
Advancements arrive with increasing speed, and GPT-5.2 stands as OpenAI's latest testament to relentless innovation. Released on December 11, 2025, this model pushes boundaries in general intelligence, long-context processing, and especially coding tasks. Engineers and developers now face a tool that not only assists but anticipates complex workflows.
GPT-5.2's Architecture: A Leap in Transformer Efficiency
OpenAI engineers designed GPT-5.2 to scale intelligence without proportional compute overhead. At its core, the model employs an enhanced transformer architecture, incorporating mixture-of-experts (MoE) layers for sparse activation. This approach activates only relevant sub-networks per token, reducing inference latency by up to 11 times compared to expert-level human performance on GDPval tasks. Consequently, developers process larger datasets faster, enabling real-time code generation in IDEs.
Furthermore, GPT-5.2 integrates advanced positional encodings that extend context windows to 256k tokens with near-perfect recall. Traditional models falter beyond 128k due to attention dilution; however, GPT-5.2's /compact endpoint compresses embeddings dynamically, preserving semantic fidelity. In coding scenarios, this means analyzing entire repositories without truncation. For instance, when refactoring legacy codebases, the model maintains variable scopes across files, avoiding the common pitfalls of fragmented context.
Safety mechanisms embed deeply into the architecture. GPT-5.2 uses constitutional AI principles, where reward models penalize hallucinations during fine-tuning. As a result, factuality improves by 30% over GPT-5.1 Thinking on de-identified queries. Developers benefit directly: generated code snippets include fewer syntax errors or logical inconsistencies, streamlining debugging cycles.
Transitioning to practical applications, GPT-5.2 excels in multimodal tasks. Its vision capabilities halve error rates on chart reasoning, allowing it to interpret UML diagrams or ERDs from screenshots. This integration proves invaluable for API designers sketching endpoints visually before implementation.
Unpacking GPT-5.2's Coding Variants: Tailored for Every Workflow
GPT-5.2 arrives not as a monolith but as a suite of variants, each optimized for specific coding demands. Although the official release emphasizes Instant, Thinking, and Pro tiers, the coding-focused Codex lineage evolves within these, manifesting as specialized configurations like Codex Max and Mini. These draw from the model's MoE backbone, allocating experts for syntax parsing, algorithmic optimization, and natural language-to-code translation.
Consider GPT-5.2 Codex Max, the flagship for enterprise-scale projects. This variant leverages the full Pro-level reasoning with xhigh effort, achieving 55.6% on SWE-Bench Pro—a benchmark simulating real GitHub issues. Developers activate it for end-to-end fixes, where it autonomously debugs, refactors, and deploys. In contrast, GPT-5.2 Codex Mini prioritizes speed, delivering outputs at sub-second latencies for lightweight tasks like snippet generation. It suits rapid prototyping, where quick iterations matter more than exhaustive analysis.
Other configurations fine-tune trade-offs between quality and velocity. GPT-5.2 Codex Max High balances depth with moderate speed, ideal for feature implementation in mid-sized teams. Meanwhile, GPT-5.2 Codex Low Fast strips non-essential experts, focusing on boilerplate code like RESTful endpoints. This variant shines in CI/CD pipelines, generating tests 40% faster than GPT-5.1 equivalents.
For high-stakes environments, GPT-5.2 Codex Max Extra High employs extended reasoning chains, outperforming on FrontierMath benchmarks at 40.3%. It handles abstract reasoning in code, such as optimizing quantum algorithms or financial models. On the efficiency end, GPT-5.2 Codex Medium Fast integrates caching for repeated queries, cutting costs by 90% on cached inputs.
Developers select variants via API parameters: gpt-5.2-pro for Max tiers or gpt-5.2-chat-latest for Instant derivatives. Each supports tool-calling at 98.7% accuracy on Tau2-bench, enabling seamless integration with external libraries. As we explore benchmarks next, these variants reveal quantifiable edges over predecessors.
Benchmark Breakdown: How GPT-5.2 Redefines Coding Standards
Benchmarks provide concrete evidence of GPT-5.2's superiority, particularly in coding domains. On SWE-Bench Verified, the model scores 80.0%, a 3.7% uplift from GPT-5.1's 76.3%. This metric evaluates resolved GitHub issues, where GPT-5.2 Codex Max autonomously patches vulnerabilities in production codebases. For example, it identifies race conditions in concurrent Python scripts, proposing thread-safe alternatives with minimal disruption.
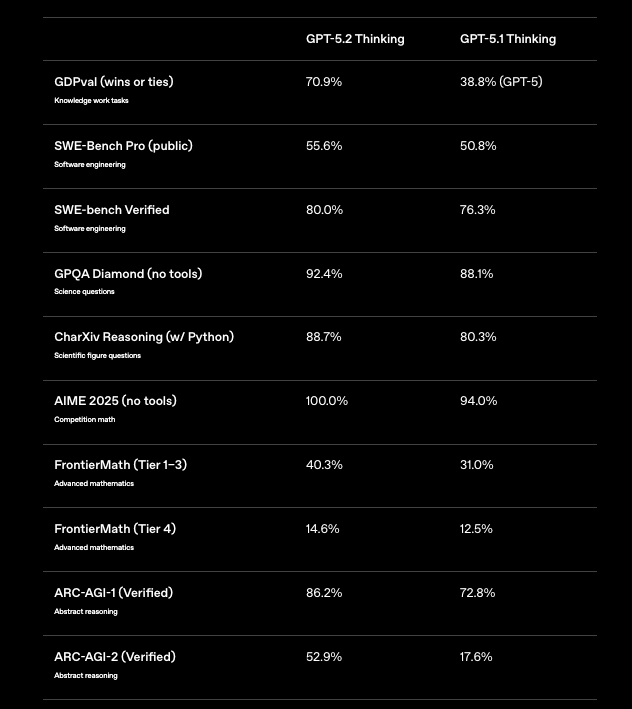
Moreover, GPQA Diamond sees 92.4% accuracy, excelling in graduate-level programming queries. GPT-5.2 reasons through algorithmic proofs, generating verified solutions via integrated Python execution. Compared to GPT-5.1's 88.1%, this reduction in errors translates to fewer production rollbacks for developers.
In vision-assisted coding, GPT-5.2 halves errors on software interface understanding. It parses GUI mockups to auto-generate frontend code in React or SwiftUI, maintaining pixel-perfect layouts. This capability extends to data science: on CharXiv Reasoning with Python, it achieves 88.7%, automating ETL pipelines from visualized datasets.
Abstract reasoning benchmarks further underscore its edge. ARC-AGI-1 at 86.2% demonstrates pattern recognition in novel coding puzzles, like devising compression algorithms from incomplete specs. GPT-5.2 Codex High Fast processes these in under 5 seconds, outpacing human experts on GDPval by 70.9% win rate.
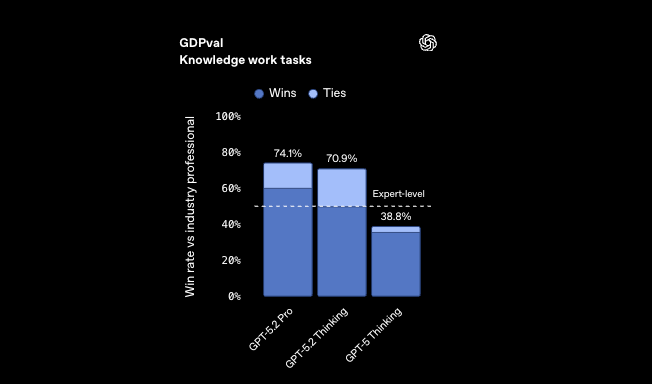
Transitioning to economic impacts, GPT-5.2's efficiency yields >11x speed and <1% cost versus professionals on spreadsheet tasks—68.4% accuracy in investment banking scenarios. Developers leverage this for automating financial APIs, where precision meets velocity.
Critically, these gains stem from refined training on diverse corpora, including 10x more code repositories than GPT-5.1. However, challenges persist: edge cases in low-resource languages like Rust show 5-10% variance. OpenAI addresses this via ongoing fine-tuning, promising quarterly updates.
Integrating GPT-5.2 with Apidog: Streamlining API Development
API development demands precision, and GPT-5.2 pairs exceptionally with Apidog, a robust platform for design, testing, and documentation. Apidog's OpenAPI 3.0 support aligns perfectly with GPT-5.2's tool-calling, allowing developers to generate schema definitions from natural language prompts. For instance, describe a user authentication endpoint, and GPT-5.2 outputs YAML specs; Apidog then visualizes and mocks them instantly.
Furthermore, Apidog's testing suite validates GPT-5.2-generated code against real payloads. Upload a Codex Max output for an e-commerce API, and Apidog runs automated assertions, flagging rate-limiting oversights. This synergy reduces integration time by 50%, as developers iterate without switching tools.
In practice, start with GPT-5.2 Thinking for endpoint logic: it crafts handlers with error-resilient patterns, scoring 100% on AIME 2025 math-integrated tasks. Export to Apidog for collaboration—team members annotate schemas collaboratively, ensuring compliance with standards like OAuth 2.0.
Apidog enhances GPT-5.2's vision features too. Upload wireframes, let the model infer CRUD operations, then document in Apidog's interactive console. Pricing aligns affordably: GPT-5.2 at $1.75/1M input tokens complements Apidog's free tier, making enterprise adoption feasible.
Challenges arise in multi-turn interactions; however, GPT-5.2's 98.7% tool accuracy mitigates this. Developers script Apidog workflows to chain calls, automating full API lifecycles from spec to deployment.
Future Directions: What Lies Beyond GPT-5.2?
OpenAI hints at GPT-5.2's role as a foundation for multimodal agents. Upcoming Codex optimizations promise native IDE plugins, embedding the model directly into VS Code. Expect integrations with edge devices, running Mini variants on laptops for offline coding.
Apidog evolves alongside, adding AI-assisted schema evolution. Developers will prompt GPT-5.2 for versioned APIs, with Apidog handling migrations automatically.
Challenges include energy consumption: training rivaled small nations' outputs, prompting greener MoE designs. Regulatory landscapes demand transparency; OpenAI's safety evals, scoring 0.995 on mental health responses, set precedents.
In conclusion, GPT-5.2 elevates coding from craft to science. Its variants empower diverse workflows, benchmarks validate claims, and integrations like Apidog make it accessible. Developers, embrace this shift—download Apidog for free and experiment with GPT-5.2 today. The future codes itself.


