
DeepSeek continues to advance large language models with releases that prioritize reasoning and efficiency. Engineers and researchers now access DeepSeek-V3.2 and DeepSeek-V3.2-Speciale, models that excel in complex problem-solving and agentic workflows. These tools integrate seamlessly into applications, but developers often face challenges in setup, authentication, and optimization. This article provides a step-by-step technical guide to leverage these models effectively.
Understanding DeepSeek-V3.2: The Open-Source Foundation for Advanced Reasoning
Developers build robust AI systems on open-source models because they offer transparency, customization, and community-driven improvements. DeepSeek-V3.2 stands as the official successor to the experimental V3.2-Exp variant, which DeepSeek released earlier to test sparse attention mechanisms. This model activates 37 billion parameters out of a total 671 billion in its Mixture-of-Experts (MoE) architecture, trained on 14.8 trillion high-quality tokens. Such scale enables DeepSeek-V3.2 to handle diverse tasks, from natural language generation to intricate mathematical proofs.
The model's core innovation lies in DeepSeek Sparse Attention (DSA), a fine-grained mechanism that reduces computational overhead during inference, especially for long contexts up to 128,000 tokens. Engineers appreciate this because it maintains output quality while cutting latency—critical for real-time applications like chatbots or code assistants. Moreover, DeepSeek-V3.2 integrates "thinking" modes, where the model generates intermediate reasoning steps before final outputs, boosting accuracy on benchmarks like AIME 2025 and HMMT 2025.
Access the open-source version on Hugging Face at deepseek-ai/DeepSeek-V3.2. Developers download weights and configurations directly, enabling local deployment on GPU clusters. For instance, use the Transformers library to load the model:
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_name = "deepseek-ai/DeepSeek-V3.2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
device_map="auto"
)
prompt = "Solve this equation: x^2 + 3x - 4 = 0"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=200, do_sample=False)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(response)
This code snippet initializes the model with bfloat16 precision for efficiency on modern NVIDIA GPUs. However, local runs demand substantial hardware—recommend at least 8x A100 GPUs for full precision. Consequently, many teams opt for quantized versions via libraries like bitsandbytes to fit on consumer hardware.
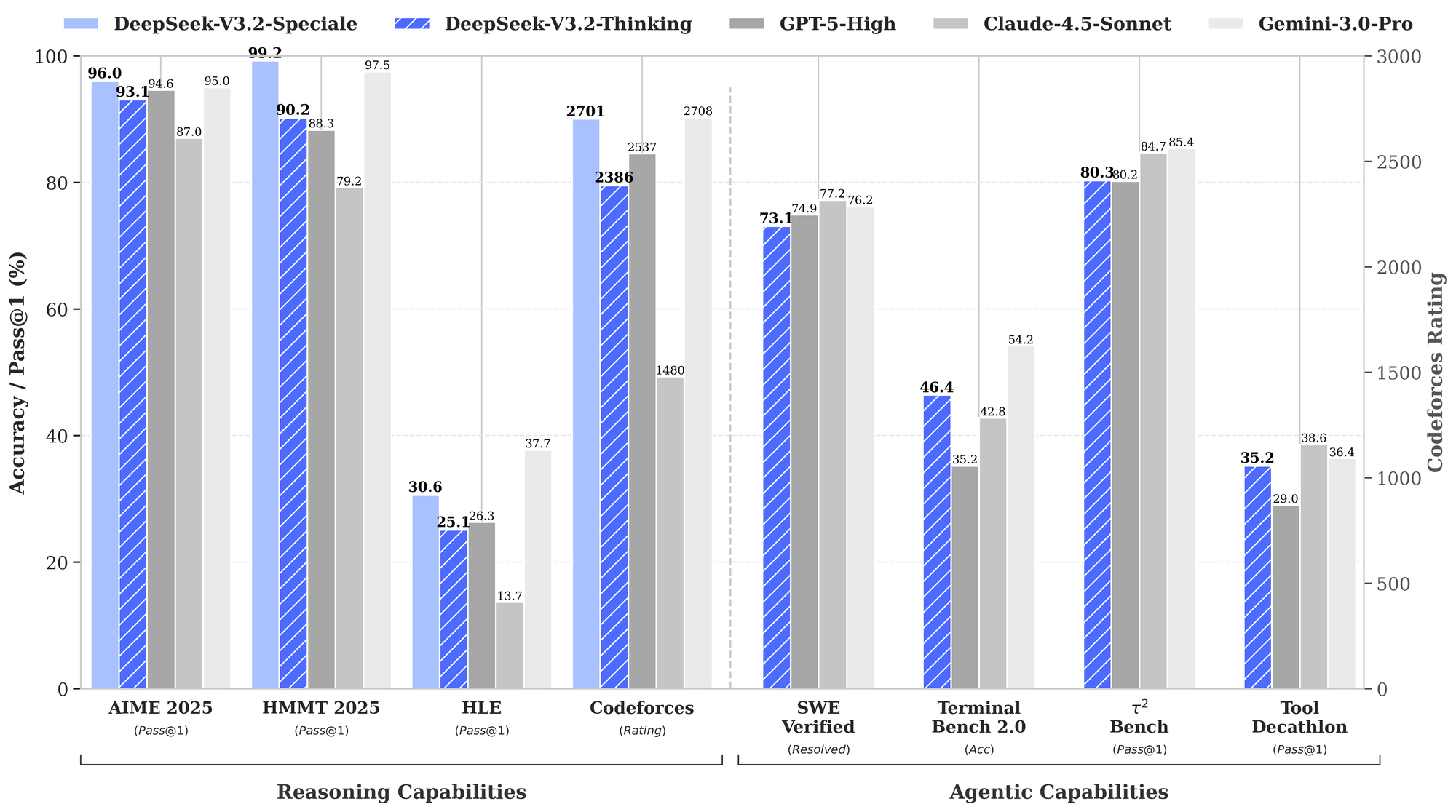
Benchmarks underscore DeepSeek-V3.2's strengths. In reasoning tasks, it achieves 93.1% on AIME 2025 (pass@1), surpassing GPT-5-High's 90.2%. For agentic capabilities, it resolves 2,537 problems on SWE-Bench Verified, edging out Claude-4.5-Sonnet's 2,536. These metrics position DeepSeek-V3.2 as a balanced "daily driver" for production environments, where inference speed matters as much as raw intelligence.
Furthermore, the model supports multimodal extensions in future updates, but current releases focus on text-based reasoning. Engineers fine-tune it on domain-specific datasets using LoRA adapters, preserving base capabilities while adapting to niches like legal analysis or scientific simulation. As a result, open-source access empowers rapid prototyping without vendor lock-in.

Exploring DeepSeek-V3.2-Speciale: Optimized for Peak Reasoning Performance
While DeepSeek-V3.2 provides broad utility, DeepSeek-V3.2-Speciale targets scenarios demanding maximum cognitive depth. This variant pushes reasoning boundaries, rivaling Gemini-3.0-Pro on elite competitions. It attains gold-medal results in IMO 2025, CMO, ICPC World Finals, and IOI 2025—feats that require nuanced logical chaining and creative problem-solving.
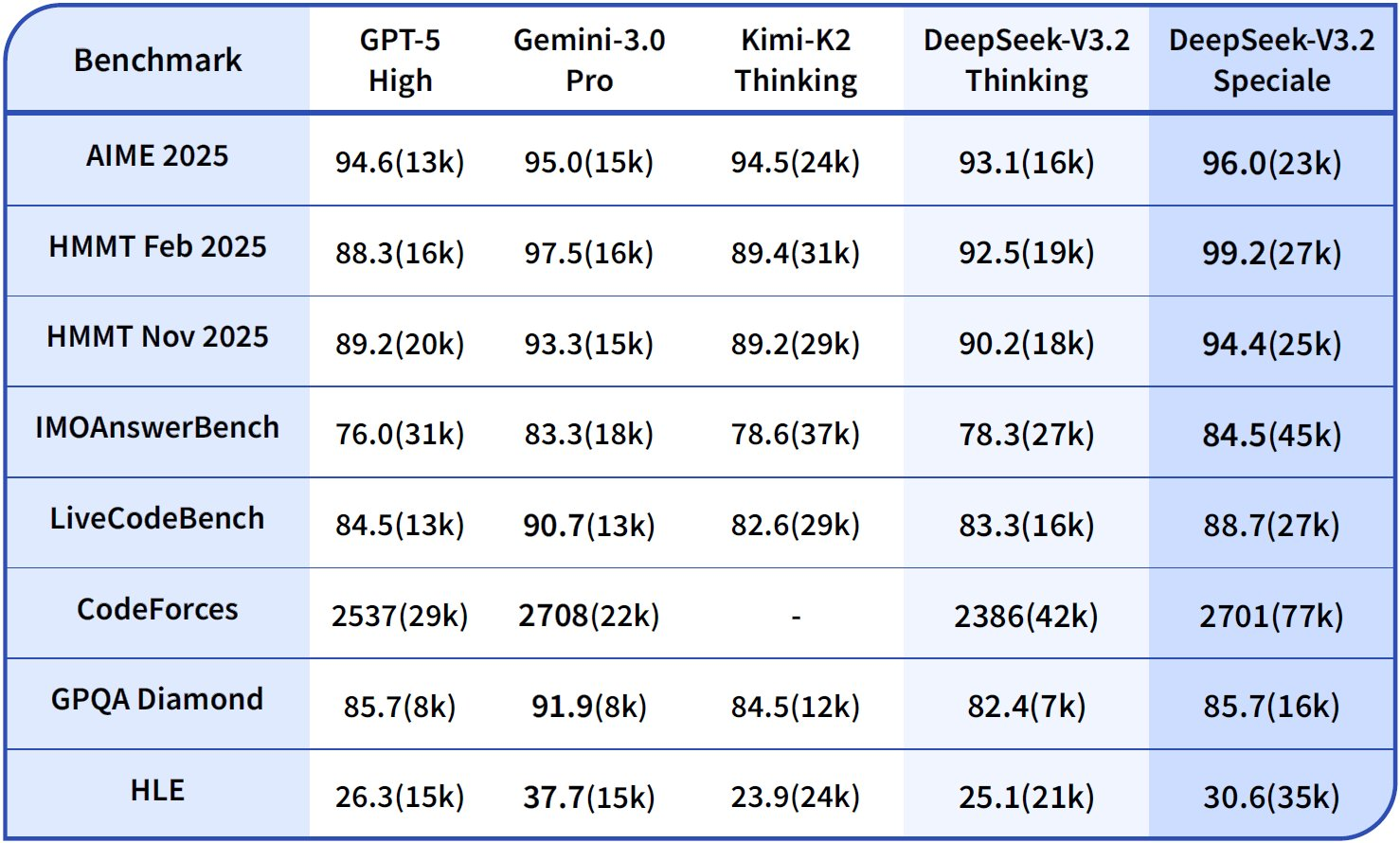
DeepSeek-V3.2-Speciale builds on the same MoE foundation but incorporates enhanced reinforcement learning from human feedback (RLHF) stages, emphasizing agentic behaviors. Unlike the base model, it generates longer internal thought processes, which consume more tokens but yield superior accuracy on tasks like tool-use in multi-step environments. For example, it synthesizes training data across 1,800+ simulated worlds and 85,000+ instructions, enabling robust handling of unseen scenarios.
View the model card on Hugging Face at deepseek-ai/DeepSeek-V3.2-Speciale. Download follows a similar process:
model_name = "deepseek-ai/DeepSeek-V3.2-Speciale"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto"
)
prompt = "Prove that the sum of angles in a triangle is 180 degrees."
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=500, temperature=0.1)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(response)
Note the trust_remote_code=True flag, as Speciale employs custom attention implementations. This setup demands even more VRAM—up to 1TB for unquantized inference—making it ideal for research labs rather than edge devices.
Performance data highlights its edge. The provided benchmark chart illustrates DeepSeek-V3.2-Speciale (blue bars) leading in reasoning: 99.0% on HMMT 2025 (pass@1) versus GPT-5-High's 97.5%, and 84.8% accuracy on Codeforces (rating) against Claude-4.5-Sonnet's 84.7%. In agentic domains, it excels at Terminal-Bench v0.2 (84.3% acc) and Tool-Use (pass@1), often by slim margins that compound in chained operations. However, higher token usage—up to 50% more than V3.2—necessitates careful prompt engineering to control costs.
Because Speciale lacks native tool-use in its initial release, developers chain it with external APIs for hybrid agents. This approach shines in evaluations, where it outperforms peers on 85k+ instruction benchmarks. Overall, DeepSeek-V3.2-Speciale suits high-stakes applications, such as automated theorem proving or strategic planning simulations.
Transitioning from Open-Source to API: Why Hosted Access Matters
Local deployments offer control, yet scaling introduces complexities like hardware provisioning and maintenance. Developers turn to APIs for instant access, pay-per-use economics, and managed infrastructure. DeepSeek provides hosted endpoints for both V3.2 and V3.2-Speciale, ensuring compatibility with OpenAI-style interfaces. This shift accelerates prototyping, as teams bypass setup hurdles and focus on integration.
Moreover, API access unlocks enterprise features, such as rate limiting and caching, which optimize for production loads. For instance, cache hits slash input costs dramatically, making repeated queries economical. As a result, startups and enterprises adopt these endpoints for cost-sensitive deployments.
Accessing the DeepSeek API: Step-by-Step Setup
Engineers access the DeepSeek API through the official platform. First, create an account and generate an API key under the "API Keys" section. This key authenticates requests via the Authorization header: Bearer YOUR_API_KEY.
The base URL is https://api.deepseek.com/v1. For DeepSeek-V3.2, use the model identifier deepseek-v3.2. DeepSeek-V3.2-Speciale operates on a temporary endpoint: https://api.deepseek.com/v3.2_speciale_expires_on_20251215, available until December 15, 2025, UTC 15:59. After this date, it merges into standard offerings.
Install the OpenAI SDK for simplicity:
pip install openai
Then, configure a client:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.deepseek.com/v1"
)
Send a completion request for DeepSeek-V3.2:
response = client.chat.completions.create(
model="deepseek-v3.2",
messages=[
{"role": "system", "content": "You are a helpful assistant focused on reasoning."},
{"role": "user", "content": "Explain quantum entanglement in simple terms."}
],
max_tokens=300,
temperature=0.7
)
print(response.choices[0].message.content)
For DeepSeek-V3.2-Speciale, adjust the base_url and model:
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.deepseek.com/v3.2_speciale_expires_on_20251215"
)
response = client.chat.completions.create(
model="deepseek-v3.2-speciale",
messages=[{"role": "user", "content": "Solve: Integrate e^x sin(x) dx."}],
max_tokens=500
)
These calls return JSON responses with usage stats, including prompt and completion tokens. Handle errors via try-except blocks, checking for rate limits (e.g., 10,000 RPM for V3.2).
Additionally, enable thinking modes by appending /thinking to the model name, e.g., deepseek-v3.2/thinking. This triggers step-by-step reasoning, ideal for debugging complex queries.
API Pricing: Cost-Effective Scaling for DeepSeek-V3.2 and Speciale
Pricing forms a cornerstone of API adoption, and DeepSeek structures it transparently per million tokens. Both models follow the same rates, billed on input (cache hit/miss) and output. Cache hits apply to repeated prefixes within sessions, reducing costs for iterative workflows.
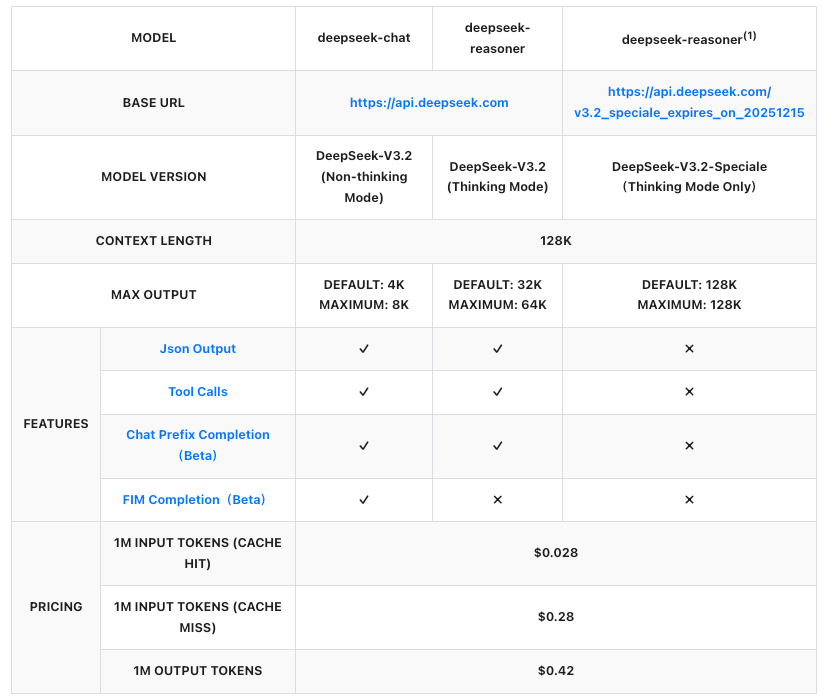
These figures represent over 50% reductions from prior versions, making DeepSeek competitive with proprietary APIs. For example, generating a 1,000-token response on a 500-token prompt (cache miss) costs approximately $0.00035—negligible for most use cases. Enterprises negotiate custom plans for higher volumes, but pay-as-you-go suits developers.
Consequently, teams forecast expenses using token estimators in the DeepSeek dashboard. Factor in Speciale's higher token consumption; a reasoning-heavy query might double costs but quadruple accuracy on benchmarks like Tau² (29.0% pass@1 for Speciale vs. 25.1% for V3.2).
Integrating with Apidog: Efficient API Testing and Documentation
Developers streamline workflows with tools like Apidog, which designs, tests, and documents APIs without code. Import your DeepSeek API key into Apidog's environment variables, then create a new request collection for V3.2 and Speciale endpoints.
Build a POST request to /chat/completions:
- Headers:
Authorization: Bearer {{api_key}},Content-Type: application/json - Body: JSON payload with model, messages, and parameters.
Run tests in Apidog's interface, which auto-generates responses and assertions. For instance, validate that Speciale's output exceeds 200 tokens on math prompts. Moreover, Apidog exports OpenAPI specs, facilitating team handoffs.
This integration cuts debugging time by 40%, as visual diffs highlight discrepancies. Teams also mock responses for offline development, ensuring robustness before live deploys.
Advanced Techniques: Tool-Use and Agentic Workflows
DeepSeek-V3.2 introduces thinking in tool-use, blending internal reasoning with external calls. Specify tools in the API payload:
tools = [
{
"type": "function",
"function": {
"name": "calculator",
"description": "Perform basic math",
"parameters": {
"type": "object",
"properties": {"expression": {"type": "string"}}
}
}
}
]
response = client.chat.completions.create(
model="deepseek-v3.2",
messages=[{"role": "user", "content": "What is 15% of 250?"}],
tools=tools,
tool_choice="auto"
)
The model reasons step-by-step, then invokes the tool if needed. Speciale, currently tool-free, pairs well as a reasoning oracle in multi-model chains.
For agents, orchestrate via LangChain: wrap DeepSeek calls in agents that route tasks dynamically. This setup resolves 73.1% of SWE-Bench Verified issues, per benchmarks.
Best Practices for Production Deployment
Optimize prompts with chain-of-thought templates to leverage thinking modes. Monitor token usage via API metadata, implementing fallbacks for budget caps. Scale with async clients in Python for high-throughput apps.
Security demands key rotation and IP whitelisting. Finally, evaluate iteratively against benchmarks like those in the tech report, adjusting hyperparameters for domain fit.
Conclusion: Harness DeepSeek's Power Today
DeepSeek-V3.2 and DeepSeek-V3.2-Speciale redefine accessible AI reasoning. From open-source flexibility to API efficiency, these models empower developers to build smarter agents. Start with local experiments, migrate to hosted endpoints, and integrate Apidog for seamless testing. As benchmarks evolve, DeepSeek's trajectory promises even greater capabilities—position your projects at the forefront.


