Developers constantly seek powerful language models that deliver robust performance across diverse applications. Zhipu AI introduces GLM-4.6, an advanced iteration in the GLM series that pushes boundaries in artificial intelligence capabilities. This model builds on previous versions by incorporating significant enhancements in context handling, reasoning, and practical utility. Engineers integrate GLM-4.6 into their workflows to tackle complex tasks, from code generation to content creation, with greater efficiency and accuracy.
Zhipu AI designs GLM-4.6 as part of the GLM Coding Plan, a subscription-based service that starts at an affordable price point. Users access this model through integrated tools such as Claude Code, Cline, OpenCode, and others, enabling seamless AI-assisted development. The model excels in real-world scenarios, where it processes extensive contexts and generates high-quality outputs. Furthermore, GLM-4.6 demonstrates superior performance in benchmarks, rivaling international leaders like Claude Sonnet 4. This positions it as a top choice for developers in China and beyond who require reliable AI support.
Transitioning from understanding the model's foundation, let's examine its core features and how they benefit technical implementations.
What Is GLM-4.6?
Zhipu AI develops GLM-4.6 as a large language model optimized for a wide array of technical and creative tasks. The model features a 355B-parameter Mixture of Experts (MoE) architecture, which enables efficient computation while maintaining high performance. Users appreciate its expanded context window of 200K tokens, a notable upgrade from the 128K limit in earlier versions. This expansion allows the model to manage intricate, long-form interactions without losing coherence.
In addition, GLM-4.6 supports text input and output modalities, making it versatile for applications that demand precise language processing. The maximum output token limit reaches 128K, providing ample room for detailed responses. Developers leverage these specifications to build systems that handle extensive data, such as document analysis or multi-step reasoning chains.
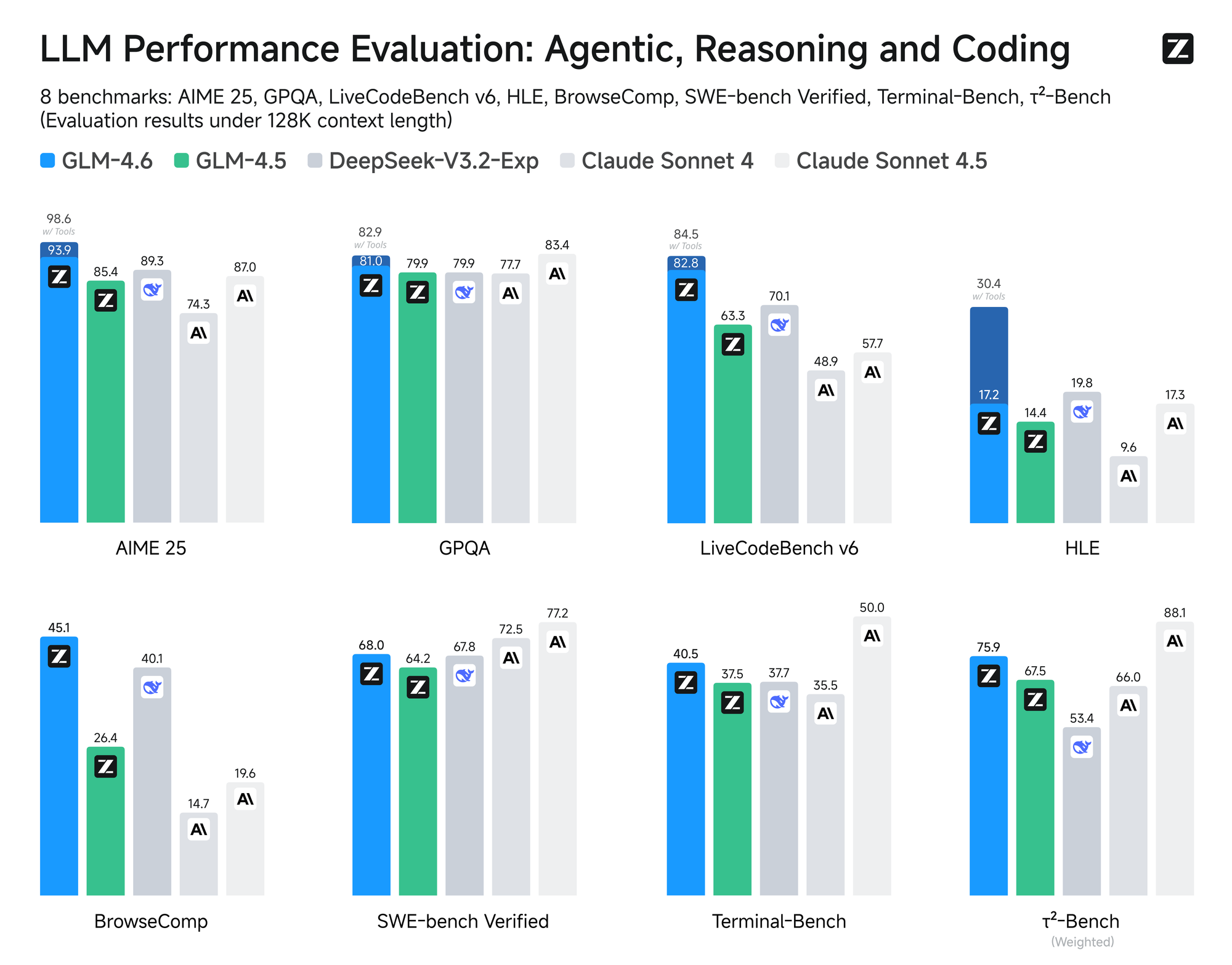
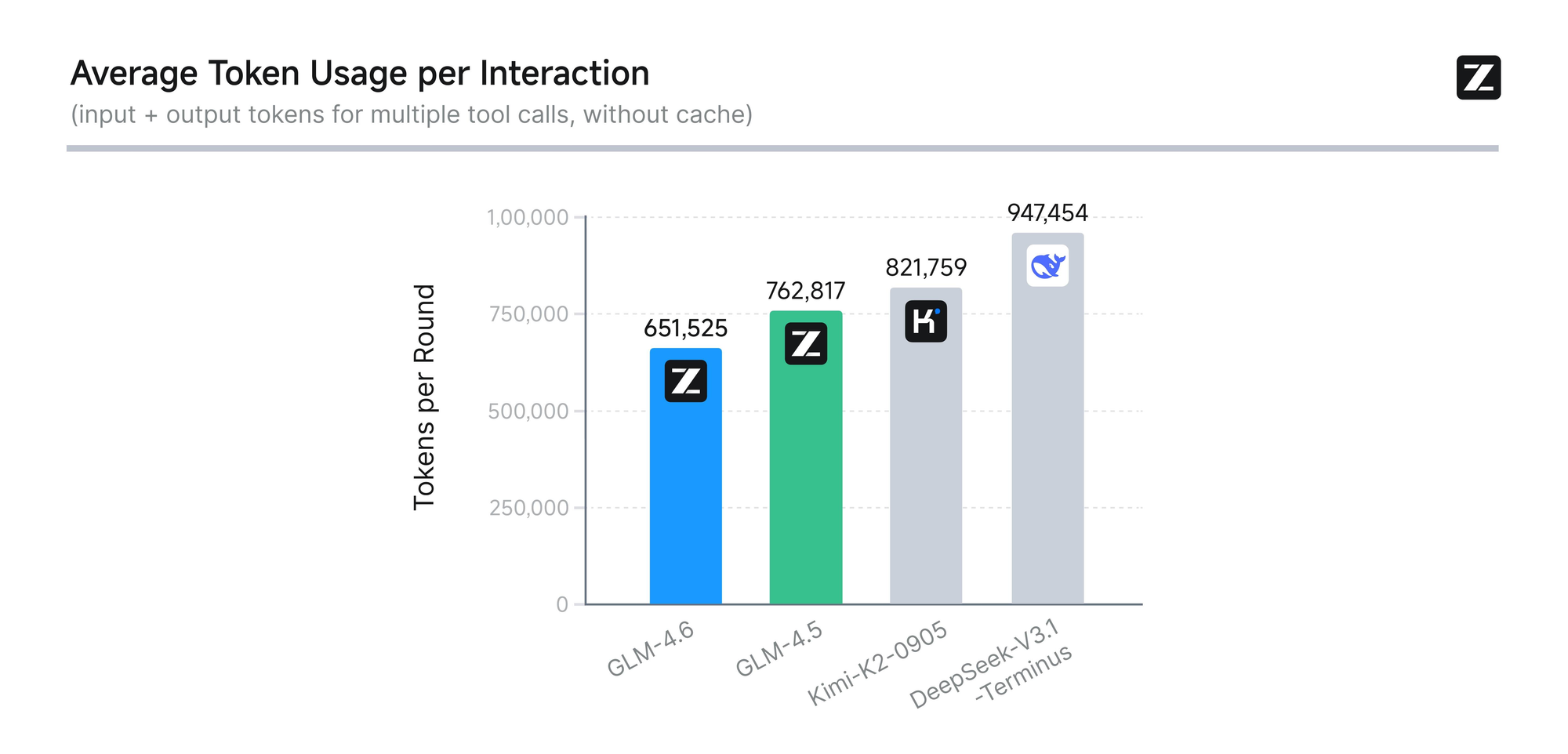
The model undergoes rigorous evaluation across eight authoritative benchmarks, including AIME 25, GPQA, LCB v6, HLE, and SWE-Bench Verified. Results show that GLM-4.6 performs on par with leading models like Claude Sonnet 4 and 4.6. For instance, in real-world coding tests conducted within the Claude Code environment, GLM-4.6 outperforms competitors in 74 practical scenarios. It achieves this with over 30% greater efficiency in token consumption, reducing operational costs for high-volume users.
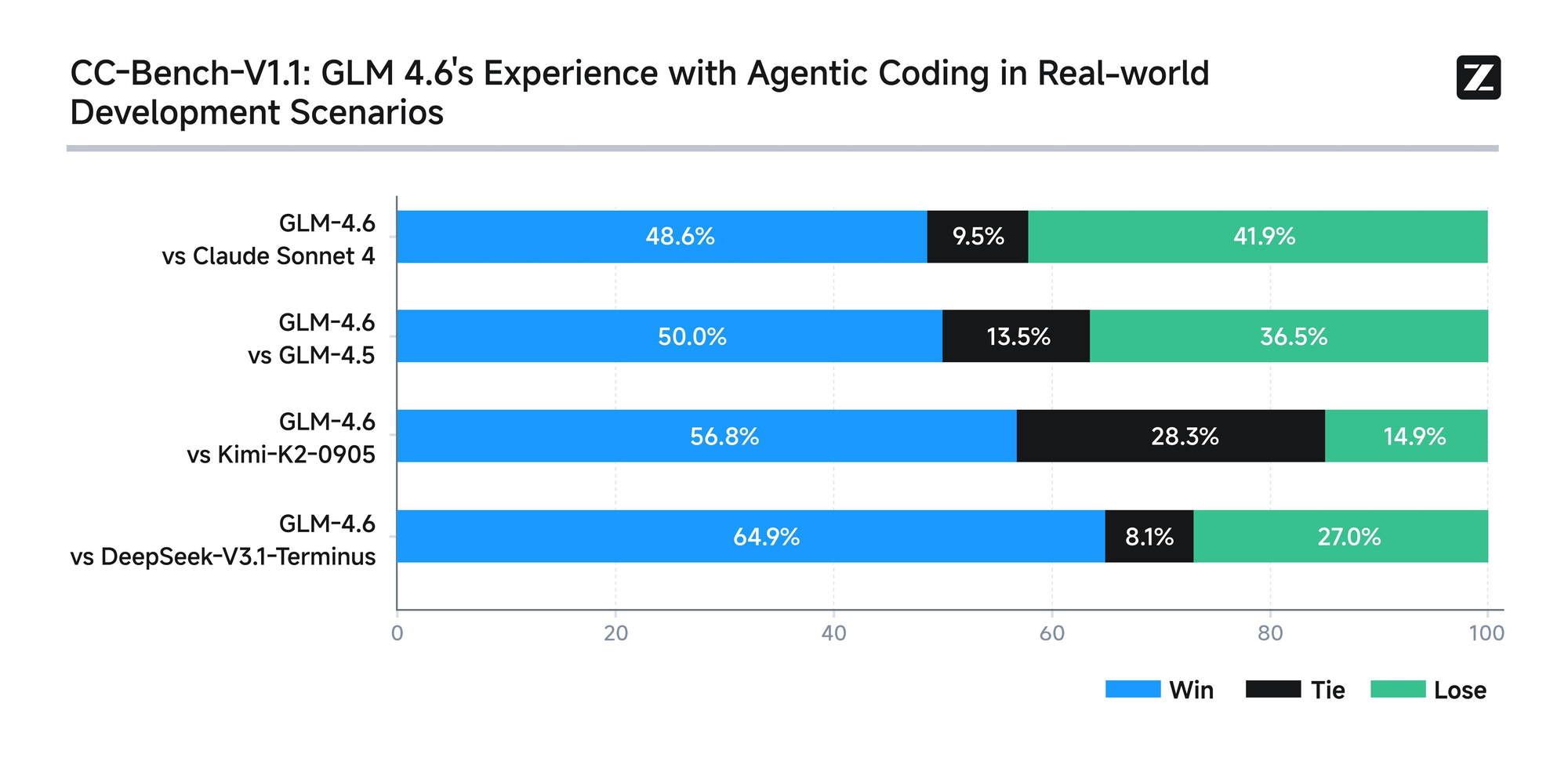
Moreover, Zhipu AI commits to transparency by releasing all test questions and agent trajectories publicly. This practice allows developers to verify claims and reproduce results, fostering trust in the technology. GLM-4.6 also integrates advanced reasoning capabilities, supporting tool use during inference. This feature enhances its utility in agentic frameworks, where the model autonomously plans and executes tasks.
Beyond coding, GLM-4.6 shines in other domains. It refines writing to align closely with human preferences, improving style, readability, and role-playing authenticity. In translation tasks, the model optimizes for minor languages like French, Russian, Japanese, and Korean, ensuring semantic coherence in informal contexts. Content creators use it for novels, scripts, and copywriting, benefiting from contextual expansion and emotional nuance.
Virtual character development represents another strength, as GLM-4.6 maintains consistent tone across multi-turn conversations. This makes it ideal for social AI and brand personification. In intelligent search and deep research, the model enhances intent understanding and result synthesis, delivering insightful outputs.
Overall, GLM-4.6 empowers developers to create smarter applications. Its combination of long-context processing, efficient token usage, and broad applicability sets it apart in the AI landscape. Now that we grasp the model's essence, we move to accessing its API for practical implementation.
How to Access the GLM-4.6 API
Zhipu AI provides straightforward access to the GLM-4.6 API through their open platform. Developers begin by signing up for an account on the Zhipu AI website, specifically at open.bigmodel.cn or z.ai. The process requires verifying an email or phone number to ensure secure registration.
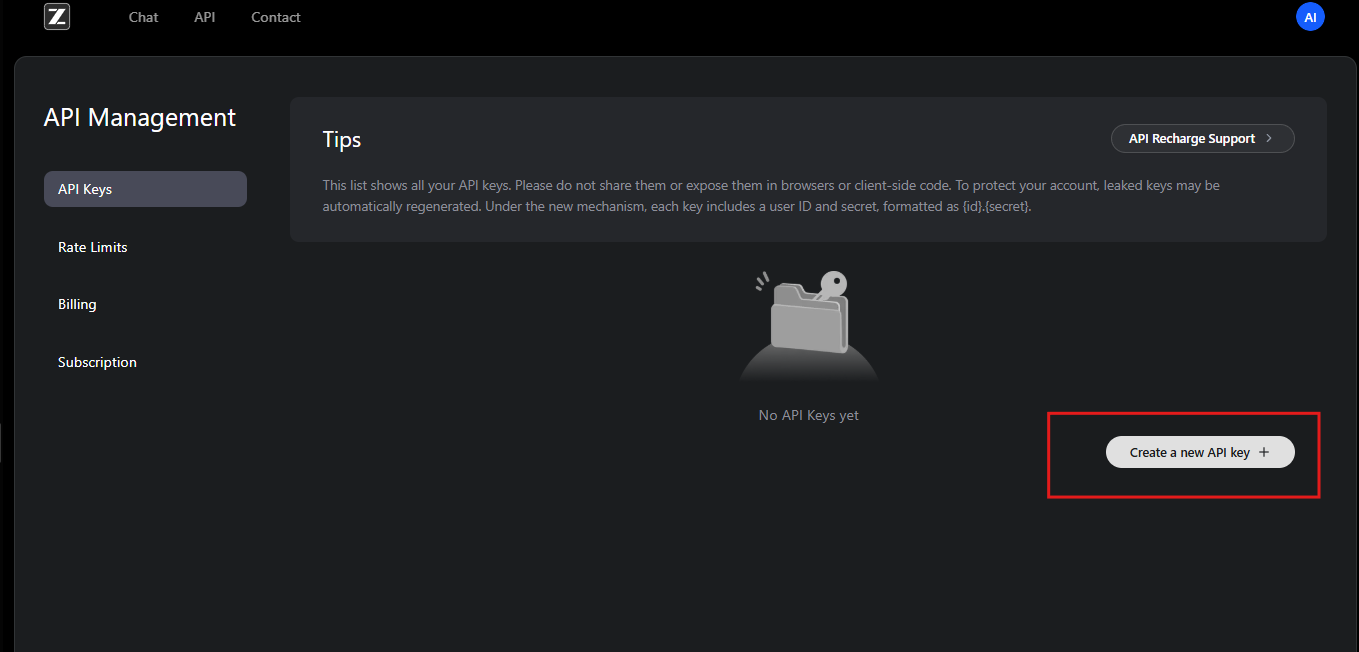
Once registered, users subscribe to the GLM Coding Plan. This plan unlocks GLM-4.6 and related models. Subscribers gain access to the API dashboard, where they generate API keys. These keys serve as credentials for authenticating requests.
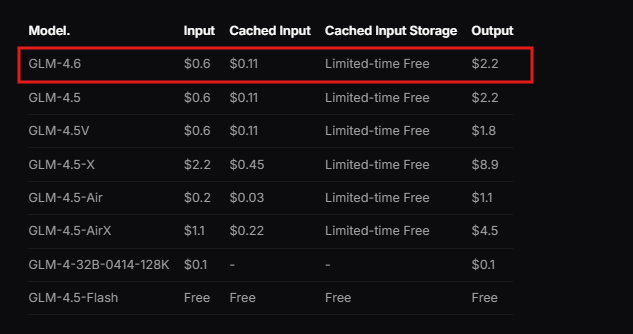
Additionally, Zhipu AI offers documentation, which details integration steps. Developers review this resource to understand prerequisites, such as compatible programming environments. The API follows a RESTful design, compatible with standard HTTP clients.
To start, users navigate to the API management section in their account. Here, they create a new API key and note its value securely. Zhipu AI recommends rotating keys periodically for security. Furthermore, the platform provides usage quotas based on subscription tiers, preventing overuse.
If developers encounter issues, Zhipu AI's support team assists via email or forums. They also offer community resources for troubleshooting common access problems. With access secured, the next step involves setting up authentication to interact with the GLM-4.6 API effectively.
Authentication and Setup for GLM-4.6 API
Authentication forms the backbone of secure API interactions. Zhipu AI employs Bearer token authentication for the GLM-4.6 API. Developers include the API key in the Authorization header of each request.
For setup, install necessary libraries in your development environment. Python users, for example, utilize the requests library. You import it and configure headers as follows:
import requests
api_key = "your-api-key"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
This code prepares the environment for sending requests. Similarly, in JavaScript with Node.js, developers use the fetch API or axios library. They set headers in the options object.
Moreover, ensure your system meets network requirements. The GLM-4.6 API endpoint resides at https://api.z.ai/api/paas/v4/chat/completions. Test connectivity by pinging the domain or sending a simple request.
During setup, developers configure environment variables to store the API key securely. This practice avoids hardcoding sensitive information in scripts. Tools like dotenv in Python or process.env in Node.js facilitate this.
If using a proxy or VPN, verify that it allows traffic to Zhipu AI's servers. Authentication failures often stem from incorrect key formatting or expired subscriptions. Zhipu AI logs errors in responses, helping diagnose issues.
Once authenticated, developers proceed to explore endpoints. This setup ensures reliable, secure access to GLM-4.6's capabilities.
Exploring GLM-4.6 API Endpoints
The GLM-4.6 API centers on a primary endpoint for chat completions. Developers send POST requests to https://api.z.ai/api/paas/v4/chat/completions to generate responses.
This endpoint handles both basic and streaming modes. In basic mode, the server processes the entire request and returns a complete response. Streaming mode, however, delivers output incrementally, ideal for real-time applications.
To invoke the endpoint, construct a JSON payload with required parameters. The model field specifies "glm-4.6". Messages array contains role-content pairs, simulating conversations.
For example, a basic curl request looks like this:
curl -X POST "https://api.z.ai/api/paas/v4/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer your-api-key" \
-d '{
"model": "glm-4.6",
"messages": [
{"role": "user", "content": "Generate a Python function for sorting a list."}
]
}'
The server responds with JSON containing the generated content. Developers parse this to extract assistant messages.
Additionally, the endpoint supports advanced features like thinking steps. Set the thinking object to enable detailed reasoning in outputs.
Understanding this endpoint allows developers to build interactive AI systems. Next, we break down the request parameters in detail.
Detailed Explanation of GLM-4.6 API Request Parameters
Request parameters control the behavior of the GLM-4.6 API. The model parameter mandates "glm-4.6" to select this specific version.
The messages array drives the conversation. Each object includes a role – "user" for inputs, "assistant" for prior responses – and content as text strings. Developers structure multi-turn dialogues by alternating roles.
Furthermore, max_tokens limits the response length, preventing excessive output. Set it to 4096 for balanced results. Temperature adjusts randomness; lower values like 0.6 yield deterministic outputs, while higher ones encourage creativity.
For streaming, include "stream": true. This changes the response format to chunked data.
The thinking parameter enables step-by-step reasoning. Set "thinking": {"type": "enabled"} to include intermediate thoughts in responses.
Other optional parameters include top_p for nucleus sampling and presence_penalty to discourage repetition. Developers tune these based on use cases.
Invalid parameters trigger error responses with codes like 400 for bad requests. Always validate payloads before sending.
By mastering these parameters, developers customize GLM-4.6 API calls for optimal performance.
Handling Responses from the GLM-4.6 API
Responses from the GLM-4.6 API arrive in JSON format. Developers parse the choices array to access generated content.
In basic mode, the response includes:
{
"id": "chatcmpl-...",
"object": "chat.completion",
"created": 1694123456,
"model": "glm-4.6",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Your generated text here."
},
"finish_reason": "stop"
}
]
}
Extract the content field for use in applications.
In streaming mode, responses stream as Server-Sent Events (SSE). Each chunk follows:
data: {"id":"chatcmpl-...","choices":[{"delta":{"content":" partial text"}}]}
Developers accumulate deltas to build the full output.
Error handling involves checking status codes. A 401 indicates authentication failure, while 429 signals rate limits.
Log responses for debugging. This approach ensures robust integration with the GLM-4.6 API.
Code Examples for Integrating GLM-4.6 API
Developers implement GLM-4.6 API in various languages. In Python, use requests for a basic call:
import requests
import json
url = "https://api.z.ai/api/paas/v4/chat/completions"
payload = {
"model": "glm-4.6",
"messages": [{"role": "user", "content": "Explain quantum computing."}],
"max_tokens": 500,
"temperature": 0.7
}
headers = {
"Authorization": "Bearer your-api-key",
"Content-Type": "application/json"
}
response = requests.post(url, data=json.dumps(payload), headers=headers)
print(response.json()["choices"][0]["message"]["content"])
This code sends a query and prints the response.
In JavaScript with Node.js:
const fetch = require('node-fetch');
const url = 'https://api.z.ai/api/paas/v4/chat/completions';
const payload = {
model: 'glm-4.6',
messages: [{ role: 'user', content: 'Write a haiku about AI.' }],
max_tokens: 100
};
const headers = {
'Authorization': 'Bearer your-api-key',
'Content-Type': 'application/json'
};
fetch(url, {
method: 'POST',
body: JSON.stringify(payload),
headers
})
.then(res => res.json())
.then(data => console.log(data.choices[0].message.content));
For streaming in Python, use SSE parsing libraries like sseclient.
These examples demonstrate practical integration, allowing developers to prototype quickly.
Using Apidog for GLM-4.6 API Testing
Apidog serves as an excellent tool for testing the GLM-4.6 API. This all-in-one platform enables developers to design, debug, mock, and automate API interactions.
Start by downloading Apidog from apidog.com and creating a project. Import the GLM-4.6 API endpoint by adding a new API with the URL https://api.z.ai/api/paas/v4/chat/completions.
Set authentication in Apidog's headers section, adding "Authorization: Bearer your-api-key". Configure the request body with JSON parameters like model and messages.
Apidog allows sending requests and viewing responses in a user-friendly interface. Developers test variations by duplicating requests and adjusting parameters.
Furthermore, automate tests by creating scenarios in Apidog. Define assertions to validate response content, ensuring the GLM-4.6 API behaves as expected.
Mock servers in Apidog simulate responses for offline development. This feature accelerates prototyping without live API calls.

By incorporating Apidog, developers streamline GLM-4.6 API workflows, reducing errors and speeding up deployment.
Best Practices and Rate Limits for GLM-4.6 API
Adhering to best practices maximizes the GLM-4.6 API's potential. Developers monitor usage to stay within rate limits, typically defined by tokens per minute or requests per day based on subscription.
Implement exponential backoff for retries on errors like 429. This prevents overwhelming the server.
Optimize prompts for clarity to improve response quality. Use system messages to set context, guiding the model effectively.
Secure API keys in production environments. Avoid exposing them in client-side code.
Log interactions for auditing and performance analysis. This data informs refinements.
Handle edge cases, such as empty responses or timeouts, with fallback mechanisms.
Zhipu AI updates rate limits in documentation; check regularly.
Following these practices ensures efficient, reliable use of the GLM-4.6 API.
Advanced Usage of GLM-4.6 API
Advanced users explore streaming for interactive applications. Set "stream": true and process chunks in real-time.
Incorporate tools by including function calls in messages. GLM-4.6 supports tool invocation, enabling agents to execute external actions.
For example, define tools in the payload:
"tools": [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather",
"parameters": {...}
}
}
]
The model responds with tool calls if needed.
Fine-tune temperature for specific tasks; low for factual queries, high for creative ones.
Combine with long contexts for document summarization. Feed large texts in messages.
Integrate into agent frameworks like LangChain for complex workflows.
These techniques unlock GLM-4.6's full potential in sophisticated systems.
Conclusion
The GLM-4.6 API offers developers a powerful tool for AI innovation. By following this guide, you integrate it seamlessly into projects. Experiment with features, test using Apidog, and apply best practices for success. Zhipu AI continues evolving GLM-4.6, promising even greater capabilities ahead.