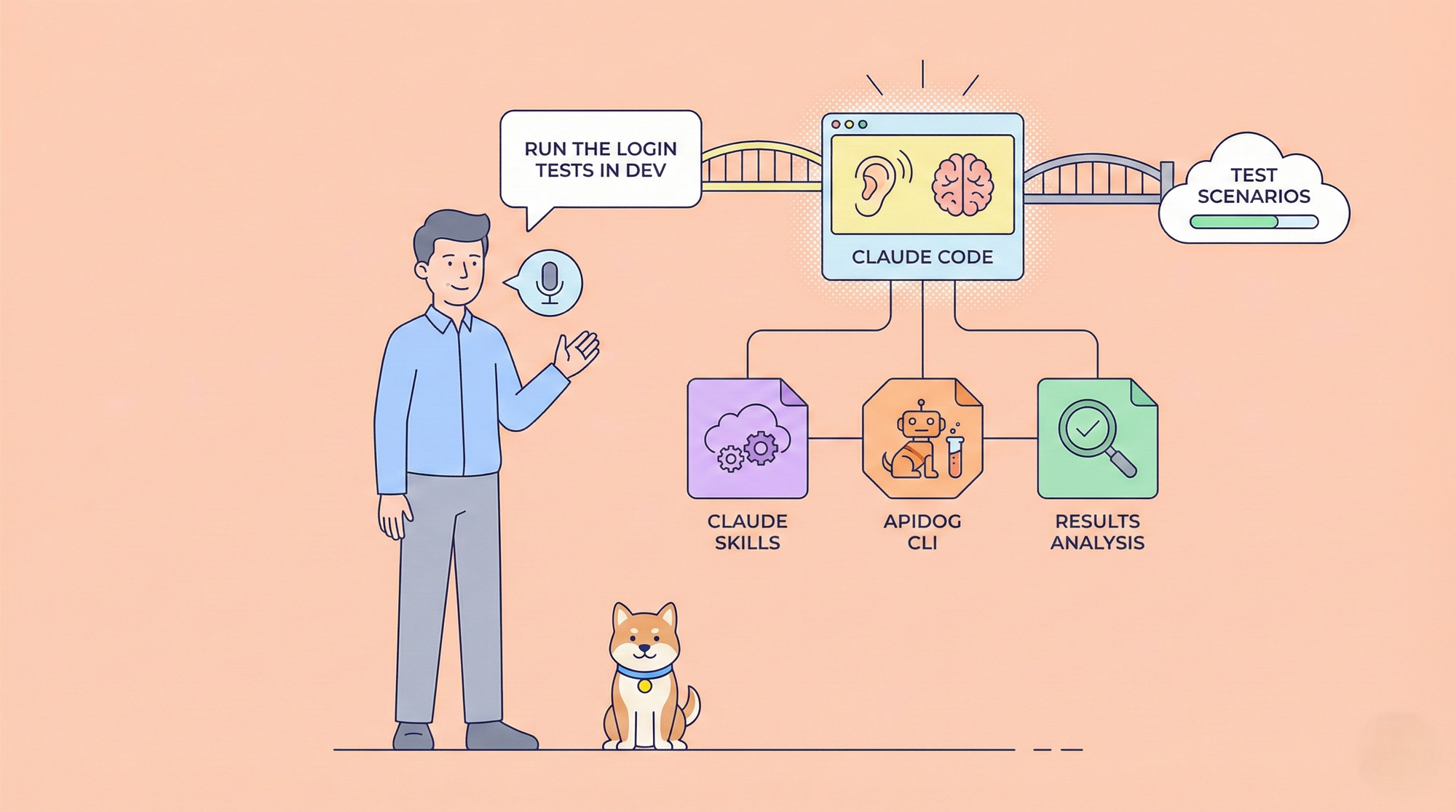
Developers seek tools that enhance productivity without introducing unnecessary complexity. DeepSeek-V3.2 and DeepSeek-V3.2-Speciale emerge as powerful open-source models optimized for reasoning and agentic tasks, offering a compelling alternative to proprietary systems. These models excel in code generation, problem-solving, and long-context processing, making them ideal for integration into terminal-based coding environments like Claude Code.
Understanding DeepSeek-V3.2: An Open-Source Powerhouse for Reasoning Tasks
Developers value open-source models for their transparency and flexibility. DeepSeek-V3.2 stands out as a reasoning-first large language model (LLM) that prioritizes logical inference, code synthesis, and agentic capabilities. Released under an MIT license, this model builds on previous iterations like DeepSeek-V3.1, incorporating advancements in sparse attention mechanisms to handle extended contexts up to 128,000 tokens.
You access DeepSeek-V3.2 primarily through Hugging Face, where the repository at deepseek-ai/DeepSeek-V3.2 hosts the model weights, configuration files, and tokenizer details. To load the model locally, install the Transformers library via pip and execute a simple script:
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_name = "deepseek-ai/DeepSeek-V3.2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.float16, device_map="auto")
# Example inference
inputs = tokenizer("Write a Python function to compute Fibonacci sequence:", return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=100)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
This setup requires a GPU with at least 16GB VRAM for efficient inference, though quantization techniques via libraries like bitsandbytes reduce memory footprint. DeepSeek-V3.2's architecture employs a mixture-of-experts (MoE) design with 236 billion parameters, activating only a subset per token to optimize compute. Consequently, it achieves high throughput on consumer hardware while maintaining competitive performance.
Transitioning from local experimentation to production-scale usage often requires API access. This shift provides scalability without hardware management, paving the way for integrations like Claude Code.
DeepSeek-V3.2-Speciale: Enhanced Capabilities for Advanced Agentic Workflows
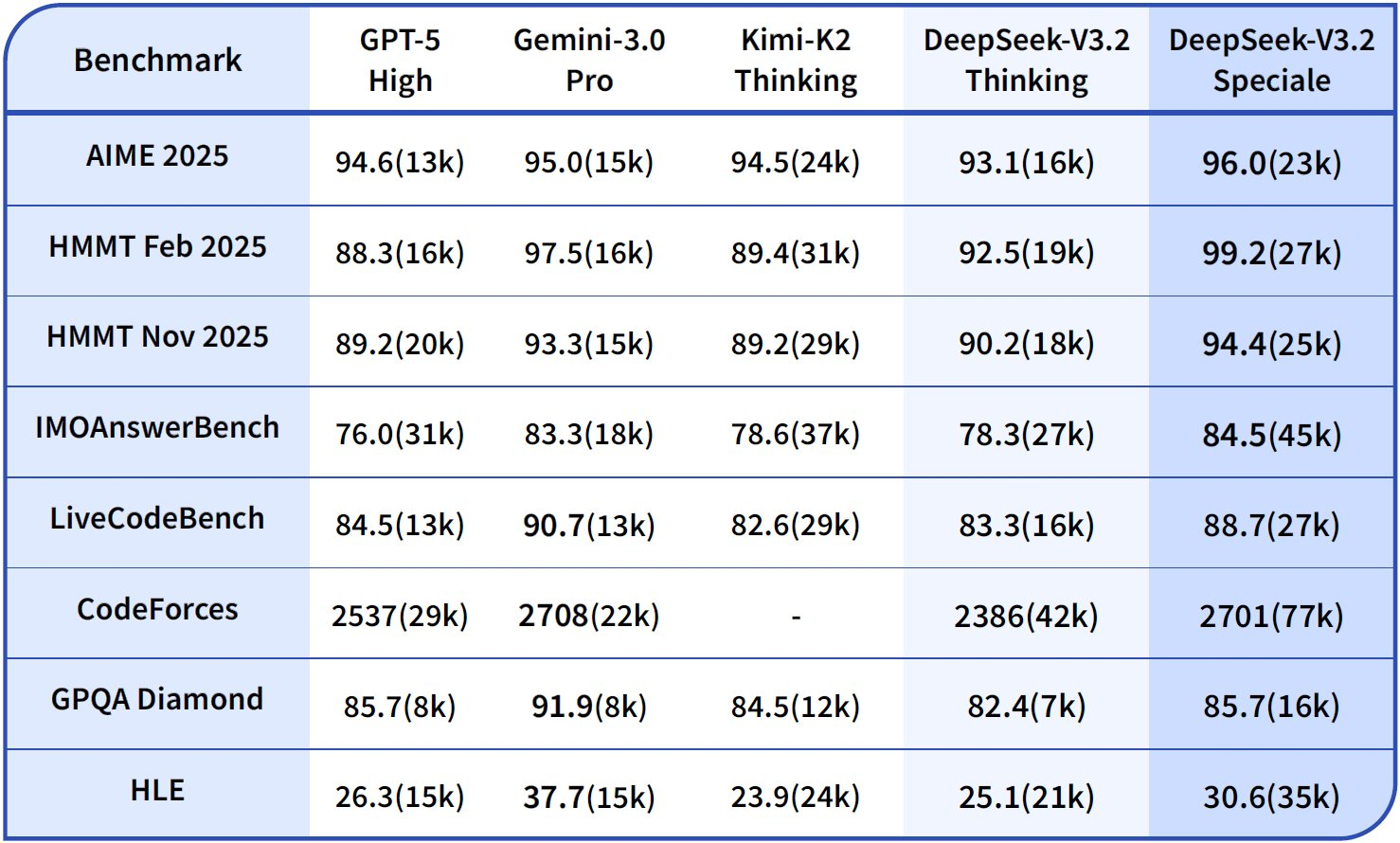
While DeepSeek-V3.2 offers broad utility, DeepSeek-V3.2-Speciale refines these foundations for specialized demands. This variant, tuned for contest-level reasoning and high-stakes simulations, pushes boundaries in mathematics, coding competitions, and multi-step agent tasks. Available via the Hugging Face repository at deepseek-ai/DeepSeek-V3.2-Speciale, it shares the core MoE architecture but incorporates additional post-training alignments for precision.
Load DeepSeek-V3.2-Speciale similarly:
model_name = "deepseek-ai/DeepSeek-V3.2-Speciale"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16, device_map="auto")
Its parameter count mirrors the base model, yet optimizations in sparse attention—DeepSeek Sparse Attention (DSA)—yield up to 50% faster inference on long sequences. DSA employs fine-grained sparsity, preserving quality while reducing quadratic complexity in attention layers.
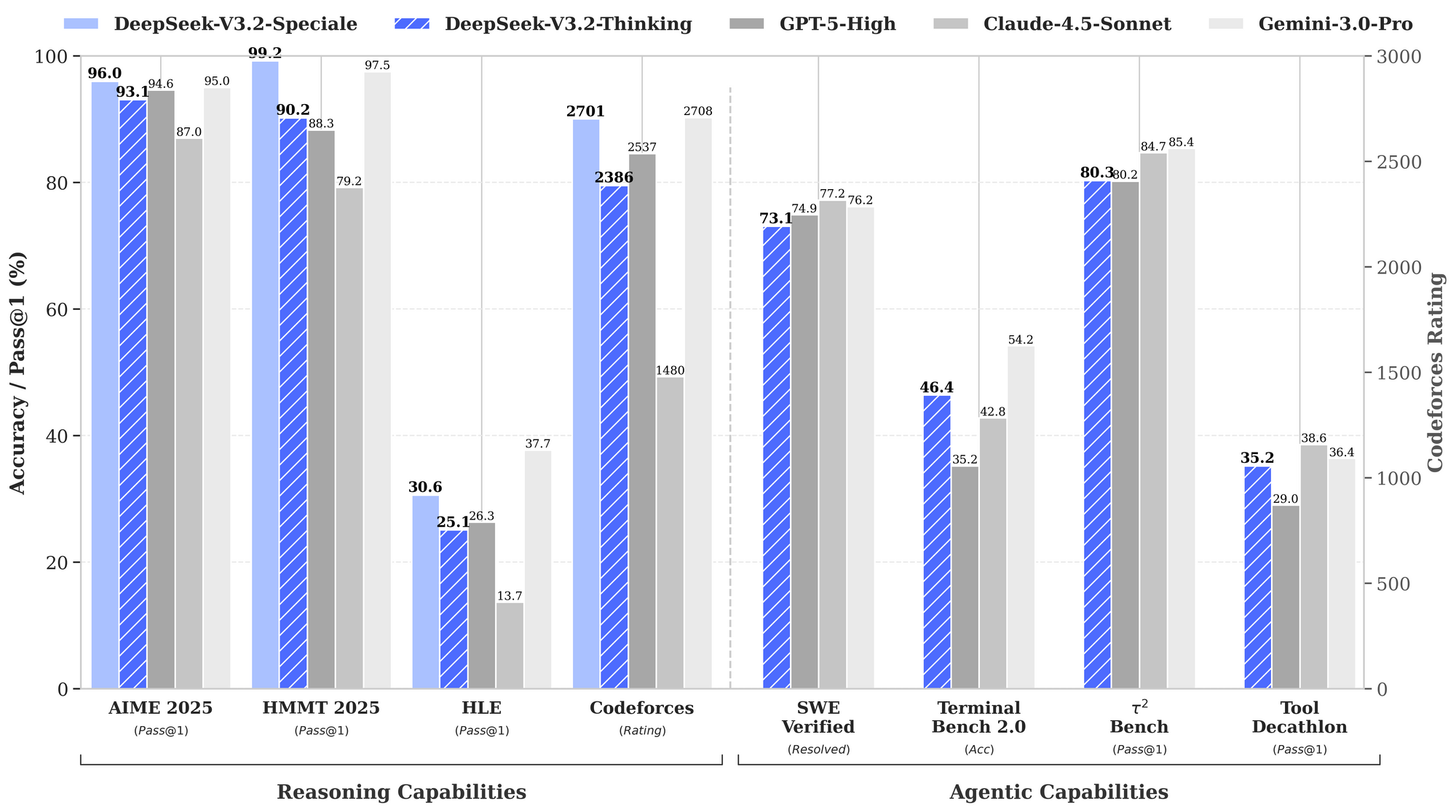
In practice, DeepSeek-V3.2-Speciale shines in scenarios requiring chained reasoning, such as optimizing algorithms for competitive programming. For instance, prompt it with: "Solve this LeetCode hard problem: [description]. Explain your approach step-by-step." The model outputs structured solutions with time complexity analysis, often outperforming generalist models by 15-20% on edge cases.
However, local runs demand more resources—recommend 24GB+ VRAM for full precision. For lighter setups, apply 4-bit quantization:
from transformers import BitsAndBytesConfig
quant_config = BitsAndBytesConfig(load_in_4bit=True)
model = AutoModelForCausalLM.from_pretrained(model_name, quantization_config=quant_config)
This configuration maintains 90% of original fidelity while halving memory use. As with the base model, enable thinking modes to leverage its metacognitive traces, where it self-corrects assumptions mid-reasoning.
Open-source access empowers customization, but for collaborative or scaled environments, API endpoints provide reliability. Next, examine how to bridge these models to cloud-based interactions.
Accessing the DeepSeek API: Seamless Integration for Scalable Development
Open-source models like DeepSeek-V3.2 and DeepSeek-V3.2-Speciale thrive in local setups, yet API access unlocks broader applications. DeepSeek's platform offers a compatible interface, supporting OpenAI and Anthropic SDKs for effortless migration.
Sign up at platform.deepseek.com to obtain an API key.
The dashboard provides usage analytics and billing controls. Invoke models via standard endpoints; for DeepSeek-V3.2, use the deepseek-chat alias. DeepSeek-V3.2-Speciale requires a specific base URL: https://api.deepseek.com/v3.2_speciale_expires_on_20251215—note this temporary routing expires December 15, 2025.
A basic curl request demonstrates access:
curl https://api.deepseek.com/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $DEEPSEEK_API_KEY" \
-d '{
"model": "deepseek-chat",
"messages": [{"role": "user", "content": "Generate a REST API endpoint in Node.js for user authentication."}],
"max_tokens": 500,
"temperature": 0.7
}'
This returns JSON with generated code, including error handling and JWT integration. For Anthropic compatibility—key for Claude Code—set the base URL to https://api.deepseek.com/anthropic and use the anthropic Python SDK:
import anthropic
client = anthropic.Anthropic(base_url="https://api.deepseek.com/anthropic", api_key="your_deepseek_key")
message = client.messages.create(
model="deepseek-chat",
max_tokens=1000,
messages=[{"role": "user", "content": "Explain quantum entanglement in code terms."}]
)
print(message.content[0].text)
Such compatibility ensures drop-in replacements. Rate limits stand at 10,000 tokens per minute for standard tiers, scalable via enterprise plans.
Use Apidog to prototype these calls. Import the OpenAPI spec from DeepSeek docs into Apidog, then simulate requests with variable payloads. This tool auto-generates test suites, validating responses against schemas—essential for ensuring model outputs align with your codebase standards.
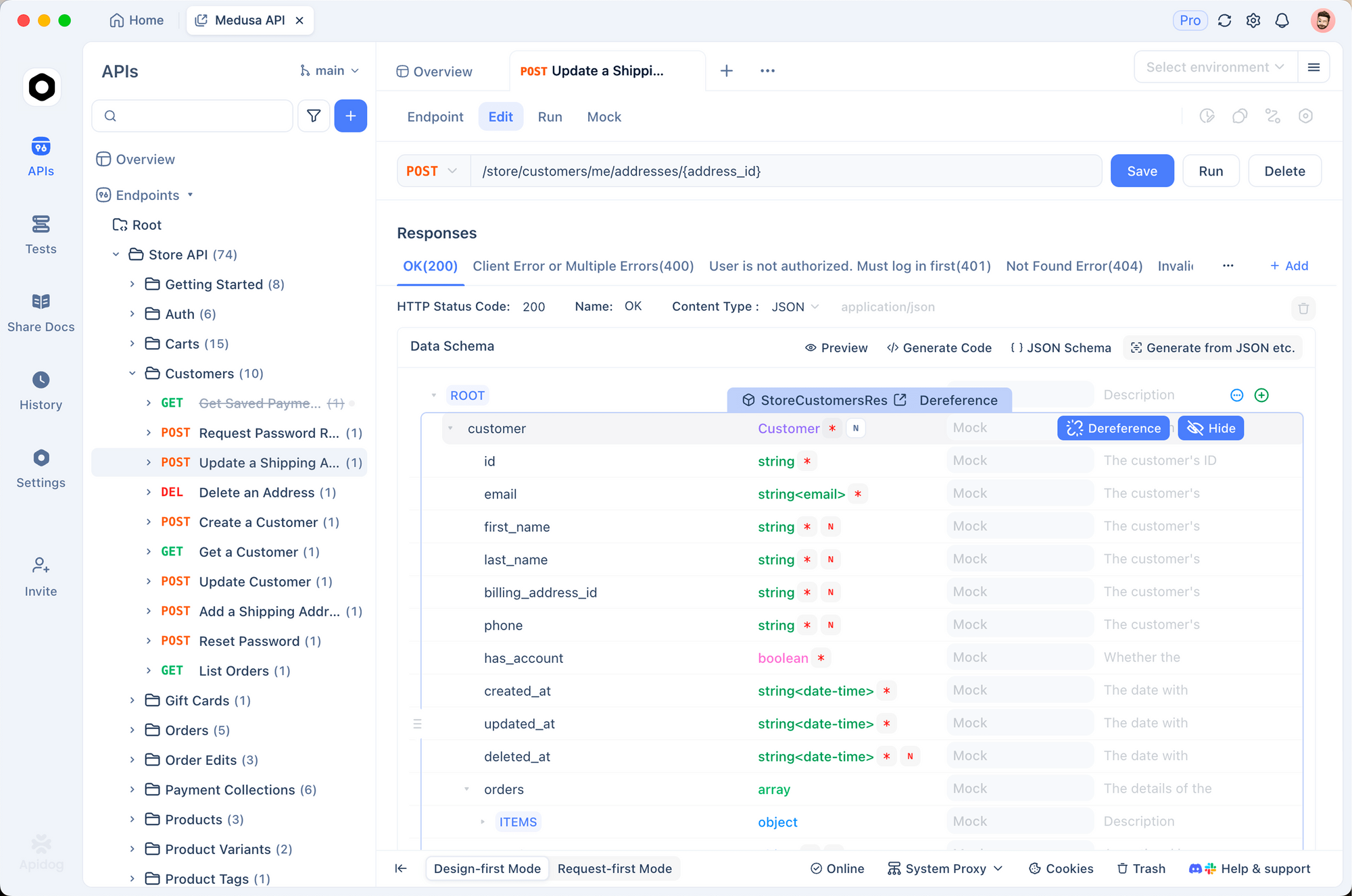
With API access secured, integrate these endpoints into development tools. Claude Code, in particular, benefits from this setup, as explored below.
Pricing Breakdown: Cost-Effective Strategies for DeepSeek API Usage
Budget-conscious developers appreciate predictable costs. DeepSeek's pricing model rewards efficient prompting and caching, directly impacting Claude Code sessions.
Break down the structure: Cache hits apply to repeated prefixes, ideal for iterative coding where you refine prompts across sessions. Misses charge full input rates, so structure conversations to maximize reuse. Outputs scale linearly with generation length—cap max_tokens to control expenses.
| Model Variant | Input Cache Hit ($/1M Tokens) | Input Cache Miss ($/1M Tokens) | Output ($/1M Tokens) | Context Length |
|---|---|---|---|---|
| DeepSeek-V3.2 | 0.028 | 0.28 | 0.42 | 128K |
| DeepSeek-V3.2-Speciale | 0.028 | 0.28 | 0.42 | 128K |
Enterprise users negotiate volume discounts, but free tiers offer 1M tokens monthly for testing. Monitor via the dashboard; integrate logging in Claude Code to track token usage:
export ANTHROPIC_BASE_URL=https://api.deepseek.com/anthropic
export ANTHROPIC_API_KEY=$DEEPSEEK_API_KEY
claude --log-tokens
This command outputs metrics post-session, helping optimize prompts. For long-context coding, DSA in V3.2 variants keeps costs stable even at 100K+ tokens, unlike dense models that escalate quadratically.
Integrating DeepSeek-V3.2 and V3.2-Speciale into Claude Code: Step-by-Step Setup
Claude Code revolutionizes terminal-based development as an agentic tool from Anthropic. It interprets natural language commands, executes git operations, explains codebases, and automates routines—all within your shell. By routing requests to DeepSeek models, you harness cost-effective reasoning without sacrificing Claude Code's intuitive interface.

Begin with prerequisites: Install Claude Code via pip (pip install claude-code) or from GitHub anthropics/claude-code. Ensure Node.js and git reside in your PATH.
Configure environment variables for DeepSeek compatibility:
export ANTHROPIC_BASE_URL="https://api.deepseek.com/anthropic"
export ANTHROPIC_API_KEY="sk-your_deepseek_key_here"
export ANTHROPIC_MODEL="deepseek-chat" # For V3.2
export ANTHROPIC_SMALL_FAST_MODEL="deepseek-chat"
export API_TIMEOUT_MS=600000 # 10 minutes for long reasoning
export CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC=1 # Optimize for API
For DeepSeek-V3.2-Speciale, append the custom base: export ANTHROPIC_BASE_URL="https://api.deepseek.com/v3.2_speciale_expires_on_20251215/anthropic". Verify setup by running claude --version; it detects the endpoint automatically.
Launch Claude Code in your project directory:
cd /path/to/your/repo
claude
Interact via commands. For code generation: "/generate Implement a binary search tree in C++ with AVL balancing." DeepSeek-V3.2 processes this, outputting files with explanations. Its thinking mode activates implicitly for complex tasks, tracing logic before code.
Handle agentic workflows: "/agent Debug this failing test suite and suggest fixes." The model analyzes stack traces, proposes patches, and commits via git—all powered by DeepSeek's 84.8% SWE-Bench score. Parallel tool use shines here; specify "/use-tool pytest" to execute tests inline.
Customize with plugins. Extend Claude Code's YAML config (~/.claude-code/config.yaml) to prioritize DeepSeek for reasoning-heavy prompts:
models:
default: deepseek-chat
fallback: deepseek-chat # For V3.2-Speciale, override per session
reasoning_enabled: true
max_context: 100000 # Leverage 128K window
Test integrations using Apidog. Export Claude Code sessions as HAR files, import into Apidog, and replay against DeepSeek endpoints. This validates latency (typically <2s for 1K tokens) and error rates, refining prompts for production.
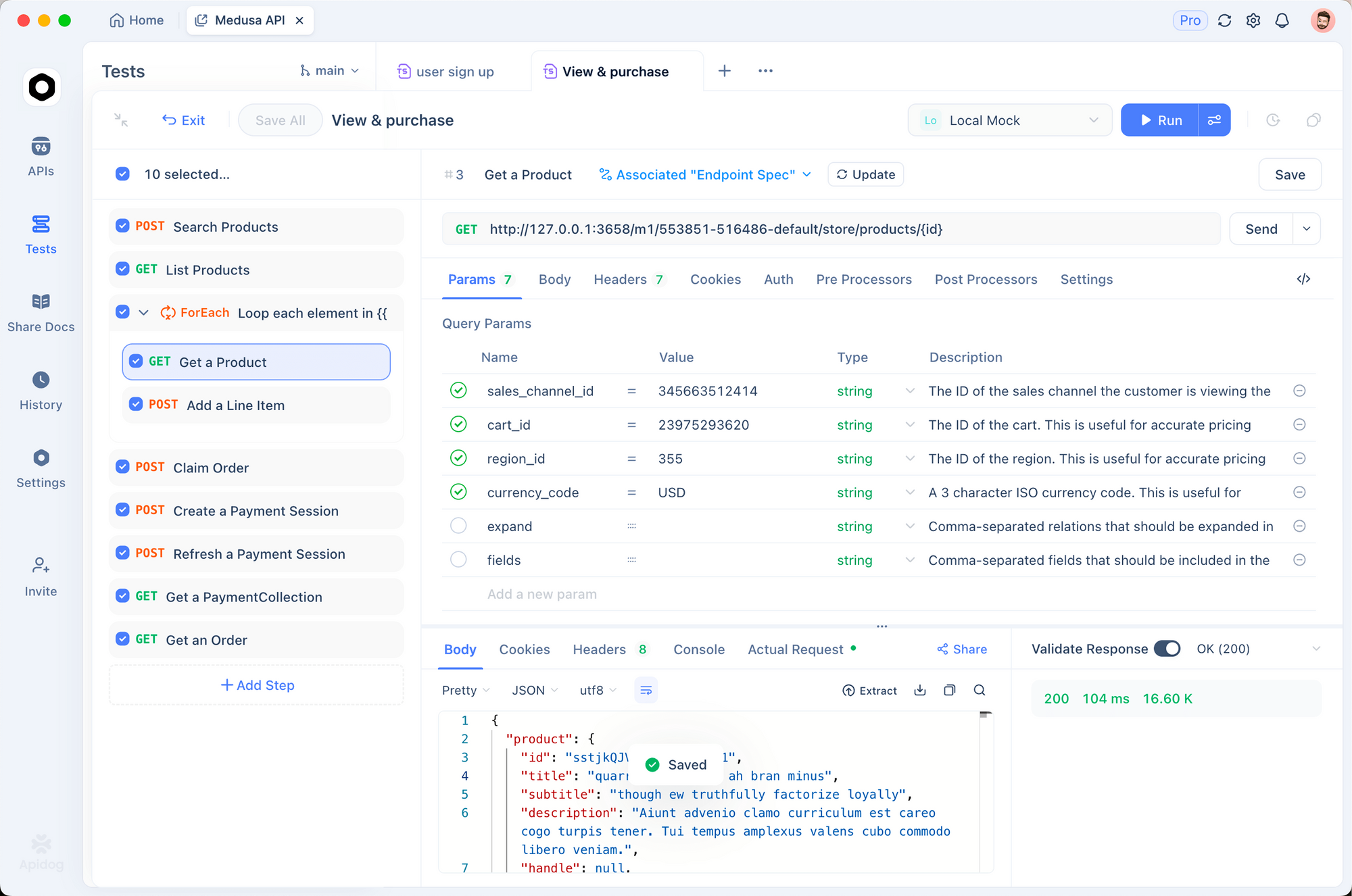
Troubleshoot common issues: If authentication fails, regenerate your API key. For token limits, chunk large codebases with "/summarize repo structure first." These adjustments ensure smooth operation.
Advanced Techniques: Leveraging DeepSeek in Claude Code for Optimal Performance
Beyond basics, advanced users exploit DeepSeek's strengths. Enable chain-of-thought (CoT) explicitly: "/think Solve this dynamic programming problem: [details]." V3.2-Speciale generates metacognitive traces, self-correcting via quasi-Monte Carlo simulations in text—boosting accuracy to 94.6% on HMMT.
For multi-file edits, use "/edit --files main.py utils.py Add logging decorators." The agent navigates dependencies, applying changes atomically. Benchmarks show 80.3% success on Terminal-Bench 2.0, outpacing Gemini-3.0-Pro.
Integrate external tools: Configure "/tool npm run build" for post-generation validation. DeepSeek's tool-use benchmark (84.7%) ensures reliable orchestration.
Monitor ethics: DeepSeek aligns with safety via RLHF, but audit outputs for biases in code assumptions. Use Apidog's schema validation to enforce secure patterns, like input sanitization.
Scale to teams: Share configs via dotfiles repos. In CI/CD, embed Claude Code scripts with DeepSeek for automated PR reviews—cutting review time by 40%.
Real-World Applications: DeepSeek-Powered Claude Code in Action
Consider a fintech project: "/generate Secure API for transaction processing using GraphQL." DeepSeek-V3.2 outputs schema, resolvers, and rate-limiting middleware, validated against OWASP standards.
In ML pipelines: "/agent Optimize this PyTorch model for edge deployment." It refactors for quantization, tests on simulated hardware, and documents trade-offs.
These cases demonstrate 2-3x productivity gains, substantiated by user reports on GitHub issues.
Conclusion
DeepSeek-V3.2 and DeepSeek-V3.2-Speciale transform Claude Code into a reasoning-centric powerhouse. From open-source loading to API-driven scalability, these models deliver benchmark-leading performance at fraction-of-the-cost pricing. Implement the steps outlined—starting with Apidog for API prototyping—and witness streamlined workflows.
Experiment today: Set up your environment, run a sample command, and iterate. The integration not only accelerates development but fosters deeper code understanding through transparent reasoning. As AI evolves, tools like these ensure developers remain at the forefront.