splitting Datasets in Python
How to divide a dataset into batches in Python?
To divide a dataset into batches in Python, you can use libraries like NumPy or PyTorch. Here's a simple example using NumPy:
import numpy as np
def create_batches(data, batch_size):
return np.array_split(data, np.ceil(len(data) / batch_size))
# Example usage
data = np.arange(10) # Sample dataset
batches = create_batches(data, 3)
print(batches)
This function splits the dataset into batches of the specified size.
How should I split my dataset?
When splitting a dataset, consider the following strategies:
- Random Split: Shuffle the dataset and split it into training, validation, and test sets.
- Stratified Split: Ensure that each subset maintains the same distribution of target classes as the original dataset.
- Time-Based Split: For time series data, split based on time to maintain the sequence.
Common practice is to use a combination of these methods to ensure a representative sample in each subset.
How to split a dataset 80 20?
To split a dataset into 80% training and 20% testing, you can use the train_test_split function from the sklearn.model_selection module:
from sklearn.model_selection import train_test_split
data = ... # Your dataset
train_data, test_data = train_test_split(data, test_size=0.2, random_state=42)
This code will randomly split the dataset, allocating 80% to train_data and 20% to test_data.
How do I choose a batch size for a large dataset?
Choosing a batch size for a large dataset involves several considerations:
- Memory Constraints: Ensure the batch size fits within your GPU or CPU memory limits.
- Training Stability: Smaller batch sizes can lead to more stable training but may increase training time.
- Learning Dynamics: Larger batch sizes can speed up training but may lead to poorer generalization.
A common approach is to start with a batch size of 32 or 64 and adjust based on performance and resource availability. Experimentation is key to finding the optimal batch size for your specific scenario.
Before we conclude, if you are doing API Testing that needs a eligible replacement for Postman (Which is getting more expensive and providing less features), APIDog is your ideal choice!
Apidog is a collaborative platform designed for API management and testing, similar to Postman, but with additional features that make handling dates easier. Here’s how it can help:


