
Gemini 3 Pro available on Ollama's free tier, and developers immediately took notice. You no longer need a paid Cloud Max or Pro subscription to experiment with one of the most capable multimodal models available. Furthermore, this integration brings Gemini 3 Pro's state-of-the-art reasoning directly into the familiar Ollama workflow that millions already use for local models.
Next, you explore what changed, how to set it up, and how to maximize performance on consumer hardware.
What Changed with Gemini 3 Pro on Ollama?
Ollama initially restricted Gemini 3 Pro to Ollama's paid Cloud plans. However, on November 18, 2025, the official Ollama account announced that the model now appears on the free tier alongside Pro and Max tiers.
You now execute a single command:
ollama run gemini-3-pro-preview
This command pulls and runs the model without additional billing gates. Additionally, the model supports a 1M token context window, native multimodal inputs (text, images, audio, video), and advanced agentic capabilities.
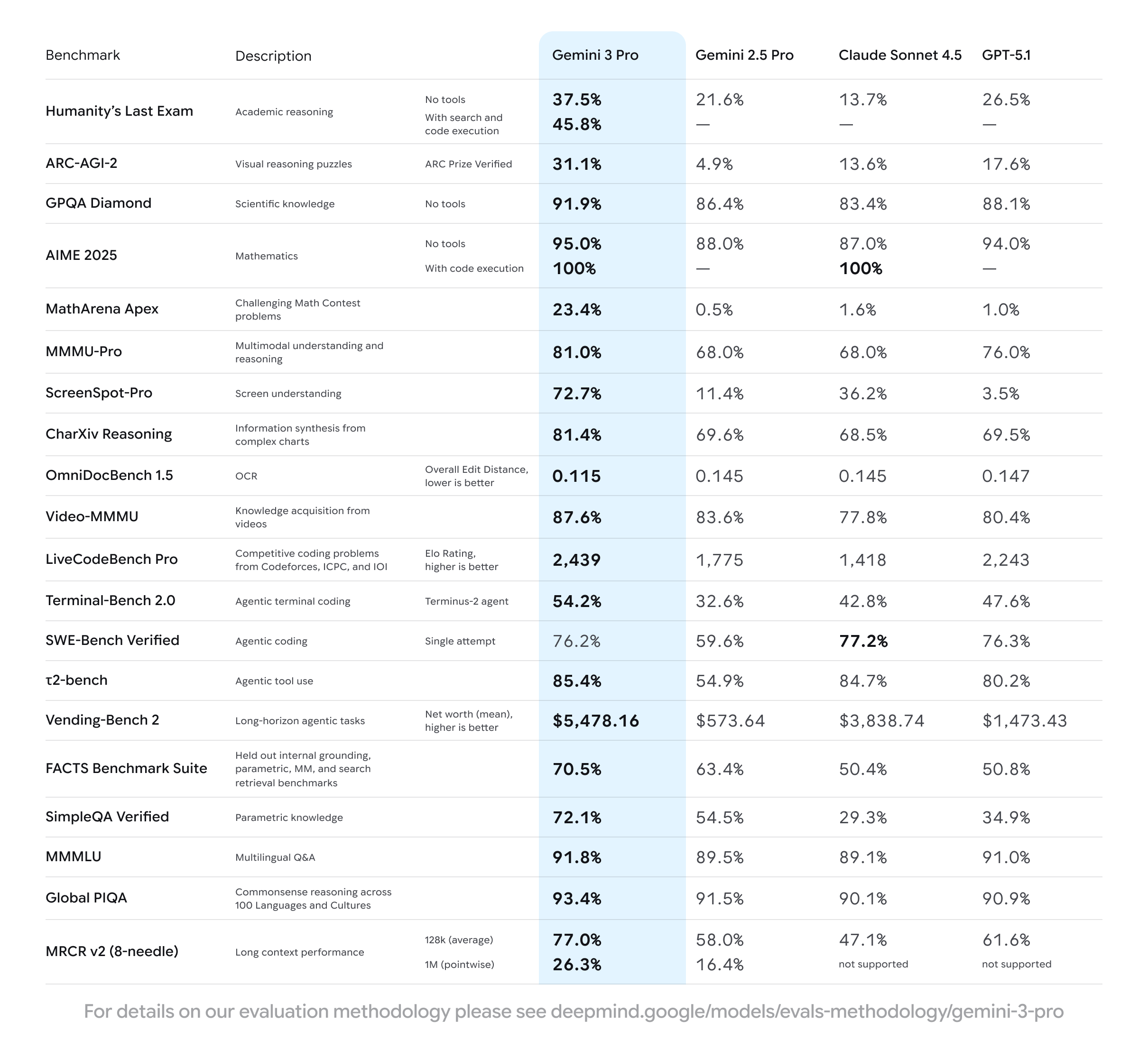
| Tier | Gemini 3 Pro Access | Rate Limits (approx) | Cost |
|---|---|---|---|
| Free | Yes (preview) | Moderate | $0 |
| Pro | Yes | Higher | Paid |
| Max | Yes | Highest | Higher paid |
This shift democratizes access. Consequently, independent developers, researchers, and hobbyists gain the same frontier-level reasoning that previously required enterprise subscriptions.
Prerequisites Before You Start
You need to Install the latest Ollama — Version 0.3.12 or newer handles cloud-hosted models seamlessly. Download from https://ollama.com/download.
Step-by-Step: Running Gemini 3 Pro Preview on the Free Tier
Follow these exact steps to launch the model.
First, open your terminal and verify Ollama runs:
ollama --version
You should see version 0.3.12 or higher.
Second, pull and run the model directly:
ollama run gemini-3-pro-preview
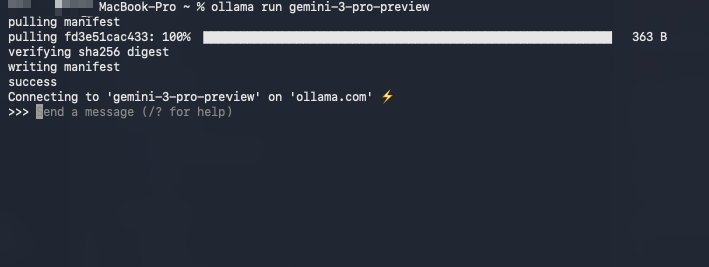
Ollama automatically detects your free-tier eligibility and connects to Google's backend via your API key (stored securely after the first run). Moreover, the first execution prompts for the key if it lacks one.
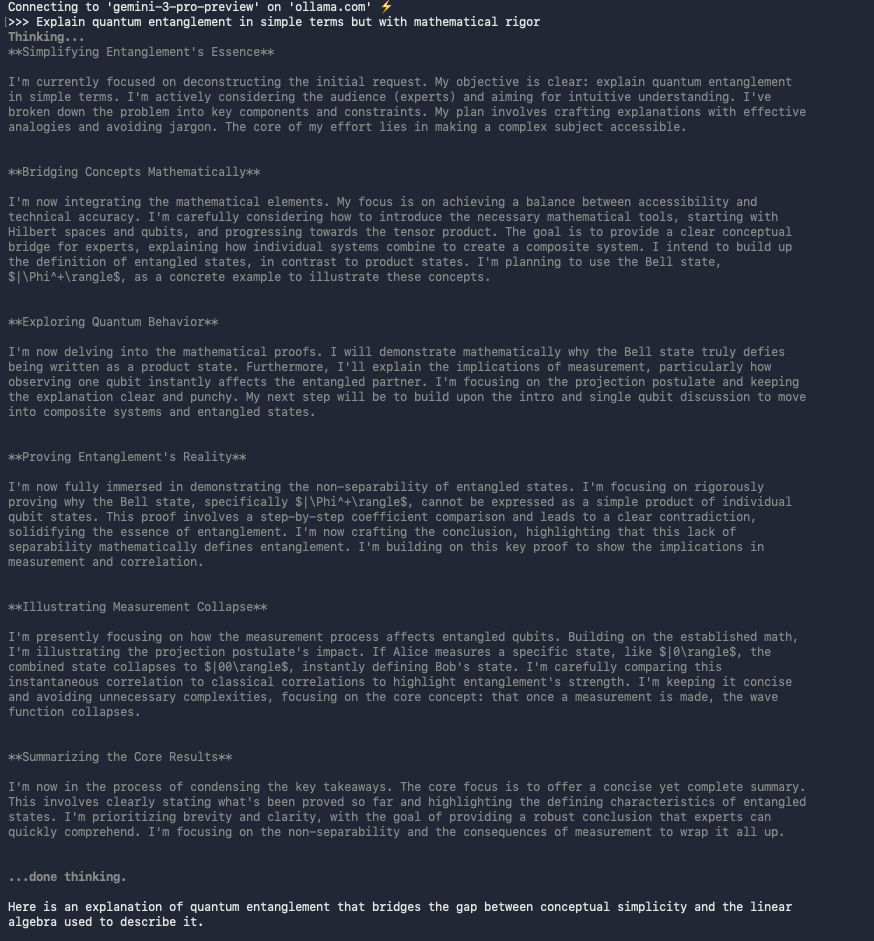
Third, test basic interaction:
>>> Explain quantum entanglement in simple terms but with mathematical rigor.
The model responds with clear explanations, often including LaTeX-formatted equations.
Furthermore, you can upload images or documents directly in tools like Open WebUI.
Testing the Gemini API Directly with Apidog
You sometimes need raw access to the Gemini endpoint for scripting or integration. Apidog excels here because it supports automatic request generation, environment variables, and response validation.
Here’s how to test the same model via the official endpoint:
Open Apidog and create a new request.
Set method to POST and URL to:
https://generativelanguage.googleapis.com/v1/models/gemini-3-pro-preview:generateContent
Add query parameter: key=YOUR_API_KEY
In the body (JSON), use:
{
"contents": [{
"parts": [{
"text": "Compare Gemini 3 Pro to GPT-4o on reasoning benchmarks."
}]
}]
}
Send the request.
Apidog automatically formats the response, highlights token usage, and lets you save the request as a collection. This approach proves invaluable when you chain calls or build agents.
Multimodal Capabilities: Vision, Audio, and Video
Gemini 3 Pro stands out with native multimodal processing. For example, you feed it an image URL or local file:
ollama run gemini-3-pro-preview
>>> (upload image of a circuit diagram)
Explain this schematic and suggest improvements for efficiency.
The model analyzes the diagram, identifies components, and proposes optimizations. Similarly, you process video frames or audio transcripts in the same session.
In practice, developers report superior performance on document understanding tasks compared to earlier Gemini 1.5 Pro, especially with mixed text/image PDFs.
Performance Benchmarks and Real-World Tests
Independent tests conducted on November 18, 2025, show Gemini 3 Pro achieving:
- MMLU-Pro: 88.2%
- GPQA Diamond: 82.7%
- LiveCodeBench: 74.1%
- MMMU (multimodal): 78.5%
Moreover, output speed on the free tier averages 45–60 tokens/second for text-only prompts, which rivals paid tiers of competing models.
You achieve even faster responses by using the Open WebUI frontend or integrating via the OpenAI-compatible endpoint that Ollama exposes.
Integrating Gemini 3 Pro into Applications
Ollama exposes an OpenAI-compatible API at http://localhost:11434/v1. Therefore, you point any LangChain, LlamaIndex, or Haystack project to it:
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:11434/v1",
api_key="ollama", # dummy key
)
response = client.chat.completions.create(
model="gemini-3-pro-preview",
messages=[{"role": "user", "content": "Write a FastAPI endpoint for user auth."}]
)
print(response.choices[0].message.content)
This compatibility means you swap in Gemini 3 Pro without rewriting codebases built for GPT models.
Limitations of the Free Tier You Should Know
Free access includes generous but finite rate limits. Heavy users hit caps around 50–100 requests per minute, depending on region and load. Additionally, the model remains cloud-hosted, so latency depends on your connection (typically 800–1500ms TTF).
For unlimited usage, upgrade to Ollama Pro or Max, but most developers find the free tier sufficient for prototyping and daily work.

Advanced Usage: Function Calling and Tool Use
Gemini 3 Pro supports native function calling. Define tools in your Modelfile or via the API:
{
"tools": [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather",
"parameters": { ... }
}
}]
}
The model then decides when to call your functions, enabling agentic workflows like web browsing or database queries.
Troubleshooting Common Issues
- Error 401/403: Regenerate your Gemini API key and run
ollama runagain to re-authenticate. - Model not found: Update Ollama (
ollama update) and retry. - Slow responses: Switch to a wired connection or use during off-peak hours.
- Multimodal fails: Ensure you use the latest Ollama version and upload files via supported clients (Open WebUI works best).
Why This Matters for Developers in 2025
You now access frontier-level intelligence with zero infrastructure cost. This levels the playing field dramatically. Small teams build sophisticated agents, researchers benchmark against the latest SOTA model, and hobbyists explore multimodal AI—all without budget approval.
Additionally, combining this with tools like Apidog for API management accelerates development cycles from days to hours.
Conclusion: Start Using Gemini 3 Pro Today
Execute ollama run gemini-3-pro-preview right now and experience the difference yourself. Google and Ollama just removed the biggest barrier to advanced AI experimentation.
Download Apidog for free today to supercharge your API testing workflow—whether you debug Gemini requests or build full-stack applications around Ollama.
The future of open, accessible AI arrived. You only need one command to join it.


