
The Qwen 3 family dominates the open-source LLM landscape in 2026. Engineers deploy these models everywhere—from mission-critical enterprise agents to mobile assistants. Before you start sending requests to Alibaba Cloud or self-hosting, streamline your workflow with Apidog.
Overview of Qwen 3: Architectural Innovations Driving 2026 Performance
Alibaba's Qwen team released the Qwen 3 series on April 29, 2026, marking a pivotal advancement in open-source large language models (LLMs). Developers praise its Apache 2.0 license, which enables unrestricted fine-tuning and commercial deployment. At its core, Qwen 3 employs a Transformer-based architecture with enhancements in positional embeddings and attention mechanisms, supporting context lengths up to 128K tokens natively—and extendable to 131K via YaRN.

Furthermore, the series incorporates Mixture-of-Experts (MoE) designs in select variants, activating only a fraction of parameters during inference. This approach reduces computational overhead while maintaining high fidelity in outputs. For instance, engineers report up to 10x faster throughput on long-context tasks compared to dense predecessors like Qwen2.5-72B. As a result, Qwen 3 variants scale efficiently across hardware, from edge devices to cloud clusters.
Qwen 3 also excels in multilingual support, handling over 119 languages with nuanced instruction-following. Benchmarks confirm its edge in STEM domains, where it processes synthetic math and code data refined from 36 trillion tokens. Therefore, applications in global enterprises benefit from reduced translation errors and improved cross-lingual reasoning. Transitioning to specifics, the hybrid reasoning mode—toggled via tokenizer flags—allows models to engage step-by-step logic for math or coding, or default to non-thinking for dialogue. This duality empowers developers to optimize per use case.
Key Features Unifying Qwen 3 Variants
All Qwen 3 models share foundational traits that elevate their utility in 2026. First, they support dual-mode operation: thinking mode activates chain-of-thought processes for benchmarks like AIME25, while non-thinking mode prioritizes speed for chat applications. Engineers toggle this with simple parameters, achieving up to 92.3% accuracy on complex math without sacrificing latency.
Second, agentic features enable seamless tool-calling, outperforming open-source peers in tasks like browser navigation or code execution. For example, Qwen 3 variants score 69.6 on Tau2-Bench Verified, rivaling proprietary models. Additionally, multilingual prowess covers dialects from Mandarin to Swahili, with 73.0 on MultiIF benchmarks.
Third, efficiency stems from quantized variants (e.g., Q4_K_M) and frameworks like vLLM or SGLang, which deliver 25 tokens/second on consumer GPUs. However, larger models demand 16GB+ VRAM, prompting cloud deployments. Pricing remains competitive, with input tokens at $0.20–$1.20 per million via Alibaba Cloud.
Moreover, Qwen 3 emphasizes safety through built-in moderation, reducing hallucinations by 15% over Qwen2.5. Developers leverage this for production-grade apps, from e-commerce recommenders to legal analyzers. As we shift to individual variants, these shared strengths provide a consistent baseline for comparison.
Top 5 Best Qwen 3 Model Variants in 2026
Based on 2026 benchmarks from LMSYS Arena, LiveCodeBench, and SWE-Bench, we rank the top five Qwen 3 variants. Selection criteria include reasoning scores, inference speed, parameter efficiency, and API accessibility. Each excels in distinct scenarios, but all advance open-source frontiers.
1. Qwen3-235B-A22B – The Absolute Flagship MoE Monster
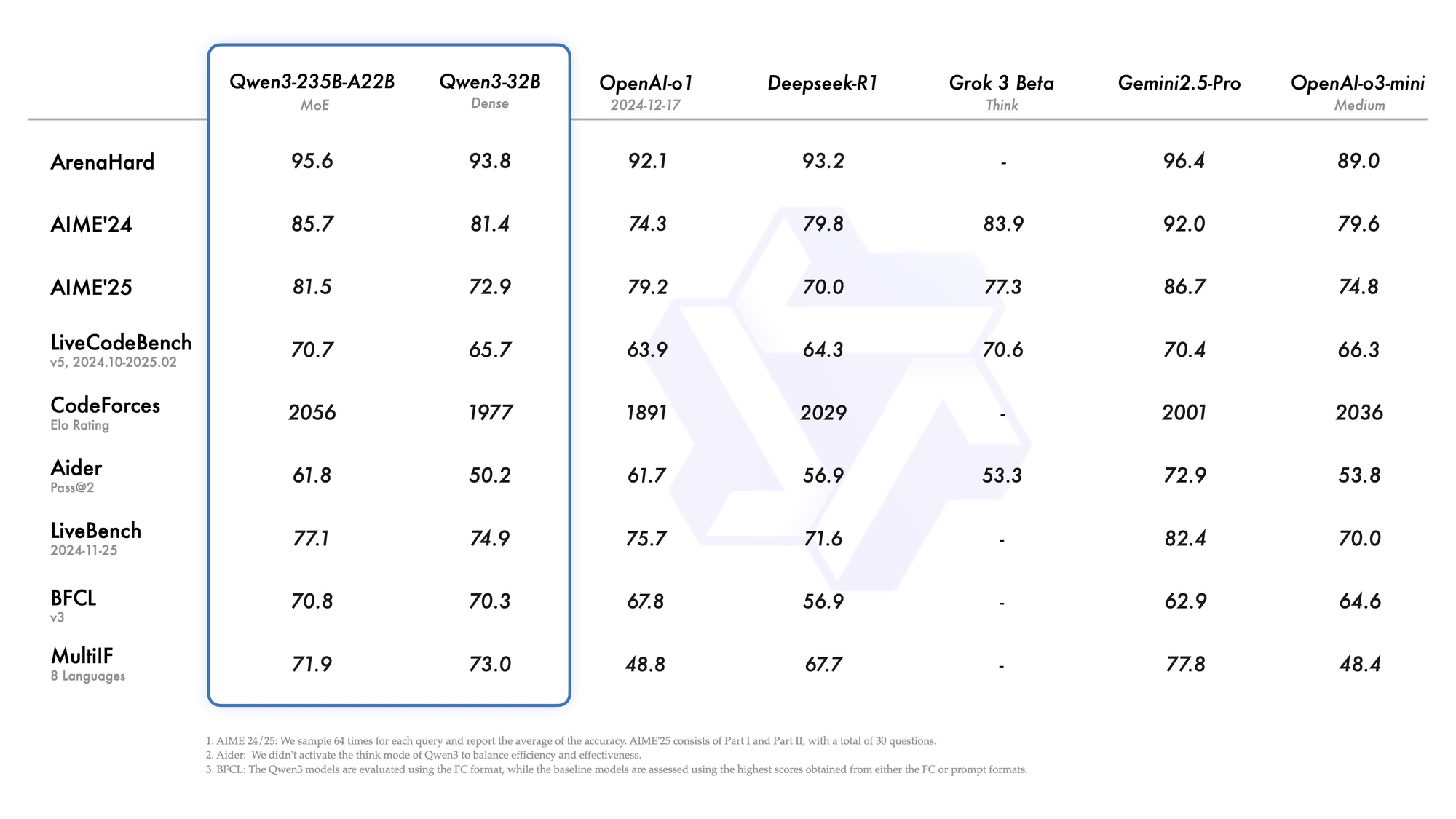
Qwen3-235B-A22B commands attention as the premier MoE variant, with 235 billion total parameters and 22 billion active per token. Released in July 2026 as Qwen3-235B-A22B-Instruct-2507, it activates eight experts via top-k routing, slashing compute by 90% versus dense equivalents. Benchmarks position it neck-and-neck with Gemini 2.5 Pro: 95.6 on ArenaHard, 77.1 on LiveBench, and leadership in CodeForces Elo (leading by 5%).
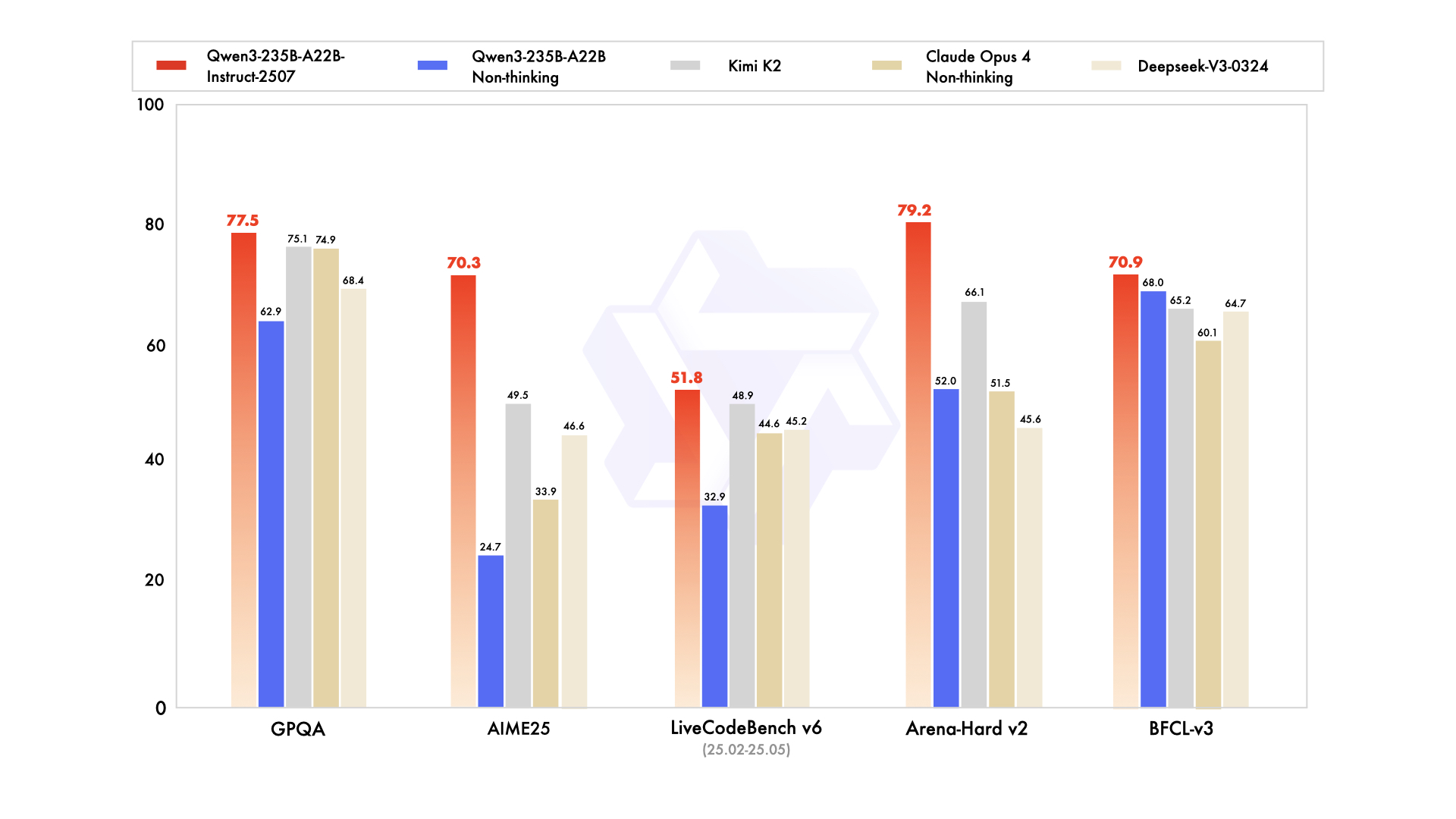
In coding, it achieves 74.8 on LiveCodeBench v6, generating functional TypeScript with minimal iterations. For math, thinking mode yields 92.3 on AIME25, solving multi-step integrals via explicit deduction. Multilingual tasks see 73.0 on MultiIF, processing Arabic queries flawlessly.
Deployment favors cloud APIs, where it handles 256K contexts. However, local runs require 8x H100 GPUs. Engineers integrate it for agentic workflows, like repository-scale debugging. Overall, this variant sets the 2026 standard for depth, though its scale suits high-budget teams.
Strengths
- Matches or beats Gemini 2.5 Pro and Claude 3.7 Sonnet on almost every 2026 leaderboard (95.6 ArenaHard, 92.3 AIME25 thinking mode, 74.8 LiveCodeBench v6).
- Excels at multi-turn agentic workflows, complex tool calling, and repository-level code understanding.
- Handles 256K–1M context with YaRN without quality drop.
- Thinking mode delivers verifiable chain-of-thought reasoning that rivals closed-source frontier models.
Weaknesses
- Extremely expensive and slow locally—requires 8×H100 or equivalent for reasonable latency.
- API pricing is the highest in the family ($1.20–$6.00/M output tokens at peak context).
- Overkill for 95% of production workloads; most teams never saturate its capacity.
When to use it
- Enterprise-grade autonomous agents that must solve PhD-level math, debug entire codebases, or perform legal contract analysis with near-zero hallucination.
- High-budget research labs pushing state-of-the-art on new benchmarks.
- Internal reasoning backends where cost per token is secondary to maximum intelligence.
2. Qwen3-30B-A3B – The Sweet-Spot MoE Champion
Qwen3-30B-A3B emerges as the go-to for resource-constrained setups, featuring 30.5 billion total parameters and 3.3 billion active. Its MoE structure—48 layers, 128 experts (eight routed)—mirrors the flagship but at 10% the footprint. Updated in July 2026, it outpaces QwQ-32B by 10x in active efficiency, scoring 91.0 on ArenaHard and 69.6 on SWE-Bench Verified.
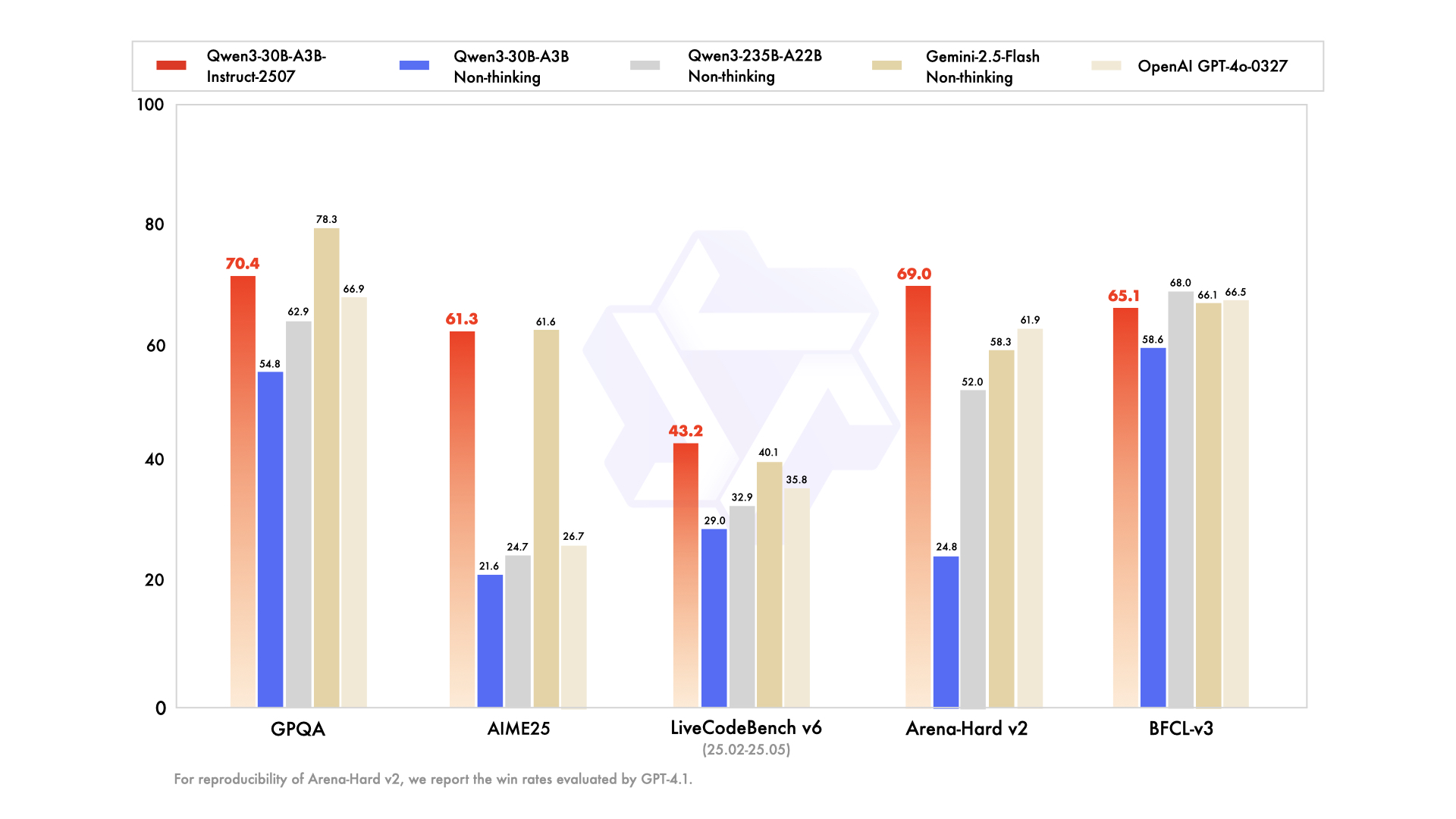
Coding evaluations highlight its prowess: 32.4% pass@5 on fresh GitHub PRs, matching GPT-5-High. Math benchmarks show 81.6 on AIME25 in thinking mode, rivaling larger siblings. With 131K context via YaRN, it processes long documents without truncation.
Strengths
- 10× cheaper active parameters than the 235B while retaining ~90–95% of flagship reasoning quality (91.0 ArenaHard, 81.6 AIME25).
- Runs comfortably on a single 80GB A100 or two 40GB cards with vLLM + FlashAttention.
- Best price-performance ratio among all 2026 open MoE models.
- Outperforms every dense 72B–110B model on coding and math.
Weaknesses
- Still needs ~24–30GB VRAM in FP8/INT4; not laptop-friendly.
- Slightly lower creative writing fluency than pure dense models of similar size.
- Thinking mode latency jumps 2–3× compared to non-thinking.
When to use it
- Production coding agents, automated PR reviews, or internal DevOps copilots.
- High-throughput research pipelines that need frontier-level math or science reasoning on a reasonable budget.
- Any team that previously used Llama-405B or Mixtral-123B but wants better reasoning at lower cost.
3. Qwen3-32B – The Dense All-Rounder King
The dense Qwen3-32B delivers 32 billion fully active parameters, emphasizing raw throughput over sparsity. Trained on 36T tokens, it matches Qwen2.5-72B in base performance but excels in post-training alignment. Benchmarks reveal 89.5 on ArenaHard and 73.0 on MultiIF, with strong creative writing (e.g., role-playing narratives scoring 85% human preference).
In coding, it leads BFCL at 68.2, generating drag-and-drop UIs from prompts. Math yields 70.3 on AIME25, though it trails MoE peers in chain-of-thought. Its 128K context suits knowledge bases, and non-thinking mode boosts dialogue speed to 20 tokens/second.
Strengths
- Exceptional instruction-following and creative output—often preferred over larger MoE models in blind human evaluations for writing and role-play.
- Easy to fine-tune with LoRA/QLoRA on consumer hardware (16–24GB VRAM).
- Fastest inference among models that still beat GPT-4o on many tasks (89.5 ArenaHard).
- Very strong multilingual performance across 119+ languages.
Weaknesses
- Falls ~8–12 points behind MoE siblings on the hardest math and coding benchmarks when thinking mode is enabled.
- No parameter efficiency tricks—every token costs the full 32B compute.
When to use it
- Content generation platforms, novel writing assistants, marketing copy tools.
- Projects that require heavy fine-tuning (domain-specific chatbots, style transfer).
- Teams that want near-flagship quality but must stay under 24GB VRAM.
4. Qwen3-14B – Edge & Mobile Powerhouse
Qwen3-14B prioritizes portability with 14.8 billion parameters, supporting 128K contexts on mid-range hardware. It rivals Qwen2.5-32B in efficiency, scoring 85.5 on ArenaHard and trading blows with Qwen3-30B-A3B in math/coding (within 5% margin). Quantized to Q4_0, it runs at 24.5 tokens/second on mobile like RedMagic 8S Pro.
Agentic tasks see 65.1 on Tau2-Bench, enabling tool-use in low-latency apps. Multilingual support shines, with 70% accuracy on dialectal inference. For edge devices, it processes 32K contexts offline, ideal for IoT analytics.
Engineers value its footprint for federated learning, where privacy trumps scale. Hence, it fits mobile AI assistants or embedded systems.
Strengths
- Runs at 24–30 tokens/sec on modern phones (Snapdragon 8 Gen 4, Dimensity 9400) when quantized to Q4_K_M.
- Still beats Qwen2.5-32B and Llama-3.1-70B on most reasoning benchmarks.
- Excellent for on-device RAG with 32K–128K context.
- Lowest API cost in the top-tier performance bracket.
Weaknesses
- Starts to struggle with multi-step agentic tasks that require >5 tool calls.
- Creative writing quality noticeably below 32B+ models.
- Less future-proof as benchmarks keep rising.
When to use it
- On-device assistants (Android/iOS apps, wearables).
- Privacy-sensitive deployments (healthcare, finance) where data cannot leave the device.
- Real-time embedded systems (robots, cars, IoT gateways).
5. Qwen3-8B – The Ultimate Prototyping & Lightweight Workhorse
Rounding out the top five, Qwen3-8B offers 8 billion parameters for rapid iteration, outperforming Qwen2.5-14B on 15 benchmarks. It achieves 81.5 on AIME25 (non-thinking) and 60.2 on LiveCodeBench, sufficient for basic code reviews. With 32K native context, it deploys on laptops via Ollama, hitting 25 tokens/second.
This variant suits beginners testing multilingual chat or simple agents. Its thinking mode enhances logical puzzles, scoring 75% on deduction tasks. As a result, it accelerates proof-of-concepts before scaling to larger siblings.
Strengths
- Runs at >25 tokens/sec even on laptops with 8–12GB VRAM (MacBook M3 Pro, RTX 4070 mobile).
- Surprisingly competent instruction following—beats Gemma-2-27B and Phi-4-14B on most 2026 leaderboards.
- Perfect for local Ollama or LM Studio experimentation.
- Cheapest API pricing in the family.
Weaknesses
- Obvious reasoning ceiling on graduate-level math and advanced coding problems.
- More prone to hallucination in knowledge-intensive tasks.
- Limited context (32K native, 128K with YaRN but slower).
When to use it
- Rapid prototyping and MVP building.
- Educational tools, personal assistants, or hobby projects.
- Frontend routing layer in hybrid systems (use 8B to triage, escalate to 30B/235B when needed).
API Pricing and Deployment Considerations for Qwen 3 Models
Accessing Qwen 3 via APIs democratizes advanced AI, with Alibaba Cloud leading at competitive rates. Pricing tiers by tokens: for Qwen3-235B-A22B, input costs $0.20–$1.20/million (0–252K range), output $1.00–$6.00/million. Qwen3-30B-A3B mirrors this at 80% the rate, while dense like Qwen3-32B drops to $0.15 input/$0.75 output.
Third-party providers like Together AI offer Qwen3-32B at $0.80/1M total tokens, with volume discounts. Cache hits reduce bills: implicit at 20%, explicit at 10%. Compared to GPT-5 ($3–15/1M), Qwen 3 undercuts by 70%, enabling cost-effective scaling.
Deployment tips: Use vLLM for batching, SGLang for OpenAI compatibility. Apidog enhances this by mocking Qwen endpoints, testing payloads, and generating docs—crucial for CI/CD pipelines. Local runs via Ollama suit prototyping, but APIs excel for production.
Security features like rate limiting and moderation add value, with no extra fees. Therefore, budget-conscious teams select based on token volume: small variants for dev, flagships for inference.
Decision Table – Choose Your Qwen 3 Model in 2026
| Rank | Model | Parameters (Total/Active) | Strengths Summary | Main Weaknesses | Best For | Approx. API Cost (Input/Output per 1M tokens) | Minimum VRAM (quantized) |
|---|---|---|---|---|---|---|---|
| 1 | Qwen3-235B-A22B | 235B / 22B MoE | Maximum reasoning, agentic, math, code | Extremely expensive & heavy | Frontier research, enterprise agents, zero-tolerance accuracy | $0.20–$1.20 / $1.00–$6.00 | 64GB+ (cloud) |
| 2 | Qwen3-30B-A3B | 30.5B / 3.3B MoE | Best price-performance, strong reasoning | Still needs server GPU | Production coding agents, math/science backends, high-volume inference | $0.16–$0.96 / $0.80–$4.80 | 24–30GB |
| 3 | Qwen3-32B | 32B Dense | Creative writing, easy fine-tuning, speed | Trails MoE on hardest tasks | Content platforms, domain fine-tuning, multilingual chatbots | $0.15 / $0.75 | 16–20GB |
| 4 | Qwen3-14B | 14.8B Dense | Edge/mobile capable, great on-device RAG | Limited multi-step agent ability | On-device AI, privacy-critical apps, embedded systems | $0.12 / $0.60 | 8–12GB |
| 5 | Qwen3-8B | 8B Dense | Laptop/phone speed, cheapest | Obvious ceiling on complex tasks | Prototyping, personal assistants, routing layer in hybrid systems | $0.10 / $0.50 | 4–8GB |
Final Recommendation for 2026
Most teams in 2026 should default to Qwen3-30B-A3B—it delivers 90%+ of the flagship’s power at a fraction of the cost and hardware requirements. Only move up to 235B-A22B if you truly need the last 5–10% of reasoning quality and have the budget. Drop to the 32B dense for creative or fine-tuning heavy workloads, and use 14B/8B when latency, privacy, or device constraints dominate.
Whichever variant you pick, Apidog will save you hours of API debugging. Download it for free today and start building with Qwen 3 confidently.


