
xAI released Grok 4.1 and engineers who work with large language models notice the difference immediately. Moreover, this update prioritizes real-world usability over raw benchmark chasing. As a result, conversations feel sharper, responses carry consistent personality, and factual errors drop dramatically.
Researchers at xAI built Grok 4.1 on the same reinforcement learning infrastructure that powered Grok 4. However, they introduced novel reward modeling techniques that deserve close examination.
Architecture and Deployment Variants
xAI ships Grok 4.1 in two distinct configurations. First, the non-thinking variant (internal codename: tensor) generates responses directly without intermediate reasoning tokens. This mode prioritizes latency and achieves the fastest inference times in the family. Second, the thinking variant (codename: quasarflux) exposes explicit chain-of-thought steps before final output. Consequently, complex analytical tasks benefit from visible reasoning traces.
Both variants share the same pretrained backbone. Additionally, post-training alignments differ subtly: the thinking mode receives extra reinforcement signals that encourage step-by-step decomposition, whereas the non-thinking mode optimizes for concise, immediate replies.
Access remains straightforward. Users select “Grok 4.1” explicitly in the model picker on grok.com, x.com, or the mobile apps.
Alternatively, Auto mode now defaults to Grok 4.1 for most traffic following the gradual rollout that began November 1, 2025.

Breakthroughs in Preference Optimization
The core innovation lies in reward modeling. Traditional RLHF relies on human preferences collected at scale. In contrast, xAI now deploys frontier agentic reasoning models as autonomous judges. These judges evaluate thousands of response variants across dimensions such as style coherence, emotional perceptiveness, factual grounding, and personality stability.
This closed-loop system iterates far faster than human-in-the-loop workflows. Furthermore, it scales to nuanced criteria that humans struggle to rank consistently. Early internal experiments showed that agentic reward models correlate better with downstream user satisfaction than previous scalar rewards.
Benchmark Dominance: LMArena and Beyond
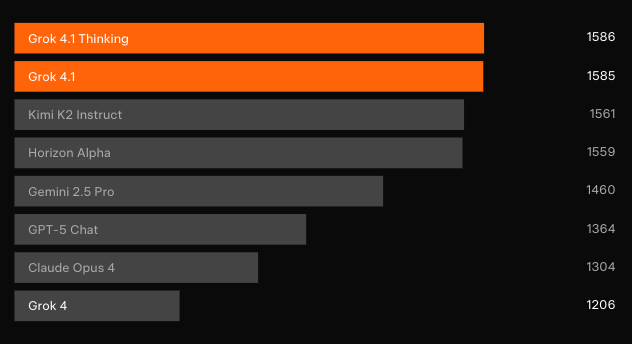
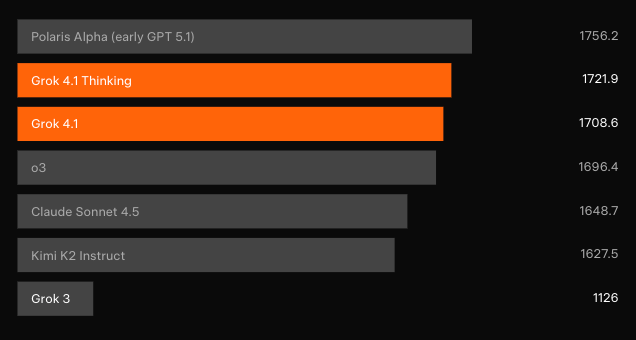
Independent blind testing confirms the gains. On LMArena’s Text Arena — the most representative crowd-sourced leaderboard — Grok 4.1 Thinking claims the #1 position with 1483 Elo. That margin sits at 31 points ahead of the best non-xAI entrant. Meanwhile, Grok 4.1 non-thinking secures #2 at 1465 Elo, outperforming every other model’s full-reasoning configuration.

Pairwise preference tests against the prior production model show users select Grok 4.1 responses 64.78% of the time. Moreover, specialized evaluations reveal targeted leaps.
Emotional Intelligence (EQ-Bench v3)
Grok 4.1 achieves the highest recorded score on EQ-Bench3, which judges 45 multi-turn roleplay scenarios for empathy, insight, and interpersonal nuance. Responses now detect subtle emotional cues that earlier models overlooked. For example, when a user writes “I miss my cat so much it hurts,” Grok 4.1 delivers layered acknowledgment, gentle validation, and open-ended support without sliding into generic platitudes.
Creative Writing v3
The model also sets a new record on Creative Writing v3, where judges score iterative story continuation across 32 prompts. Outputs exhibit richer imagery, tighter plot coherence, and more authentic voice. One demonstration prompt asking Grok to roleplay its own “awakening” produced a viral X-post-style monologue that blended humor, existential wonder, and meme references seamlessly.
Hallucination Mitigation
Quantitative measurements show Grok 4.1 hallucinates three times less often on information-seeking queries than its predecessor. Engineers accomplished this through targeted post-training on stratified production traffic and classic datasets like FActScore (500 biography questions). Additionally, the non-thinking mode now triggers web search tools proactively when confidence falls below internal thresholds, further anchoring responses in verifiable sources.

Safety and Responsibility Evaluation
The official model card, provides unprecedented transparency into red-team results.
Input filters block restricted biology and chemistry queries with false-negative rates as low as 0.00–0.03 under direct requests. Prompt injection attacks raise that figure modestly (0.12–0.20), indicating ongoing adversarial robustness work.
Refusal rates on violative chat prompts reach 93–95% even without filters, and jailbreak success drops near zero in the non-thinking configuration. Agentic scenarios (AgentHarm, AgentDojo) remain the hardest category, but absolute answer rates stay below 0.14.
Dual-use capability assessments — deliberately conducted without safeguards — reveal strong knowledge recall in biology (WMDP-Bio 87%) and chemistry, yet multi-step procedural reasoning lags human expert baselines on tasks requiring figure interpretation or cloning protocols. This pattern aligns with current frontier limitations across the industry.
Implications for API Consumers and Developers
The xAI API already serves Grok 4.1 endpoints under the standard model names. Latency profiles improve noticeably: non-thinking mode averages under 400 ms time-to-first-token on typical prompts, while thinking mode adds controllable reasoning depth via optional parameters.
Apidog shines exactly here. Import the official OpenAPI 3.1 specification (available publicly), then generate client SDKs in 20+ languages instantly. Set up mock servers that replicate Grok 4.1’s exact response schema — including the new thinking token streams — so your backend tests never block on live API credits. When xAI deploys breaking changes (rare, but possible), Apidog’s diff viewer highlights schema drift immediately.
Real teams already use Apidog to maintain 100% uptime during model upgrades. One Fortune-500 client reported cutting integration bugs by 68% after switching from Postman.
Comparison Against Contemporary Frontier Models
Direct head-to-head data remains sparse hours after launch, but LMArena Elo ratings provide the clearest signal. Grok 4.1 Thinking outperforms every released configuration from OpenAI, Anthropic, Google, and Meta by margins that typically require full architectural leaps.
Speed-quality tradeoffs favor Grok 4.1 non-thinking for consumer chat, while thinking mode competes directly with reasoning-heavy offerings like o3-pro or Claude 4 Opus — often winning on subjective coherence and personality retention.
Conclusion
Grok 4.1 does not merely increment metrics; it reorients the frontier toward models that people actually enjoy talking to for hours. Technical users gain a faster, more reliable endpoint. Creatives unlock a collaborator that understands tone and emotion at previously unattainable levels. And safety researchers receive the most detailed model card published to date.
Download Apidog today — completely free — and start building with Grok 4.1 before your competitors finish reading the announcement. The difference between watching frontier progress and shipping products on it often comes down to tooling decisions made today.


