As Google quietly rolls out Gemini 3.0 through shadow deployments and preview endpoints, developers gain early opportunities to test its enhanced reasoning and multimodal performance.
Researchers and engineers at Google DeepMind have positioned Gemini 3.0 as the company's most capable model family to date. Furthermore, it advances beyond incremental updates by introducing native agentic behaviors and deeper tool integration.
Gemini 3.0 Release Timeline and Rollout Strategy
Google adopts a phased deployment approach for major model upgrades. Consequently, Gemini 3.0 first appeared in controlled environments without a traditional keynote announcement.
The model initially surfaced in AI Studio under the identifier "gemini-3-pro-preview" around mid-November 2025. Additionally, select Gemini Advanced subscribers received in-app notifications stating, "We've upgraded you from the previous model to 3.0 Pro, our smartest model yet." This shadow release allows Google to collect production telemetry while maintaining interface continuity.
Vertex AI and the Gemini API changelog now list preview endpoints such as gemini-3-pro-preview-11-2025. Moreover, internal codenames like "lithiumflow" and "orionmist" that dominated LM Arena leaderboards in October 2025 have been confirmed as early Gemini 3.0 checkpoints.
Google DeepMind publicly acknowledged the family in a November 2025 thread, describing Gemini 3 as delivering "state-of-the-art reasoning capabilities, world-leading multimodal understanding, and new agentic coding experiences." Full stable release, including broader Gemini 3 API availability, is expected before the end of 2025.
Core Architectural Advances in Gemini 3.0
Gemini 3.0 builds on the mixture-of-experts (MoE) foundation established in earlier generations. However, it incorporates several critical enhancements that directly impact inference quality and efficiency.
First, the model expands context window support beyond the 2 million tokens available in Gemini 2.5 Pro, with preview instances handling extended sessions more coherently. Second, training on vastly larger multimodal datasets improves cross-modal alignment – the model now processes interleaved text, code, images, and structured data with reduced modality loss.
Researchers introduce refined attention mechanisms that prioritize long-range dependencies during reasoning chains. As a result, Gemini 3.0 exhibits fewer context drift issues in multi-turn interactions exceeding 100 exchanges.
The family includes at least two primary variants in preview:
- Gemini 3.0 Pro: The flagship model optimized for maximum intelligence and complex problem-solving.
- Gemini 3.0 Flash: A distilled, latency-focused version that maintains high capability while achieving sub-second response times on TPU infrastructure.
Early instrumentation reveals that Pro operates at temperature 1.0 by default, with documentation warning that lower values can degrade chain-of-thought performance – a departure from previous models where temperature 0.7 often yielded optimal results.
Multimodal Understanding and Generation Capabilities
Gemini 3.0 significantly strengthens native multimodal processing. Engineers train the model end-to-end on diverse data types, enabling it to reason across vision, audio, and text without separate encoders.
For instance, the model analyzes screenshots of user interfaces, extracts functional specifications, and generates complete React or Flutter code with embedded animations in a single pass. Additionally, it interprets scientific diagrams, derives underlying equations, and simulates outcomes using built-in physics knowledge.
Preview users report breakthrough performance in visual reasoning tasks:
- Accurate interpretation of complex charts containing overlaid annotations
- Generation of SVG code that respects mathematical constraints (e.g., perfect circles, proportional scaling)
- Creation of interactive Canvas experiences combining prose, code execution, and visual output
Furthermore, agentic extensions allow the model to orchestrate tool calls autonomously. Developers observe Gemini 3.0 Pro planning multi-step browser interactions or API sequences without explicit prompting, a capability previously limited to experimental modes.
Reasoning and Agentic Behavior Improvements
Google emphasizes "Deep Think" as a core paradigm in Gemini 3.0. The model internally decomposes problems into sub-problems, evaluates multiple solution paths, and self-corrects before final output.
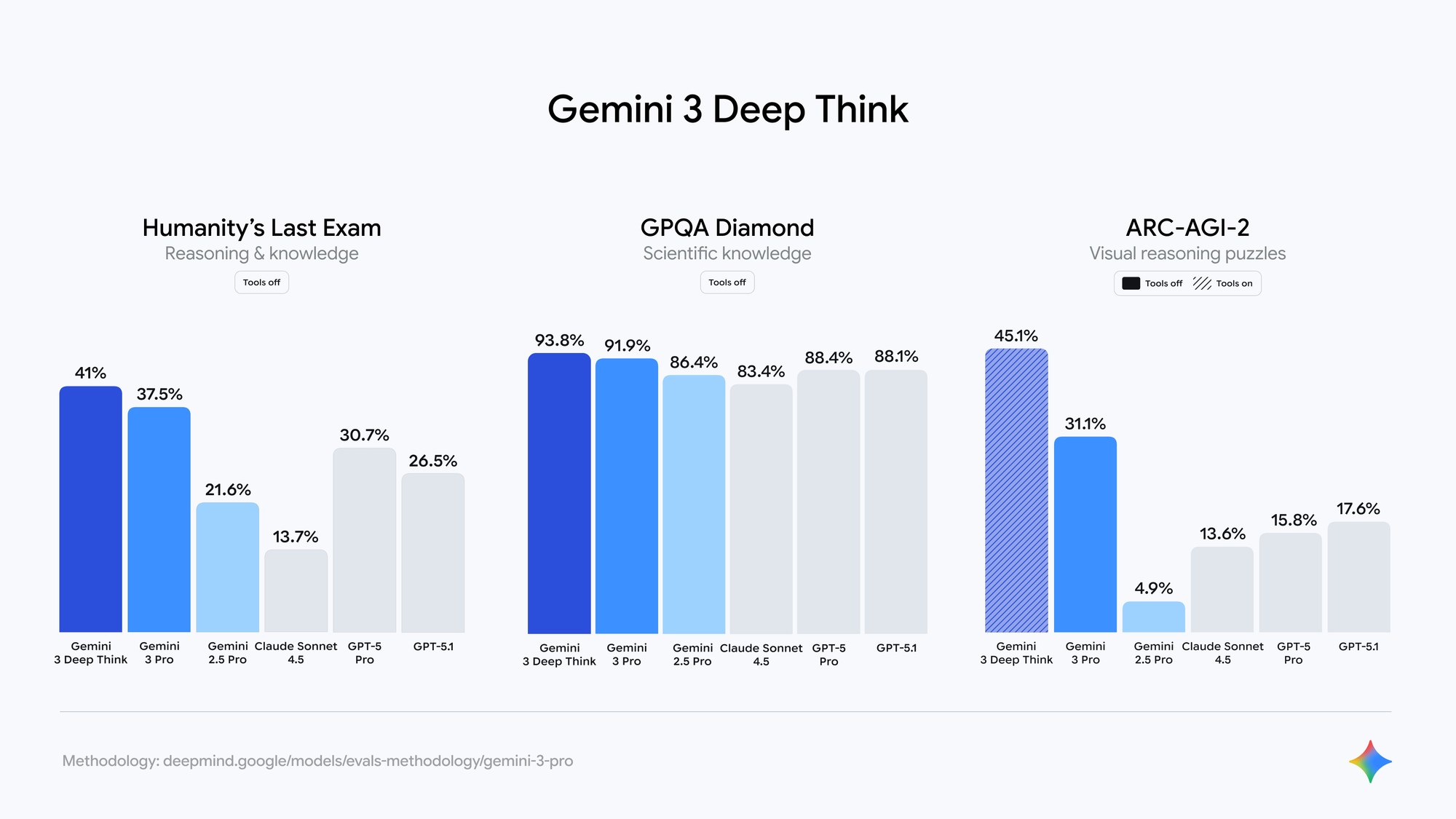
Independent evaluations on closed LM Arena checkpoints (widely accepted as Gemini 3.0 variants) show:
- SimpleBench scores approaching 90–100% (versus 62.4% for Gemini 2.5 Pro)
- Substantial gains on GPQA Diamond, AIME 2024, and SWE-bench Verified
- Improved factual consistency in long-form generation
Moreover, the model demonstrates emergent planning abilities. When tasked with system design, it produces complete architectural diagrams, API contracts, and deployment scripts while anticipating edge cases.
Accessing the Gemini 3 API in Preview
Developers currently access Gemini 3.0 through the Gemini API preview endpoints. Google maintains backward compatibility with existing SDKs, requiring only a model name update.
Key endpoint changes include:
# Existing Gemini 2.5 code continues to work
import google.generativeai as genai
genai.configure(api_key="YOUR_API_KEY")
# Switch to preview model
model = genai.GenerativeModel("gemini-3-pro-preview-11-2025")
response = model.generate_content(
"Explain quantum entanglement with a working Python simulation",
generation_config=genai.types.GenerationConfig(
temperature=1.0,
max_output_tokens=8192
)
)
The Gemini 3 API supports the same safety settings, function calling, and grounding features as previous versions. However, preview quotas remain conservative, and rate limits apply per project.
For production-grade testing, tools like Apidog prove invaluable. Apidog automatically imports Gemini OpenAPI specifications, enables request mocking for offline development, and provides detailed response validation – essential when experimenting with new reasoning behaviors that can produce variable output lengths.
Benchmark Performance and Competitive Positioning
Although Google has not published official cards yet, community-verified results from preview access and shadow deployments indicate Gemini 3.0 Pro leads current public models on several frontiers:
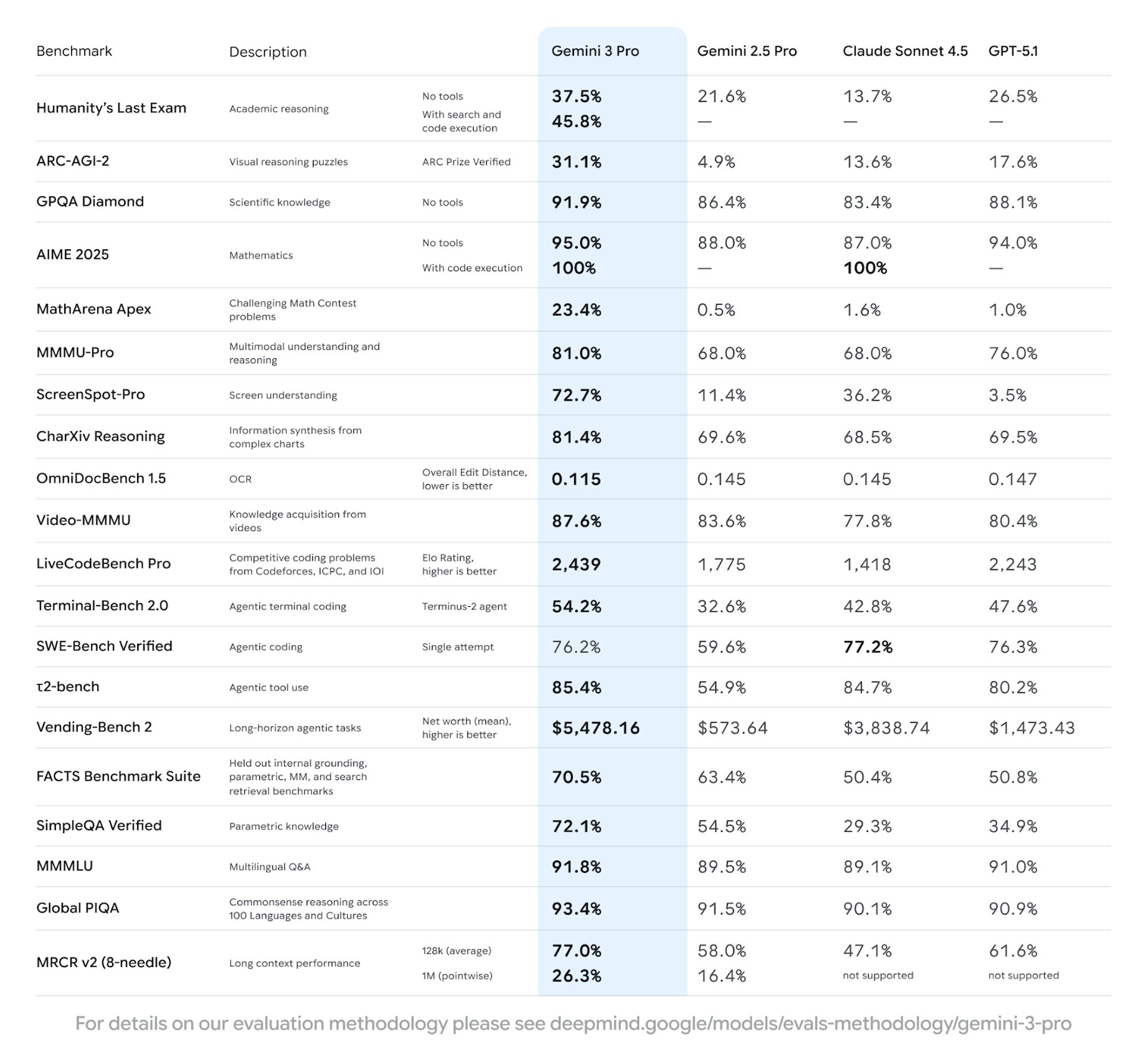
These figures position Gemini 3.0 ahead of contemporary Claude 4 Opus and GPT-4.1 equivalents in reasoning density and code quality.
Practical Integration Patterns with the Gemini 3 API
Successful adoption requires understanding new behavioral characteristics. Developers must account for longer thinking times on complex prompts – the model often spends additional tokens on internal deliberation before responding.
Best practices emerging from preview usage:
- Set temperature to 1.0 for reasoning-heavy tasks
- Use system instructions to enforce structured output (JSON, YAML)
- Leverage the expanded context for full codebase uploads
- Chain tool calls explicitly when deterministic behavior is required
Additionally, combine the Gemini 3 API with external orchestration layers for reliable agent loops. Apidog excels here by providing environment-specific collections that switch seamlessly between gemini-2.5-pro and gemini-3-pro-preview endpoints.
Limitations and Known Issues in Preview
Preview builds exhibit occasional instability. Users encounter context loss in extremely long sessions (>150k tokens) and rare hallucinations in niche domains. Furthermore, image generation remains tied to separate Imagen/Nano Banana endpoints rather than native integration.
Google actively iterates based on telemetry. Most reported issues resolve within days of discovery, reflecting the advantages of shadow deployment.
Future Outlook and Ecosystem Impact
Gemini 3.0 establishes a new baseline for multimodal agents. As the Gemini 3 API moves to stable status, expect rapid integration across Google Workspace, Android, and Vertex AI agents.
Enterprises will benefit from private instances with custom alignment, while developers gain access to reasoning depth previously requiring multiple model calls.
The combination of raw intelligence, native tool understanding, and efficient deployment positions Gemini 3.0 as the foundation for next-generation AI applications.
Developers ready to experiment with these capabilities should begin migrating test suites to the Gemini 3 API preview immediately. Tools like Apidog dramatically reduce friction during this transition by offering one-click endpoint switching and comprehensive debugging.
Google's measured rollout demonstrates maturity in large-model deployment. Consequently, when Gemini 3.0 reaches general availability, the ecosystem will be primed for immediate productive use.