
Xử lý tài liệu từ lâu đã là một trong những ứng dụng thực tế nhất của AI—thế nhưng hầu hết các giải pháp OCR đều buộc phải đánh đổi khó chịu giữa độ chính xác và hiệu quả. Các hệ thống truyền thống như Tesseract đòi hỏi quá trình tiền xử lý mở rộng. Các API đám mây tính phí theo mỗi trang và làm tăng độ trễ. Ngay cả các mô hình ngôn ngữ thị giác hiện đại cũng gặp khó khăn với tình trạng bùng nổ token phát sinh từ các hình ảnh tài liệu có độ phân giải cao.
DeepSeek-OCR 2 thay đổi hoàn toàn điều này. Dựa trên cách tiếp cận "Nén quang học theo ngữ cảnh" (Contexts Optical Compression) từ phiên bản 1, phiên bản mới giới thiệu "Luồng nhân quả thị giác" (Visual Causal Flow)—một kiến trúc xử lý tài liệu theo cách con người thực sự đọc chúng, hiểu các mối quan hệ và ngữ cảnh hình ảnh thay vì chỉ nhận dạng ký tự. Kết quả là một mô hình đạt độ chính xác 97% trong khi nén hình ảnh xuống chỉ còn 64 token, cho phép xử lý hơn 200.000 trang mỗi ngày trên một GPU duy nhất.
Hướng dẫn này bao gồm mọi thứ từ thiết lập cơ bản đến triển khai sản xuất—với mã hoạt động mà bạn có thể sao chép-dán và chạy ngay lập tức.
DeepSeek-OCR 2 là gì?
DeepSeek-OCR 2 là một mô hình ngôn ngữ-thị giác mã nguồn mở được thiết kế đặc biệt để hiểu tài liệu và trích xuất văn bản. Được DeepSeek AI phát hành vào tháng 1 năm 2026, nó được xây dựng dựa trên DeepSeek-OCR gốc với kiến trúc "Luồng nhân quả thị giác" (Visual Causal Flow) mới, mô hình hóa cách các yếu tố hình ảnh trong tài liệu liên quan đến nhau một cách nhân quả—hiểu rằng tiêu đề bảng xác định cách các ô bên dưới nó nên được giải thích, hoặc chú thích hình ảnh giải thích biểu đồ phía trên nó.
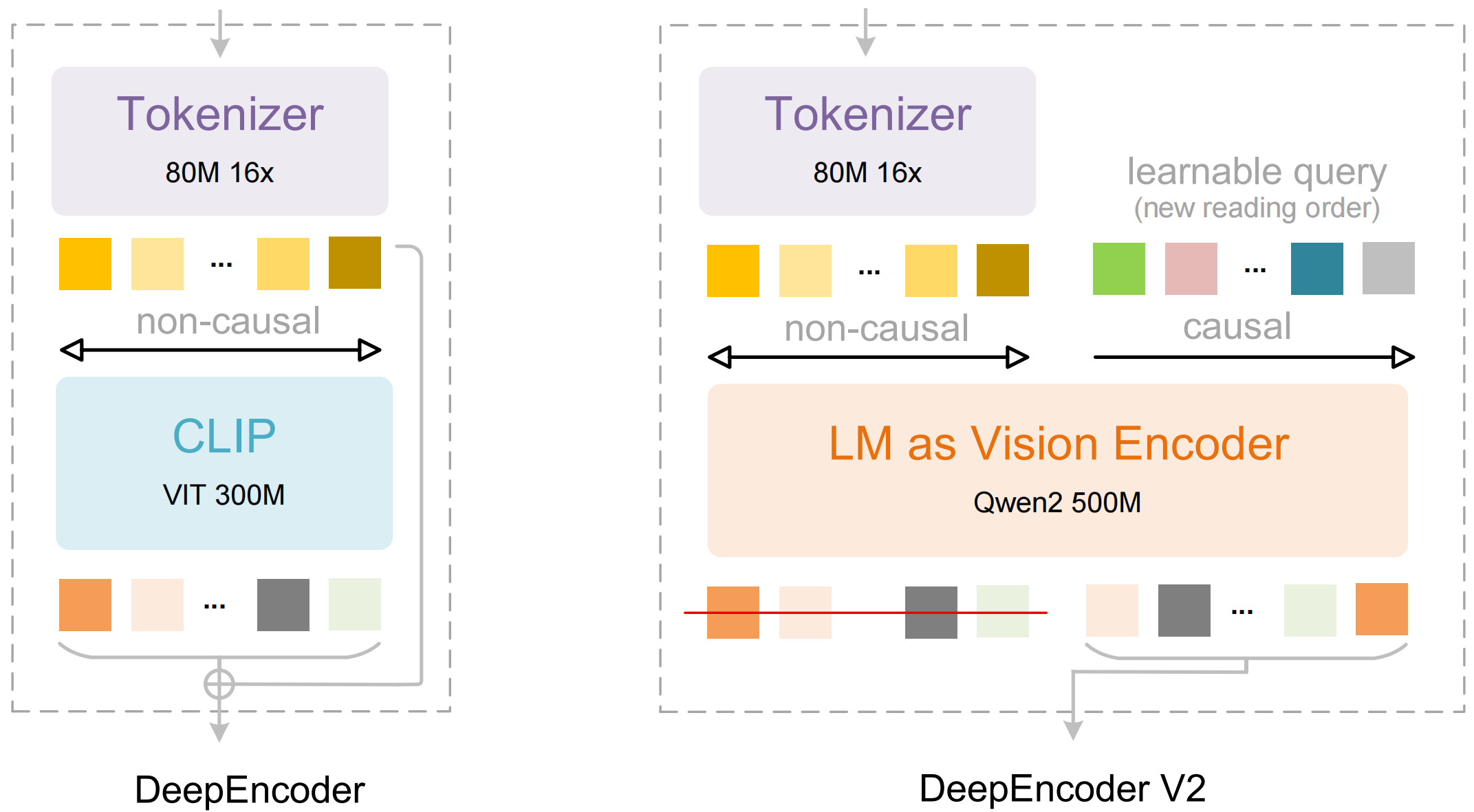
Mô hình bao gồm hai thành phần chính:
- DeepEncoder: Một transformer thị giác kép kết hợp trích xuất chi tiết cục bộ (dựa trên SAM, 80M tham số) với hiểu bố cục toàn cầu (dựa trên CLIP, 300M tham số)
- Bộ giải mã DeepSeek3B-MoE: Một mô hình ngôn ngữ kết hợp các chuyên gia (mixture-of-experts) tạo ra đầu ra có cấu trúc (Markdown, LaTeX, JSON) từ biểu diễn hình ảnh đã nén
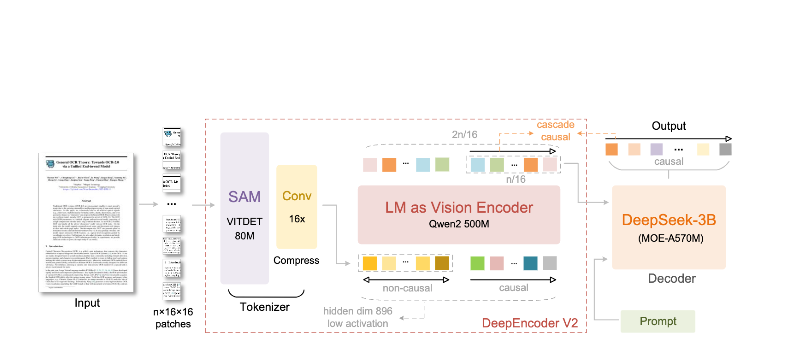
Điều gì làm nên sự khác biệt của DeepSeek-OCR 2:
- Nén cực cao: Giảm một hình ảnh 1024×1024 từ 4.096 mảng ảnh xuống chỉ còn 256 token—giảm 16 lần
- Đầu ra có cấu trúc: Tạo ra Markdown sạch với các bảng, tiêu đề và định dạng phù hợp
- Hỗ trợ đa định dạng: Xử lý PDF, tài liệu đã quét, ảnh chụp màn hình, ghi chú viết tay và nhiều hơn nữa
- Hơn 100 ngôn ngữ: Được huấn luyện trên 30 triệu trang bao phủ khoảng 100 ngôn ngữ
- Trọng số mở: Được cấp phép theo MIT, có sẵn trên Hugging Face
Các tính năng chính và Kiến trúc
Luồng nhân quả thị giác (Visual Causal Flow)
Tính năng nổi bật của phiên bản 2 là "Luồng nhân quả thị giác" (Visual Causal Flow)—một cách tiếp cận mới để hiểu tài liệu vượt xa OCR đơn thuần. Thay vì coi một trang như một lưới ký tự phẳng, mô hình học các mối quan hệ nhân quả giữa các yếu tố hình ảnh:
- Suy luận thứ tự đọc: Tự động xác định trình tự chính xác cho bố cục nhiều cột
- Hiểu cấu trúc bảng: Nhận dạng tiêu đề, ô đã hợp nhất và các bảng lồng nhau
- Liên kết hình ảnh-chú thích: Kết nối hình ảnh với mô tả của chúng
- Phân tích biểu thức toán học: Xử lý LaTeX nội tuyến và khối một cách chính xác
Kiến trúc DeepEncoder
DeepEncoder là nơi điều kỳ diệu xảy ra. Nó xử lý hình ảnh độ phân giải cao trong khi vẫn duy trì số lượng token có thể quản lý được:
Input Image (1024×1024)
↓
Khối SAM-base (80M tham số)
- Cơ chế chú ý theo cửa sổ để lấy chi tiết cục bộ
- Trích xuất các đặc điểm chi tiết
↓
Khối CLIP-large (300M tham số)
- Cơ chế chú ý toàn cục cho bố cục
- Hiểu cấu trúc tài liệu
↓
Khối Convolution
- Giảm token 16 lần
- 4.096 mảng ảnh → 256 token
↓
Đầu ra: Các token thị giác đã nén
Đánh đổi giữa nén và độ chính xác
| Tỷ lệ nén | Token thị giác | Độ chính xác |
|---|---|---|
| 4× | 1.024 | 99%+ |
| 10× | 256 | 97% |
| 16× | 160 | 92% |
| 20× | 128 | ~60% |
Điểm tối ưu cho hầu hết các ứng dụng là tỷ lệ nén 10×, duy trì độ chính xác 97% trong khi cho phép thông lượng cao, giúp việc triển khai sản xuất trở nên thực tế.
Cài đặt và Thiết lập
Yêu cầu tiên quyết
- Python 3.10+ (khuyến nghị 3.12.9)
- CUDA 11.8+ với GPU NVIDIA tương thích
- Ít nhất 16GB bộ nhớ GPU (khuyến nghị A100-40G cho sản xuất)
Phương pháp 1: Cài đặt vLLM (Khuyến nghị)
vLLM mang lại hiệu suất tốt nhất cho việc triển khai sản xuất:
# Tạo môi trường ảo
python -m venv deepseek-ocr-env
source deepseek-ocr-env/bin/activate
# Cài đặt vLLM với hỗ trợ CUDA
pip install vllm>=0.8.5
# Cài đặt flash attention để đạt hiệu suất tối ưu
pip install flash-attn==2.7.3 --no-build-isolation
Phương pháp 2: Cài đặt Transformers
Để phát triển và thử nghiệm:
pip install transformers>=4.40.0
pip install torch>=2.6.0 torchvision>=0.21.0
pip install accelerate
pip install flash-attn==2.7.3 --no-build-isolation
Phương pháp 3: Docker (Sản xuất)
FROM nvidia/cuda:11.8-devel-ubuntu22.04
RUN pip install vllm>=0.8.5 flash-attn==2.7.3
# Tải trước mô hình
RUN python -c "from vllm import LLM; LLM(model='deepseek-ai/DeepSeek-OCR-2')"
EXPOSE 8000
CMD ["vllm", "serve", "deepseek-ai/DeepSeek-OCR-2", "--port", "8000"]
Xác minh cài đặt
import torch
print(f"Phiên bản PyTorch: {torch.__version__}")
print(f"CUDA có sẵn: {torch.cuda.is_available()}")
print(f"GPU: {torch.cuda.get_device_name(0)}")
import vllm
print(f"Phiên bản vLLM: {vllm.__version__}")
Ví dụ mã Python
OCR cơ bản với vLLM
Đây là cách đơn giản nhất để trích xuất văn bản từ hình ảnh tài liệu:
from vllm import LLM, SamplingParams
from vllm.model_executor.models.deepseek_ocr import NGramPerReqLogitsProcessor
from PIL import Image
# Khởi tạo mô hình
llm = LLM(
model="deepseek-ai/DeepSeek-OCR-2",
enable_prefix_caching=False,
mm_processor_cache_gb=0,
logits_processors=[NGramPerReqLogitsProcessor],
trust_remote_code=True,
)
# Tải hình ảnh tài liệu của bạn
image = Image.open("document.png").convert("RGB")
# Chuẩn bị lời nhắc - "Free OCR." kích hoạt trích xuất tiêu chuẩn
prompt = "<image>\nFree OCR."
model_input = [{
"prompt": prompt,
"multi_modal_data": {"image": image}
}]
# Cấu hình các tham số lấy mẫu
sampling_params = SamplingParams(
temperature=0.0, # Xác định cho OCR
max_tokens=8192,
extra_args={
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": {128821, 128822}, # <td>, </td> cho bảng
},
skip_special_tokens=False,
)
# Tạo đầu ra
outputs = llm.generate(model_input, sampling_params)
# Trích xuất văn bản markdown
markdown_text = outputs[0].outputs[0].text
print(markdown_text)
Xử lý hàng loạt nhiều tài liệu
Xử lý nhiều tài liệu một cách hiệu quả trong một lô duy nhất:
from vllm import LLM, SamplingParams
from vllm.model_executor.models.deepseek_ocr import NGramPerReqLogitsProcessor
from PIL import Image
from pathlib import Path
def batch_ocr(image_paths: list[str], llm: LLM) -> list[str]:
"""Xử lý nhiều hình ảnh trong một lô duy nhất."""
# Tải tất cả hình ảnh
images = [Image.open(p).convert("RGB") for p in image_paths]
# Chuẩn bị đầu vào theo lô
prompt = "<image>\nFree OCR."
model_inputs = [
{"prompt": prompt, "multi_modal_data": {"image": img}}
for img in images
]
sampling_params = SamplingParams(
temperature=0.0,
max_tokens=8192,
extra_args={
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": {128821, 128822},
},
skip_special_tokens=False,
)
# Tạo tất cả đầu ra trong một lần gọi
outputs = llm.generate(model_inputs, sampling_params)
return [out.outputs[0].text for out in outputs]
# Cách sử dụng
llm = LLM(
model="deepseek-ai/DeepSeek-OCR-2",
enable_prefix_caching=False,
mm_processor_cache_gb=0,
logits_processors=[NGramPerReqLogitsProcessor],
)
image_files = list(Path("documents/").glob("*.png"))
results = batch_ocr([str(f) for f in image_files], llm)
for path, text in zip(image_files, results):
print(f"--- {path.name} ---")
print(text[:500]) # 500 ký tự đầu tiên
print()
Sử dụng trực tiếp Transformers
Để kiểm soát nhiều hơn quá trình suy luận:
import torch
from transformers import AutoModel, AutoTokenizer
from PIL import Image
# Đặt GPU
device = "cuda:0"
# Tải mô hình và tokenizer
model_name = "deepseek-ai/DeepSeek-OCR-2"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(
model_name,
_attn_implementation="flash_attention_2",
trust_remote_code=True,
use_safetensors=True,
)
model = model.eval().to(device).to(torch.bfloat16)
# Tải và tiền xử lý hình ảnh
image = Image.open("document.png").convert("RGB")
# Các lời nhắc khác nhau cho các tác vụ khác nhau
prompts = {
"ocr": "<image>\nFree OCR.",
"markdown": "<image>\n<|grounding|>Chuyển đổi tài liệu sang markdown.",
"table": "<image>\nTrích xuất tất cả các bảng dưới dạng markdown.",
"math": "<image>\nTrích xuất các biểu thức toán học dưới dạng LaTeX.",
}
# Xử lý với lời nhắc đã chọn của bạn
prompt = prompts["markdown"]
inputs = tokenizer(prompt, return_tensors="pt").to(device)
# Thêm hình ảnh vào đầu vào (tiền xử lý cụ thể theo mô hình)
with torch.no_grad():
outputs = model.generate(
**inputs,
images=[image],
max_new_tokens=4096,
do_sample=False,
)
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(result)
Xử lý bất đồng bộ cho thông lượng cao
import asyncio
from vllm import AsyncLLMEngine, AsyncEngineArgs, SamplingParams
from vllm.model_executor.models.deepseek_ocr import NGramPerReqLogitsProcessor
from PIL import Image
async def process_document(engine, image_path: str, request_id: str):
"""Xử lý một tài liệu duy nhất một cách bất đồng bộ."""
image = Image.open(image_path).convert("RGB")
prompt = "<image>\nFree OCR."
sampling_params = SamplingParams(
temperature=0.0,
max_tokens=8192,
extra_args={
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": {128821, 128822},
},
)
results = []
async for output in engine.generate(prompt, sampling_params, request_id):
results.append(output)
return results[-1].outputs[0].text
async def main():
# Khởi tạo engine bất đồng bộ
engine_args = AsyncEngineArgs(
model="deepseek-ai/DeepSeek-OCR-2",
enable_prefix_caching=False,
mm_processor_cache_gb=0,
)
engine = AsyncLLMEngine.from_engine_args(engine_args)
# Xử lý nhiều tài liệu đồng thời
image_paths = ["doc1.png", "doc2.png", "doc3.png"]
tasks = [
process_document(engine, path, f"req_{i}")
for i, path in enumerate(image_paths)
]
results = await asyncio.gather(*tasks)
for path, text in zip(image_paths, results):
print(f"{path}: {len(text)} ký tự đã được trích xuất")
asyncio.run(main())
Sử dụng vLLM cho sản xuất
Khởi động máy chủ tương thích OpenAI
Triển khai DeepSeek-OCR 2 dưới dạng máy chủ API:
vllm serve deepseek-ai/DeepSeek-OCR-2 \
--host 0.0.0.0 \
--port 8000 \
--logits_processors vllm.model_executor.models.deepseek_ocr:NGramPerReqLogitsProcessor \
--no-enable-prefix-caching \
--mm-processor-cache-gb 0 \
--max-model-len 16384 \
--gpu-memory-utilization 0.9
Gọi máy chủ bằng OpenAI SDK
from openai import OpenAI
import base64
# Khởi tạo client trỏ đến máy chủ cục bộ
client = OpenAI(
api_key="EMPTY", # Không bắt buộc đối với máy chủ cục bộ
base_url="http://localhost:8000/v1",
timeout=3600,
)
def encode_image(image_path: str) -> str:
"""Mã hóa hình ảnh sang base64."""
with open(image_path, "rb") as f:
return base64.b64encode(f.read()).decode("utf-8")
def ocr_document(image_path: str) -> str:
"""Trích xuất văn bản từ tài liệu bằng API OCR."""
base64_image = encode_image(image_path)
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-OCR-2",
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": f"data:image/png;base64,{base64_image}"
}
},
{
"type": "text",
"text": "Free OCR."
}
]
}
],
max_tokens=8192,
temperature=0.0,
extra_body={
"skip_special_tokens": False,
"vllm_xargs": {
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": [128821, 128822],
},
},
)
return response.choices[0].message.content
# Cách sử dụng
result = ocr_document("invoice.png")
print(result)
Sử dụng với URL
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-OCR-2",
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://example.com/document.png"
}
},
{
"type": "text",
"text": "Free OCR."
}
]
}
],
max_tokens=8192,
temperature=0.0,
)
Kiểm tra với Apidog
Để kiểm tra API OCR hiệu quả đòi hỏi phải trực quan hóa cả tài liệu đầu vào và đầu ra đã trích xuất. Apidog cung cấp một giao diện trực quan để thử nghiệm với DeepSeek-OCR 2.
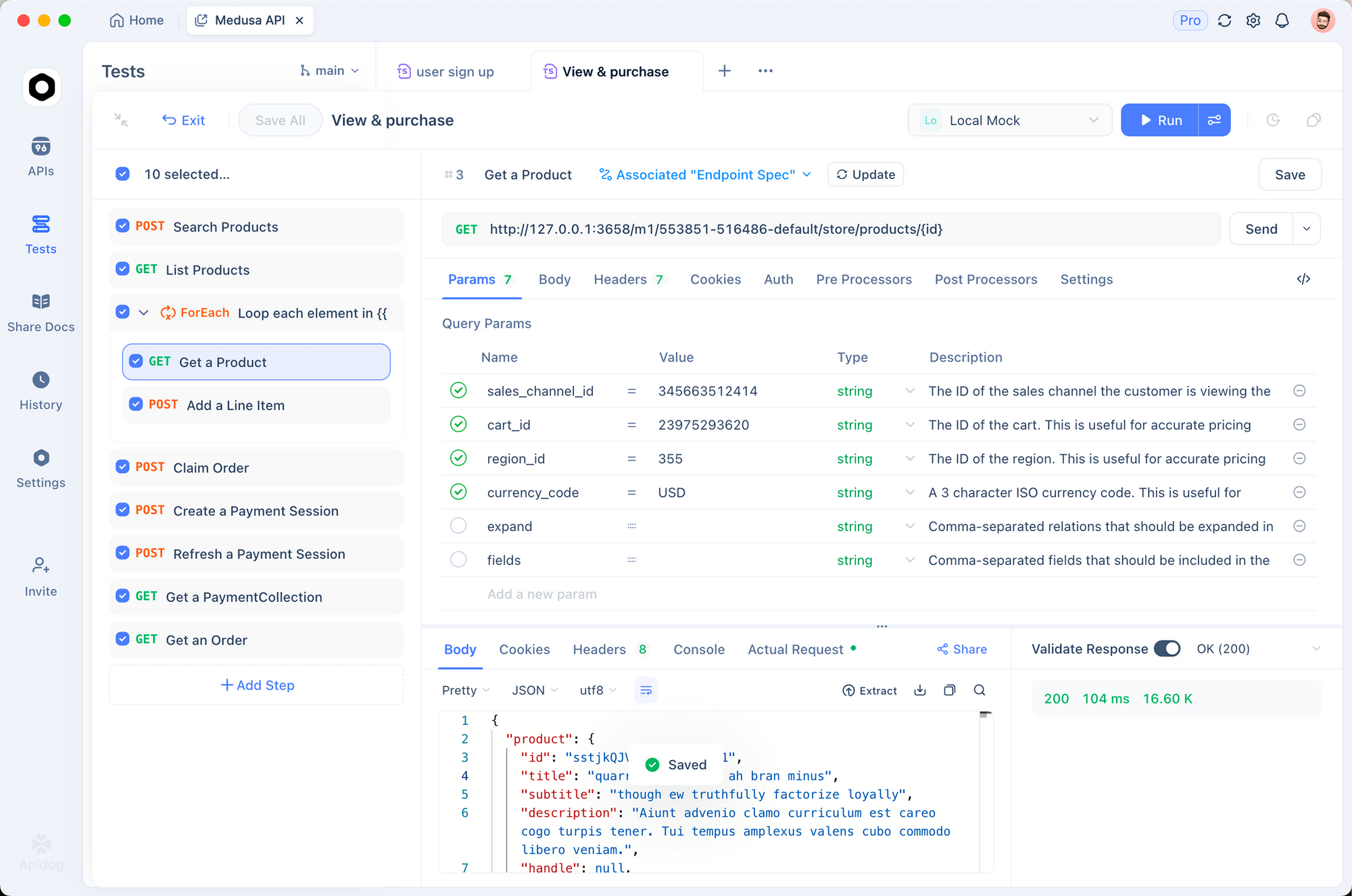
Thiết lập điểm cuối OCR
Bước 1: Tạo yêu cầu mới
- Mở Apidog và tạo một dự án mới
- Thêm yêu cầu POST tới
http://localhost:8000/v1/chat/completions
Bước 2: Cấu hình Header
Content-Type: application/json
Bước 3: Cấu hình Body yêu cầu
{
"model": "deepseek-ai/DeepSeek-OCR-2",
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "data:image/png;base64,{{base64_image}}"
}
},
{
"type": "text",
"text": "Free OCR."
}
]
}
],
"max_tokens": 8192,
"temperature": 0,
"extra_body": {
"skip_special_tokens": false,
"vllm_xargs": {
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": [128821, 128822]
}
}
}
Kiểm tra các loại tài liệu khác nhau
Tạo các yêu cầu đã lưu cho các loại tài liệu phổ biến:
- Trích xuất hóa đơn - Kiểm tra trích xuất dữ liệu có cấu trúc
- Bài báo khoa học - Kiểm tra xử lý toán học LaTeX
- Ghi chú viết tay - Kiểm tra nhận dạng chữ viết tay
- Bố cục nhiều cột - Kiểm tra suy luận thứ tự đọc
So sánh các chế độ độ phân giải
Thiết lập biến môi trường để nhanh chóng kiểm tra các chế độ khác nhau: