
The gpt-oss-safeguard models from OpenAI address this need by enabling policy-based reasoning for classification tasks. Engineers integrate these models to classify user-generated content, detect violations, and maintain platform integrity.
Understanding GPT-OSS-Safeguard: Features and Capabilities
OpenAI engineers developed gpt-oss-safeguard as open-weight reasoning models tailored for safety classification. They fine-tune these models from the gpt-oss base, releasing them under the Apache 2.0 license. Developers download the models from Hugging Face and deploy them freely. The lineup includes gpt-oss-safeguard-20b and gpt-oss-safeguard-120b, where the numbers indicate parameter scales.
These models process two primary inputs: a developer-defined policy and the content for evaluation. The system applies chain-of-thought reasoning to interpret the policy and classify the content. For instance, it determines whether a user message violates rules on cheating in gaming forums. This approach allows dynamic policy updates without retraining, which traditional classifiers demand.
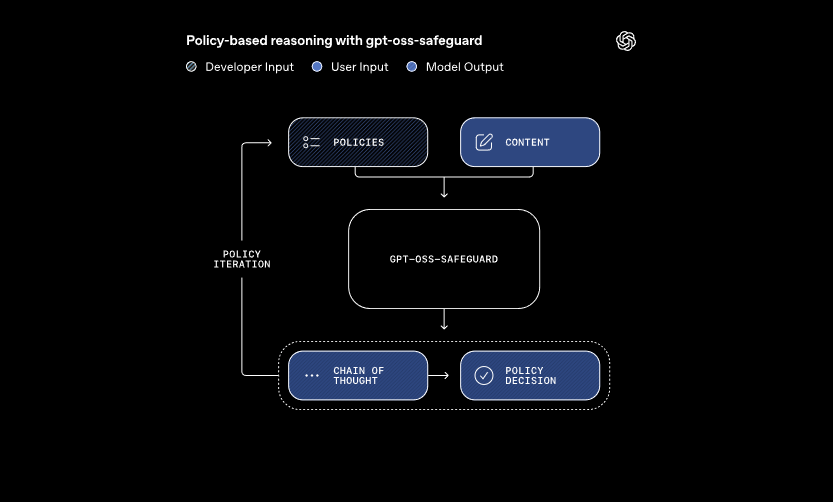
Moreover, gpt-oss-safeguard supports multiple policies simultaneously. Developers feed several rules into a single inference call, and the model evaluates content against all of them. This capability streamlines workflows for platforms handling diverse risks, such as misinformation or harmful speech. However, performance may dip slightly with added policies, so teams test configurations thoroughly.
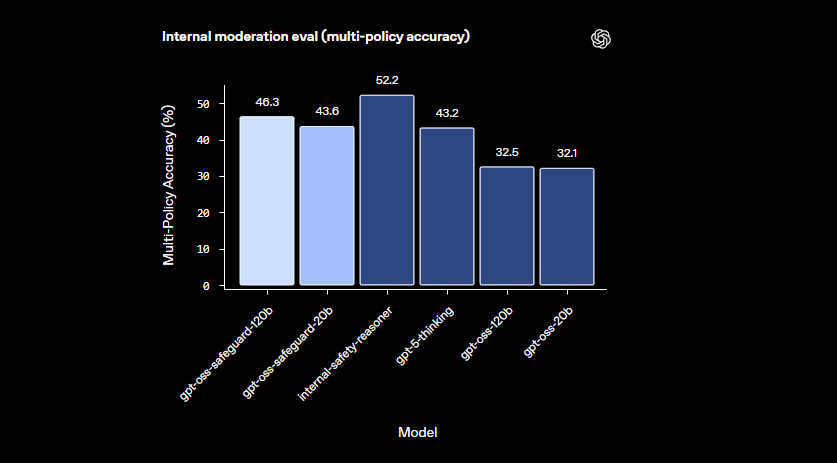
The models excel in nuanced domains where smaller classifiers falter. They handle emerging harms by adapting to revised policies quickly. Additionally, the chain-of-thought output provides transparency—developers review the reasoning trace to audit decisions. This feature proves invaluable for compliance teams requiring explainable AI.
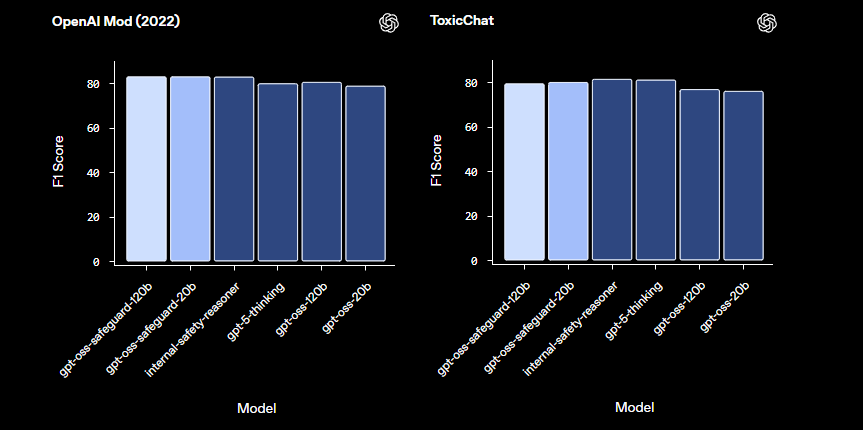
In comparison to prebaked safety models like LlamaGuard, gpt-oss-safeguard offers greater customization. It avoids fixed taxonomies, empowering organizations to define their own thresholds. Consequently, integration suits Trust & Safety engineers building scalable moderation pipelines. Now that we grasp the fundamentals, let's proceed to environment setup.
Setting Up Your Environment for GPT-OSS-Safeguard API Access
Developers begin by preparing their systems to run gpt-oss-safeguard. Since the models are open-weight, you deploy them locally or via hosted providers. This flexibility accommodates various hardware setups, from personal machines to cloud servers.
First, install necessary dependencies. Python 3.10 or higher serves as the base. Use pip to add libraries like Hugging Face Transformers: pip install transformers. For accelerated inference, include torch with CUDA support if you own a compatible GPU. Engineers with NVIDIA hardware enable this for faster processing.
Next, download the models from Hugging Face. Access the collection. Select gpt-oss-safeguard-20b for lighter resource needs or gpt-oss-safeguard-120b for superior accuracy. The command transformers-cli download openai/gpt-oss-safeguard-20b retrieves the files.
To expose an API, run a local server. Tools like vLLM handle this efficiently. Install vLLM with pip install vllm. Then, launch the server: vllm serve openai/gpt-oss-safeguard-20b. This command starts an OpenAI-compatible endpoint at http://localhost:8000/v1. Similarly, Ollama simplifies deployment: ollama run gpt-oss-safeguard:20b. It provides REST APIs for integration.
For local testing, LM Studio offers a user-friendly interface. Execute lms get openai/gpt-oss-safeguard-20b to fetch the model. The software emulates OpenAI's Chat Completions API, allowing seamless code transitions to production.
Hosted options eliminate hardware concerns. Providers like Groq support gpt-oss-safeguard-20b through their API. Sign up at https://console.groq.com, generate an API key, and target the model in requests. Pricing starts at $0.075 per million input tokens. OpenRouter also hosts it.
Once set up, verify the installation. Send a test request via curl: curl http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" -d '{"model": "openai/gpt-oss-safeguard-20b", "messages": [{"role": "system", "content": "Test policy"}, {"role": "user", "content": "Test content"}]}'. A successful response confirms readiness. With the environment configured, you craft policies next.
Crafting Effective Policies for GPT-OSS-Safeguard
Policies form the backbone of gpt-oss-safeguard operations. Developers write them as structured prompts that guide classification. A well-designed policy maximizes the model's reasoning power, ensuring accurate and explainable outputs.
Structure your policy with distinct sections. Begin with Instructions, specifying the model's tasks. For example, direct it to classify content as violating (1) or safe (0). Follow with Definitions, clarifying key terms like "dehumanizing language." Then, outline Criteria for violations and safe content. Finally, include Examples—provide 4-6 borderline cases labeled accordingly.
Use active voice in policies: "Flag content that promotes violence" instead of passive alternatives. Keep language precise; avoid ambiguities like "generally unsafe." If conflicts arise between rules, define precedence explicitly. For multi-policy scenarios, concatenate them in the system message.
Control reasoning depth via the "reasoning_effort" parameter: set it to "high" for complex cases or "low" for speed. The harmony format, built into gpt-oss-safeguard, separates reasoning from final output. This ensures clean API responses while preserving audit trails.
Optimize policy length around 400-600 tokens. Shorter policies risk oversimplification, while longer ones may confuse the model. Test iteratively: classify sample content and refine based on outputs. Tools like token counters in Hugging Face assist here.
For output formats, choose binary for simplicity: Return exactly 0 or 1. Add rationale for depth: {"violation": 1, "rationale": "Explanation here"}. This JSON structure integrates easily with downstream systems. As you refine policies, transition to API implementation.
Implementing API Calls with GPT-OSS-Safeguard
Developers interact with gpt-oss-safeguard through OpenAI-compatible endpoints. Whether local or hosted, the process follows standard chat completion patterns.
Prepare your client. In Python, import OpenAI: from openai import OpenAI. Initialize with the base URL and key: client = OpenAI(base_url="http://localhost:8000/v1", api_key="dummy") for local, or provider-specific values.
Construct messages. The system role holds the policy: {"role": "system", "content": "Your detailed policy here"}. The user role contains content: {"role": "user", "content": "Content to classify"}.
Call the API: completion = client.chat.completions.create(model="openai/gpt-oss-safeguard-20b", messages=messages, max_tokens=500, temperature=0.0). Temperature at 0 ensures deterministic outputs for safety tasks.
Parse the response: result = completion.choices[0].message.content. For structured outputs, use JSON parsing. Groq enhances this with prompt caching—reuse policies across calls to cut costs by 50%.
Handle streaming for real-time feedback: set stream=True and iterate over chunks. This suits high-volume moderation.
Incorporate tools if needed, though gpt-oss-safeguard focuses on classification. Define functions in the tools parameter for extended capabilities, like fetching external data.
Monitor token usage: input includes policy plus content, outputs add reasoning. Limit max_tokens to prevent overflows. With calls mastered, explore examples.
Advanced Features in GPT-OSS-Safeguard API
gpt-oss-safeguard offers advanced tools for refined control. Prompt caching on Groq reuses policies, reducing latency and costs.
Adjust reasoning_effort in the system message: "Reasoning: high" for deep analysis. This handles ambiguous content better.
Leverage the 128k context window for long chats or documents. Feed entire conversations for holistic classification.
Integrate with larger systems: Pipe outputs to escalation queues or logging. Use webhooks for real-time alerts.
Fine-tune further if needed, though the base excels at policy following. Combine with smaller models for pre-filtering, optimizing compute.
Security matters: Secure API keys and monitor for prompt injections. Validate inputs to prevent exploits.
Scaling: Deploy on clusters with vLLM for high throughput. Providers like Groq deliver 1000+ tokens/second.
These features elevate gpt-oss-safeguard from basic classifier to enterprise tool. However, follow best practices for optimal results.
Best Practices and Optimization for GPT-OSS-Safeguard
Engineers optimize gpt-oss-safeguard by iterating on policies. Test with diverse datasets, measuring accuracy via metrics like F1-score.
Balance model size: Use 20b for speed, 120b for precision. Quantize weights to reduce memory footprint.
Monitor performance: Log reasoning traces for audits. Adjust temperature minimally—0.0 suits deterministic needs.
Handle limitations: The model may struggle with highly specialized domains; supplement with domain data.
Ensure ethical use: Align policies with regulations. Avoid biases by diversifying examples.
Update regularly: As OpenAI evolves gpt-oss-safeguard, incorporate improvements.
Cost management: For hosted APIs, track token spends. Local deployments minimize expenses.
By applying these practices, you maximize efficiency. In summary, gpt-oss-safeguard empowers robust safety systems.
Conclusion: Integrating GPT-OSS-Safeguard into Your Workflow
Developers harness gpt-oss-safeguard to build adaptable safety classifiers. From setup to advanced usage, this guide equips you with technical knowledge. Implement policies, execute API calls, and optimize for your needs. As platforms evolve, gpt-oss-safeguard adapts seamlessly, ensuring secure environments.


