
Cohere provides developers access to sophisticated Large Language Models (LLMs) capable of understanding and generating human-like text. To interact with these models programmatically, you need an API key. This key acts as your unique identifier and password, allowing Cohere's systems to authenticate your requests and track your usage.
This guide will walk you through the essential steps: obtaining your API key, understanding the critical differences between key types (especially regarding costs and usage limits), and performing a simple initial test using the Apidog tool to ensure your key is working correctly.
Step 1: Obtaining Your Cohere API Key
Getting your key is the first and most crucial step. Cohere makes this process relatively simple through their online dashboard.
- Navigate to the Cohere Dashboard: Open your web browser and go to the main Cohere platform access point. You'll typically find a login or sign-up page.
- Access Your Account:
- If you already have a Cohere account, log in using your credentials.
- If you are new to Cohere, you'll need to sign up for an account. Follow the registration process, which usually involves providing an email address and setting a password.
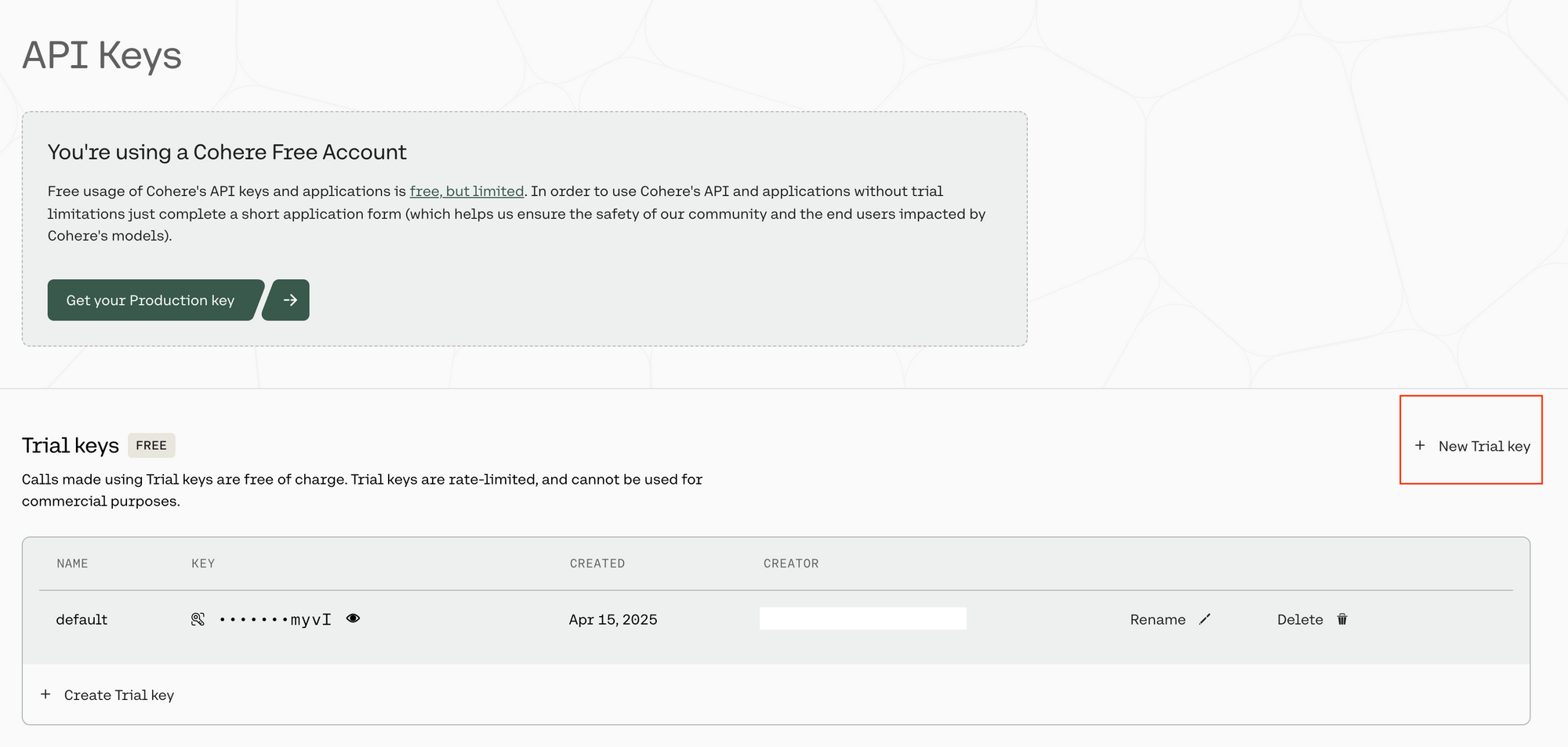
Locate the API Keys Section: Once you are successfully logged into the Cohere dashboard, look for a section specifically dedicated to managing API Keys. This might be under account settings, a developer section, or directly accessible via a menu item labeled "API Keys". The interface is designed to be user-friendly, so it should be relatively prominent.
Initiate Key Generation: Within the API Keys section, you will find an option to create a new key. You will likely see choices differentiating between key types, most notably "Trial Key" and potentially "Production Key". For initial testing and learning, select the option to generate a Trial Key.
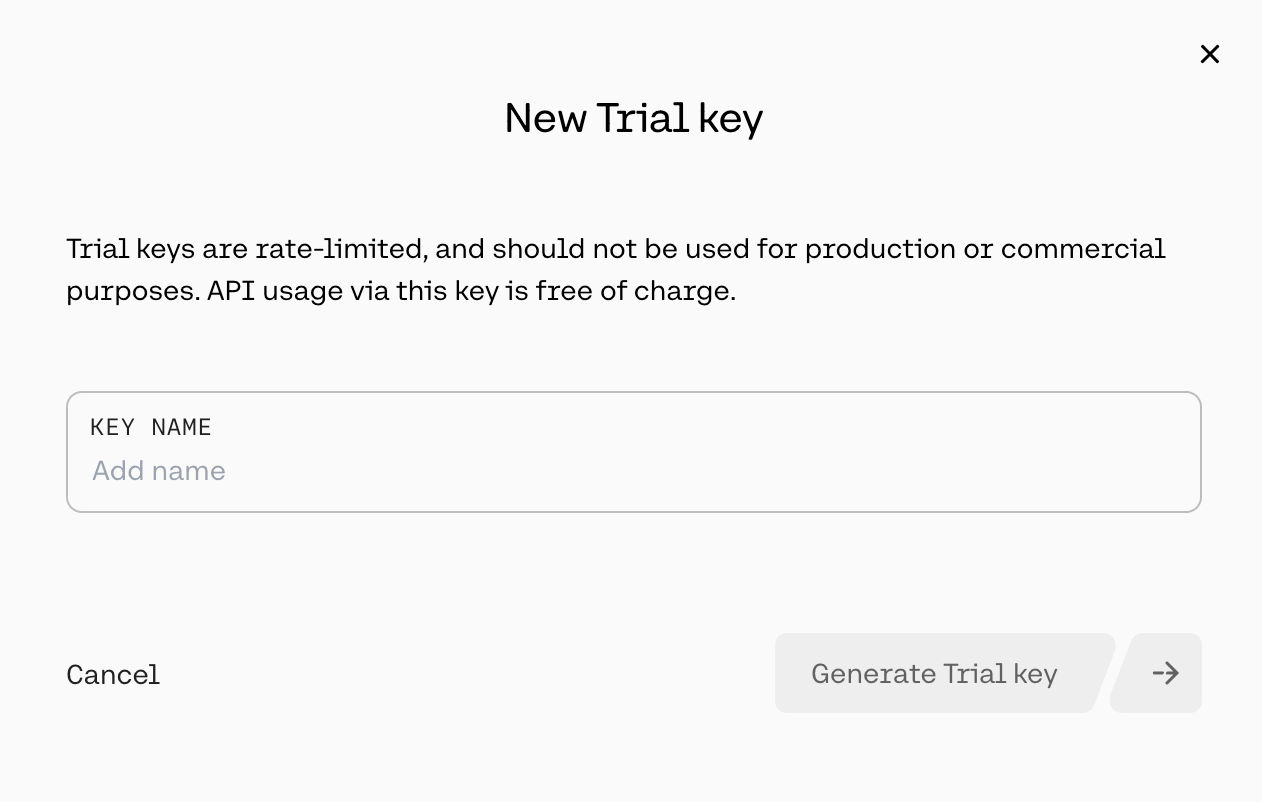
Assign a Name: A prompt will ask you to name your key. Choose a descriptive name that will help you remember its purpose later, especially if you generate multiple keys for different projects. Examples include "MyFirstTestKey", "LearningProjectKey", or "ApidogTestingKey".
Generate and Secure Your Key: Click the button to confirm and generate the key (e.g., "Generate Trial Key"). Cohere will then display your newly generated API key. This is the only time the full key will be shown. It is absolutely essential that you copy this key immediately and store it in a very secure location, such as a password manager or a secure note. Treat it with the same level of security as a password. Do not share it publicly, embed it directly in client-side code, or commit it to version control systems like Git. Once you close the pop-up window or navigate away, you cannot retrieve the full key again for security reasons (though you can see the key's name and potentially its first/last few characters in the dashboard). If you lose it, you will need to generate a new one.
With your API key copied and secured, you're ready to understand what you can do with it and the associated rules.
Step 2: Understanding Key Types, Costs, and Usage Limits
Not all Cohere API keys are created equal. The type of key you have dictates how much you can use the API, how quickly, and whether it incurs costs. Understanding these differences is vital to avoid unexpected interruptions or charges.
A. Trial API Keys: Free for Evaluation
When you first sign up or generate a key without setting up billing, you typically receive a Trial Key. These are designed for exploration, learning, and small-scale testing.
- Cost: Trial keys are free to use. You won't be billed for usage associated with a trial key.
- Overall Usage Cap: The most significant restriction is a monthly limit of 1,000 total API calls across all Cohere endpoints combined. This means every request you make (whether to Chat, Embed, Rerank, etc.) counts towards this monthly total. Once you hit 1,000 calls in a calendar month, your key will stop working until the next month begins.
- Rate Limits (Requests Per Minute - RPM): To ensure fair usage and system stability, Trial keys also have strict rate limits, restricting how many requests you can send within a one-minute window to specific endpoints. These are crucial to be aware of, as exceeding them will result in
429 Too Many Requestserrors. Key Trial rate limits include: - Chat Endpoint (
/v2/chat): 20 requests per minute. This is the endpoint used for conversational AI, text generation, summarization, etc. - Embed Endpoint (
/v2/embed) - Text: 100 requests per minute. Used for generating vector embeddings for text data (semantic search, clustering). - Embed Endpoint (
/v2/embed) - Images: 5 requests per minute. Used for generating vector embeddings for image data (multimodal search). - Rerank Endpoint (
/v2/rerank): 10 requests per minute. Used to improve the relevance ranking of search results. - Tokenize Endpoint (
/v2/tokenize): 100 requests per minute. Used to see how text is broken down into tokens by Cohere's models. - Classify Endpoint (
/v1/classify): 100 requests per minute. Used for text classification tasks (legacy, fine-tuning preferred now). - Legacy Endpoints (Summarize, Generate): 5 requests per minute.
- Other/Default: Limits may apply to other less common or management endpoints.
Trial keys are ideal for:
- Learning how the Cohere API works.
- Experimenting with different models and parameters in the Playground or via direct calls.
- Building small personal projects or prototypes with limited expected usage.
- Evaluating Cohere's capabilities before committing to paid usage.
If you consistently hit the monthly cap or the per-minute rate limits, it's a strong indicator that you need to upgrade to a Production key.
B. Production API Keys: For Building and Scaling
When you're ready to build applications with real users, handle more significant workloads, or move beyond the trial limitations, you'll need a Production Key. This requires setting up billing information in your Cohere account.
- Cost: Production keys operate on a pay-as-you-go model based primarily on token usage. Tokens are units of text (roughly corresponding to words or parts of words) that the models process. You are charged for both the tokens you send to the model (input tokens) and the tokens the model generates in its response (output tokens).
- Pricing Varies by Model: More powerful models generally cost more per token than lighter, faster models.
- Example Pricing (Illustrative - check Cohere's official pricing page for current rates):
- Command R Model: Might cost around $0.50 per million input tokens and $1.50 per million output tokens. (Note: The previous search result indicated $2.50 input / $10.00 output for Command R - using those values: $2.50 / 1M input tokens, $10.00 / 1M output tokens.)
- Command R+ Model: Being more capable, it would likely have a higher price, perhaps $3.00 per million input tokens and $15.00 per million output tokens.
- Embed Models (e.g.,
embed-english-v3.0): Embedding models are typically priced only on input tokens, as they don't generate lengthy text outputs. Pricing might be around $0.10 per million input tokens. - Token Calculation: Cohere provides a Tokenizer endpoint and documentation to help you understand how text translates into tokens for accurate cost estimation. Longer inputs and outputs naturally cost more.
- Overall Usage Cap: There is no monthly total call limit for production keys. You can make as many calls as needed, provided you stay within the rate limits and manage your costs.
- Rate Limits (Requests Per Minute - RPM): Production keys benefit from significantly higher rate limits, allowing applications to handle much more traffic:
- Chat Endpoint (
/v2/chat): 500 requests per minute (compared to 20/min for Trial). - Embed Endpoint (
/v2/embed) - Text: 2,000 requests per minute (compared to 100/min). - Embed Endpoint (
/v2/embed) - Images: 400 requests per minute (compared to 5/min). - Rerank Endpoint (
/v2/rerank): 1,000 requests per minute (compared to 10/min). - Tokenize Endpoint (
/v2/tokenize): 2,000 requests per minute. - Classify Endpoint (
/v1/classify): 1,000 requests per minute. - Rate Limit Increases: For very high-volume applications, it may be possible to request further rate limit increases by contacting Cohere support.
Production keys are necessary for:
- Developing and deploying applications intended for end-users.
- Handling consistent or high volumes of API requests.
- Any commercial use case.
- Unlocking the full performance potential without being constrained by trial limits.
C. Choosing the Right Key:
- Start with Trial: Always begin with a Trial key for learning and initial development.
- Monitor Usage: Keep an eye on your call volume and frequency.
- Upgrade When Necessary: If your application consistently hits rate limits, exceeds the 1,000 monthly call cap, or if you are preparing to launch publicly or commercially, upgrade to a Production key by adding billing details in the Cohere dashboard.
Okay, here is the revised Step 3 section focusing on testing the streaming chat request provided in the curl command using Apidog, presented in Markdown:
Step 3: Performing a Basic API Test Call for Streaming Chat with Apidog
Before integrating the API into complex code, especially for streaming responses, it's helpful to perform a direct test. Apidog allows you to replicate the curl command structure to verify your key and understand the basic request/response flow for streaming.
- Launch Apidog: Open the Apidog application on your computer.
- Create a New Request: Click the '+' button or equivalent to create a new API request. Name it something descriptive, like "Cohere Streaming Chat Test".
- Configure the Endpoint:
- HTTP Method: Select
POST. - URL: Enter the Cohere v2 Chat endpoint URL:
https://api.cohere.ai/v2/chat
4. Set Up Headers:
- Navigate to the "Headers" tab. You'll need to add several headers based on the
curlcommand: - Accept: Key:
Accept, Value:application/json - Content-Type: Key:
Content-Type, Value:application/json - Authorization: Key:
Authorization, Value:Bearer YOUR_API_KEY(ReplaceYOUR_API_KEYwith your actual Cohere API key. Ensure there's a space afterBearer).
5. Construct the Request Body (with Streaming Enabled):
- Go to the "Body" tab.
- Select the option for "raw" input.
- Choose
JSONas the format. - Paste the following JSON payload, mirroring the
curlcommand's data, including the crucial"stream": trueflag:
{
"stream": true,
"model": "command-r",
"messages": [
{
"role": "user",
"content": "Hello world!"
}
]
}
(Note: The curl example used "role": "user" (lowercase) and model "command-a-03-2025". I've kept "role": "USER" and model "command-r" for consistency with earlier examples, but you should adjust the model and role casing in the JSON above to precisely match the specific request you intend to test if different.)
6. Execute the Request: Click the "Send" button in Apidog.
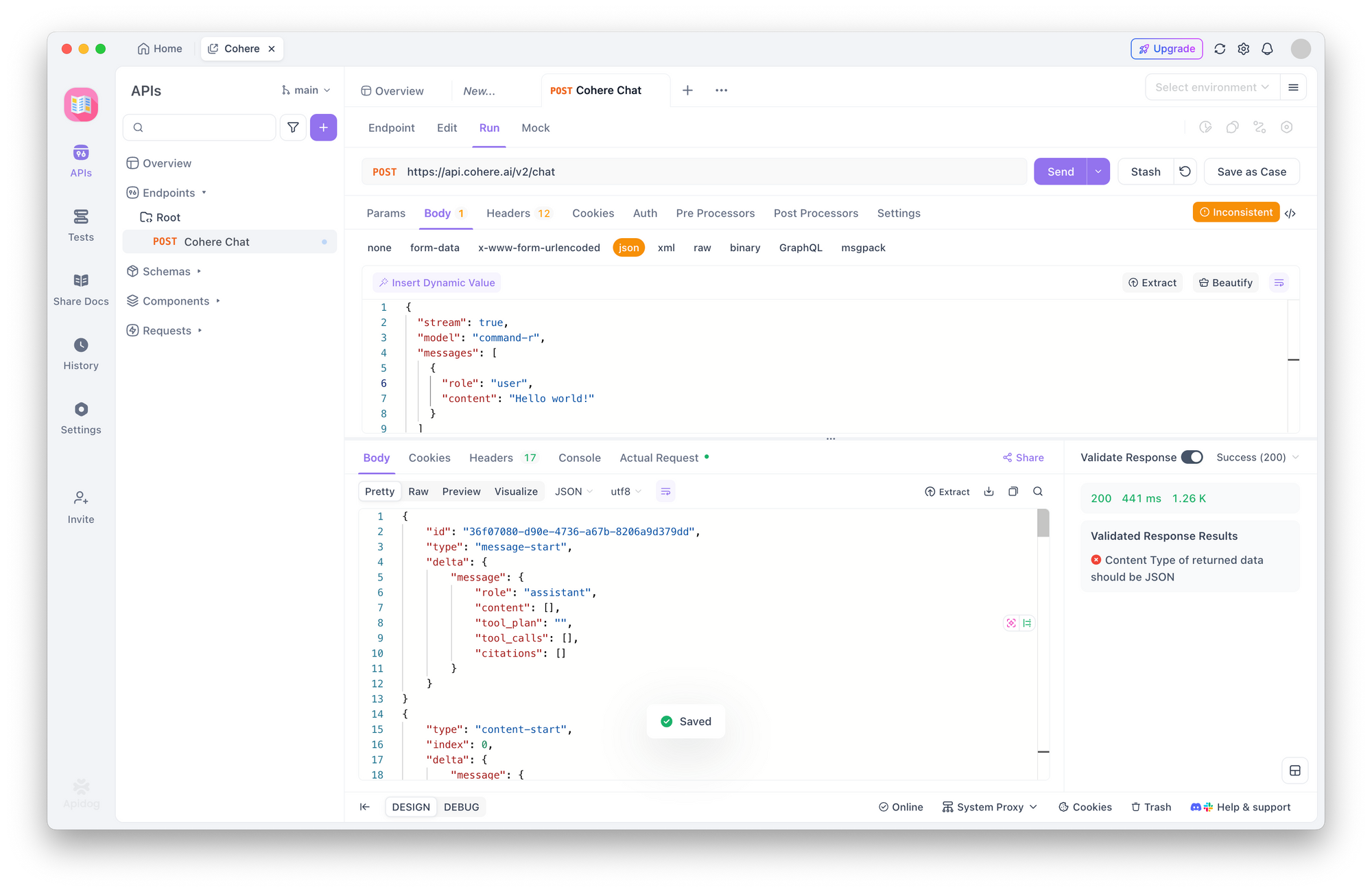
7. Analyze the Response (Streaming Specifics):
- Status Code: You should still receive a
200 OKstatus code if the initial request is accepted by the server. - Response Headers: Check the response headers for signs of streaming, such as
Transfer-Encoding: chunked. - Response Body: How Apidog displays the streaming response might vary. It may:
- Wait until the stream completes and show the fully concatenated text or the final event payload.
- Show the raw chunks or Server-Sent Events (SSE) as they arrive, potentially looking like multiple JSON objects one after another.
- It likely won't render the text smoothly token-by-token like a purpose-built application.
- Content: Look through the response body content. You should see events related to the stream, such as
text-generationevents containing parts of the "Hello world!" response, and eventually astream-endevent indicating the process finished. - Errors: If you get errors (
401,403,400,429), diagnose them as described previously (check API key, JSON validity, rate limits). A400 Bad Requestmight occur if the model specified doesn't support streaming or if other parameters are incompatible.
This test helps confirm that the API accepts your streaming request and that your key is valid for this type of interaction, even if Apidog itself isn't the ideal tool for visualizing the stream's real-time nature. It verifies the fundamental request setup is correct.
Conclusion
You now have your Cohere API key and understand the crucial differences between Trial and Production keys, particularly regarding the 1,000 monthly call limit and per-minute rate limits on Trial keys versus the pay-as-you-go, token-based pricing and higher limits of Production keys. You've also performed a basic but vital test using Apidog to confirm your key works and you can structure a simple API call.
This foundation is essential for interacting effectively with the Cohere API. Remember to keep your key secure, monitor your usage against the limits (especially on a Trial key), and refer to Cohere's documentation for detailed information on specific models, advanced parameters, and SDK usage as you start building more sophisticated applications.


