Công nghệ nhân bản giọng nói đại diện cho một trong những tiến bộ quan trọng nhất trong phát triển ứng dụng hiện đại. Các nhà phát triển hiện có khả năng tích hợp giọng nói tổng hợp siêu thực, biểu cảm cảm xúc vào ứng dụng của họ mà không cần đến hàng tháng các buổi ghi âm. Sự chuyển đổi này trở nên khả thi thông qua các API nhân bản giọng nói tinh vi, tận dụng các thuật toán học máy tiên tiến và mạng thần kinh.
Sự hội tụ của API TTS (Chuyển văn bản thành giọng nói) với API STT (Chuyển giọng nói thành văn bản) tạo ra một hệ sinh thái toàn diện cho các ứng dụng hỗ trợ giọng nói. Dù bạn đang xây dựng chatbot dịch vụ khách hàng, tạo hệ thống tường thuật sách nói hay phát triển trải nghiệm chơi game tương tác, việc chọn nền tảng API phù hợp sẽ quyết định các chỉ số thành công của bạn.
Tìm hiểu các nguyên tắc cơ bản của công nghệ nhân bản giọng nói
Nhân bản giọng nói hoạt động dựa trên một nguyên tắc đơn giản nhưng mạnh mẽ: các mô hình học máy phân tích mẫu âm thanh để trích xuất các đặc điểm giọng nói độc đáo, sau đó tái tạo các đặc điểm đó thông qua quá trình tạo giọng nói tổng hợp. Quá trình này đòi hỏi sự hiểu biết về một số thành phần cốt lõi phân biệt các API nhân bản giọng nói cao cấp với các giải pháp cơ bản.
Các hệ thống nhân bản giọng nói hiện đại hoạt động trên ba lớp vận hành chính. Đầu tiên, chúng thu thập các mẫu giọng nói chứa các đặc điểm âm điệu, kiểu giọng và sắc thái cảm xúc cụ thể. Sau đó, các mạng thần kinh tiên tiến xử lý dữ liệu này để xác định và phân lập các đặc điểm giọng nói đặc trưng. Cuối cùng, mô hình được đào tạo sẽ tạo ra giọng nói mới trong khi vẫn giữ nguyên tất cả các đặc điểm giọng nói gốc, bao gồm các kiểu phát âm, tốc độ nói và chiều sâu cảm xúc.
1. ElevenLabs: Tiêu chuẩn ngành cho chất lượng giọng nói tiếng Anh
ElevenLabs chiếm vị trí thống trị trong các API nhân bản giọng nói, đã khẳng định mình là tiêu chuẩn vàng cho chất lượng tổng hợp giọng nói tiếng Anh. Kiến trúc kỹ thuật của nền tảng cho phép nhân bản giọng nói với dữ liệu đào tạo tối thiểu, thường chỉ cần 30 giây đến hai phút mẫu âm thanh rõ ràng.
Các tính năng kỹ thuật chính:
- Nhân bản giọng nói siêu nhanh: Tạo bản sao giọng nói trong vài giây sau khi tải âm thanh lên
- Hơn 300 tùy chọn giọng nói dựng sẵn: Cung cấp giọng nói sẵn sàng sử dụng trên hơn 30 ngôn ngữ
- Kiểm soát cảm xúc và âm điệu: Cho phép điều chỉnh động các thông số biểu cảm giọng nói
- Thiết kế API-First: Cung cấp khả năng tích hợp đơn giản thông qua các điểm cuối REST và nhiều tùy chọn SDK
- Hỗ trợ WebSocket: Tạo điều kiện tổng hợp giọng nói phát trực tuyến theo thời gian thực cho các ứng dụng đàm thoại
Chất lượng giọng nói của ElevenLabs mang lại kết quả chính xác đến mức người dùng luôn báo cáo rằng giọng nói tổng hợp hầu như không thể phân biệt được với giọng nói tự nhiên của con người. Mức độ chính xác này đã đặt ra các tiêu chuẩn ngành mà các đối thủ cạnh tranh vẫn đang cố gắng đạt được.
Cấu trúc giá:
Nền tảng này hoạt động trên các mô hình đăng ký và trả tiền theo mức sử dụng. Các gói cơ bản bắt đầu từ 5 đô la mỗi tháng, trong khi các gói đăng ký cấp chuyên nghiệp đạt 99 đô la mỗi tháng cho các tính năng nâng cao bao gồm nhân bản giọng nói tùy chỉnh và quyền truy cập API ưu tiên. Các thỏa thuận doanh nghiệp cho phép sử dụng không giới hạn với giá tùy chỉnh.
2. Resemble AI: Tổng hợp giọng nói cấp doanh nghiệp với khả năng thời gian thực
Resemble AI nổi bật nhờ sự nhấn mạnh chuyên biệt vào chuyển đổi giọng nói theo thời gian thực và các ứng dụng cấp thương mại. Nền tảng này xử lý việc nhân bản giọng nói trên 62 ngôn ngữ ấn tượng, khiến nó đặc biệt phù hợp cho các ứng dụng phân phối toàn cầu.
Khả năng kỹ thuật khác biệt:
- Chuyển đổi giọng nói theo thời gian thực: Hỗ trợ chuyển đổi giọng nói trực tiếp mà không có độ trễ đáng kể
- Kiểm soát biểu cảm cảm xúc: Tinh chỉnh hạnh phúc, buồn bã, phấn khích và các trạng thái cảm xúc bổ sung
- Khung nội địa hóa: Xử lý các đặc điểm giọng nói và bảo tồn giọng điệu theo ngôn ngữ cụ thể
- Kiến trúc điểm cuối API: Cung cấp các điểm cuối có độ trễ thấp được tối ưu hóa cho các ứng dụng phát trực tuyến
- Đào tạo mô hình tùy chỉnh: Cho phép khách hàng doanh nghiệp phát triển các mô hình giọng nói độc quyền
Sự nhấn mạnh của nền tảng vào kiểm soát biểu cảm cảm xúc chứng tỏ giá trị đặc biệt đối với các ứng dụng yêu cầu truyền tải giọng nói tinh tế. Các bot dịch vụ khách hàng, trợ lý ảo và các nhân vật trò chơi tương tác đều được hưởng lợi từ khả năng kiểm soát cảm xúc chi tiết này.
Phân cấp giá:
Resemble AI cấu trúc giá theo các cấp độ, từ gói khởi đầu 5 đô la mỗi tháng đến các thỏa thuận doanh nghiệp có giá 3.000 đô la hàng năm. Đáng chú ý, gói kinh doanh bắt đầu từ 699 đô la mỗi tháng sẽ mở khóa các khả năng nhân bản giọng nói tùy chỉnh và hỗ trợ API ưu tiên.
3. Fish Audio: Tổng hợp giọng nói mã nguồn mở với kiểm soát nâng cao
Fish Audio đại diện cho một cách tiếp cận mã nguồn mở tiên tiến để tổng hợp giọng nói, cung cấp cho các nhà phát triển khả năng kiểm soát chưa từng có đối với việc tạo và tùy chỉnh giọng nói. Nền tảng này vượt trội đối với các tổ chức tìm kiếm các giải pháp tự lưu trữ, kiểm soát tham số giọng nói chi tiết và tự do khỏi các ràng buộc phụ thuộc vào nhà cung cấp.
Điểm mạnh của nền tảng:
- Kiến trúc mã nguồn mở: Cung cấp mã nguồn minh bạch, có thể sửa đổi cho phép triển khai tùy chỉnh
- Kiểm soát tham số giọng nói nâng cao: Cung cấp khả năng điều chỉnh chi tiết cao độ, tốc độ, cảm xúc và đặc tính âm thanh
- Nhiều mô hình nhân bản giọng nói: Hỗ trợ nhiều phương pháp nhân bản từ mẫu tối thiểu đến đào tạo toàn diện
- Khả năng tự lưu trữ: Cho phép triển khai tại chỗ cho các ứng dụng quan trọng về quyền riêng tư
- Mở rộng quy mô hiệu quả về chi phí: Giảm chi phí trên mỗi yêu cầu thông qua cơ sở hạ tầng tự lưu trữ mà không cần nhà cung cấp tăng giá
Nền tảng mã nguồn mở của Fish Audio đặc biệt hấp dẫn các nhà phát triển xây dựng các giải pháp giọng nói độc quyền hoặc các tổ chức có yêu cầu nghiêm ngặt về nơi lưu trữ dữ liệu. Nền tảng này loại bỏ sự phụ thuộc vào nhà cung cấp trong khi vẫn duy trì chất lượng tổng hợp giọng nói tiên tiến.
Cấu trúc giá linh hoạt:
Bản chất mã nguồn mở của Fish Audio cho phép tự lưu trữ miễn phí với chỉ chi phí cơ sở hạ tầng. Các biến thể được lưu trữ trên đám mây cung cấp giá trả tiền theo mức sử dụng bắt đầu từ mức tối thiểu, trong khi các thỏa thuận doanh nghiệp cho phép các phiên bản chuyên dụng và hỗ trợ ưu tiên. Các tổ chức ưu tiên hiệu quả chi phí ở quy mô lớn sẽ thấy Fish Audio đặc biệt hấp dẫn.
4. Tavus: Hội tụ giọng nói với tổng hợp video
Tavus chiếm một vị trí độc đáo bằng cách hợp nhất nhân bản giọng nói với tạo video chân thực. Nền tảng này tạo ra con người AI nói bằng giọng nói được nhân bản trong khi vẫn duy trì biểu cảm khuôn mặt và đồng bộ hóa môi nhất quán.
Các tính năng tích hợp mang tính cách mạng:
- Giao diện video đàm thoại (CVI): Cho phép tương tác trực tiếp theo thời gian thực với các hình đại diện AI
- Tạo hình đại diện chân thực: Tạo video đầu nói từ các đầu vào kịch bản
- Hỗ trợ đa ngôn ngữ: Hỗ trợ hơn 30 ngôn ngữ với tự động đồng bộ hóa môi và lồng tiếng
- Đồng bộ hóa cấp độ Studio: Cung cấp âm thanh 24 kHz với độ chính xác đồng bộ môi hoàn hảo
- Cá nhân hóa ở quy mô lớn: Tạo hàng nghìn video tùy chỉnh duy trì giọng nói và hình ảnh nhất quán
Sự kết hợp giữa tổng hợp giọng nói và video này chứng tỏ giá trị đặc biệt đối với các chiến dịch tiếp thị, nội dung giáo dục và nền tảng tương tác khách hàng. Các tổ chức có thể cá nhân hóa thông điệp ở quy mô lớn trong khi vẫn duy trì tính nhất quán hoàn toàn về hình ảnh và giọng nói.
Cân nhắc chi phí:
Mô hình định giá tập trung vào doanh nghiệp yêu cầu báo giá tùy chỉnh. Tuy nhiên, khả năng tạo ra hàng nghìn video cá nhân hóa của nền tảng này đã biện minh cho khoản đầu tư của các tổ chức có nhu cầu phân phối nội dung đáng kể.
5. Murf AI: Tạo giọng nói chuyên nghiệp dễ tiếp cận
Murf AI nhấn mạnh khả năng tiếp cận mà không hy sinh chất lượng chuyên nghiệp. Nền tảng này thu hút những người tạo nội dung, nhà giáo dục và doanh nghiệp đang tìm kiếm giải pháp tổng hợp giọng nói đơn giản mà không có rào cản kỹ thuật cản trở.
Các tính năng tập trung vào khả năng tiếp cận:
- Giao diện kéo và thả: Đơn giản hóa tổng hợp giọng nói mà không cần điều kiện tiên quyết kỹ thuật
- Hơn 120 giọng nói chuyên nghiệp: Cung cấp nhiều tùy chọn giọng nói dựng sẵn
- Kiểu cảm xúc: Hỗ trợ nhiều biểu cảm giọng nói trong một dự án
- Tường thuật đa giọng nói: Cho phép tạo đối thoại liên quan đến nhiều người nói
- Bao gồm quyền thương mại: Cho phép sử dụng nội dung được tạo không hạn chế cho mục đích thương mại
Murf dân chủ hóa tổng hợp giọng nói bằng cách loại bỏ sự phức tạp về kỹ thuật. Những người tạo nội dung có thể tập trung vào việc viết kịch bản trong khi nền tảng tự động xử lý việc tạo giọng nói.
Cấu trúc giá trong suốt:
Gói miễn phí cung cấp khoảng 10 phút tạo giọng nói hàng tháng để thử nghiệm. Gói Creator bắt đầu từ 19 đô la mỗi tháng (thanh toán hàng năm) cung cấp 2 giờ tạo giọng nói. Các cấp độ chuyên nghiệp đạt 39 đô la mỗi tháng với quyền truy cập thư viện giọng nói đầy đủ và các tính năng nâng cao.
Phân tích so sánh: Chọn API nhân bản giọng nói lý tưởng của bạn
Mỗi nền tảng đều xuất sắc trong các kịch bản cụ thể và việc so sánh khả năng kỹ thuật của chúng giúp sắp xếp hợp lý việc lựa chọn. Bảng sau đây cung cấp tổng quan hợp lý về cách năm API nhân bản giọng nói này đối chiếu với các tiêu chí đánh giá quan trọng:
| Tính năng | ElevenLabs | Resemble AI | Fish Audio | Tavus | Murf AI |
|---|---|---|---|---|---|
| Chất lượng giọng nói tiếng Anh | Cao nhất | Xuất sắc | Xuất sắc | Rất cao | Tốt |
| Hỗ trợ ngôn ngữ | Hơn 30 | Hơn 62 | Hơn 50 | Hơn 30 | Hơn 70 |
| Phát trực tuyến thời gian thực | Có | Có | Có | Không | Hạn chế |
| Tốc độ nhân bản giọng nói | 30 giây | Thay đổi | Nhanh | 2 phút | Không |
| Kiểm soát cảm xúc | Tốt | Xuất sắc | Xuất sắc | Xuất sắc | Rất tốt |
| Tích hợp hình đại diện video | Không | Không | Không | Có | Không |
| Giá khởi điểm | 5 USD/tháng | 5 USD/tháng | Miễn phí (Tự lưu trữ) | Tùy chỉnh | Miễn phí |
| Trường hợp sử dụng tốt nhất | Chất lượng tiếng Anh | Doanh nghiệp | Tập trung vào nhà phát triển | Nội dung video | Người tạo nội dung |
Tiêu chí lựa chọn chiến lược
Để có chất lượng giọng nói tiếng Anh tối đa: ElevenLabs chiếm vị trí cao cấp khi độ chân thực của giọng nói tiếng Anh quyết định sự thành công của ứng dụng. Nếu thị trường mục tiêu của bạn chỉ nói tiếng Anh và tính tự nhiên của giọng nói trở thành không thể thương lượng, ElevenLabs mang lại sự nhất quán và chân thực cảm xúc cao nhất so với các nền tảng cạnh tranh.
Đối với các ứng dụng đàm thoại thời gian thực: Resemble AI và Fish Audio đều hỗ trợ kiến trúc truyền tải cần thiết cho trải nghiệm đàm thoại. Các ứng dụng yêu cầu độ trễ dưới 100ms nên ưu tiên các nền tảng này, vì việc triển khai của chúng loại bỏ độ trễ đáng kể giữa đầu vào văn bản và đầu ra âm thanh.
Đối với các triển khai được kiểm soát bởi nhà phát triển: Nền tảng mã nguồn mở của Fish Audio thu hút các nhóm phát triển tìm kiếm sự kiểm soát hoàn toàn đối với các quy trình tổng hợp giọng nói. Triển khai tự lưu trữ loại bỏ sự phụ thuộc vào nhà cung cấp, giảm chi phí trên mỗi yêu cầu ở quy mô lớn và cho phép các tùy chỉnh độc quyền không thể thực hiện được với các đối thủ cạnh tranh mã nguồn đóng.
Đối với các ứng dụng tập trung vào video: Tavus đứng một mình trong việc kết hợp nhân bản giọng nói với việc tạo hình đại diện chân thực. Các tổ chức tạo chiến dịch video được cá nhân hóa, nội dung giáo dục tương tác hoặc hình đại diện dịch vụ khách hàng sống động như thật nên đánh giá Tavus độc quyền, vì không có nền tảng nào khác cung cấp các khả năng tích hợp tương đương.
Đối với các nhóm không chuyên về kỹ thuật: Giao diện kéo và thả của Murf AI và các yêu cầu kỹ thuật tối thiểu làm cho nó tối ưu cho các nhóm tiếp thị, người tạo nội dung và các tổ chức thiếu nguồn lực phát triển chuyên trách. Nền tảng này đánh đổi một số tùy chỉnh nâng cao để có khả năng tiếp cận đáng kể.
Đối với các Startup quan tâm đến chi phí: Cả ElevenLabs và Resemble AI đều cung cấp mức giá cạnh tranh chỉ từ 5 đô la mỗi tháng, khiến chúng trở thành điểm khởi đầu dễ tiếp cận. Tùy chọn tự lưu trữ miễn phí của Fish Audio cung cấp khả năng sử dụng không giới hạn mà không mất phí đăng ký, mặc dù có chi phí cơ sở hạ tầng.
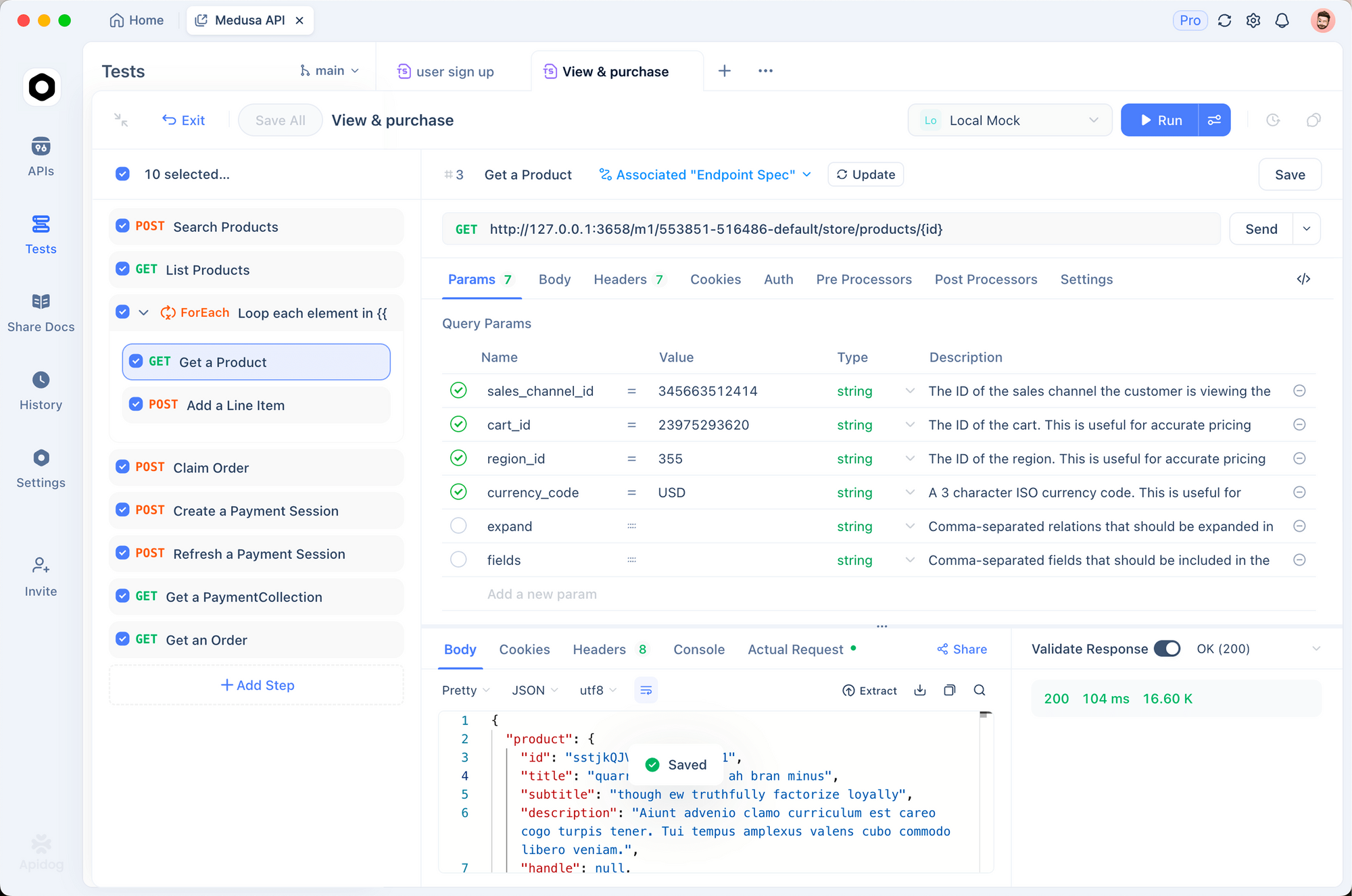
Triển khai thực tế với Apidog
Tích hợp các API nhân bản giọng nói đòi hỏi kiểm tra và xác thực có hệ thống. Apidog hợp lý hóa quá trình này bằng cách tập trung kiểm tra API trong một nền tảng duy nhất.
Quy trình triển khai:
- Thiết kế API: Sử dụng trình chỉnh sửa trực quan của Apidog để ghi lại các điểm cuối API nhân bản giọng nói cùng với các tích hợp khác
- Tạo kịch bản kiểm tra: Xây dựng các kịch bản kiểm tra toàn diện để xác thực chất lượng tổng hợp giọng nói và các tham số độ trễ
- Tạo dữ liệu giả lập (Mock Data): Tạo phản hồi giả lập thực tế trước khi triển khai với các API sản xuất
- Kiểm thử tự động: Thực hiện kiểm thử tích hợp liên tục để đảm bảo tổng hợp giọng nói luôn nhất quán trên các triển khai
- Tạo tài liệu: Tự động tạo tài liệu API cho việc cộng tác nhóm
Tính năng quản lý môi trường của Apidog chứng tỏ giá trị đặc biệt khi kiểm thử đồng thời nhiều API nhân bản giọng nói. Chuyển đổi giữa ElevenLabs, Resemble AI và các nền tảng khác chỉ yêu cầu chọn môi trường chứ không cần sửa đổi điểm cuối.
Kết luận: Lựa chọn tương lai tổng hợp giọng nói của bạn
Các API nhân bản giọng nói đã chuyển từ công nghệ thử nghiệm thành các thành phần phát triển thiết yếu. Năm nền tảng được trình bày chi tiết trong hướng dẫn này đều đại diện cho các ưu tiên tối ưu hóa khác nhau, cho dù là chất lượng, khả năng tiếp cận, hỗ trợ đa ngôn ngữ, tích hợp video hay các yêu cầu kỹ thuật cụ thể.
Thành công trong việc triển khai của bạn phụ thuộc vào việc chọn nền tảng phù hợp với các yêu cầu riêng của ứng dụng. Hãy kiểm tra nhiều tùy chọn bằng cách sử dụng các nền tảng như Apidog để đánh giá hiệu suất, độ trễ và chất lượng giọng nói trong các kịch bản thực tế.
Bắt đầu: Tải xuống Apidog để thiết kế, kiểm tra và tích hợp các API nhân bản giọng nói cùng với hệ sinh thái phát triển rộng lớn hơn của bạn. Tập trung kiểm thử API của bạn trong khi việc triển khai tổng hợp giọng nói của bạn tiến từ nguyên mẫu đến sản xuất.