
Choosing the right data management strategy is essential for achieving success in your projects. The effectiveness of your applications often hinges on how well you can manage and retrieve data.
In this article, we will dive into the key differences and benefits of GraphQL and SQL, two powerful approaches that cater to different data needs. By understanding their unique features, you can make informed decisions that align with your application's requirements and enhance its performance. Join us as we unravel the complexities of each method, paving the way for smarter, more efficient data management!
Click the Download button and transform your SQL Server connectivity today! 🚀🌟
What is GraphQL?
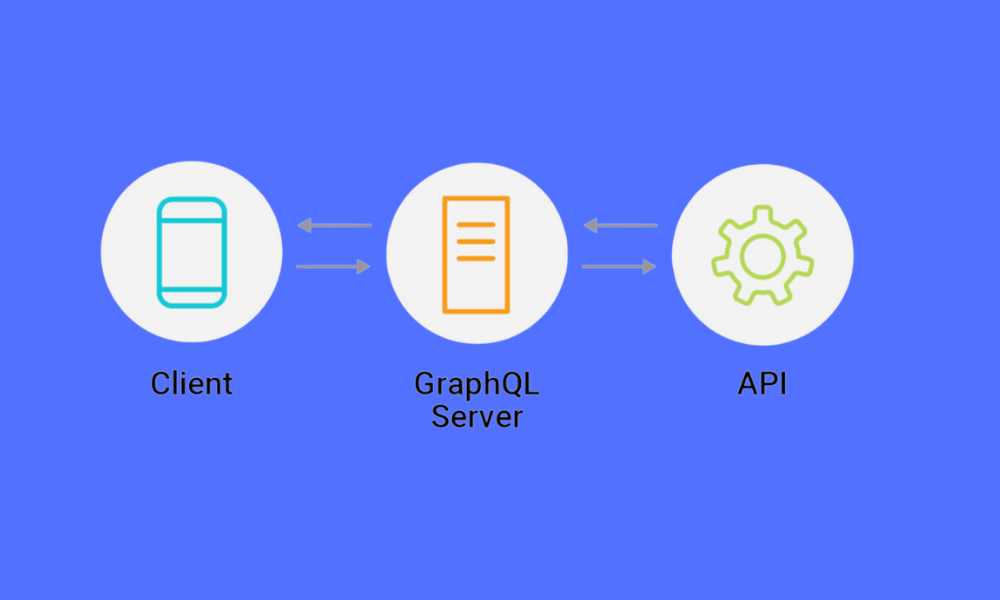
GraphQL is a query language developed by Facebook for APIs, as well as a runtime for executing those queries by using a type system defined for your data. It's not a database technology, but rather a way to interact with data through APIs.
type Query {
user(id: ID!): User
}
type User {
id: ID!
name: String
email: String
}
# Query
{
user(id: "123") {
name
email
}
}
Key Features of GraphQL
- Client-Specific Queries: Allows clients to request exactly what data they need, even with deeply nested structures.
- Single Endpoint: Uses a single API endpoint and leverages queries to fetch various data shapes.
- Real-Time Data with Subscriptions: Supports real-time data updates through subscriptions.
- Decreased Overfetching: Reduces unnecessary data transfer by allowing clients to specify exactly what they need.
Why Use GraphQL in Your Application?
Using GraphQL in an application can provide a host of benefits, especially for data-driven applications that rely on efficient and flexible data fetching. Let’s use an example of a blogging platform to illustrate the benefits of GraphQL.
Scenario: Building a Blog API
Imagine you’re developing a blog application with the following entities:
- User: Author of the blog posts.
- Post: The blog post, including title, content, and publish date.
- Comments: Comments on each post by readers.
In a REST API, you might have the following endpoints:
/users/{id}to get user details./posts/{id}to get post details./posts/{id}/commentsto get comments on a post.
To build a detailed blog post page, you’d want to display:
- The post content.
- The author’s name and profile.
- All comments, along with the name of each commenter.
REST Approach
- First Request:
/posts/123– Fetches the post content and metadata. - Second Request:
/users/45– Fetches details of the author (assuming author ID is 45). - Third Request:
/posts/123/comments– Fetches all comments for the post. - Additional Requests: You may need more requests if each comment requires data from different users, fetching each commenter's profile separately.
With REST, this can lead to over-fetching (retrieving more information than necessary, like extra fields in each endpoint) and under-fetching (not retrieving nested relationships like comments and user details in a single query).
GraphQL Approach
With GraphQL, you can structure a single query to fetch all necessary data:
query {
post(id: "123") {
title
content
publishedDate
author {
name
profilePicture
}
comments {
text
commenter {
name
}
}
}
}
In this single query:
- Post Data: You get the
title,content, andpublishedDateof the post. - Author Data: Nested under the
authorfield, so you only get thenameandprofilePictureyou need. - Comments: Each comment includes only the
textand the commenter'sname.
Key Benefits in This Example
- Reduced Network Requests: Instead of multiple requests to different endpoints, you’re fetching all necessary data with a single request. This reduces network load and speeds up the response time.
- Avoids Over-fetching/Under-fetching: You receive only the specific fields you asked for, with no excess data or missing fields. This makes data retrieval more efficient, especially on mobile or low-bandwidth networks.
- Single Source of Truth: The GraphQL schema defines the data structure, making it clear to both frontend and backend teams what data is available and how it can be queried.
- Simplified Versioning: Since each client specifies the data it needs, backend teams can safely evolve the schema without breaking existing functionality.
In this way, GraphQL’s query flexibility lets you optimize data fetching and makes your application faster and more efficient, especially when dealing with complex or deeply nested data.
What is SQL?
SQL (Structured Query Language) is a domain-specific language used in programming and designed for managing data held in relational database management systems (RDBMS). It is particularly effective for handling structured data where relationships between different entities are clearly defined.

SELECT name, email FROM users WHERE id = 123;
Key Features of SQL
- Standardized Query Language: A widely accepted standard for querying and manipulating data in relational databases.
- Tabular Data Representation: Data is organized in tables and relations can be formed using primary and foreign keys.
- Complex Queries: Supports complex queries with JOIN operations, aggregations, and subqueries.
- Transactional Control: Provides robust transactional control to ensure data integrity.
Why Use SQL in Your Application?
Using SQL (Structured Query Language) in your application has several advantages, especially when dealing with structured data and complex querying requirements. SQL databases, also known as relational databases, are widely used in applications across many industries due to their reliability, robust data integrity, and ease of use. Let’s use an example of an e-commerce application to illustrate the benefits of SQL.
Scenario: Building an E-commerce Application with SQL
Imagine you’re developing an online store with the following features:
- Users: Customers who can create accounts, place orders, and write reviews.
- Products: Items for sale, each with specific details (name, price, stock quantity).
- Orders: Transactions that include one or more products purchased by a user.
- Reviews: Feedback left by users on different products.
In SQL, these features can be represented by related tables:
- Users Table: Stores user information (user ID, name, email).
- Products Table: Stores product information (product ID, name, price, stock).
- Orders Table: Stores each order’s metadata (order ID, user ID, order date).
- OrderItems Table: Stores details about each item in an order (order item ID, order ID, product ID, quantity).
- Reviews Table: Stores reviews from users (review ID, user ID, product ID, rating, comment).
How SQL Makes This Efficient
Data Integrity with Foreign Keys
- The
OrderItemstable contains aproduct_idthat links to theProductstable, ensuring that every order item references a valid product. Similarly, theOrderstable includes auser_idfield that links to theUserstable, ensuring each order is tied to an existing user. - This setup enforces data integrity, preventing orders from including products or users that don’t exist.
Complex Queries for Reports
- Suppose you want a report of the total sales for each product. In SQL, you can use a query with joins and aggregation functions to get this data efficiently:
SELECT
Products.name,
SUM(OrderItems.quantity) AS total_quantity_sold,
SUM(OrderItems.quantity * Products.price) AS total_revenue
FROM
OrderItems
JOIN
Products ON OrderItems.product_id = Products.product_id
GROUP BY
Products.name;
This query calculates both the quantity and revenue of each product, which would otherwise require multiple steps in less structured databases.Ensuring Transactional Consistency
- When a user places an order, the application needs to update several tables:
- Add an entry to the
Orderstable for the transaction. - Add entries to the
OrderItemstable for each item purchased. - Reduce the stock quantity in the
Productstable. - Using SQL transactions, these actions are grouped together. If any step fails (e.g., a product goes out of stock), the entire transaction can be rolled back, ensuring the database remains in a consistent state.Here’s how this transaction might look in SQL:
BEGIN TRANSACTION;
-- Add a new order
INSERT INTO Orders (user_id, order_date)
VALUES (1, CURRENT_DATE);
-- Add order items
INSERT INTO OrderItems (order_id, product_id, quantity)
VALUES (LAST_INSERT_ID(), 2, 3);
-- Deduct stock
UPDATE Products
SET stock = stock - 3
WHERE product_id = 2;
COMMIT;
If the stock update fails due to insufficient quantity, SQL will roll back the transaction to ensure the order and order items aren’t partially saved, maintaining data accuracy.Data Analysis and Customer Insights
- With SQL, you can generate insights on customer behavior and product performance. For example, you might want to find the most frequently purchased products:
SELECT
product_id, COUNT(*) AS purchase_count
FROM
OrderItems
GROUP BY
product_id
ORDER BY
purchase_count DESC
LIMIT 5;
- This query finds the top five products by purchase count, a valuable metric for understanding popular products and planning inventory.
Summary of SQL Advantages in this Example
- Structured Data and Relationships: Tables and foreign keys help enforce structured, relational data, which is ideal for organized applications like e-commerce.
- Data Integrity and ACID Compliance: SQL transactions ensure that operations are completed fully or not at all, crucial for handling orders.
- Powerful Query Capabilities: SQL’s joins, aggregations, and groupings enable efficient data analysis and reporting, simplifying insights on sales and customer behavior.SQL is thus well-suited for this e-commerce application because it allows efficient data organization, reliable data integrity, and powerful querying, making it easier to manage and analyze data in real time.
Key Differences Between GraphQL and SQL
GraphQL and SQL each provide distinct benefits for managing and retrieving data. The flexible querying features, real-time functionalities, and efficient data fetching of GraphQL make it ideal for contemporary applications with varied data requirements.
In contrast, SQL is exceptional in managing structured data, navigating complex relationships, and maintaining transactional integrity. Details are as follow:
Purpose and Scope:
- GraphQL is a query language specifically designed for client-server interactions, primarily used for web APIs.
- SQL is a language for managing and manipulating data in a relational database.
Data Retrieval:
- GraphQL allows clients to specify exactly what data they need in a single request.
- SQL queries are more focused on retrieving data from a database through SELECT queries, joins, and other operations.
Real-time Data:
- GraphQL can handle real-time data with subscriptions.
- SQL does not natively support real-time data updates in the same way.
Flexibility in Querying:
- GraphQL offers high flexibility, allowing for customized queries tailored to the client's requirements.
- SQL follows a more structured approach, with predefined schemas and rigid query formats.
Handling of Overfetching:
- GraphQL effectively reduces overfetching by allowing specific queries.
- SQL might result in overfetching if the query is not well-structured or too broad.
Complexity and Learning Curve:
- GraphQL might have a steeper learning curve due to its unique approach to data retrieval.
- SQL is widely taught and used, with a vast amount of resources and a standardized approach.
Differences Between GraphQL vs SQL
| Aspect | GraphQL | SQL |
|---|---|---|
| Basic Definition | A query language for APIs, allowing clients to request specific data. | A language for managing and querying data in relational databases. |
| Data Retrieval Approach | Allows clients to request exactly what they need, reducing overfetching. | Utilizes predefined queries to retrieve data, which can lead to overfetching. |
| Real-time Data Support | Supports real-time updates with subscriptions. | Generally does not support real-time updates natively. |
| Type of Communication | Typically operates over HTTP/HTTPS with a single endpoint. | Operates over database connections, using various protocols based on the database system. |
| Query Flexibility | Highly flexible; clients can tailor requests to their exact needs. | More structured; relies on predefined schemas and query formats. |
| Data Structure | Works well with hierarchical and nested data structures. | Best suited for tabular data in normalized forms. |
| Use Cases | Ideal for complex, evolving APIs and applications with diverse data needs. | Suited for applications requiring complex transactions and data integrity in databases. |
| Complexity | Can be complex to set up and optimize for performance. | Widely used with a lot of educational resources, but complex queries can be challenging. |
| Transactional Control | Does not handle transactions; focused on data fetching. | Provides robust transactional control for data integrity. |
| Community and Ecosystem | Growing rapidly, especially popular in web and mobile application development. | Mature, with extensive tools, resources, and a vast community of users. |
| Typical Use Environment | Commonly used in web and mobile applications for flexible data retrieval. | Used in systems where data integrity, complex queries, and reporting are crucial. |
How to Connect to SQL Server in Apidog
Connecting to an SQL Server in Apidog is a process similar to connecting to an Oracle database but with some specific differences catering to SQL Server. Here's a concise guide to help you set up this connection:
Step 1: Install Apidog
- Download Apidog: Visit Apidog's official website and download the application. Ensure it's compatible with your operating system (Windows or Linux).
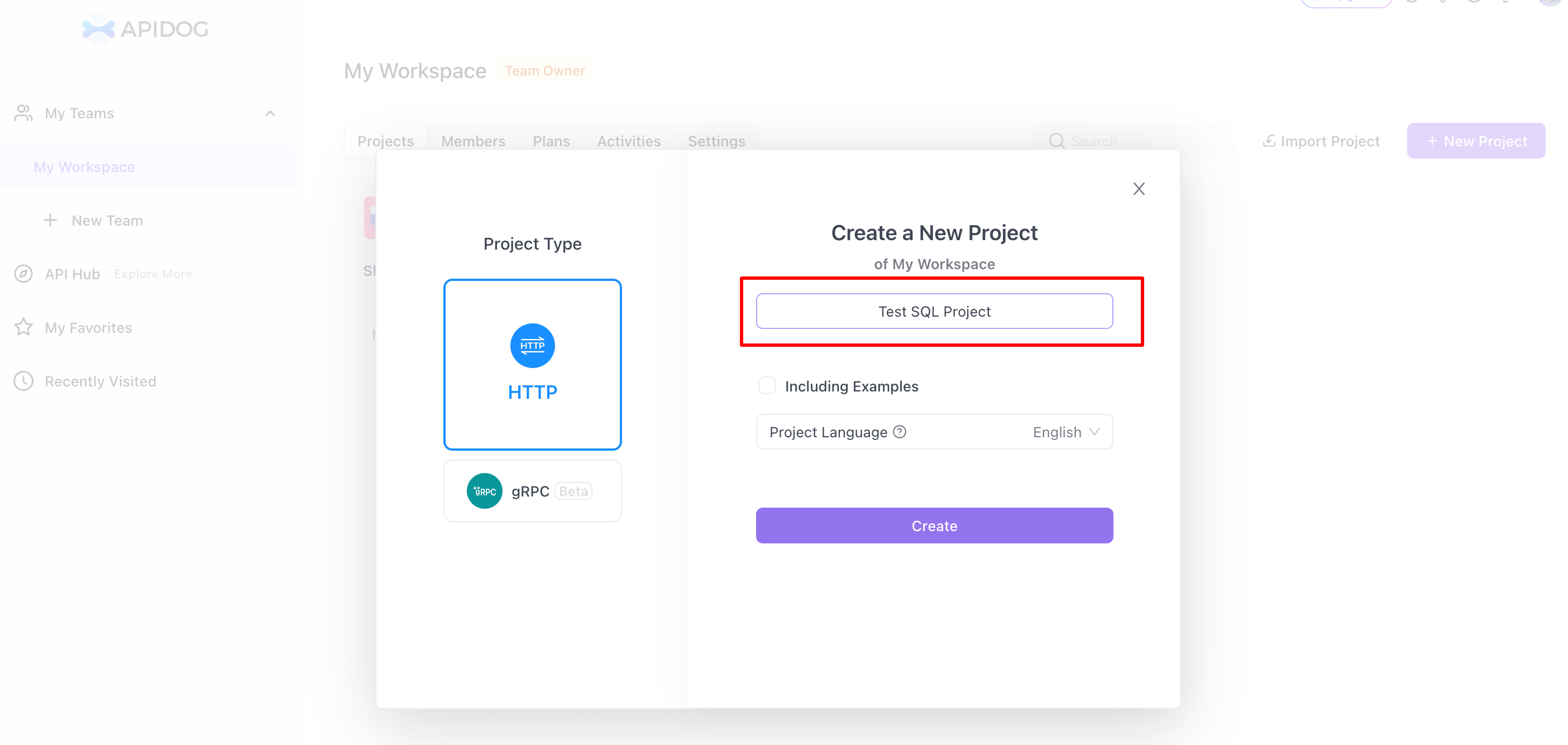
Step 2: Create a New Project
- New Project: In Apidog, go to the 'My Workspace' section, select 'New Project', and choose 'HTTP' as the type. Enter a name for your project.
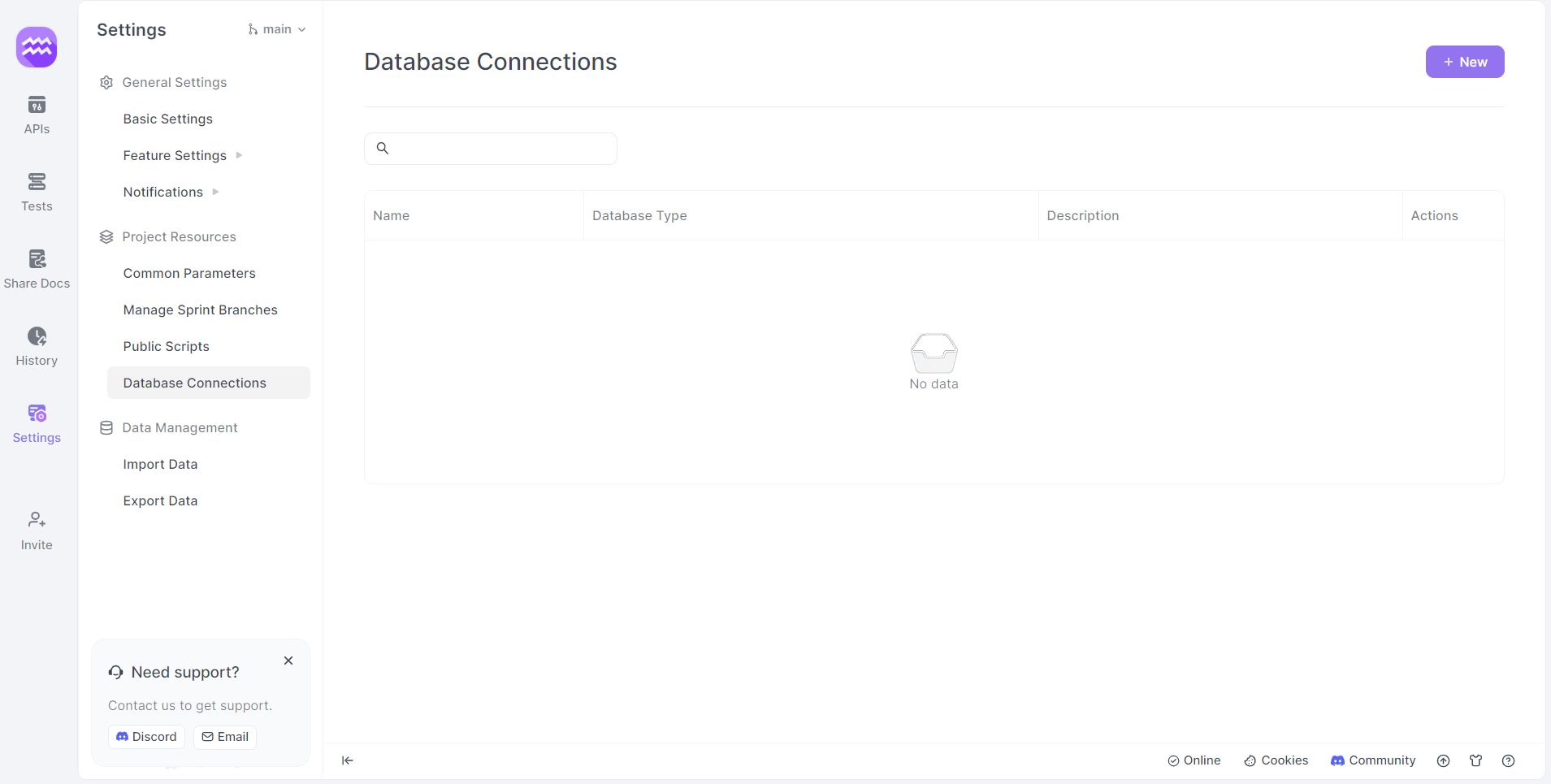
Step 3: Access Database Connections
- Settings: Click on the settings option in the side menu.
- Database Connections: Navigate to the 'Database Connections' menu.
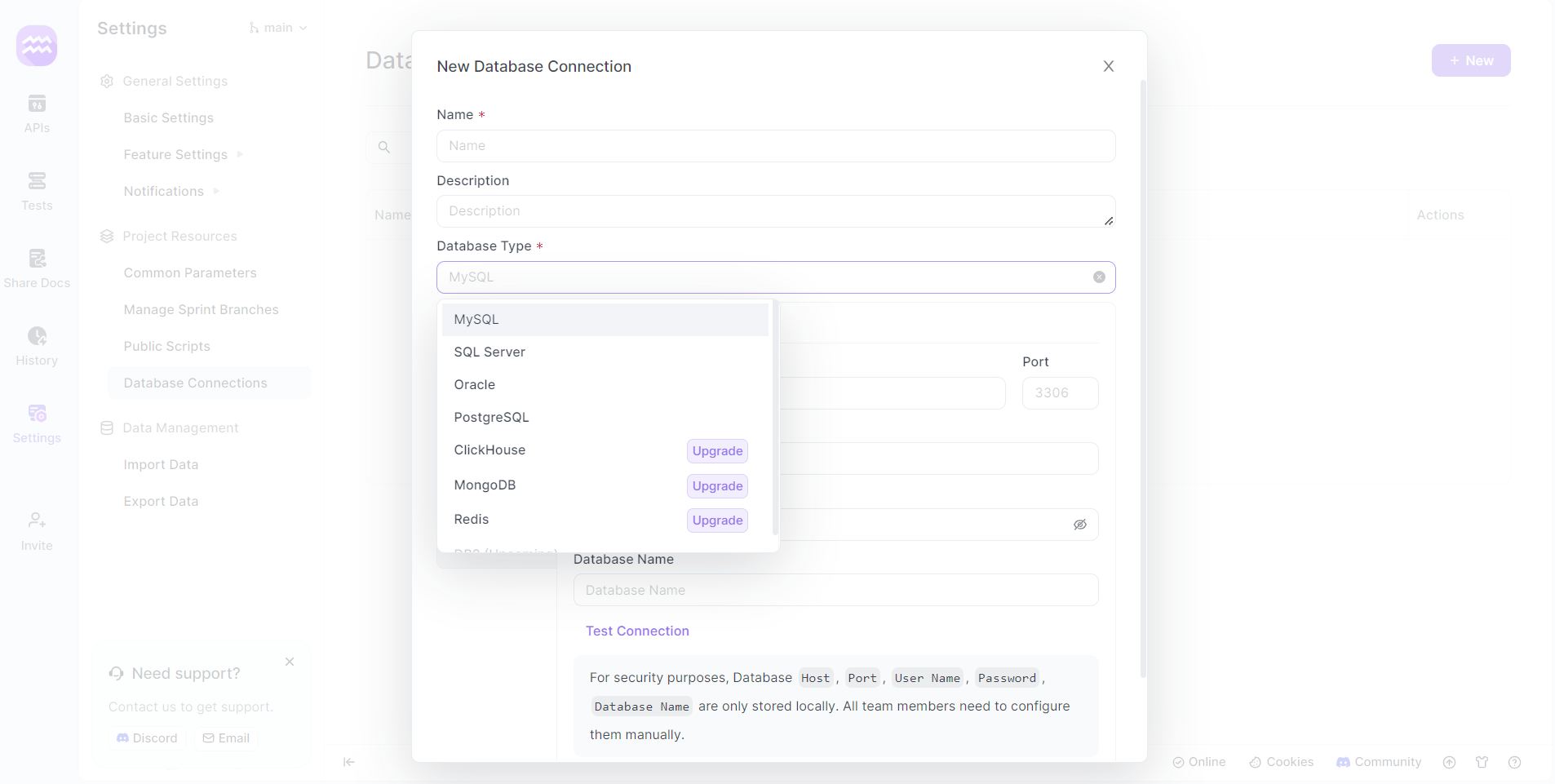
Step 4: Set Up a New Connection
- Add Connection: Click on '+ New' to create a new database connection. A new window will appear for setup.
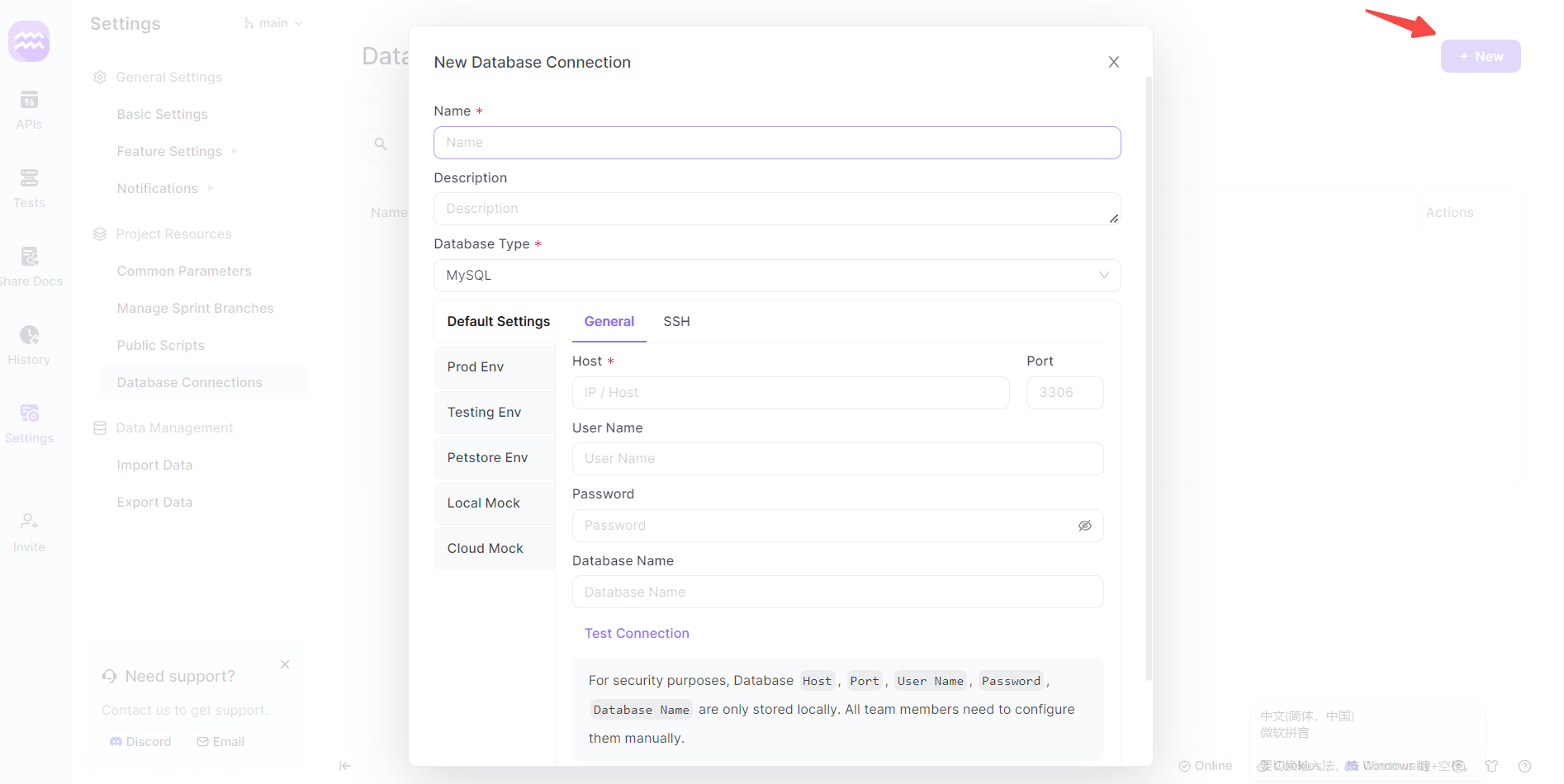
Step 5: Configure SQL Server Connection
- Connection Details: Provide a name for your database connection and select 'SQL Server' as the database type.
- Server Details: Enter the Host, Port, and other relevant details specific to your SQL Server instance.
- Authentication: Use the appropriate SQL Server username and password. Typically, this might be an admin account like 'sa' or a user-specific account.
- Test Connection: Click the 'test connection' button to verify if the setup is successful.
Step 6: Define API Endpoints
- Set Endpoints: Specify URLs for data send/receive operations of your app, marking the operation type (GET, POST, PUT, DELETE).
- Configure Processors: Define any pre-processors or post-processors for different database operations.
Step 7: Test and Validate
- API Testing: Utilize Apidog's tools to test each endpoint. The editor will highlight any errors.
- Debug and Retest: Investigate any issues, make corrections, and retest until the APIs function as expected.
Conclusion
In conclusion, GraphQL and SQL cater to different aspects of data handling and retrieval. GraphQL stands out in scenarios requiring flexible, client-specific queries and real-time data, making it a popular choice for modern web APIs.
SQL, on the other hand, remains the cornerstone for structured data manipulation in relational databases, excelling in complex data querying and transactional integrity. Understanding their distinct characteristics helps in choosing the right technology based on the specific requirements of a project.


