
Extracting valuable data from websites at scale is essential for API developers, backend engineers, and technical teams. With Firecrawl, you can automate web scraping and site crawling using just a few lines of code—making data extraction faster and more reliable.
In this guide, you’ll learn how to set up Firecrawl, use its key features, and integrate it into your workflow for efficient data collection. We’ll cover practical examples, advanced techniques, and troubleshooting to help you maximize your scraping projects.
💡 Tip: If you want to simplify API testing and streamline your AI development process, download Apidog for free. Apidog makes it easy to test APIs, especially those interacting with LLMs and AI models—perfect for integrating with tools like Firecrawl.
What Is Firecrawl?
Firecrawl is a modern web crawling and scraping engine designed to convert website content into formats such as markdown, HTML, and structured data. It’s built for developers who need to extract both structured and unstructured data efficiently—ideal for AI, LLM pipelines, and data analysis.
Core Firecrawl Features
1. Crawl: Deep Site Traversal
The /crawl endpoint enables recursive exploration of entire websites, extracting data from all subpages. This is invaluable for large-scale content discovery and creating comprehensive datasets ready for LLM processing.
2. Scrape: Precision Data Extraction
Use the Scrape feature to pull specific information from a single URL. Firecrawl can return content as markdown, HTML, screenshots, or structured data—making it easy to target exactly what you need.
3. Map: Visualize Site Structure
The Map feature rapidly retrieves all URLs associated with a website, providing a clear overview of its architecture. This is especially helpful for organizing content or identifying new data sources.
4. Extract: AI-Powered Structuring
Firecrawl’s /extract endpoint leverages AI to transform unstructured web content into organized, ready-to-use data. It automates crawling, parsing, and structuring, reducing manual processing.
Getting Started with Firecrawl: Step-by-Step
Step 1: Create an Account & Get Your API Key
- Go to Firecrawl's official website and sign up.
- After logging in, navigate to your dashboard to find your API key.
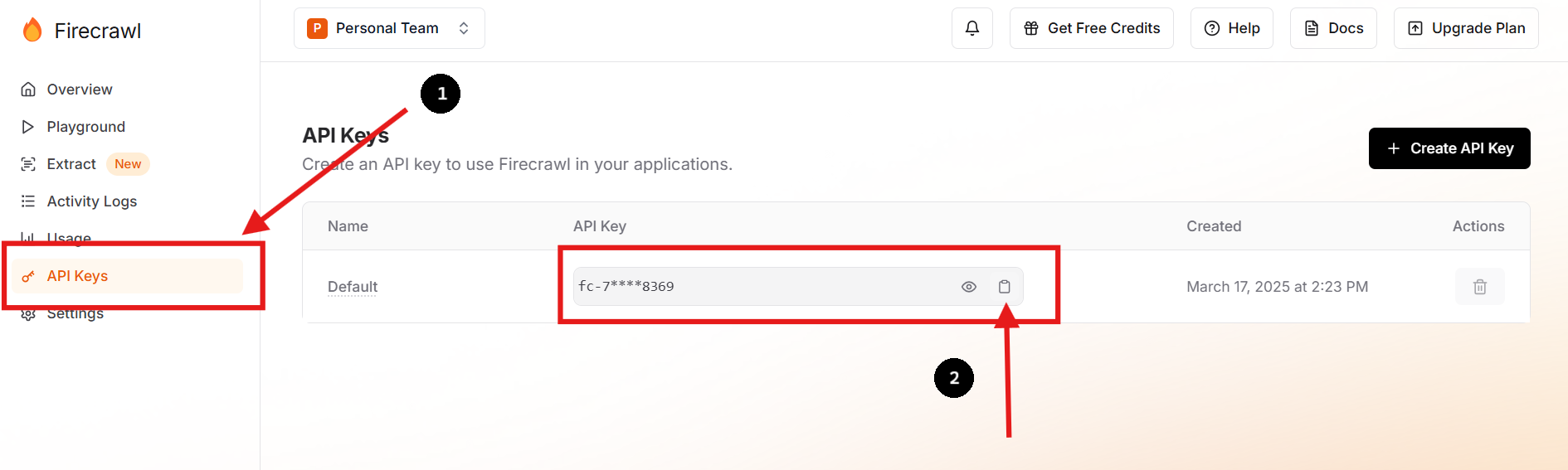
- You can generate a new API key or delete old keys as needed.

Step 2: Securely Store Your API Key
In your project directory, create a .env file to store your API key as an environment variable:
touch .env
echo "FIRECRAWL_API_KEY='fc-YOUR-KEY-HERE'" >> .env
This keeps sensitive credentials out of your codebase, improving security.
Step 3: Install the Firecrawl SDK
For Python projects, install the SDK with:
pip install firecrawl
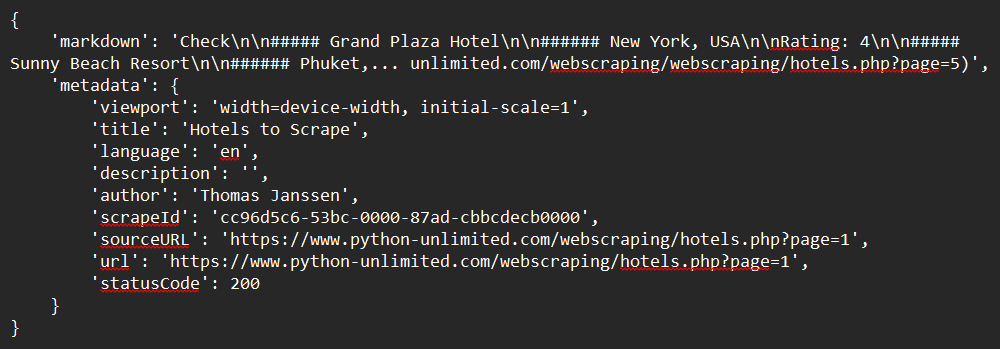
Step 4: Scrape a Single Webpage
Use the Python SDK to scrape content from any URL:
from firecrawl import FirecrawlApp
from dotenv import load_dotenv
import os
load_dotenv()
app = FirecrawlApp(api_key=os.getenv("FIRECRAWL_API_KEY"))
url = "https://www.python-unlimited.com/webscraping/hotels.php?page=1"
response = app.scrape_url(url)
print(response)
Sample Output:
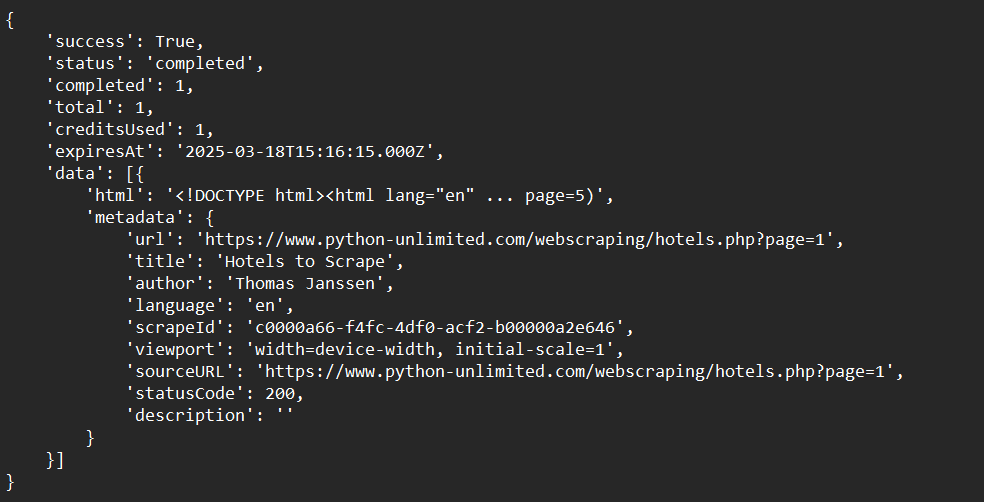
Step 5: Crawl an Entire Website
Automate deep crawling with a single function:
from firecrawl import FirecrawlApp
from dotenv import load_dotenv
import os
load_dotenv()
app = FirecrawlApp(api_key=os.getenv("FIRECRAWL_API_KEY"))
crawl_status = app.crawl_url(
'https://www.python-unlimited.com/webscraping/hotels.php?page=1',
params={
'limit': 100,
'scrapeOptions': {'formats': ['markdown', 'html']}
},
poll_interval=30
)
print(crawl_status)
Sample Output:
Step 6: Map a Website’s URLs
Quickly build a site map programmatically:
from firecrawl import FirecrawlApp
from dotenv import load_dotenv
import os
load_dotenv()
app = FirecrawlApp(api_key=os.getenv("FIRECRAWL_API_KEY"))
map_result = app.map_url('https://www.python-unlimited.com/webscraping/hotels.php?page=1')
print(map_result)
Sample Output:

Step 7: Extract Structured Data Using AI (Open Beta)
Transform content into structured data with a custom schema:
from firecrawl import FirecrawlApp
from pydantic import BaseModel, Field
from dotenv import load_dotenv
import os
load_dotenv()
app = FirecrawlApp(api_key=os.getenv("FIRECRAWL_API_KEY"))
class ExtractSchema(BaseModel):
company_mission: str
supports_sso: bool
is_open_source: bool
is_in_yc: bool
response = app.extract([
'https://docs.firecrawl.dev/*',
'https://firecrawl.dev/',
'https://www.ycombinator.com/companies/'
], {
'prompt': "Extract the data provided in the schema.",
'schema': ExtractSchema.model_json_schema()
})
print(response)
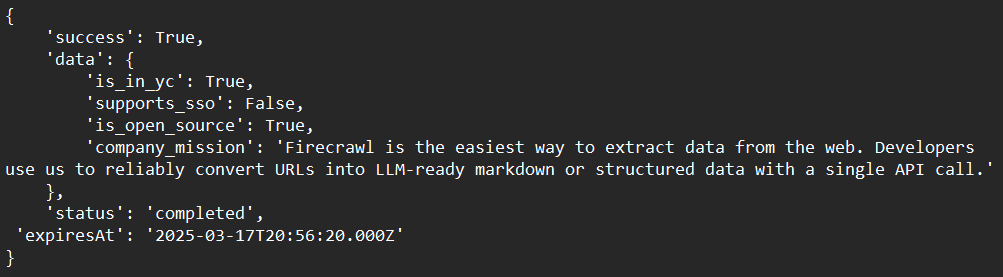
Sample Output:
Advanced Tips for Firecrawl Power Users
Handle Dynamic JavaScript Content
Firecrawl supports headless browser rendering to capture dynamic, JavaScript-loaded content—ensuring your data extraction is complete and accurate.
Bypass Common Scraping Blockers
Leverage Firecrawl’s built-in techniques, such as rotating user agents and IP addresses, to handle CAPTCHAs, rate limits, and anti-scraping mechanisms.
Integrate with LLMs & AI Workflows
Firecrawl fits seamlessly into LLM pipelines, such as with LangChain. Use it to collect and preprocess data before feeding it to your AI models for analysis or content generation.
Troubleshooting Common Issues
- API Key Not Recognized
- Ensure your API key is correctly referenced from your environment variables.
- Slow Crawling Performance
- Use asynchronous or concurrent crawling to increase throughput.
- Incomplete Content Extraction
- For JavaScript-heavy sites, confirm that Firecrawl’s headless browser mode is enabled.
Conclusion: Streamline Data Collection for API Projects
With Firecrawl, developers can automate large-scale web scraping and data extraction—saving countless hours on manual data collection. Whether you’re building data pipelines, powering AI models, or mapping complex websites, Firecrawl’s flexibility and efficiency make it a top choice.
For even more efficient API development and testing—including seamless integration with AI and scraping workflows—try Apidog. Apidog simplifies API testing for technical teams, letting you focus on building robust data-driven solutions.
Ready to level up your web scraping workflow? Download Apidog for free and see how it can supercharge your Firecrawl integration.


