
Engineers and developers often seek robust tools to integrate advanced language models into their applications. EXAONE API stands out as a powerful option from LG AI Research, hosted on platforms like Together AI. This interface allows you to perform tasks ranging from text completion to multimodal processing.
EXAONE emerges as a bilingual model family, supporting English and Korean, with variants like the 32B parameter version excelling in reasoning, math, and code. Developers use it through hosted services or local setups. First, understand its core features. Then, move to practical implementation steps.
Understanding EXAONE API Architecture
EXAONE represents LG AI Research's commitment to democratizing artificial intelligence through expert-level language models. The API architecture supports multiple model variants, including EXAONE 3.0, EXAONE 3.5, EXAONE 4.0, and EXAONE Deep, each optimized for specific use cases.
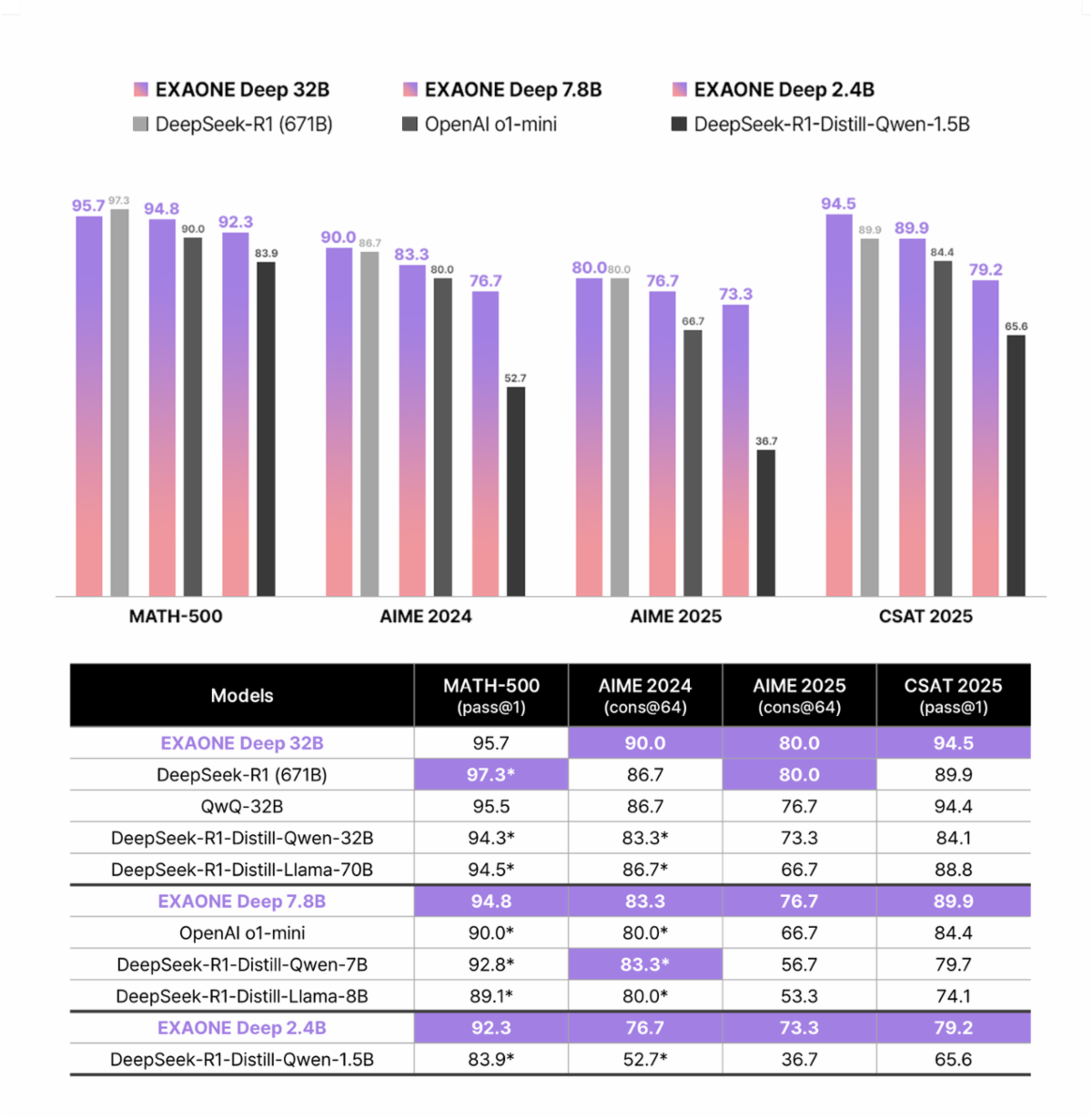
The latest EXAONE 4.0 introduces groundbreaking hybrid attention mechanisms. Unlike traditional transformer architectures, EXAONE 4.0 combines local attention with global attention in a 3:1 ratio for the 32B model variant. Furthermore, the architecture implements QK-Reorder-Norm, repositioning LayerNorm from traditional Pre-LN schemes to apply directly to attention and MLP outputs.

Additionally, EXAONE models support bilingual capabilities across English and Korean languages. Recent updates extend multilingual support to include Spanish, making the API suitable for international applications. The model series ranges from lightweight 1.2B parameters for on-device applications to robust 32B parameters for high-performance requirements.
Getting Started with EXAONE API Setup
System Requirements and Prerequisites
Before implementing EXAONE API, ensure your development environment meets the minimum requirements. The API works effectively across various platforms, including cloud-based deployments and local installations. However, specific hardware requirements depend on your chosen deployment method.
For local deployment scenarios, consider memory requirements based on model size. The 1.2B model requires approximately 2.4GB RAM, while the 32B model needs substantially more resources. Cloud deployment options eliminate these constraints while providing scalability benefits.
Authentication and Access Configuration
EXAONE API access varies depending on your chosen deployment platform. Multiple integration paths exist, including Hugging Face Hub deployment, Together AI services, and custom server configurations. Each method requires different authentication approaches.
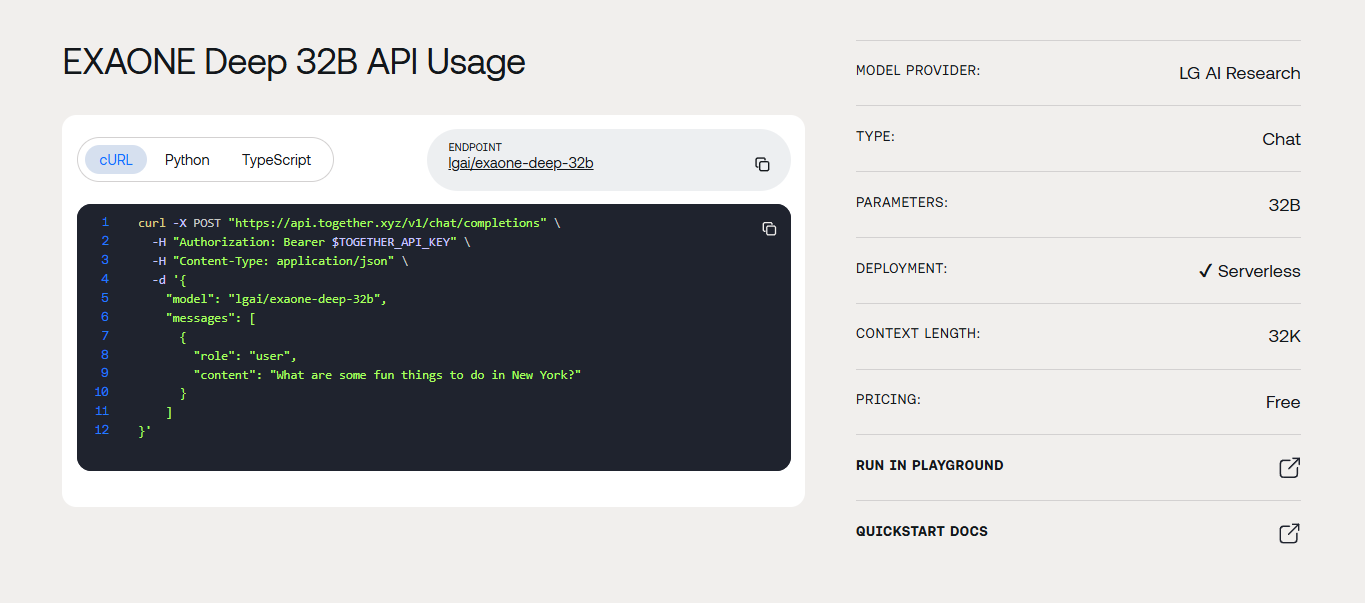
When using Together AI's EXAONE Deep 32B API endpoint, authentication involves API key management. Create an account with Together AI, generate your API key, and configure environment variables securely. Never expose API keys in client-side code or public repositories.
import Together from "together-ai";
const client = new Together({
apiKey: process.env.TOGETHER_API_KEY
});
async function callExaoneAPI(prompt) {
try {
const response = await client.chat.completions.create({
model: "exaone-deep-32b",
messages: [
{
role: "user",
content: prompt
}
],
max_tokens: 1000,
temperature: 0.7
});
return response.choices[0].message.content;
} catch (error) {
console.error("EXAONE API Error:", error);
throw error;
}
}
Local Deployment with Ollama Integration
Local deployment offers privacy, control, and reduced latency benefits. Ollama provides an excellent platform for running EXAONE models locally without complex infrastructure requirements. This approach particularly benefits developers working with sensitive data or requiring offline capabilities.
Installing and Configuring Ollama
Start by downloading Ollama from the official website. Installation processes vary across operating systems, but the setup remains straightforward. Once installed, verify the installation by running basic commands in your terminal.
# Install Ollama (MacOS)
brew install ollama
# Start Ollama service
ollama serve
# Pull EXAONE model
ollama pull exaone
After successful installation, configure Ollama to run EXAONE models effectively. The configuration involves downloading model weights, setting up proper memory allocation, and optimizing performance parameters for your specific hardware.
Running EXAONE Models Locally
Once Ollama installation completes, downloading EXAONE models becomes straightforward. The process involves pulling model weights from the official repository and configuring runtime parameters. Different model sizes offer various performance characteristics, so choose based on your specific requirements.
# Pull specific EXAONE model version
ollama pull exaone-deep:7.8b
# Run model with custom parameters
ollama run exaone-deep:7.8b --temperature 0.5 --max-tokens 2048
Local deployment also enables custom fine-tuning opportunities. Advanced users can modify model parameters, adjust inference settings, and optimize performance for specific use cases. This flexibility makes EXAONE particularly attractive for research applications and specialized implementations.
API Integration Methods and Best Practices
RESTful API Implementation
EXAONE API follows standard RESTful conventions, making integration familiar for most developers. HTTP POST requests handle model inference, while GET requests manage model information and status checks. Proper error handling ensures robust applications that gracefully manage API limitations and network issues.
import requests
import json
def exaone_api_call(prompt, model_size="32b"):
url = "https://api.together.ai/v1/chat/completions"
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
payload = {
"model": f"exaone-deep-{model_size}",
"messages": [
{"role": "user", "content": prompt}
],
"max_tokens": 1500,
"temperature": 0.7,
"top_p": 0.9
}
try:
response = requests.post(url, headers=headers, json=payload)
response.raise_for_status()
return response.json()
except requests.exceptions.RequestException as e:
print(f"API request failed: {e}")
return None
Advanced Configuration Options
EXAONE API supports various configuration parameters that significantly impact output quality and performance. Temperature controls randomness in generated responses, while top_p manages nucleus sampling behavior. Max_tokens limits response length, helping control costs and response times.
Additionally, the API supports system prompts, enabling consistent behavior across multiple requests. This feature proves particularly valuable for applications requiring specific tone, style, or format consistency. System prompts also help maintain context across conversation threads.
Testing EXAONE API with Apidog
Effective API testing accelerates development and ensures reliable integrations. Apidog provides comprehensive testing capabilities specifically designed for modern API workflows. The platform supports automated testing, request validation, and performance monitoring.
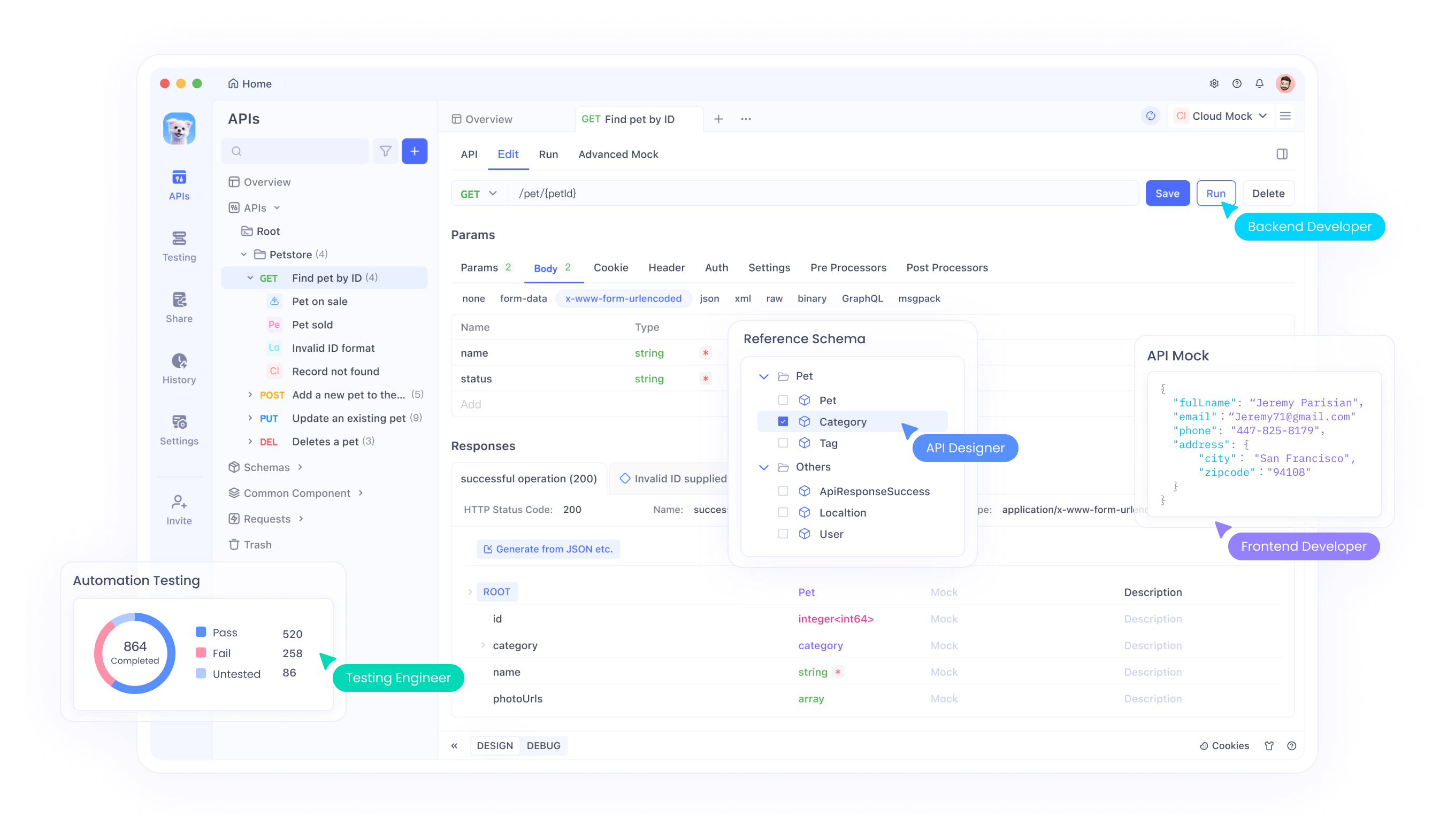
Setting Up Apidog for EXAONE Testing
Begin by creating an Apidog account and installing the desktop application. The platform offers both web-based and desktop versions, each providing powerful testing capabilities. Desktop versions offer additional features like local file imports and enhanced debugging tools.
Import EXAONE API endpoints into Apidog by creating new API specifications. Define request parameters, headers, and expected response formats. This documentation serves as both testing configuration and team collaboration tool, ensuring consistent API usage across development teams.
Creating Comprehensive Test Suites
Develop test suites covering various scenarios, including successful requests, error conditions, and edge cases. Test different parameter combinations to understand API behavior thoroughly. Apidog's test automation features enable continuous validation during development cycles.
{
"test_cases": [
{
"name": "Basic Text Generation",
"request": {
"method": "POST",
"url": "{{base_url}}/chat/completions",
"headers": {
"Authorization": "Bearer {{api_key}}",
"Content-Type": "application/json"
},
"body": {
"model": "exaone-deep-32b",
"messages": [
{"role": "user", "content": "Explain quantum computing"}
],
"max_tokens": 500
}
},
"assertions": [
{"path": "$.choices[0].message.content", "operator": "exists"},
{"path": "$.usage.total_tokens", "operator": "lessThan", "value": 600}
]
}
]
}
Performance Optimization Strategies
Request Batching and Caching
Optimize API performance through intelligent request batching and response caching. Batching reduces network overhead while caching eliminates redundant API calls for identical requests. These strategies significantly improve application responsiveness while reducing costs.
Implement caching layers using Redis or similar technologies. Cache responses based on request parameters, ensuring cache invalidation occurs appropriately. Consider cache expiration policies based on your application's requirements and data sensitivity.
Error Handling and Retry Logic
Robust error handling prevents application failures when API issues occur. Implement exponential backoff strategies for transient errors, while handling permanent errors gracefully. Rate limiting management ensures applications stay within API quotas without service interruptions.
import time
import random
from typing import Optional
class ExaoneAPIClient:
def __init__(self, api_key: str, max_retries: int = 3):
self.api_key = api_key
self.max_retries = max_retries
def call_with_retry(self, prompt: str) -> Optional[str]:
for attempt in range(self.max_retries):
try:
response = self._make_api_call(prompt)
return response
except Exception as e:
if attempt == self.max_retries - 1:
raise e
wait_time = (2 ** attempt) + random.uniform(0, 1)
time.sleep(wait_time)
return None
def _make_api_call(self, prompt: str) -> str:
# Implementation details for actual API call
pass
Real-World Implementation Examples
Chatbot Development with EXAONE
Building conversational AI applications with EXAONE API requires careful prompt engineering and context management. Unlike simpler gpt-oss alternatives, EXAONE's advanced reasoning capabilities enable more sophisticated dialogue systems.
Implement conversation history management to maintain context across multiple exchanges. Store conversation state efficiently while managing token limits to control costs. Consider implementing conversation summarization for long-running chat sessions.
Content Generation Applications
EXAONE excels at various content generation tasks, including technical documentation, creative writing, and code generation. The API's bilingual capabilities make it particularly suitable for international content creation workflows.
class ContentGenerator:
def __init__(self, exaone_client):
self.client = exaone_client
def generate_blog_post(self, topic: str, target_language: str = "en") -> str:
prompt = f"""
Write a comprehensive blog post about {topic}.
Language: {target_language}
Requirements:
- Include introduction, main content, and conclusion
- Use engaging tone and clear structure
- Target length: 800-1000 words
"""
return self.client.generate(prompt, max_tokens=1200)
def generate_code_documentation(self, code_snippet: str) -> str:
prompt = f"""
Generate comprehensive documentation for this code:
{code_snippet}
Include:
- Function purpose and behavior
- Parameter descriptions
- Return value explanation
- Usage examples
"""
return self.client.generate(prompt, max_tokens=800)
Comparing EXAONE with Alternative Solutions
Advantages Over Traditional GPT Models
EXAONE offers several advantages compared to traditional GPT implementations and gpt-oss alternatives. The hybrid attention architecture provides better long-context understanding, while the reasoning mode enables more accurate problem-solving capabilities.
Cost efficiency represents another significant advantage. Local deployment options eliminate per-token charges, making EXAONE economical for high-volume applications. Additionally, privacy benefits appeal to organizations handling sensitive data.
Integration Flexibility
Unlike some proprietary solutions, EXAONE supports multiple deployment patterns. Choose between cloud APIs, local installations, or hybrid approaches based on specific requirements. This flexibility accommodates various organizational constraints and technical preferences.
Troubleshooting Common Issues
Connection and Authentication Problems
Network connectivity issues and authentication errors represent common integration challenges. Verify API endpoints, check authentication credentials, and ensure proper header configuration. Network debugging tools help identify connection problems quickly.
Monitor API rate limits carefully, as exceeding quotas results in temporary blocks. Implement proper rate limiting in your applications to prevent service interruptions. Consider upgrading API plans if higher limits become necessary.
Model Performance Optimization
If model responses seem inconsistent or low-quality, review prompt engineering techniques. EXAONE responds well to clear, specific instructions with appropriate context. Experiment with different temperature and top_p values to achieve desired output characteristics.
Consider model size selection based on your requirements. Larger models provide better performance but require more resources and processing time. Balance performance needs against resource constraints and response time requirements.
Security Considerations and Best Practices
API Key Management
Secure API key storage prevents unauthorized access and potential security breaches. Use environment variables, secure vaults, or configuration management systems for key storage. Never commit API keys to version control systems or expose them in client-side code.
Implement key rotation policies to minimize security risks. Regular key updates reduce exposure windows if compromises occur. Monitor API usage patterns to detect unusual activity that might indicate security issues.
Data Privacy and Compliance
When processing sensitive data through EXAONE API, consider data privacy implications carefully. Local deployment options provide maximum privacy control, while cloud deployments require careful evaluation of data handling policies.
Implement data sanitization procedures to remove sensitive information before API requests. Consider implementing additional encryption layers for highly sensitive applications. Review compliance requirements specific to your industry and geographic location.
Future Developments and Roadmap
Upcoming Features
LG AI Research continues developing EXAONE capabilities, with regular model updates and feature enhancements. Future releases may include additional language support, improved reasoning capabilities, and enhanced tool integration features.
Stay informed about API changes through official documentation and community channels. Plan for migration paths when new model versions become available. Test new versions thoroughly before production deployments.
Community and Ecosystem Growth
The EXAONE ecosystem continues expanding with community contributions, third-party integrations, and specialized tools. Active participation in community discussions provides insights into best practices and emerging use cases.
Consider contributing to open-source projects related to EXAONE integration. Sharing experiences and solutions benefits the entire developer community while potentially improving the platform for everyone.
Conclusion
EXAONE API offers powerful capabilities for developers seeking advanced AI integration options. From local deployment flexibility to sophisticated reasoning capabilities, EXAONE provides compelling alternatives to mainstream solutions. The comprehensive deployment options, robust performance characteristics, and growing ecosystem make EXAONE an excellent choice for various application scenarios.
Success with EXAONE API depends on proper setup, thoughtful integration planning, and continuous optimization. Use tools like Apidog for efficient testing and debugging workflows. Follow security best practices and stay informed about platform updates to maximize your implementation's effectiveness.


