
The Dream 7B model, created by the University of Hong Kong NLP team in partnership with Huawei Noah’s Ark Lab, marks a breakthrough in language model technology. By replacing traditional autoregressive generation with a diffusion-based approach, Dream 7B delivers more coherent, flexible, and powerful text generation—unlocking new opportunities for API development, backend engineering, and advanced automation.
💡 For API developers seeking seamless integration with local models like Dream 7B, Apidog offers a robust platform to test and debug endpoints. Download Apidog to streamline your workflow and easily evaluate advanced models like Dream 7B and Mistral Small 3.1.
What Makes Dream 7B Different? Diffusion Architecture Explained
Dream 7B (Diffusion REAsoning Model, 7B parameters) stands out by leveraging discrete diffusion modeling for text generation. Unlike GPT or LLaMA, which generate text token by token from left to right, Dream 7B refines entire sequences in parallel—starting from a fully noised state and denoising step by step.
Key advantages of this architecture:
- Bidirectional context: Accesses information from both directions, boosting coherence and reasoning.
- Parallel processing: Entire sequences are handled at once, reducing sequential bottlenecks.
- Flexible generation: Supports arbitrary generation order, enabling infilling, completion, and more.
Dream 7B was initially seeded with weights from Qwen2.5 7B and trained on ~580 billion tokens (sources include Dolma v1.7, OpenCoder, DCLM-Baseline).
How Dream 7B Outperforms Traditional Autoregressive Models
Dream 7B’s diffusion approach delivers practical benefits for developers:
- Richer context modeling: Simultaneous sequence refinement improves understanding of global and local context.
- Superior planning: In tasks demanding reasoning or constraint satisfaction (e.g., puzzles, structured data), Dream 7B outshines autoregressive models of similar size.
- Dynamic generation control: Developers can set generation order and quality-speed trade-offs by adjusting diffusion steps.
- Versatile use cases: Supports text infilling, targeted completions, and controlled generation to fit diverse API and application needs.
Dream 7B Benchmark Performance: How Does It Stack Up?
Dream 7B has been rigorously benchmarked against leading models. Across language understanding, math reasoning, and code generation, it matches or beats top-tier competitors like LLaMA3 8B and Qwen2.5 7B.
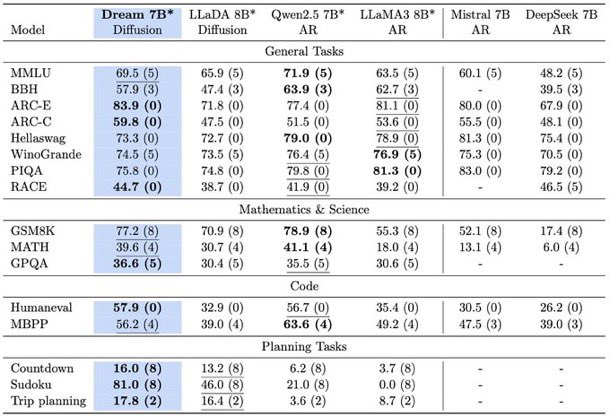
In planning-heavy tasks (e.g., Countdown, Sudoku), Dream 7B not only surpasses similar models but sometimes nears the performance of much larger models like DeepSeek V3 671B—a testament to its advanced reasoning.

Key Innovations in Dream 7B Training
1. Autoregressive Weight Initialization
Instead of training from scratch, Dream 7B started from Qwen2.5 7B weights. This strategy brought in rich language knowledge and accelerated diffusion training. Careful tuning preserved this foundation while adapting to the new architecture.
2. Context-Adaptive Token-Level Noise Rescheduling
Dream 7B introduced dynamic, token-specific noise scheduling during training. Unlike uniform noise application, this method tailors noise based on each token's context, resulting in more efficient learning and robust output.
Practical Applications: Where Dream 7B Excels
Dream 7B’s unique abilities enable several advanced use cases for API-centric teams:
Flexible Text Infilling & Completion
- Fill gaps within code, documentation, or structured outputs
- Complete prompts with precise constraints (e.g., generate content ending with a target sentence)
Controlled Generation Order
- Choose between left-to-right, random order, or hybrid generation—ideal for complex data transformations or pipeline integration
Quality vs. Speed Optimization
- Adjust diffusion steps to balance generation quality against response time—critical for production APIs where latency matters
Supervised Fine-Tuning: Aligning Dream 7B with User Instructions
To enhance alignment with user prompts, Dream 7B underwent supervised fine-tuning using 1.8 million instruction pairs (Tulu 3, SmolLM2). After three epochs, the resulting Dream-v0-Instruct-7B model demonstrates strong instruction-following abilities, rivaling top autoregressive models.
Both the base (Dream-v0-Base-7B) and instruction-tuned models are open source for further research and experimentation.
How to Run Dream 7B: Technical Requirements
To deploy Dream 7B in your development environment:
- GPU: Minimum 20GB VRAM
- Transformers: v4.46.2
- PyTorch: v2.5.1 with SdpaAttention
Generation parameters:
steps: Number of diffusion steps (lower = faster, coarser; higher = slower, higher quality)temperature: Controls output diversity (lower = more deterministic)top_p,top_k: Adjust sampling diversityalg: Selects remasking strategy for diffusion
For teams building API endpoints around Dream 7B, using Apidog can simplify endpoint management, testing, and debugging—especially when working with complex generation parameters.
Future Directions: What’s Next for Diffusion-Based Language Models?
Dream 7B’s success points toward exciting opportunities:
- Scaling up: Larger diffusion models may rival or surpass even the biggest autoregressive LLMs.
- Advanced post-training: Custom alignment and instruction tuning tailored for diffusion architectures.
- Specialized domains: Planning, decision-making, and multimodal applications (AI agents, robotics, etc.).
- Multimodal integration: Diffusion’s parallelism could extend to vision and other modalities for richer, unified models.
Conclusion: The Developer’s Case for Dream 7B
Dream 7B demonstrates that diffusion-based models can match—and sometimes exceed—autoregressive LLMs while offering developers unique advantages in flexibility, reasoning, and control.
With open-source access to both model weights and implementation, Dream 7B invites API engineers and technical teams to explore new paradigms in language modeling. For those integrating or testing advanced models locally, Apidog provides a developer-friendly toolkit to streamline every stage of API development.
Stay ahead in the evolution of language AI by experimenting with diffusion models—and equip yourself with tools like Apidog to bring innovation to your API workflows.


