

Have you ever wanted to run sophisticated AI vision models right on your own machine, without depending on expensive cloud services or worrying about data privacy? Well, you're in luck! Today, we're diving deep into how to run Qwen 3 VL (Vision Language) models locally with Ollama and trust me, this is going to be a game-changer for your AI development workflow.
Now, before we jump into the technical stuff, let me ask you something: Are you tired of hitting API rate limits, paying sky-high costs for cloud inference, or simply want more control over your AI models? If you nodded yes, then this guide is specifically designed for you. Moreover, if you're looking for a powerful tool to test and debug your local AI APIs, I highly recommend downloading Apidog for free it's an excellent API testing platform that works seamlessly with Ollama's local endpoints.
In this guide, we’ll walk through everything you need to run Qwen 3 VL models locally using Ollama from installation to inference, troubleshooting, and even integrating with tools like Apidog. By the end of this comprehensive guide, you'll have a fully functional, private, and responsive vision-language Qwen3-VL running smoothly on your local machine, and you'll be equipped with all the knowledge you need to integrate it into your projects.
So, buckle up, grab your favorite beverage, and let's embark on this exciting journey together.
Understanding Qwen3-VL: The Revolutionary Vision-Language Model

Why Qwen 3 VL? And Why Run It Locally?
Before we jump into the technical steps, let’s talk about why Qwen 3 VL matters and why running it locally is a game-changer.
Qwen 3 VL is part of Alibaba’s Qwen series, but it’s specifically designed for vision-language tasks. Unlike traditional LLMs that only understand text, Qwen 3 VL can:
- Analyze images and answer questions about them (“What’s in this photo?”)
- Generate detailed captions
- Extract structured data from charts, diagrams, or documents
- Support multimodal RAG (retrieval-augmented generation) with visual context
And because it’s open-weight (under the Tongyi Qianwen license), developers can use, modify, and deploy it freely as long as they comply with the license terms.
Now, why run it locally?
- Privacy: Your images and prompts never leave your machine.
- Cost: No API fees or usage limits.
- Customization: Fine-tune, quantize, or integrate with your own pipelines.
- Offline access: Perfect for secure or air-gapped environments.
But local deployment used to mean wrestling with CUDA versions, Python environments, and massive Dockerfiles. Enter Ollama.
Model Variants: Something for Every Use Case
Qwen3-VL comes in various sizes to suit different hardware configurations and use cases. Whether you're working on a lightweight laptop or have access to a powerful workstation, there's a Qwen3-VL model that fits your needs perfectly.
Dense Models (Traditional Architecture):
- Qwen3-VL-2B: Perfect for edge devices and mobile applications
- Qwen3-VL-4B: Great balance of performance and resource usage
- Qwen3-VL-8B: Excellent for general-purpose tasks with moderate reasoning
- Qwen3-VL-32B: High-end tasks requiring strong reasoning and extensive context
Mixture-of-Experts (MoE) Models (Efficient Architecture):
- Qwen3-VL-30B-A3B: Efficient performance with only 3B active parameters
- Qwen3-VL-235B-A22B: Massive-scale applications with 235B total parameters but only 22B active
The beauty of MoE models is that they activate only a subset of "expert" neural networks for each inference, allowing massive parameter counts while keeping computational costs manageable.
Ollama: Your Gateway to Local AI Excellence
Now that we understand what Qwen3-VL brings to the table, let's talk about why Ollama is the ideal platform for running these models locally. Think of Ollama as the conductor of an orchestra it orchestrates all the complex processes happening behind the scenes so you can focus on what matters most: using your AI models.
What Is Ollama and Why It’s Perfect for Qwen 3 VL
Ollama is an open-source tool that lets you run large language models (and now, multimodal models) locally with a single command. Think of it as the “Docker for LLMs” but even simpler.
Key features:
- Automatic GPU acceleration (via Metal on macOS, CUDA on Linux)
- Built-in model library (including Llama 3, Mistral, Gemma, and now Qwen)
- REST API for easy integration
- Lightweight and beginner-friendly
Best of all, Ollama now supports Qwen 3 VL models, including variants like qwen3-vl:4b and qwen3-vl:8b. These are quantized versions optimized for local hardware meaning you can run them on consumer-grade GPUs or even powerful laptops.
The Technical Magic Behind Ollama
What happens behind the scenes when you run an Ollama command? It's like watching a well-choreographed dance of technological processes:
1.Model Download & Caching: Ollama intelligently downloads and caches model weights, ensuring fast startup times for frequently used models.
2.Quantization Optimization: Models are automatically optimized for your hardware configuration, choosing the best quantization method (4-bit, 8-bit, etc.) for your GPU and RAM.
3.Memory Management: Advanced memory mapping techniques ensure efficient GPU memory usage while maintaining high performance.
4.Parallel Processing: Ollama leverages multiple CPU cores and GPU streams for maximum throughput.
Prerequisites: What You’ll Need Before Installing
Before we install anything, let’s make sure your system is ready.
Hardware Requirements
- RAM: At least 16GB (32GB recommended for 8B models)
- GPU: NVIDIA GPU with 8GB+ VRAM (for Linux) or Apple Silicon Mac (M1/M2/M3 with 16GB+ unified memory)
- Storage: 10–20GB of free space (models are large!)
Software Requirements
- Operating System: macOS (12+) or Linux (Ubuntu 20.04+ recommended)
- Ollama: Latest version (v0.1.40+ for Qwen 3 VL support)
- Optional: Docker (if you prefer containerized deployment), Python (for advanced scripting)
Step-by-Step Installation Guide: Your Path to Local AI Mastery
Step 1: Installing Ollama - The Foundation
Let's start with the foundation of our entire setup. Installing Ollama is surprisingly straightforward it's designed to be accessible to everyone, from AI novices to seasoned developers.
For macOS Users:
1.Visit ollama.com/download
2.Download the macOS installer
3.Open the downloaded file and drag Ollama to your Applications folder
4.Launch Ollama from your Applications folder or Spotlight search
The installation process is incredibly smooth on macOS, and you'll see the Ollama icon appear in your menu bar once installation is complete.
For Windows Users:
1.Navigate to ollama.com/download
2.Download the Windows installer (.exe file)
3.Run the installer with administrator privileges
4.Follow the installation wizard (it's quite intuitive)
5.Once installed, Ollama will automatically start in the background
Windows users might see a Windows Defender notification don't worry, this is normal for the first run. Just click "Allow" and Ollama will work perfectly.
For Linux Users:
Linux users have two options:
Option A: Install Script (Recommended)
bash
curl -fsSL <https://ollama.com/install.sh> | sh
Option B: Manual Installation
bash
# Download the latest Ollama binarycurl -o ollama <https://ollama.com/download/ollama-linux-amd64>
# Make it executablechmod +x ollama
# Move to PATHsudo mv ollama /usr/local/bin/
Step 2: Verifying Your Installation
Now that Ollama is installed, let's make sure everything is working correctly. Think of this as a smoke test to ensure our foundation is solid.
Open your terminal (or command prompt on Windows) and run:
bash
ollama --version
You should see output similar to:
ollama version is 0.1.0
Next, let's test the basic functionality:
bash
ollama serve
This command starts the Ollama server. You should see output indicating the server is running on http://localhost:11434. Let the server run we'll use it to test our Qwen3-VL installation.
Step 3: Pulling and Running Qwen3-VL Models
Now for the exciting part! Let's download and run our first Qwen3-VL model. We'll start with a smaller model to test the waters, then move to more powerful variants.
Testing with Qwen3-VL-4B (Great Starting Point):
bash
ollama run qwen3-vl:4b
This command will:
1.Download the Qwen3-VL-4B model (approximately 2.8GB)
2.Optimize it for your hardware
3.Start an interactive chat session
Running Other Model Variants:
If you have more powerful hardware, try these alternatives:
bash
# For 8GB+ GPU systemsollama run qwen3-vl:8b
# For 16GB+ RAM systemsollama run qwen3-vl:32b
# For high-end systems with multiple GPUsollama run qwen3-vl:30b-a3b
# For maximum performance (requires serious hardware)ollama run qwen3-vl:235b-a22b
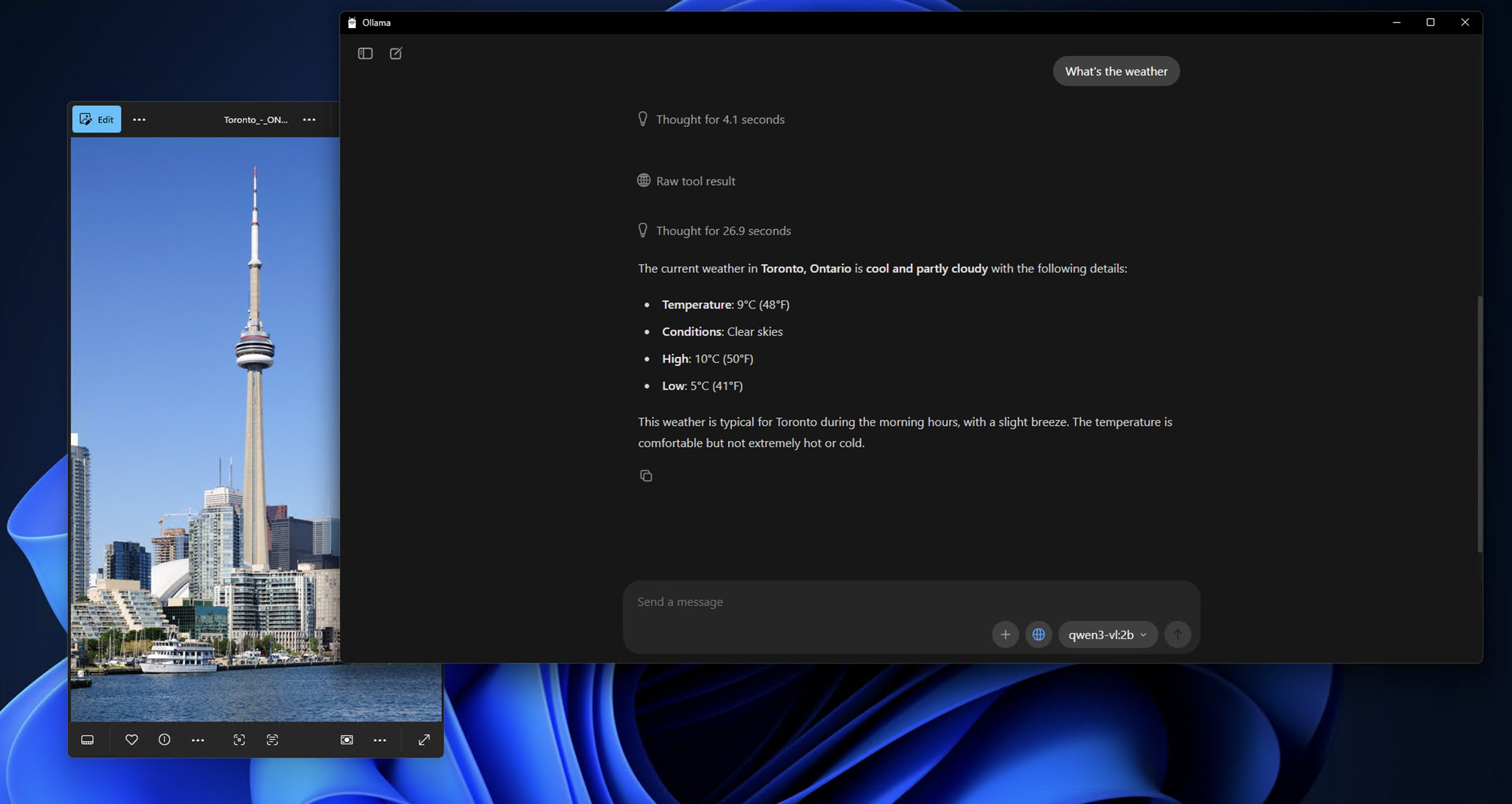
Step 4: First Interaction with Your Local Qwen3-VL
Once the model is downloaded and running, you'll see a prompt like this:
Send a message (type /? for help)
Let's test the model's capabilities with a simple image analysis:
Prepare a Test Image:
Find any image on your computer it could be a photo, screenshot, or illustration. For this example, I'll assume you have an image called test_image.jpg in your current directory.

Interactive Chat Testing:
bash
What do you see in this image? /path/to/your/image.jpg
Alternative: Using the API for Testing
If you prefer to test programmatically, you can use the Ollama API. Here's a simple test using curl:
bash
curl <http://localhost:11434/api/generate> \\
-H "Content-Type: application/json" \\
-d '{
"model": "qwen3-vl:4b",
"prompt": "What is in this image? Describe it in detail.",
"images": ["base64_encoded_image_data_here"]
}'

Step 5: Advanced Configuration Options
Now that you have a working installation, let's explore some advanced configuration options to optimize your setup for your specific hardware and use case.
Memory Optimization:
If you're running into memory issues, you can adjust the model loading behavior:
bash
# Set maximum memory usage (adjust based on your RAM)export OLLAMA_MAX_LOADED_MODELS=1
# Enable GPU offloadingexport OLLAMA_GPU=1
# Set custom port (if 11434 is already in use)export OLLAMA_HOST=0.0.0.0:11435
Quantization Options:
For systems with limited VRAM, you can force specific quantization levels:
bash
# Load model with 4-bit quantization (more compatible, slower)ollama run qwen3-vl:4b --format json
# Load with 8-bit quantization (balanced)ollama run qwen3-vl:8b --format json
Multi-GPU Configuration:
If you have multiple GPUs, you can specify which ones to use:
bash
# Use specific GPU IDs (Linux/macOS)export CUDA_VISIBLE_DEVICES=0,1
ollama run qwen3-vl:30b-a3b
# On macOS with multiple Apple Silicon GPUsexport CUDA_VISIBLE_DEVICES=0,1
ollama run qwen3-vl:30b-a3b
Testing and Integration with Apidog: Ensuring Quality and Performance

Now that you have Qwen3-VL running locally, let's talk about how to properly test and integrate it into your development workflow. This is where Apidog truly shines as an indispensable tool for AI developers.
Apidog isn't just another API testing tool it's a comprehensive platform designed specifically for modern API development workflows. When working with local AI models like Qwen3-VL, you need a tool that can:
1.Handle Complex JSON Structures: AI model responses often contain nested JSON with varying content types
2.Support File Uploads: Many AI models need image, video, or document inputs
3.Manage Authentication: Secure testing of endpoints with proper auth handling
4.Create Automated Tests: Regression testing for model performance consistency
5.Generate Documentation: Automatically create API documentation from your test cases
Troubleshooting Common Issues
Even with Ollama’s simplicity, you might hit snags. Here are fixes for frequent problems.
❌ “Model not found” or “Unsupported model”
- Ensure you’re using Ollama v0.1.40 or newer
- Run
ollama pull qwen3-vl:4bagain sometimes the download fails silently
❌ “Out of memory” on GPU
- Try the 4B version instead of 8B
- Close other GPU-heavy apps (Chrome, games, etc.)
- On Linux, check VRAM with
nvidia-smi
❌ Image not recognized
- Confirm the image is under 4MB
- Use PNG or JPG (avoid HEIC, BMP)
- Ensure base64 string has no newlines (use
base64 -w 0on Linux)
❌ Slow inference on CPU
- Qwen 3 VL is large even quantized. Expect 1–5 tokens/sec on CPU
- Upgrade to Apple Silicon or NVIDIA GPU for 10x speedup
Real-World Use Cases for Local Qwen 3 VL
Why go through all this trouble? Here are practical applications:
- Document Intelligence: Extract tables, signatures, or clauses from scanned PDFs
- Accessibility Tools: Describe images for visually impaired users
- Internal Knowledge Bots: Answer questions about internal diagrams or dashboards
- Education: Build a tutor that explains math problems from photos
- Security Analysis: Analyze network diagrams or system architecture screenshots
Because it’s local, you avoid sending sensitive visuals to third-party APIs a huge win for enterprises and privacy-conscious developers.
Conclusion: Your Journey into Local AI Excellence
Congratulations! You've just completed an epic journey into the world of local AI with Qwen3-VL and Ollama. By now, you should have:
- A fully functional Qwen3-VL installation running locally
- Comprehensive testing setup with Apidog
- Deep understanding of the model's capabilities and limitations
- Practical knowledge for integrating these models into real-world applications
- Troubleshooting skills to handle common issues
- Future-proofing strategies for continued success
The fact that you've made it this far shows your commitment to understanding and leveraging cutting-edge AI technology. You've not just installed a model you've gained expertise in a technology that's reshaping how we interact with visual and textual information.
The Future is Local AI
What we've accomplished here represents more than just technical setup it's a step toward a future where AI is accessible, private, and under individual control. As these models continue to improve and become more efficient, we're moving toward a world where sophisticated AI capabilities are available to everyone, regardless of their budget or technical expertise.
Remember, the journey doesn't end here. AI technology evolves rapidly, and staying curious, adaptive, and engaged with the community will ensure you continue to leverage these powerful tools effectively.
Final Thoughts
Running Qwen 3 VL locally with Ollama isn’t just a tech demo or about convenience or cost savings it’s a glimpse into the future of on-device AI. As models get more efficient and hardware gets more powerful, we’ll see more developers ship private, multimodal features directly in their apps. You now have the tools to explore AI technology without limitations, to experiment freely, and to build applications that matter to you and your organization.
The combination of Qwen3-VL's impressive multimodal capabilities and Ollama's user-friendly interface creates opportunities for innovation that were previously available only to large corporations with massive resources. You're now part of a growing community of developers democratizing AI technology.
And with tools like Ollama simplifying deployment and Apidog streamlining API development, the barrier to entry has never been lower.
So whether you’re a solo hacker, a startup founder, or a corporate engineer, now’s the perfect time to experiment with vision-language models safely, affordably, and locally.


