
Developers constantly seek powerful tools to build intelligent applications. OpenAI addresses this need with the release of GPT-OSS, a series of open-weight language models that provide advanced reasoning capabilities. These models, including gpt-oss-120b and gpt-oss-20b, allow customization and deployment in various environments. Users access them through APIs provided by hosting platforms, enabling seamless integration into projects.
To start working with the GPT-OSS API, developers obtain access via providers such as OpenRouter or Together AI. These platforms host the models and expose standard endpoints compatible with OpenAI's API format. This compatibility simplifies migration from proprietary models.
What Is GPT-OSS? Key Features and Capabilities
OpenAI designs GPT-OSS as a family of Mixture-of-Experts (MoE) models. This architecture activates only a subset of parameters per token, boosting efficiency. For example, gpt-oss-120b features 117 billion total parameters but activates just 5.1 billion per token. Similarly, gpt-oss-20b uses 21 billion parameters with 3.6 billion active.
The models employ Transformer-based structures with alternating dense and sparse attention layers. They incorporate Rotary Positional Embeddings (RoPE) for handling long contexts up to 128,000 tokens. Developers benefit from this in applications requiring extensive input, such as document summarization.
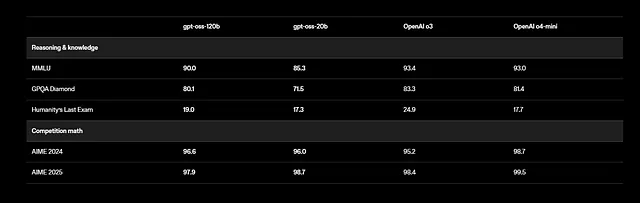
Moreover, GPT-OSS supports multilingual tasks, though training focuses on English with emphasis on STEM and coding data. Benchmarks show impressive results: gpt-oss-120b scores 94.2% on MMLU (Massive Multitask Language Understanding) and 96.6% on AIME (American Invitational Mathematics Examination). It outperforms models like o4-mini in health-related queries and competition math.
Developers utilize tool calling features, where the model invokes external functions like web search or code execution. This agentic capability enables building autonomous systems. For instance, the model chains multiple tool calls in a single response to solve problems step by step.
Additionally, the models adhere to the Apache 2.0 license, allowing free modification and deployment. OpenAI provides weights on Hugging Face, quantized in MXFP4 format for reduced memory usage. Users run them locally or via cloud providers.
However, safety considerations apply. OpenAI conducts evaluations under its Preparedness Framework, testing for risks like misinformation. Developers implement safeguards, such as filtering outputs, to mitigate issues.
In essence, GPT-OSS combines power with accessibility. Its open nature encourages community contributions, leading to rapid improvements. Next, identify providers that offer API access to these models.
Choosing Providers for GPT-OSS API Access
Several platforms host GPT-OSS models and provide API endpoints. Developers select based on needs like speed, cost, and scalability. OpenRouter, for example, offers gpt-oss-120b with competitive pricing and easy integration.
Together AI provides another option, emphasizing enterprise-ready deployments. It supports the model through a /v1/chat/completions endpoint, compatible with OpenAI clients. Developers send JSON payloads specifying messages, max_tokens, and temperature.
Furthermore, Fireworks AI and Cerebras deliver high-speed inference. Cerebras achieves up to 3,000 tokens per second, ideal for real-time applications. Pricing varies: OpenRouter charges around $0.15 per million input tokens, while Together AI offers similar rates with volume discounts.
Developers also consider self-hosting for privacy. Tools like vLLM or Ollama allow running GPT-OSS on local servers, exposing an API. For instance, vLLM serves the model with OpenAI-compatible routes, requiring a single command to start.
However, cloud providers simplify scaling. AWS, Azure, and Vercel integrate GPT-OSS via partnerships with OpenAI. These options handle load balancing and auto-scaling automatically.
Additionally, evaluate latency. gpt-oss-20b suits edge devices with lower requirements, while gpt-oss-120b demands GPUs like NVIDIA H100. Providers optimize for hardware, ensuring consistent performance.
In short, the right provider aligns with project goals. Once chosen, proceed to obtain API credentials.
Obtaining API Access and Setting Up Your Environment
Developers begin by registering on a provider's site. For OpenRouter, visit openrouter.ai, create an account, and navigate to the Keys section. Generate a new API key, naming it for reference, and copy it securely.
Next, install client libraries. In Python, use pip to add openai: pip install openai. Configure the client with the base URL and key. For example:
from openai import OpenAI
client = OpenAI(
base_url="https://openrouter.ai/api/v1",
api_key="your_api_key_here"
)
This setup allows sending requests to gpt-oss models.
Furthermore, for Together AI, use their SDK: pip install together. Initialize with:
import together
together.api_key = "your_together_api_key"
Test the connection by listing models or sending a simple query.
However, verify hardware if self-hosting. Download weights from Hugging Face: huggingface-cli download openai/gpt-oss-120b. Then, use vLLM to serve: vllm serve openai/gpt-oss-120b.
Additionally, set environment variables for security. Store keys in .env files and load them with dotenv library.
In case of issues, check provider docs for rate limits or authentication errors. This preparation ensures smooth API interactions.
Making Your First API Call to GPT-OSS
Developers craft requests using the chat completions endpoint. Specify the model, such as "openai/gpt-oss-120b", in the payload.
For a basic call, prepare messages as a list of dictionaries. Each includes role (system, user, assistant) and content.
Here’s an example in Python:
completion = client.chat.completions.create(
model="openai/gpt-oss-120b",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain quantum superposition."}
],
max_tokens=200,
temperature=0.7
)
print(completion.choices[0].message.content)
This generates a response explaining the concept technically.
Furthermore, adjust parameters for control. Temperature influences creativity – lower values yield deterministic outputs. Top_p limits token sampling, while presence_penalty discourages repetition.
Next, incorporate tool calling. Define tools in the request:
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string", "description": "The city and state, e.g. San Francisco, CA"},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]}
},
"required": ["location"]
}
}
}
]
completion = client.chat.completions.create(
model="openai/gpt-oss-120b",
messages=[{"role": "user", "content": "What's the weather like in Boston?"}],
tools=tools,
tool_choice="auto"
)
The model responds with a tool call, which developers execute and feed back.
However, handle responses carefully. Parse the JSON for content, finish_reason, and usage stats like token counts.
Additionally, for chain-of-thought, prompt with "Think step by step." Set reasoning effort in system messages: "reasoning_effort: medium".
Experiment with gpt-oss-20b for faster tests: Replace the model name in calls.
In advanced scenarios, stream responses using stream=True for real-time output.
These steps build foundational skills. Now, integrate testing tools like Apidog.
Integrating Apidog for Efficient GPT-OSS API Testing
Developers rely on Apidog to test and debug API interactions. This tool provides a user-friendly interface for sending requests to gpt-oss endpoints.
First, install Apidog from their website. Create a new project and add an API endpoint, such as https://openrouter.ai/api/v1/chat/completions.
Next, configure headers: Add Authorization with Bearer token and Content-Type as application/json.
Furthermore, build the request body. Use Apidog's JSON editor to input model, messages, and parameters. For example, test a gpt-oss call for code generation.
Apidog visualizes responses, highlighting errors or successes. It supports environment variables for switching API keys between providers.
However, leverage collections to organize tests. Group GPT-OSS queries by task, like reasoning or tool use, and run them in batches.
Additionally, Apidog generates code snippets in languages like Python or cURL from your requests, accelerating development.
For collaboration, share projects with teams. This ensures consistent testing of gpt-oss integrations.
In practice, use Apidog to monitor token usage and optimize prompts, reducing costs.
Overall, Apidog enhances productivity when working with the GPT-OSS API.
Advanced Usage: Fine-Tuning and Deployment
Developers fine-tune GPT-OSS for specific domains. Use Hugging Face's transformers library to load weights and train on custom datasets.
For instance, prepare data in JSONL format with prompt-completion pairs. Run fine-tuning scripts from the GitHub repo.
Furthermore, deploy tuned models via vLLM for API serving. This supports production loads with features like dynamic batching.
Next, explore multi-modal extensions. Though text-focused, integrate with vision models for hybrid apps.
However, monitor for overfitting during fine-tuning. Use validation sets and early stopping.
Additionally, scale with distributed inference on clusters. Providers like AWS offer managed options.
In agentic setups, chain GPT-OSS with external APIs for workflows like automated research.
These techniques expand capabilities beyond basic calls.
Best Practices, Limitations, and Troubleshooting
Developers follow best practices for optimal results. Craft clear prompts, use few-shot examples, and iterate based on outputs.
Furthermore, respect rate limits – check provider dashboards to avoid throttling.
However, acknowledge limitations: GPT-OSS may hallucinate, so validate critical responses. It lacks real-time knowledge updates.
Additionally, secure API keys and log usage for cost control.
Troubleshoot by reviewing error codes; 401 indicates invalid auth, 429 means rate limit hit.
In summary, adhere to these guidelines for reliable performance.
Conclusion: Empower Your Projects with GPT-OSS API
Developers now possess the tools to integrate GPT-OSS effectively. From setup to advanced features, this guide equips you for success. Experiment, refine, and innovate with gpt-oss and Apidog to create impactful AI solutions.


