
يقوم ElevenLabs بتحويل النص إلى كلام طبيعي ويدعم مجموعة واسعة من الأصوات واللغات والأنماط. تجعل واجهة برمجة التطبيقات (API) من السهل تضمين الصوت في التطبيقات، أو أتمتة مسارات السرد، أو بناء تجارب في الوقت الفعلي مثل وكلاء الصوت. إذا كان بإمكانك إرسال طلب HTTP، يمكنك إنشاء صوت في ثوانٍ.
ما هي واجهة برمجة تطبيقات ElevenLabs؟
توفر واجهة برمجة تطبيقات ElevenLabs وصولاً برمجيًا إلى نماذج الذكاء الاصطناعي التي تولد الصوت وتحوّله وتحلّله. بدأت المنصة كخدمة تحويل النص إلى كلام ولكنها توسعت لتصبح مجموعة كاملة من حلول الذكاء الاصطناعي الصوتي.
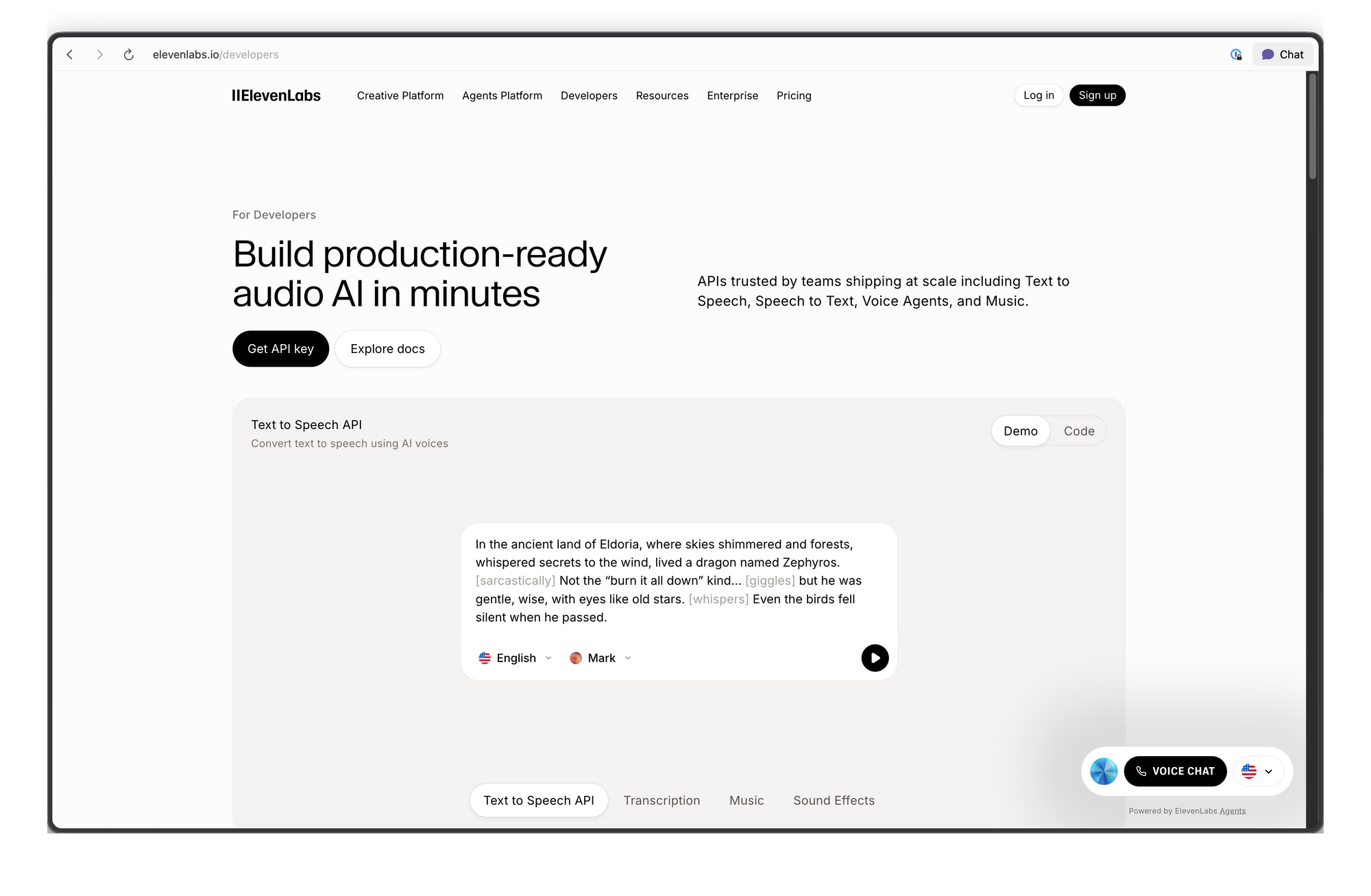
الإمكانيات الأساسية:
- تحويل النص إلى كلام (TTS): تحويل النص المكتوب إلى صوت منطوق مع التحكم في خصائص الصوت والعواطف والإيقاع
- تحويل الكلام إلى كلام (STS): تحويل صوت إلى آخر مع الحفاظ على التنغيم والتوقيت الأصليين
- استنساخ الصوت: إنشاء نسخة رقمية لأي صوت من 60 ثانية فقط من الصوت النظيف
- الدبلجة بالذكاء الاصطناعي: ترجمة ودبلجة محتوى الصوت/الفيديو إلى لغات مختلفة مع الحفاظ على خصائص صوت المتحدث
- المؤثرات الصوتية: توليد مؤثرات صوتية من وصف نصي
- تحويل الكلام إلى نص: نسخ الصوت إلى نص بدقة عالية
تعمل واجهة برمجة التطبيقات عبر بروتوكولات HTTP و WebSocket القياسية. يمكنك استدعائها من أي لغة، ولكن توجد حزم SDK رسمية لـ Python و JavaScript/TypeScript مع دعم مدمج لسلامة الأنواع والتدفق.
الحصول على مفتاح API لـ ElevenLabs
قبل إجراء أي استدعاء لواجهة برمجة التطبيقات، تحتاج إلى مفتاح API. إليك كيفية الحصول عليه:
الخطوة 1: أنشئ حسابًا مجانيًا. حتى الخطة المجانية تتضمن الوصول إلى واجهة برمجة التطبيقات بـ 10,000 حرف شهريًا.
الخطوة 2: قم بتسجيل الدخول وانتقل إلى قسم الملف الشخصي + مفتاح API. يمكنك العثور على هذا بالضغط على أيقونة ملفك الشخصي في الزاوية السفلية اليسرى، أو بالانتقال مباشرة إلى إعدادات المطور.
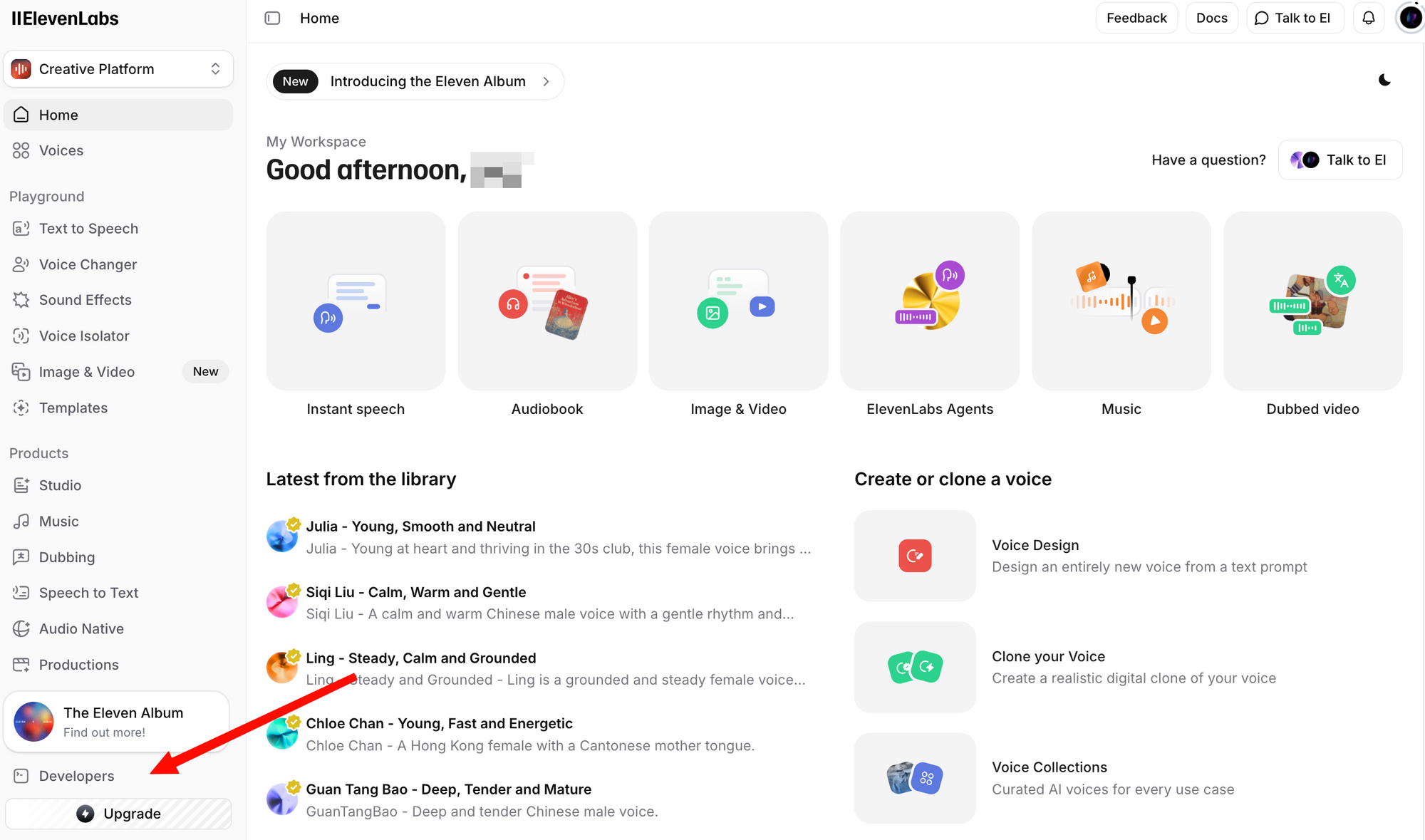
الخطوة 3: انقر على إنشاء مفتاح API. انسخ المفتاح وقم بتخزينه بأمان—لن تتمكن من رؤية المفتاح كاملاً مرة أخرى.
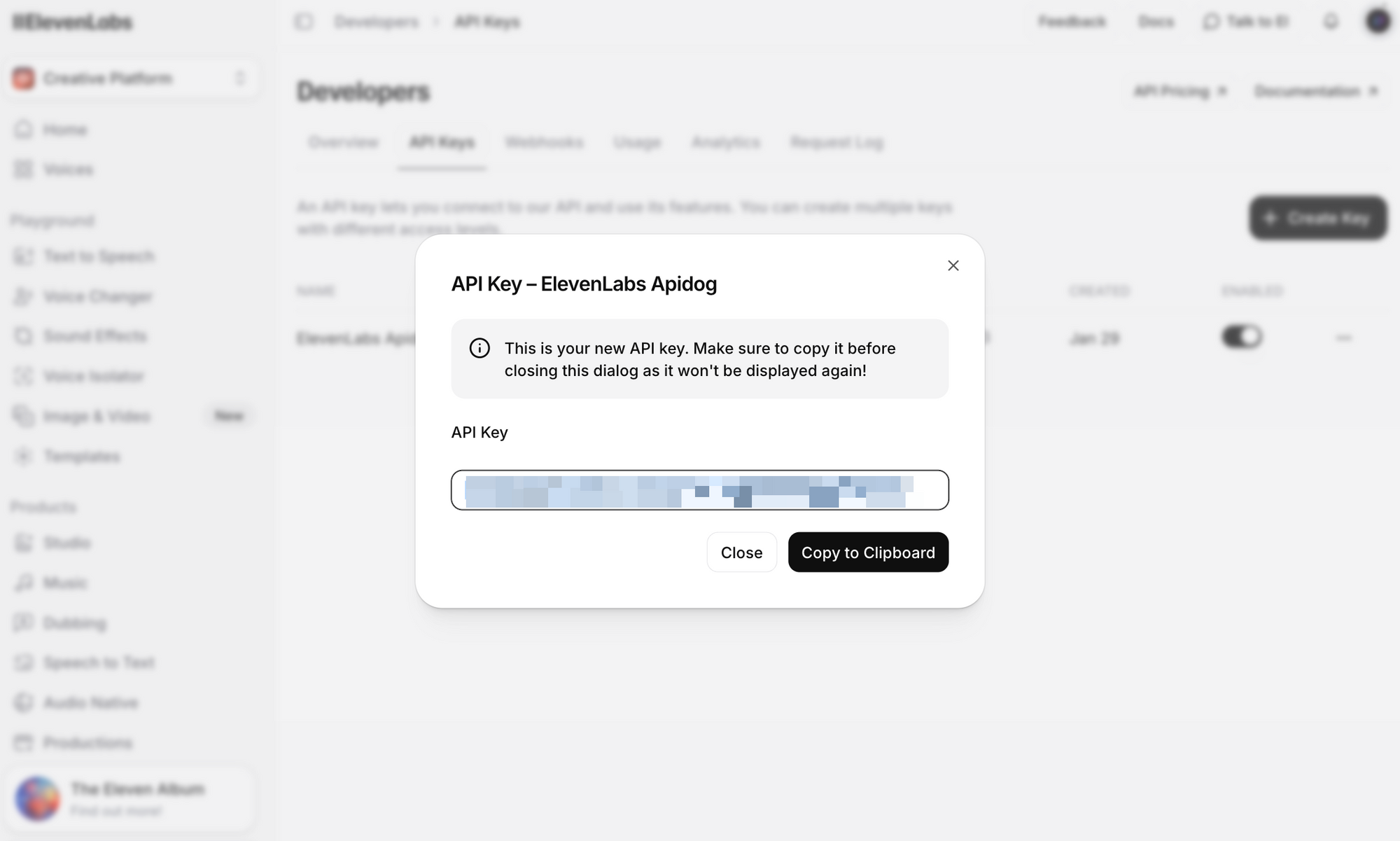
ملاحظات أمنية هامة:
- لا تقم أبدًا بتضمين مفتاح API الخاص بك في نظام التحكم في الإصدار
- استخدم متغيرات البيئة أو مدير الأسرار في بيئة الإنتاج
- يمكن تحديد نطاق مفاتيح API لمساحات عمل محددة لبيئات الفريق
- قم بتدوير المفاتيح بانتظام وإلغاء المفاتيح المخترقة على الفور
عيّنه كمتغير بيئة للأمثلة في هذا الدليل:
# Linux/macOS
export ELEVENLABS_API_KEY="your_api_key_here"
# Windows (PowerShell)
$env:ELEVENLABS_API_KEY="your_api_key_here"
نظرة عامة على نقاط نهاية واجهة برمجة تطبيقات ElevenLabs
تنظم واجهة برمجة التطبيقات حول عدة مجموعات موارد. فيما يلي نقاط النهاية الأكثر استخدامًا:
| نقطة النهاية | الطريقة | الوصف |
|---|---|---|
/v1/text-to-speech/{voice_id} | POST | تحويل النص إلى صوت كلام |
/v1/text-to-speech/{voice_id}/stream | POST | بث الصوت فور إنشائه |
/v1/speech-to-speech/{voice_id} | POST | تحويل الكلام من صوت إلى آخر |
/v1/voices | GET | سرد جميع الأصوات المتاحة |
/v1/voices/{voice_id} | GET | الحصول على تفاصيل صوت محدد |
/v1/models | GET | سرد جميع النماذج المتاحة |
/v1/user | GET | الحصول على معلومات حساب المستخدم واستخدامه |
/v1/voice-generation/generate-voice | POST | توليد صوت عشوائي جديد |
عنوان URL الأساسي: https://api.elevenlabs.io
المصادقة: تتطلب جميع الطلبات رأس xi-api-key:
xi-api-key: your_api_key_here
تحويل النص إلى كلام باستخدام cURL
أسرع طريقة لاختبار واجهة برمجة التطبيقات هي باستخدام أمر cURL. يستخدم هذا المثال صوت Rachel (المعرف: 21m00Tcm4TlvDq8ikWAM)، وهو أحد الأصوات الافتراضية المتاحة في جميع الخطط:
curl -X POST "https://api.elevenlabs.io/v1/text-to-speech/21m00Tcm4TlvDq8ikWAM" \
-H "xi-api-key: $ELEVENLABS_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"text": "Welcome to our application. This audio was generated using the ElevenLabs API.",
"model_id": "eleven_flash_v2_5",
"voice_settings": {
"stability": 0.5,
"similarity_boost": 0.75,
"style": 0.0,
"use_speaker_boost": true
}
}' \
--output speech.mp3
إذا نجحت العملية، ستحصل على ملف speech.mp3 يحتوي على الصوت المُنشأ. قم بتشغيله باستخدام أي مشغل وسائط.
تحليل الطلب:
- voice_id (في عنوان URL): معرف الصوت المراد استخدامه. كل صوت في ElevenLabs له معرف فريد.
- text: المحتوى المراد تحويله إلى كلام. يدعم نموذج Flash v2.5 ما يصل إلى 40,000 حرف لكل طلب.
- model_id: نموذج الذكاء الاصطناعي المراد استخدامه. يوفر
eleven_flash_v2_5أفضل توازن بين السرعة والجودة. - voice_settings: معلمات الضبط الدقيق الاختيارية (مغطاة بالتفصيل أدناه).
تعيد الاستجابة بيانات صوتية خام. التنسيق الافتراضي هو MP3، ولكن يمكنك طلب تنسيقات أخرى عن طريق إضافة معلمة الاستعلام output_format:
# Get PCM audio instead of MP3
curl -X POST "https://api.elevenlabs.io/v1/text-to-speech/21m00Tcm4TlvDq8ikWAM?output_format=pcm_44100" \
-H "xi-api-key: $ELEVENLABS_API_KEY" \
-H "Content-Type: application/json" \
-d '{"text": "Hello world", "model_id": "eleven_flash_v2_5"}' \
--output speech.pcm
استخدام حزمة SDK لـ Python
تبسط حزمة SDK الرسمية لـ Python عملية التكامل بفضل تلميحات النوع (type hints) وتشغيل الصوت المدمج ودعم البث.
التثبيت
pip install elevenlabs
لتشغيل الصوت مباشرة عبر مكبرات الصوت لديك، قد تحتاج أيضًا إلى mpv أو ffmpeg:
# macOS
brew install mpv
# Ubuntu/Debian
sudo apt install mpv
تحويل النص إلى كلام أساسي
import os
from elevenlabs.client import ElevenLabs
from elevenlabs import play
client = ElevenLabs(
api_key=os.getenv("ELEVENLABS_API_KEY")
)
audio = client.text_to_speech.convert(
text="The ElevenLabs API makes it easy to add realistic voice output to any application.",
voice_id="JBFqnCBsd6RMkjVDRZzb", # George voice
model_id="eleven_multilingual_v2",
output_format="mp3_44100_128",
)
play(audio)
حفظ الصوت في ملف
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="your_api_key")
audio = client.text_to_speech.convert(
text="This audio will be saved to a file.",
voice_id="21m00Tcm4TlvDq8ikWAM",
model_id="eleven_flash_v2_5",
)
with open("output.mp3", "wb") as f:
for chunk in audio:
f.write(chunk)
print("Audio saved to output.mp3")
سرد الأصوات المتاحة
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="your_api_key")
response = client.voices.search()
for voice in response.voices:
print(f"Name: {voice.name}, ID: {voice.voice_id}, Category: {voice.category}")
يطبع هذا جميع الأصوات المتاحة في حسابك، بما في ذلك الأصوات المعدة مسبقًا والأصوات المستنسخة وأصوات المجتمع التي أضفتها.
دعم Async
للتطبيقات التي تستخدم asyncio، توفر حزمة SDK الفئة AsyncElevenLabs:
import asyncio
from elevenlabs.client import AsyncElevenLabs
client = AsyncElevenLabs(api_key="your_api_key")
async def generate_speech():
audio = await client.text_to_speech.convert(
text="This was generated asynchronously.",
voice_id="21m00Tcm4TlvDq8ikWAM",
model_id="eleven_flash_v2_5",
)
with open("async_output.mp3", "wb") as f:
async for chunk in audio:
f.write(chunk)
print("Async audio saved.")
asyncio.run(generate_speech())
استخدام حزمة SDK لـ JavaScript
توفر حزمة SDK الرسمية لـ Node.js (@elevenlabs/elevenlabs-js) دعمًا كاملاً لـ TypeScript وتعمل في بيئات Node.js.
التثبيت
npm install @elevenlabs/elevenlabs-js
تحويل النص إلى كلام أساسي
import { ElevenLabsClient, play } from "@elevenlabs/elevenlabs-js";
const elevenlabs = new ElevenLabsClient({
apiKey: process.env.ELEVENLABS_API_KEY,
});
const audio = await elevenlabs.textToSpeech.convert(
"21m00Tcm4TlvDq8ikWAM", // Rachel voice ID
{
text: "Hello from the ElevenLabs JavaScript SDK!",
modelId: "eleven_multilingual_v2",
}
);
await play(audio);
الحفظ في ملف (Node.js)
import { ElevenLabsClient } from "@elevenlabs/elevenlabs-js";
import { createWriteStream } from "fs";
import { Readable } from "stream";
import { pipeline } from "stream/promises";
const elevenlabs = new ElevenLabsClient({
apiKey: process.env.ELEVENLABS_API_KEY,
});
const audio = await elevenlabs.textToSpeech.convert(
"21m00Tcm4TlvDq8ikWAM",
{
text: "This audio will be written to a file using Node.js streams.",
modelId: "eleven_flash_v2_5",
}
);
const readable = Readable.from(audio);
const writeStream = createWriteStream("output.mp3");
await pipeline(readable, writeStream);
console.log("Audio saved to output.mp3");
معالجة الأخطاء
import { ElevenLabsClient, ElevenLabsError } from "@elevenlabs/elevenlabs-js";
const elevenlabs = new ElevenLabsClient({
apiKey: process.env.ELEVENLABS_API_KEY,
});
try {
const audio = await elevenlabs.textToSpeech.convert(
"21m00Tcm4TlvDq8ikWAM",
{
text: "Testing error handling.",
modelId: "eleven_flash_v2_5",
}
);
await play(audio);
} catch (error) {
if (error instanceof ElevenLabsError) {
console.error(`API Error: ${error.message}, Status: ${error.statusCode}`);
} else {
console.error("Unexpected error:", error);
}
}
تعيد حزمة SDK محاولة الطلبات الفاشلة مرتين كحد أقصى افتراضيًا، مع مهلة 60 ثانية. كلا القيمتين قابلتان للتكوين.
بث الصوت في الوقت الفعلي
بالنسبة لروبوتات الدردشة، والمساعدين الصوتيين، أو أي تطبيق يكون فيه زمن الوصول مهمًا، يتيح لك البث البدء في تشغيل الصوت قبل اكتمال إنشاء الاستجابة بأكملها. هذا أمر بالغ الأهمية للذكاء الاصطناعي التخاطبي حيث يتوقع المستخدمون استجابات شبه فورية.
بث بايثون
from elevenlabs import stream
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="your_api_key")
audio_stream = client.text_to_speech.stream(
text="Streaming allows you to start hearing audio almost instantly, without waiting for the entire generation to complete.",
voice_id="JBFqnCBsd6RMkjVDRZzb",
model_id="eleven_flash_v2_5",
)
# Play streamed audio through speakers in real time
stream(audio_stream)
بث جافا سكريبت
import { ElevenLabsClient, stream } from "@elevenlabs/elevenlabs-js";
const elevenlabs = new ElevenLabsClient();
const audioStream = await elevenlabs.textToSpeech.stream(
"JBFqnCBsd6RMkjVDRZzb",
{
text: "This audio streams in real time with minimal latency.",
modelId: "eleven_flash_v2_5",
}
);
stream(audioStream);
بث WebSocket
للحصول على أقل زمن وصول، استخدم اتصالات WebSocket. هذا مثالي لوكلاء الصوت في الوقت الفعلي حيث يصل النص على شكل أجزاء (مثل من LLM):
import asyncio
import websockets
import json
import base64
async def stream_tts_websocket():
voice_id = "21m00Tcm4TlvDq8ikWAM"
model_id = "eleven_flash_v2_5"
uri = f"wss://api.elevenlabs.io/v1/text-to-speech/{voice_id}/stream-input?model_id={model_id}"
async with websockets.connect(uri) as ws:
# Send initial config
await ws.send(json.dumps({
"text": " ",
"voice_settings": {"stability": 0.5, "similarity_boost": 0.75},
"xi_api_key": "your_api_key",
}))
# Send text chunks as they arrive (e.g., from an LLM)
text_chunks = [
"Hello! ",
"This is streaming ",
"via WebSockets. ",
"Each chunk is sent separately."
]
for chunk in text_chunks:
await ws.send(json.dumps({"text": chunk}))
# Signal end of input
await ws.send(json.dumps({"text": ""}))
# Receive audio chunks
audio_data = b""
async for message in ws:
data = json.loads(message)
if data.get("audio"):
audio_data += base64.b64decode(data["audio"])
if data.get("isFinal"):
break
with open("websocket_output.mp3", "wb") as f:
f.write(audio_data)
print("WebSocket audio saved.")
asyncio.run(stream_tts_websocket())
اختيار وإدارة الأصوات
تقدم ElevenLabs مئات الأصوات. اختيار الصوت المناسب أمر مهم لتجربة مستخدم تطبيقك.
الأصوات الافتراضية
هذه الأصوات متاحة في جميع الخطط، بما في ذلك الطبقة المجانية:
| اسم الصوت | معرف الصوت | الوصف |
|---|---|---|
| Rachel | 21m00Tcm4TlvDq8ikWAM | هادئة، أنثى شابة |
| Drew | 29vD33N1CtxCmqQRPOHJ | ذكر متوازن |
| Clyde | 2EiwWnXFnvU5JabPnv8n | شخصية محارب قديم |
| Paul | 5Q0t7uMcjvnagumLfvZi | مراسل ميداني |
| Domi | AZnzlk1XvdvUeBnXmlld | أنثى قوية وحازمة |
| Dave | CYw3kZ02Hs0563khs1Fj | ذكر بريطاني محاور |
| Fin | D38z5RcWu1voky8WS1ja | ذكر أيرلندي |
| Sarah | EXAVITQu4vr4xnSDxMaL | ناعمة، أنثى شابة |
العثور على معرفات الأصوات
استخدم واجهة برمجة التطبيقات للبحث عن جميع الأصوات المتاحة:
curl -X GET "https://api.elevenlabs.io/v1/voices" \
-H "xi-api-key: $ELEVENLABS_API_KEY" | python3 -m json.tool
أو قم بالتصفية حسب الفئة (معدة مسبقًا، مستنسخة، مولدة):
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="your_api_key")
# List only premade voices
response = client.voices.search(category="premade")
for voice in response.voices:
print(f"{voice.name}: {voice.voice_id}")
يمكنك أيضًا نسخ معرف الصوت مباشرة من موقع ElevenLabs: حدد صوتًا، وانقر على قائمة النقاط الثلاث، ثم اختر نسخ معرف الصوت.
اختيار النموذج المناسب
تقدم ElevenLabs نماذج متعددة، تم تحسين كل منها لحالات استخدام مختلفة:

# List all available models with details
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="your_api_key")
models = client.models.list()
for model in models:
print(f"Model: {model.name}")
print(f" ID: {model.model_id}")
print(f" Languages: {len(model.languages)}")
print(f" Max chars: {model.max_characters_request_free_user}")
print()
اختبار واجهة برمجة تطبيقات ElevenLabs باستخدام Apidog
قبل كتابة تعليمات التكامل البرمجية، يساعد اختبار نقاط نهاية واجهة برمجة التطبيقات بشكل تفاعلي. يجعل Apidog هذا الأمر سهلاً—يمكنك تكوين الطلبات بصريًا، وفحص الاستجابات (بما في ذلك الصوت)، وإنشاء رمز العميل بمجرد أن تكون راضيًا.
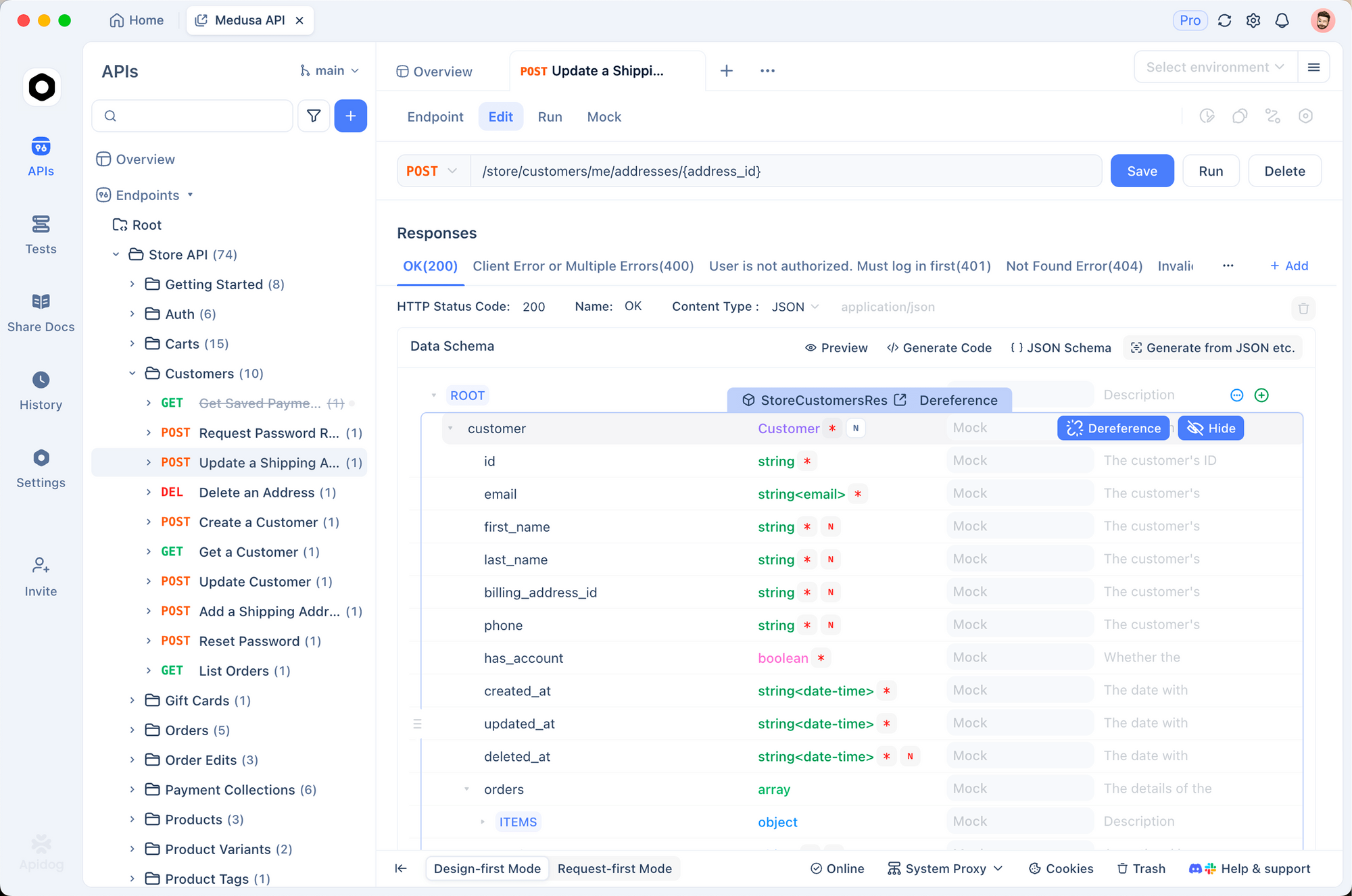
الخطوة 1: إعداد مشروع جديد
افتح Apidog وأنشئ مشروعًا جديدًا. سمّه "ElevenLabs API" أو أضف نقاط النهاية إلى مشروع موجود.
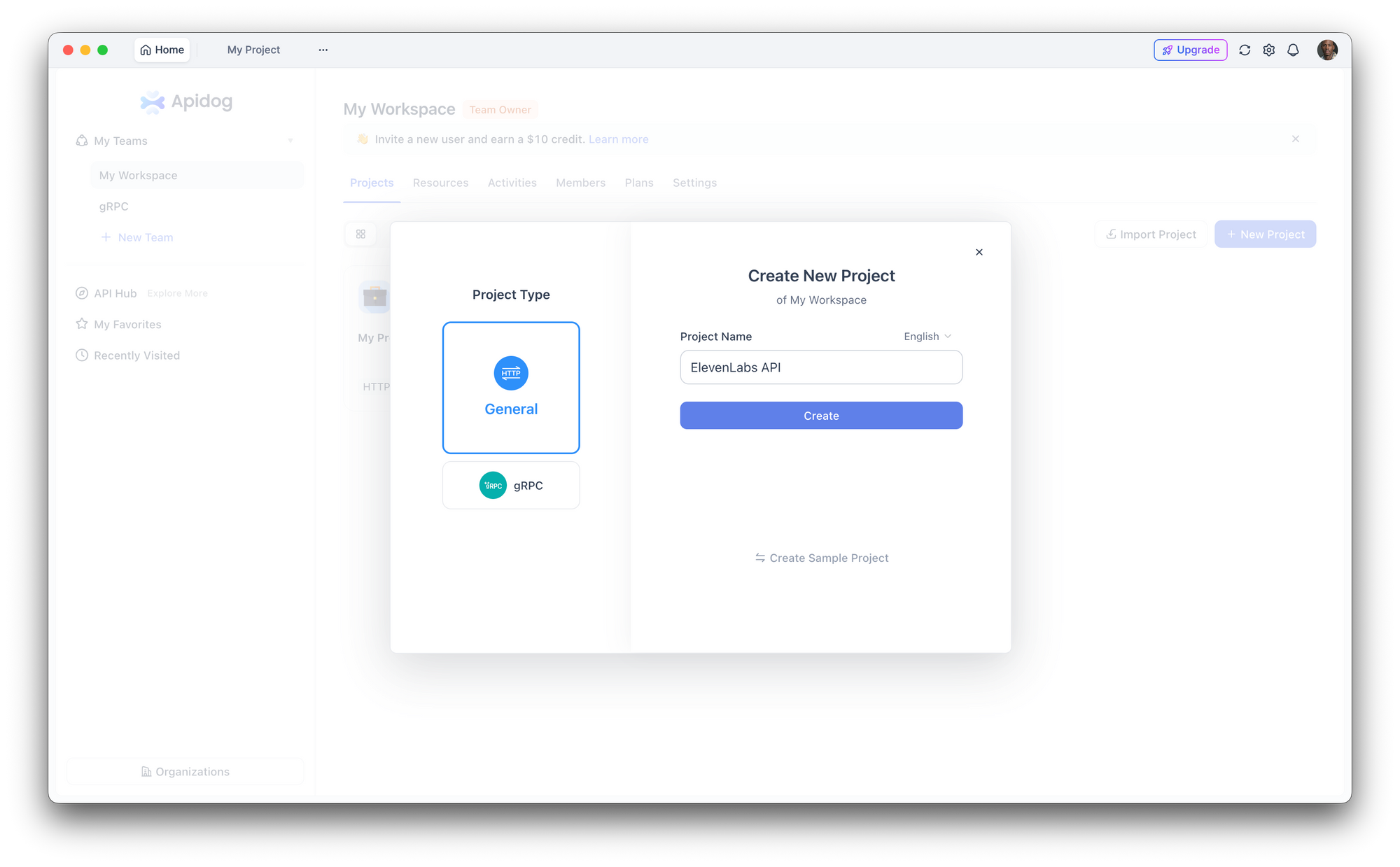
الخطوة 2: تكوين المصادقة
انتقل إلى إعدادات المشروع > المصادقة وقم بإعداد رأس عام:
- اسم الرأس:
xi-api-key - قيمة الرأس: مفتاح API الخاص بك في ElevenLabs
يقوم هذا تلقائيًا بإرفاق المصادقة بكل طلب في المشروع.
الخطوة 3: إنشاء طلب تحويل النص إلى كلام
إنشاء طلب POST جديد:
- عنوان URL:
https://api.elevenlabs.io/v1/text-to-speech/21m00Tcm4TlvDq8ikWAM - الجسم (JSON):
{
"text": "Testing the ElevenLabs API through Apidog. This makes it easy to experiment with different voices and settings.",
"model_id": "eleven_flash_v2_5",
"voice_settings": {
"stability": 0.5,
"similarity_boost": 0.75
}
}
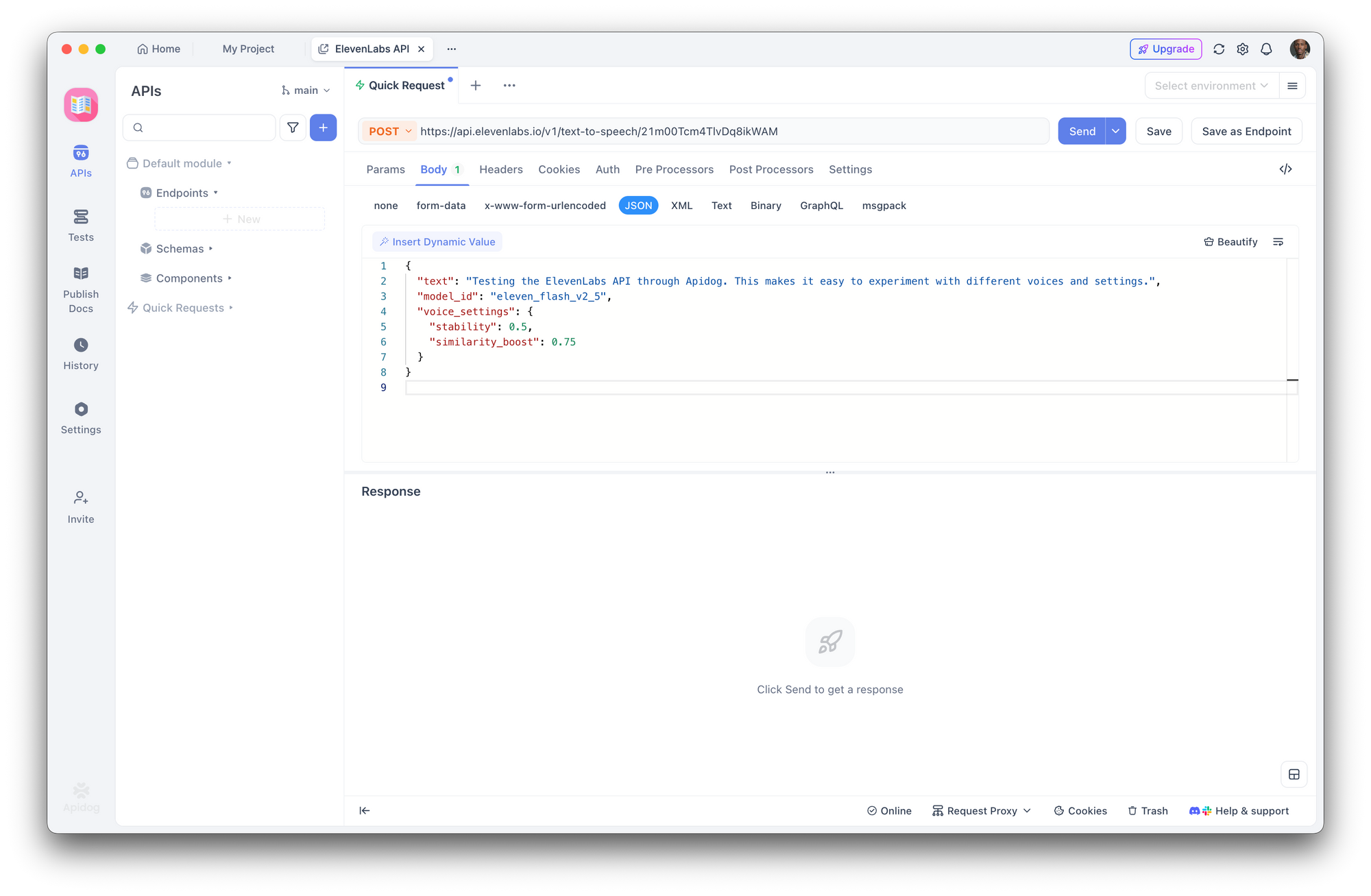
انقر على إرسال. يعرض Apidog رؤوس الاستجابة ويتيح لك تنزيل الصوت أو تشغيله مباشرة.
الخطوة 4: تجربة المعلمات
استخدم واجهة Apidog لتبديل معرفات الأصوات بسرعة، أو تغيير النماذج، أو تعديل إعدادات الصوت دون تحرير JSON الخام. احفظ التكوينات المختلفة كنقاط نهاية منفصلة في مجموعتك لتسهيل المقارنة.
الخطوة 5: توليد رمز العميل
بمجرد تأكيد عمل الطلب، انقر على توليد الرمز في Apidog للحصول على رمز عميل جاهز للاستخدام بلغات Python، JavaScript، cURL، Go، Java، والمزيد. هذا يزيل الحاجة إلى الترجمة اليدوية من وثائق واجهة برمجة التطبيقات إلى رمز عملي.
جربها الآن:حمّل Apidog مجانًا
إعدادات الصوت والضبط الدقيق
تتيح لك إعدادات الصوت ضبط كيفية صوت الصوت. يتم إرسال هذه المعلمات في كائن voice_settings:
| المعلمة | المدى | الافتراضي | التأثير |
|---|---|---|---|
stability | 0.0 - 1.0 | 0.5 | استقرار أعلى = أكثر اتساقًا، أقل تعبيرًا. استقرار أدنى = أكثر تنوعًا، أكثر عاطفية. |
similarity_boost | 0.0 - 1.0 |