
Are you looking to deploy Deepseek R1 —one of the most powerful large language models—on a cloud platform? Whether you're working on AWS, Azure, or Digital Ocean, this guide has got you covered. By the end of this post, you’ll have a clear roadmap to get your Deepseek R1 model up and running with ease. Plus, we’ll show you how tools like Apidog can help streamline API testing during deployment.
Why Deploy Deepseek R1 in the Cloud?
Deploying Deepseek R1 in the cloud is not just about scalability; it's about leveraging the power of GPUs and serverless infrastructure to handle massive workloads efficiently. With its 671B parameters, Deepseek R1 demands robust hardware and optimized configurations. The cloud provides flexibility, cost-effectiveness, and high-performance resources that make deploying such models feasible even for smaller teams.
In this guide, we’ll walk you through deploying Deepseek R1 on three popular platforms: AWS, Azure, and Digital Ocean. We’ll also share tips to optimize performance and integrate tools like Apidog for API management.
Preparing Your Environment
Before jumping into deployment, let’s prepare our environment. This involves setting up authentication tokens, ensuring GPU availability, and organizing your files.
Authentication Tokens
Every cloud provider requires some form of authentication. For example:
- On AWS , you’ll need an IAM role with permissions to access S3 buckets and EC2 instances.
- On Azure , you can use simplified authentication experiences provided by Azure Machine Learning SDKs.
- On Digital Ocean , generate an API token from your account dashboard.
These tokens are crucial because they allow secure communication between your local machine and the cloud platform.
File Organization
Organize your files systematically. If you’re using Docker (which is highly recommended), create a Dockerfile containing all dependencies. Tools like Tensorfuse provide pre-built templates for deploying Deepseek R1. Similarly, IBM Cloud users should upload their model files to Object Storage before proceeding.

Option 1: Deploying Deepseek R1 on AWS Using Tensorfuse
Let’s start with Amazon Web Services (AWS), one of the most widely used cloud platforms. AWS is like a Swiss Army knife—it has tools for every task, from storage to compute power. In this section, we’ll focus on deploying Deepseek R1 using Tensorfuse, which simplifies the process significantly.
Why Build with Deepseek-R1?
Before diving into the technical details, let’s understand why Deepseek R1 stands out:
- High Performance on Evaluations: Achieves strong results on industry-standard benchmarks, scoring 90.8% on MMLU and 79.8% on AIME 2024.
- Advanced Reasoning: Handles multi-step logical reasoning tasks with minimal context, excelling in benchmarks like LiveCodeBench (Pass@1-COT) with a score of 65.9%.
- Multilingual Support: Pretrained on diverse linguistic data, making it adept at multilingual understanding.
- Scalable Distilled Models: Smaller distilled variants (2B, 7B, and 70B) offer cheaper options without compromising on cost.
These strengths make Deepseek R1 an excellent choice for production-ready applications, from chatbots to enterprise-level data analytics.
Prerequisites
Before you begin, ensure you have configured Tensorfuse on your AWS account. If you haven’t done that yet, follow the Getting Started guide. This setup is like preparing your workspace before starting a project—it ensures everything is in place for a smooth process.
Step 1: Set Your API Authentication Token
Generate a random string that will be used as your API authentication token. Store it as a secret in Tensorfuse using the following command:
tensorkube secret create vllm-token VLLM_API_KEY=vllm-key --env default
Ensure that in production, you use a randomly generated token. You can quickly generate one using openssl rand -base64 32 and remember to keep it safe as Tensorfuse secrets are opaque.
Step 2: Prepare the Dockerfile
We will use the official vLLM OpenAI image as our base image. This image comes with all the necessary dependencies to run vLLM.
Here’s the Dockerfile configuration:
# Dockerfile for Deepseek-R1-671B
FROM vllm/vllm-openai:latest
# Enable HF Hub Transfer
ENV HF_HUB_ENABLE_HF_TRANSFER 1
# Expose port 80
EXPOSE 80
# Entrypoint with API key
ENTRYPOINT ["python3", "-m", "vllm.entrypoints.openai.api_server", \
"--model", "deepseek-ai/DeepSeek-R1", \
"--dtype", "bfloat16", \
"--trust-remote-code", \
"--tensor-parallel-size","8", \
"--max-model-len", "4096", \
"--port", "80", \
"--cpu-offload-gb", "80", \
"--gpu-memory-utilization", "0.95", \
"--api-key", "${VLLM_API_KEY}"]
This configuration ensures that the vLLM server is optimized for Deepseek R1’s specific requirements, including GPU memory utilization and tensor parallelism .
Step 3: Deployment Configuration
Create a deployment.yaml file to define your deployment settings:
# deployment.yaml for Deepseek-R1-671B
gpus: 8
gpu_type: h100
secret:
- vllm-token
min-scale: 1
readiness:
httpGet:
path: /health
port: 80
Deploy your service using the following command:
tensorkube deploy --config-file ./deployment.yaml
This command sets up an autoscaling production LLM service ready to serve authenticated requests.
Step 4: Accessing the Deployed App
Once the deployment is successful, you can test your endpoint using curl or Python’s OpenAI client library. Here’s an example using curl:
curl --request POST \
--url YOUR_APP_URL/v1/completions \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer vllm-key' \
--data '{
"model": "deepseek-ai/DeepSeek-R1",
"prompt": "Earth to Robotland. What's up?",
"max_tokens": 200
}'
For Python users, here’s a sample snippet:
import openai
# Replace with your actual URL and token
base_url = "YOUR_APP_URL/v1"
api_key = "vllm-key"
openai.api_base = base_url
openai.api_key = api_key
response = openai.Completion.create(
model="deepseek-ai/DeepSeek-R1",
prompt="Hello, Deepseek R1! How are you today?",
max_tokens=200
)
print(response)
Option 2: Deploying Deepseek R1 on Azure
Deploying Deepseek R1 on Azure Machine Learning (Azure ML) is a streamlined process that leverages the platform's robust infrastructure and advanced tools for real-time inference. In this section, we’ll walk you through deploying Deepseek R1 using Azure ML’s Managed Online Endpoints. This approach ensures scalability, efficiency, and ease of management.
Step 1: Create a Custom Environment for vLLM on Azure ML
To begin, we need to create a custom environment tailored for vLLM, which will serve as the backbone for deploying Deepseek R1. The vLLM framework is optimized for high-throughput inference, making it ideal for handling large language models like Deepseek R1.
1.1: Define the Dockerfile :We start by creating a Dockerfile that specifies the environment for our model. The vLLM base container includes all necessary dependencies and drivers, ensuring a smooth setup:
FROM vllm/vllm-openai:latest
ENV MODEL_NAME deepseek-ai/DeepSeek-R1-Distill-Llama-8B
ENTRYPOINT python3 -m vllm.entrypoints.openai.api_server --model $MODEL_NAME $VLLM_ARGS
This Dockerfile allows us to pass the model name via an environment variable (MODEL_NAME), enabling flexibility in selecting the desired model during deployment . For instance, you can easily switch between different versions of Deepseek R1 without modifying the underlying code.
1.2: Log into Azure ML Workspace: Next, log into your Azure ML workspace using the Azure CLI. Replace <subscription ID>, <Azure Machine Learning workspace name>, and <resource group> with your specific details:
az account set --subscription <subscription ID>
az configure --defaults workspace=<Azure Machine Learning workspace name> group=<resource group>
This step ensures that all subsequent commands are executed within the context of your workspace.
1.3: Create the Environment Configuration File: Now, create an environment.yml file to define the environment settings. This file references the Dockerfile we created earlier:
$schema: https://azuremlschemas.azureedge.net/latest/environment.schema.json
name: r1
build:
path: .
dockerfile_path: Dockerfile
1.4: Build the Environment: With the configuration file ready, build the environment using the following command:
az ml environment create -f environment.yml
This step compiles the environment, making it available for use in your deployment.
Step 2: Deploy the Azure ML Managed Online Endpoint
Once the environment is set up, we move on to deploying the Deepseek R1 model using Azure ML’s Managed Online Endpoints. These endpoints provide scalable, real-time inference capabilities, making them perfect for production-grade applications.
2.1: Create the Endpoint Configuration File: Start by creating an endpoint.yml file to define the Managed Online Endpoint:
$schema: https://azuremlsdk2.blob.core.windows.net/latest/managedOnlineEndpoint.schema.json
name: r1-prod
auth_mode: key
This configuration specifies the endpoint’s name (r1-prod) and authentication mode (key). You can retrieve the endpoint’s scoring URI and API keys later for testing purposes.
2.2: Create the Endpoint: Use the following command to create the endpoint:
az ml online-endpoint create -f endpoint.yml
2.3: Retrieve the Docker Image Address: Before proceeding, retrieve the address of the Docker image created in Step 1. Navigate to Azure ML Studio > Environments > r1 to locate the image address. It will look something like this:
xxxxxx.azurecr.io/azureml/azureml_xxxxxxxx
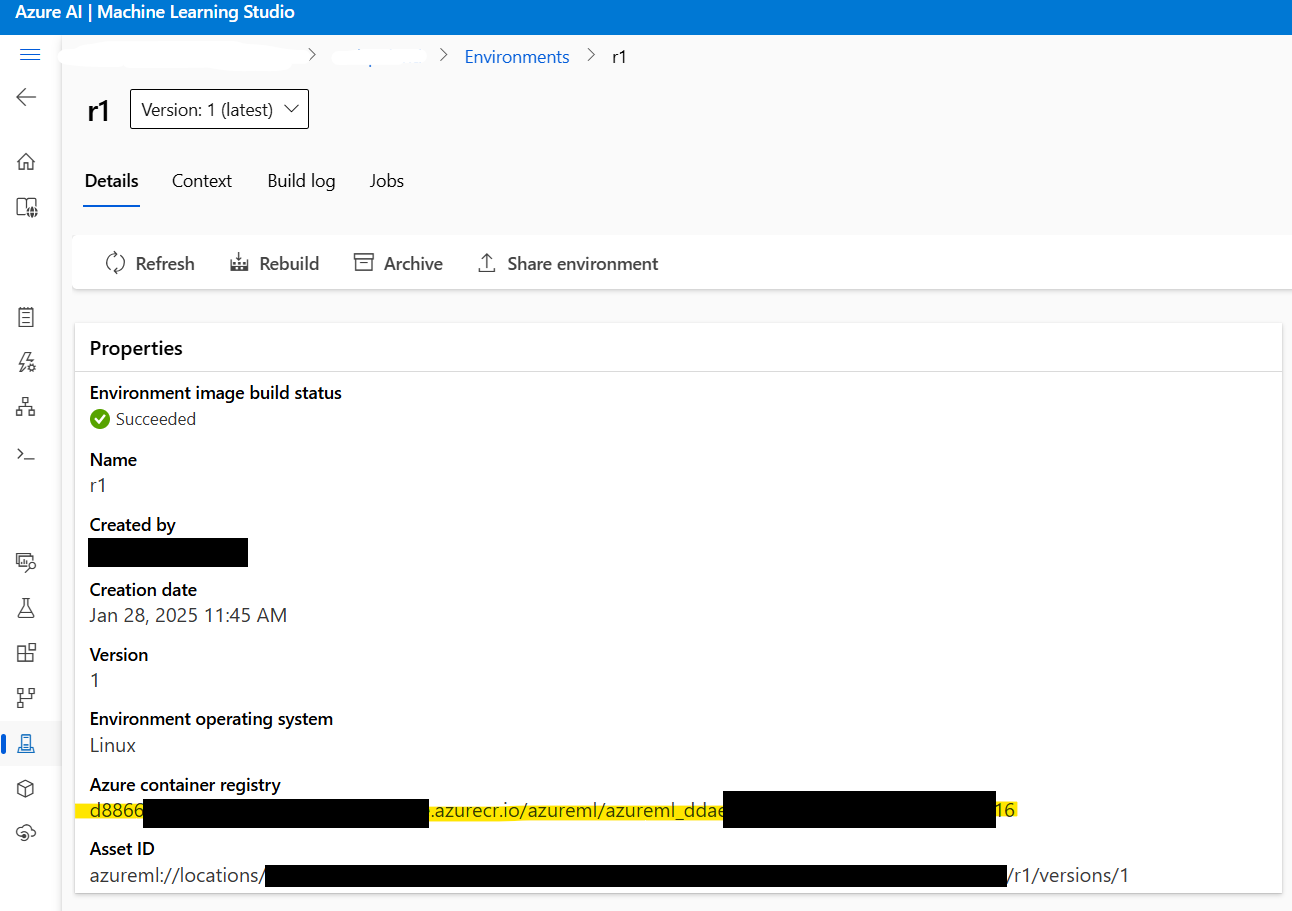
2.4: Create the Deployment Configuration File: Next, create a deployment.yml file to configure the deployment settings. This file specifies the model, instance type, and other parameters:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: current
endpoint_name: r1-prod
environment_variables:
MODEL_NAME: deepseek-ai/DeepSeek-R1-Distill-Llama-8B
VLLM_ARGS: "" # Optional arguments for vLLM runtime
environment:
image: xxxxxx.azurecr.io/azureml/azureml_xxxxxxxx # Paste Docker image address here
inference_config:
liveness_route:
port: 8000
path: /ping
readiness_route:
port: 8000
path: /health
scoring_route:
port: 8000
path: /
instance_type: Standard_NC24ads_A100_v4
instance_count: 1
request_settings: # Optional but important for optimizing throughput
max_concurrent_requests_per_instance: 32
request_timeout_ms: 60000
liveness_probe:
initial_delay: 10
period: 10
timeout: 2
success_threshold: 1
failure_threshold: 30
readiness_probe:
initial_delay: 120 # Wait for 120 seconds before probing, allowing the model to load peacefully
period: 10
timeout: 2
success_threshold: 1
failure_threshold: 30
Key parameters to consider:
instance_count: Defines how many nodes ofStandard_NC24ads_A100_v4to spin up. Increasing this value scales throughput linearly but also increases cost.max_concurrent_requests_per_instance: Controls the number of concurrent requests allowed per instance. Higher values increase throughput but may raise latency.request_timeout_ms: Specifies the maximum time (in milliseconds) the endpoint waits for a response before timing out. Adjust this based on your workload requirements.
2.5: Deploy the Model: Finally, deploy the Deepseek R1 model using the following command:
az ml online-deployment create -f deployment.yml --all-traffic
This step completes the deployment, making the model accessible via the specified endpoint .
Step 3: Testing the Deployment
Once the deployment is complete, it’s time to test the endpoint to ensure everything is functioning as expected.
3.1: Retrieve Endpoint Details: Use the following commands to retrieve the endpoint’s scoring URI and API keys:
az ml online-endpoint show -n r1-prod
az ml online-endpoint get-credentials -n r1-prod
3.2: Stream Responses Using OpenAI SDK: For streaming responses, you can use the OpenAI SDK:
from openai import OpenAI
url = "https://r1-prod.polandcentral.inference.ml.azure.com/v1"
client = OpenAI(base_url=url, api_key="xxxxxxxx")
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-R1-Distill-Llama-8B",
messages=[
{"role": "user", "content": "What is better, summer or winter?"},
],
stream=True
)
for chunk in response:
delta = chunk.choices[0].delta
if hasattr(delta, "content"):
print(delta.content, end="", flush=True)
Step 4: Monitoring and Autoscaling
Azure Monitor provides comprehensive insights into resource utilization, including GPU metrics. When under constant load, you’ll notice that vLLM consumes approximately 90% of GPU memory, with GPU utilization nearing 100%. These metrics help you fine-tune performance and optimize costs.
To enable autoscaling, configure scaling policies based on traffic patterns. For example, you can increase the instance_count during peak hours and reduce it during off-peak times to balance performance and cost.
Option 3: Deploying Deepseek R1 on Digital Ocean
Finally, let’s discuss deploying Deepseek R1 on Digital Ocean , known for its simplicity and affordability.
Prerequisites
Before diving into the deployment process, let’s ensure you have everything you need:
- DigitalOcean Account: If you don’t already have one, sign up for a DigitalOcean account. New users receive a $100 credit for the first 60 days, which is perfect for experimenting with GPU-powered droplets.
- Bash Shell Familiarity: You’ll be using the terminal to interact with your droplet, download dependencies, and execute commands. Don’t worry if you’re not an expert—each command will be provided step by step.
- GPU Droplet: DigitalOcean now offers GPU droplets specifically designed for AI/ML workloads. These droplets come equipped with NVIDIA H100 GPUs, making them ideal for deploying large models like Deepseek R1.
With these prerequisites in place, you’re ready to move forward.
Setting Up the GPU Droplet
The first step is to set up your machine. Think of this as preparing the canvas before painting—you want everything ready before diving into the details.
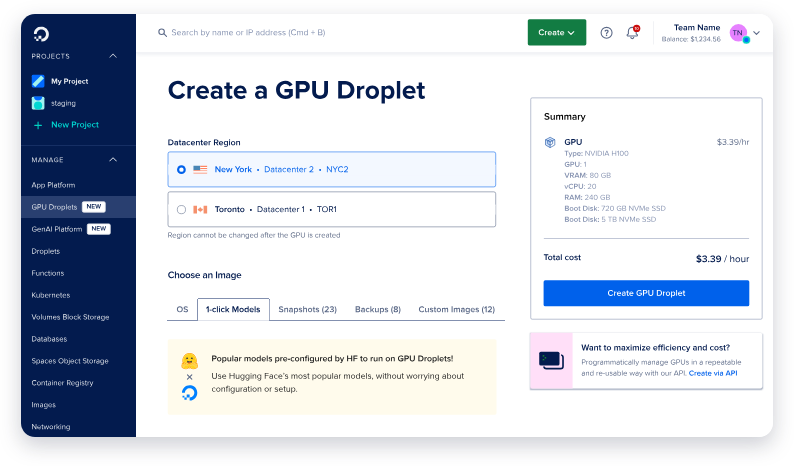
Step 1: Create a New GPU Droplet
- Log in to your DigitalOcean account and navigate to the Droplets section.
- Click on Create Droplet and select the AI/ML Ready operating system. This OS comes pre-configured with CUDA drivers and other dependencies needed for GPU acceleration.
- Choose a single NVIDIA H100 GPU unless you plan to deploy the largest 671B parameter version of Deepseek R1, which may require multiple GPUs.
- Once your droplet is created, wait for it to spin up. This process typically takes just a few minutes.
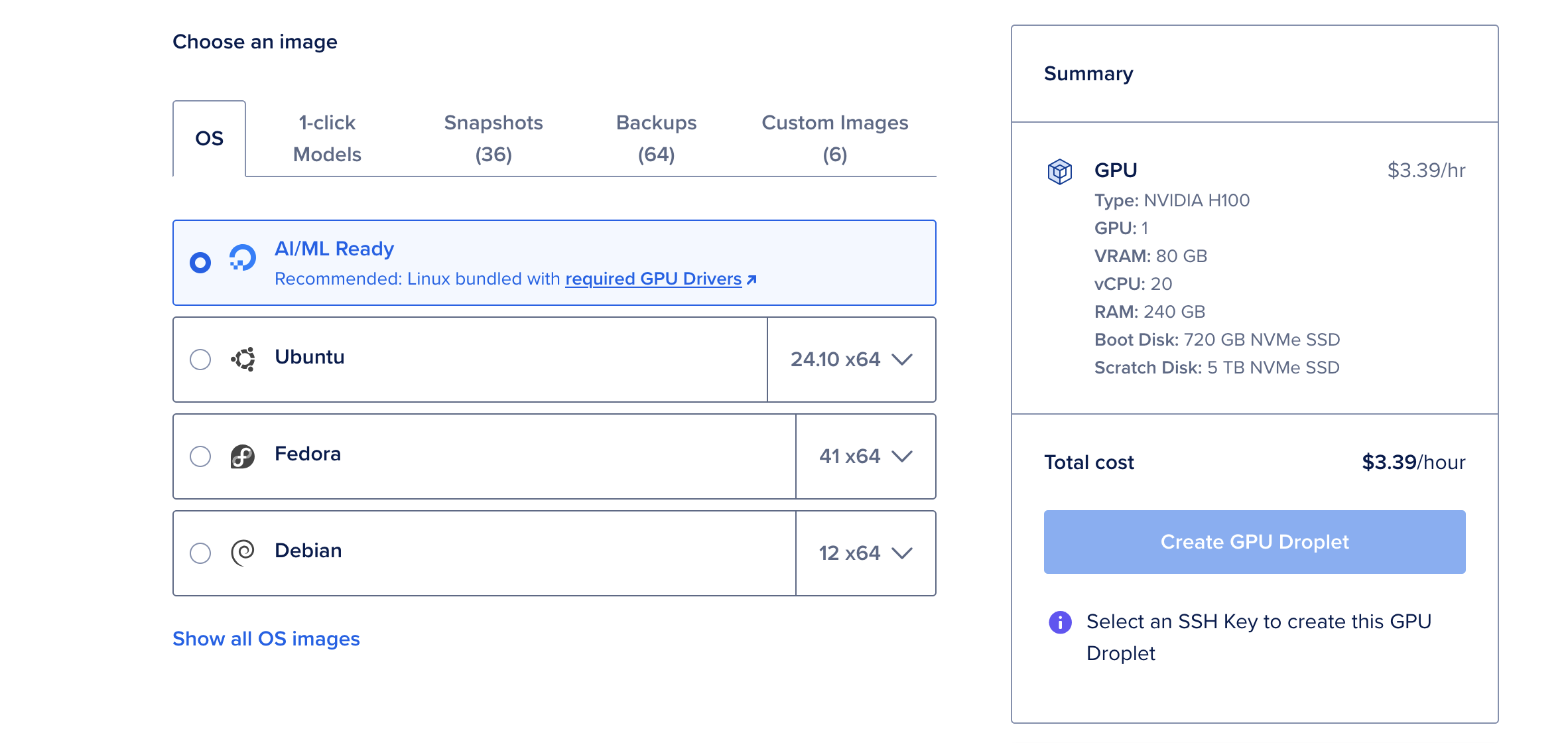
Why Choose the H100 GPU?
The NVIDIA H100 GPU is a powerhouse, offering 80GB of vRAM, 240GB of RAM, and 720GB of storage. At $6.47 per hour, it’s a cost-effective option for deploying large language models like Deepseek R1. For smaller models, such as the 70B parameter version, a single H100 GPU is more than sufficient.
Installing Ollama & Deepseek R1
Now that your GPU droplet is up and running, it’s time to install the tools needed to run Deepseek R1. We’ll use Ollama, a lightweight framework designed to simplify the deployment of large language models.
Step 1: Open the Web Console
From your droplet’s details page, click the Web Console button located in the top-right corner. This opens a terminal window directly in your browser, eliminating the need for SSH configuration.
Step 2: Install Ollama
In the terminal, paste the following command to install Ollama:
curl -fsSL https://ollama.com/install.sh | sh
This script automates the installation process, downloading and configuring all necessary dependencies. The installation may take a few minutes, but once complete, your machine will be ready to run Deepseek R1.
Step 3: Run Deepseek R1
With Ollama installed, executing Deepseek R1 is as simple as running a single command. For this demonstration, we’ll use the 70B parameter version, which strikes a balance between performance and resource usage:
ollama run deepseek-r1:70b
The first time you run this command, it will download the model (approximately 40GB) and load it into memory. This process can take several minutes, but subsequent runs will be much faster since the model is cached locally.
Once the model is loaded, you’ll see an interactive prompt where you can start interacting with Deepseek R1. It’s like having a conversation with a highly intelligent assistant!
Testing and Monitoring with Apidog
Once your Deepseek R1 model is deployed, it’s time to test and monitor its performance. This is where Apidog shines. Test DeepSeek API here.
What Is Apidog?
Apidog is a powerful API testing tool designed to simplify debugging and validation. With its intuitive interface, you can quickly create test cases, mock responses, and monitor API health.
Why Use Apidog?
- Ease of Use : No coding required! Drag-and-drop functionality lets you build tests visually.
- Integration Capabilities : Seamlessly integrates with CI/CD pipelines, making it ideal for DevOps workflows.
- Real-Time Insights : Monitor latency, error rates, and throughput in real-time.
By integrating Apidog into your workflow, you can ensure that your Deepseek R1 deployment remains reliable and performs optimally under varying loads.
Conclusion
Deploying Deepseek R1 in the cloud doesn’t have to be daunting. By following the steps outlined above, you can successfully set up this cutting-edge model on AWS, Azure, or Digital Ocean. Remember to leverage tools like Apidog to streamline testing and monitoring processes.


