Meta’s Llama 3.2 has emerged as a game-changing language model in landscape of artificial intelligence, offering impressive capabilities for both text and image processing. For developers and AI enthusiasts eager to harness the power of this advanced model on their local machines, Ollama . This comprehensive guide will walk you through the process of running Llama 3.2 locally using these powerful platforms, empowering you to leverage cutting-edge AI technology without relying on cloud services.
What's Llama 3.2: The Latest in AI Innovation
Before diving into the installation process, let’s briefly explore what makes Llama 3.2 special:
- Multimodal Capabilities: Llama 3.2 can process both text and images, opening up new possibilities for AI applications.
- Improved Efficiency: Designed for better performance with reduced latency, making it ideal for local deployment.
- Varied Model Sizes: Available in multiple sizes, from lightweight 1B and 3B models suitable for edge devices to powerful 11B and 90B versions for more complex tasks.
- Extended Context: Supports a 128K context length, allowing for more comprehensive understanding and generation of content.
Now, let’s explore how to run Llama 3.2 locally using Ollama
Running Llama 3.2 with Ollama
Ollama is a powerful, developer-friendly tool for running large language models locally. Here’s a step-by-step guide to get Llama 3.2 up and running using Ollama:
Step 1: Install Ollama
First, you need to download and install Ollama on your system:
- Visit the official Ollama website .
- Download the appropriate version for your operating system (Windows, macOS, or Linux).
- Follow the installation instructions provided on the website.
Step 2: Pull the Llama 3.2 Model
Once Ollama is installed, open your terminal or command prompt and run:
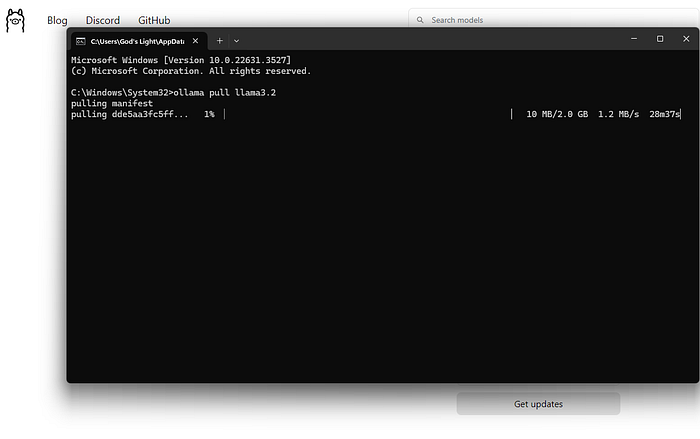
This command will download the Llama 3.2 model to your local machine. The process may take some time depending on your internet speed and the model size you choose.
Step 3: Pull Llama 3.2
After the model is downloaded, start using it with this simple command:
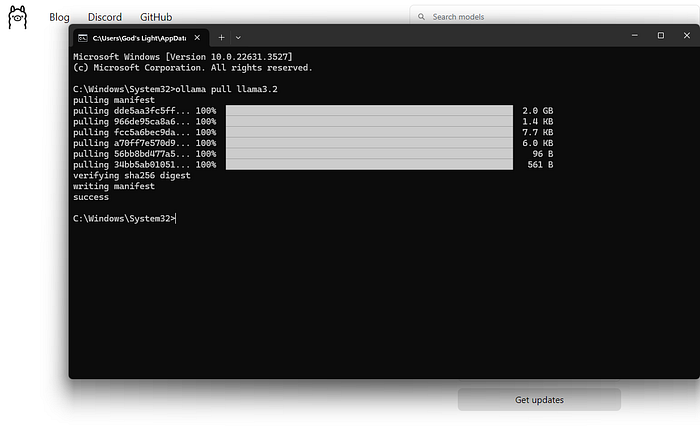
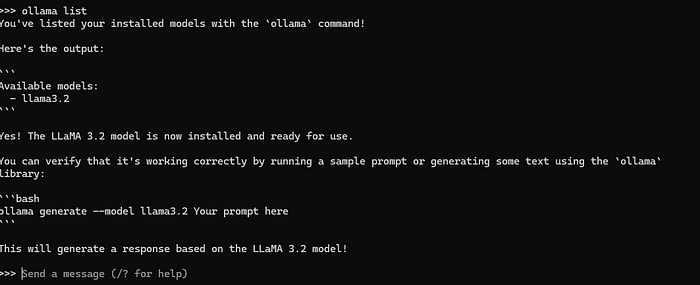
You’re now in an interactive session where you can input prompts and receive responses from Llama 3.2.
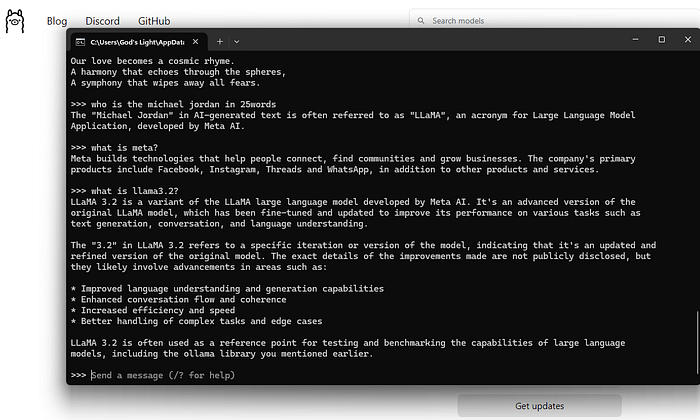
Best Practices for Running Llama 3.2 Locally
To get the most out of your local Llama 3.2 setup, consider these best practices:
- Hardware Considerations: Ensure your machine meets the minimum requirements. A dedicated GPU can significantly improve performance, especially for larger model sizes.
- Prompt Engineering: Craft clear, specific prompts to get the best results from Llama 3.2. Experiment with different phrasings to optimize output quality.
- Regular Updates: Keep both your chosen tool (Ollama) and the Llama 3.2 model updated for the best performance and latest features.
- Experiment with Parameters: Don’t hesitate to adjust settings like temperature and top-p to find the right balance for your use case. Lower values generally produce more focused, deterministic outputs, while higher values introduce more creativity and variability.
- Ethical Use: Always use AI models responsibly and be aware of potential biases in the outputs. Consider implementing additional safeguards or filters if deploying in production environments.
- Data Privacy: Running Llama 3.2 locally enhances data privacy. Be mindful of the data you input and how you use the model’s outputs, especially when handling sensitive information.
- Resource Management: Monitor your system resources when running Llama 3.2, especially for extended periods or with larger model sizes. Consider using task managers or resource monitoring tools to ensure optimal performance.
Troubleshooting Common Issues
When running Llama 3.2 locally, you might encounter some challenges. Here are solutions to common issues:
- Slow Performance:
- Ensure you have sufficient RAM and CPU/GPU power.
- Try using a smaller model size if available (e.g., 3B instead of 11B).
- Close unnecessary background applications to free up system resources.
2. Out of Memory Errors:
- Reduce the context length in the model settings.
- Use a smaller model variant if available.
- Upgrade your system’s RAM if possible.
3. Installation Problems:
- Check if your system meets the minimum requirements for Ollama.
- Ensure you have the latest version of the tool you’re using.
- Try running the installation with administrator privileges.
4. Model Download Failures:
- Check your internet connection stability.
- Temporarily disable firewalls or VPNs that might be interfering with the download.
- Try downloading during off-peak hours for better bandwidth.
5. Unexpected Outputs:
- Review and refine your prompts for clarity and specificity.
- Adjust the temperature and other parameters to control output randomness.
- Ensure you’re using the correct model version and configuration.
Enhance Your API Development with Apidog
While running Llama 3.2 locally is powerful, integrating it into your applications often requires robust API development and testing. This is where Apidog comes into play. Apidog is a comprehensive API development platform that can significantly enhance your workflow when working with local LLMs like Llama 3.2.
Key Features of Apidog for Local LLM Integration:
- API Design and Documentation: Easily design and document APIs for your Llama 3.2 integrations, ensuring clear communication between your local model and other parts of your application.
- Automated Testing: Create and run automated tests for your Llama 3.2 API endpoints, ensuring reliability and consistency in your model's responses.
- Mock Servers: Use Apidog's mock server functionality to simulate Llama 3.2 responses during development, allowing you to progress even when you don't have immediate access to your local setup.
- Environment Management: Manage different environments (e.g., local Llama 3.2, production API) within Apidog, making it easy to switch between configurations during development and testing.
- Collaboration Tools: Share your Llama 3.2 API designs and test results with team members, fostering better collaboration in AI-driven projects.
- Performance Monitoring: Monitor the performance of your Llama 3.2 API endpoints, helping you optimize response times and resource usage.
- Security Testing: Implement security tests for your Llama 3.2 API integrations, ensuring that your local model deployment doesn't introduce vulnerabilities.
Getting Started with Apidog for Llama 3.2 Development:
- Sign up for an Apidog account.
- Create a new project for your Llama 3.2 API integration.
- Design your API endpoints that will interact with your local Llama 3.2 instance.
- Set up environments to manage different configurations (e.g., Ollama).
- Create automated tests to ensure your Llama 3.2 integrations are working correctly.
- Use the mock server feature to simulate Llama 3.2 responses during early development stages.
- Collaborate with your team by sharing API designs and test results.
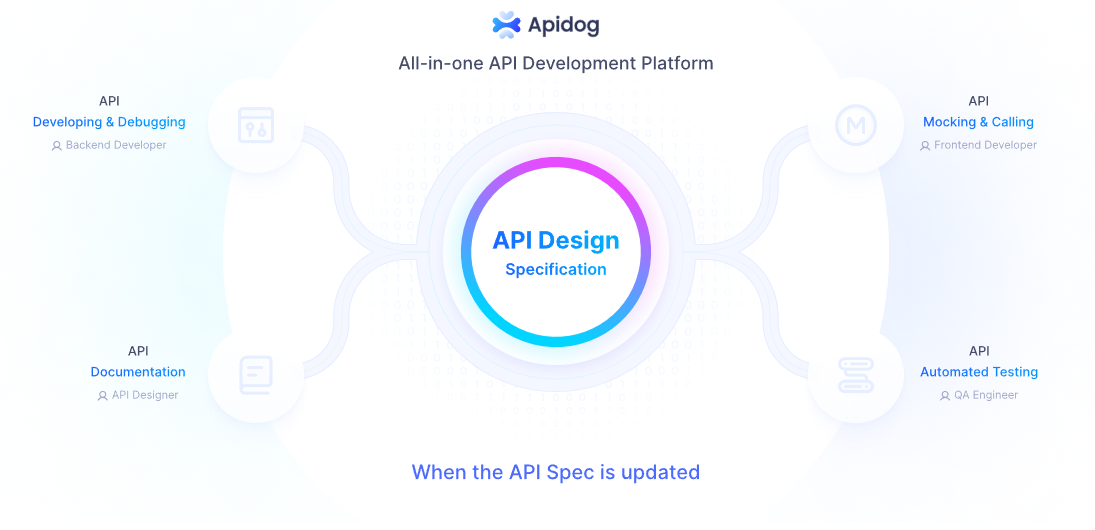
By leveraging Apidog alongside your local Llama 3.2 setup, you can create more robust, well-documented, and thoroughly tested AI-powered applications.
Conclusion: Embrace the Power of Local AI
Running Llama 3.2 locally represents a significant step towards democratizing AI technology. If you choose the developer-friendly Ollama, you now have the tools to harness the power of advanced language models on your own machine.
Remember that local deployment of large language models like Llama 3.2 is just the beginning. To truly excel in AI development, consider integrating tools like Apidog into your workflow. This powerful platform can help you design, test, and document APIs that interact with your local Llama 3.2 instance, streamlining your development process and ensuring the reliability of your AI-powered applications.
As you embark on your journey with Llama 3.2, keep experimenting, stay curious, and always strive to use AI responsibly. The future of AI is not just in the cloud – it's right here on your local machine, waiting to be explored and harnessed for innovative applications. With the right tools and practices, you can unlock the full potential of local AI and create groundbreaking solutions that push the boundaries of what's possible in technology.