
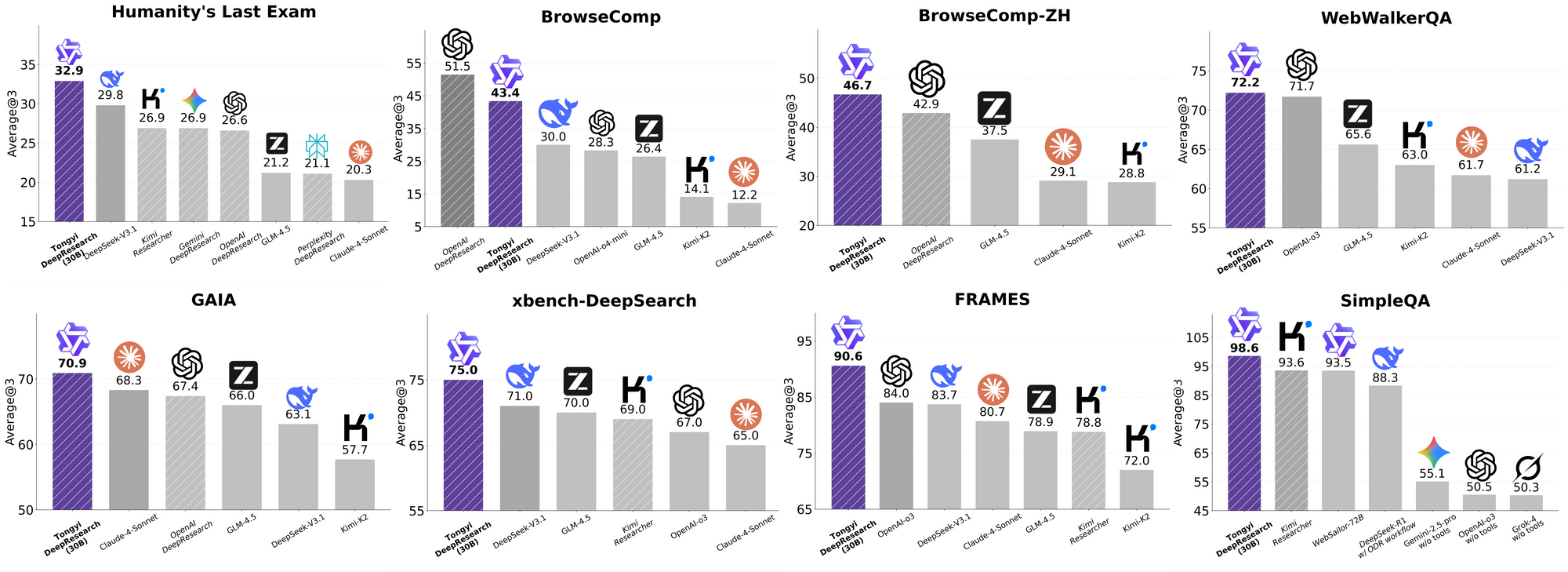
Tongyi DeepResearch của Alibaba định nghĩa lại các tác nhân AI tự chủ với mô hình Mixture of Experts (MoE) 30 tỷ tham số, chỉ kích hoạt 3 tỷ tham số trên mỗi token để nghiên cứu web hiệu quả, độ chính xác cao. Cỗ máy mã nguồn mở mạnh mẽ này vượt qua các điểm chuẩn như Humanity's Last Exam (32,9% so với 24,9% của OpenAI o3) và xbench-DeepSearch (75,0% so với 67,0%), cho phép các nhà phát triển giải quyết các truy vấn phức tạp, nhiều bước — từ phân tích pháp lý đến lịch trình du lịch — mà không bị khóa vào nhà cung cấp độc quyền.
nút
Các kỹ sư tại Tongyi Lab đã thiết kế tác nhân này để chinh phục khả năng suy luận dài hạn và sử dụng công cụ động một cách trực tiếp. Do đó, nó vượt trội hơn các mô hình đóng trong việc tổng hợp thế giới thực, đồng thời chạy cục bộ thông qua Hugging Face. Trong phân tích kỹ thuật này, chúng tôi sẽ mổ xẻ kiến trúc thưa thớt, quy trình dữ liệu tự động, đào tạo tối ưu hóa bằng RL, sự thống trị về điểm chuẩn và các thủ thuật triển khai của nó. Đến cuối bài, bạn sẽ thấy Tongyi DeepResearch — và các công cụ như Apidog — mở khóa AI tác nhân có thể mở rộng cho các dự án của bạn như thế nào.
Tìm hiểu Tongyi DeepResearch: Các khái niệm cốt lõi và đổi mới
Tongyi DeepResearch định nghĩa lại AI tác nhân bằng cách tập trung vào việc truy xuất và tổng hợp thông tin chuyên sâu. Không giống như các mô hình ngôn ngữ lớn (LLM) truyền thống xuất sắc trong việc tạo nội dung ngắn, tác nhân này điều hướng các môi trường động như trình duyệt web để khám phá những hiểu biết sâu sắc. Cụ thể, nó sử dụng kiến trúc Mixture of Experts (MoE), trong đó toàn bộ 30 tỷ tham số chỉ được kích hoạt chọn lọc thành 3 tỷ trên mỗi token. Hiệu quả này cho phép hiệu suất mạnh mẽ trên phần cứng hạn chế tài nguyên trong khi vẫn duy trì nhận thức ngữ cảnh cao lên đến 128K token.
Hơn nữa, mô hình tích hợp liền mạch với các mô hình suy luận bắt chước quá trình ra quyết định giống con người. Ở chế độ ReAct, nó tự động luân chuyển qua các bước suy nghĩ, hành động và quan sát, bỏ qua việc thiết kế lời nhắc phức tạp. Đối với các tác vụ đòi hỏi khắt khe hơn, chế độ Heavy kích hoạt khung IterResearch, điều phối các khám phá tác nhân song song để tránh quá tải ngữ cảnh. Kết quả là, người dùng đạt được kết quả vượt trội trong các tình huống yêu cầu tinh chỉnh lặp đi lặp lại, chẳng hạn như đánh giá tài liệu học thuật hoặc phân tích thị trường.
Điều làm nên sự khác biệt của Tongyi DeepResearch nằm ở cam kết cởi mở của nó. Toàn bộ hệ thống — từ trọng số mô hình đến mã đào tạo — đều nằm trên các nền tảng như Hugging Face và GitHub. Các nhà phát triển truy cập trực tiếp biến thể Tongyi-DeepResearch-30B-A3B, tạo điều kiện tinh chỉnh cho các nhu cầu cụ thể theo miền. Ngoài ra, khả năng tương thích của nó với các môi trường Python tiêu chuẩn giúp giảm rào cản gia nhập. Ví dụ, việc cài đặt chỉ cần một lệnh pip đơn giản sau khi thiết lập môi trường Conda với Python 3.10.
Chuyển sang tiện ích thực tế, Tongyi DeepResearch cung cấp năng lượng cho các ứng dụng đòi hỏi đầu ra có thể kiểm chứng. Trong nghiên cứu pháp lý, nó phân tích các đạo luật và án lệ, trích dẫn các nguồn một cách chính xác. Tương tự, trong lập kế hoạch du lịch, nó xây dựng các hành trình nhiều ngày bằng cách đối chiếu dữ liệu thời gian thực. Những khả năng này bắt nguồn từ một triết lý thiết kế có chủ ý: ưu tiên suy luận tác nhân hơn là chỉ dự đoán.
Kiến trúc của Tongyi DeepResearch: Hiệu quả kết hợp với sức mạnh
Về cốt lõi, Tongyi DeepResearch tận dụng thiết kế MoE thưa thớt để cân bằng nhu cầu tính toán với sức mạnh biểu cảm. Mô hình chỉ kích hoạt một tập hợp con các chuyên gia trên mỗi token, định tuyến đầu vào động dựa trên độ phức tạp của truy vấn. Phương pháp này giảm độ trễ tới 90% so với các đối tác dày đặc, giúp nó khả thi cho việc triển khai tác nhân theo thời gian thực. Hơn nữa, cửa sổ ngữ cảnh 128K hỗ trợ các tương tác mở rộng, rất quan trọng cho các tác vụ liên quan đến chuỗi tài liệu dài hoặc tìm kiếm web theo luồng.
Các thành phần kiến trúc chính bao gồm một trình mã hóa tùy chỉnh được tối ưu hóa cho các token tác nhân — chẳng hạn như tiền tố hành động và dấu phân cách quan sát — và một bộ công cụ nhúng để điều hướng trình duyệt, truy xuất và tính toán. Khung này hỗ trợ tích hợp học tăng cường theo chính sách (RL), nơi các tác nhân học hỏi từ các lần chạy mô phỏng trong một môi trường ổn định. Do đó, mô hình ít bị ảo giác hơn trong việc gọi công cụ, bằng chứng là điểm số cao của nó trên các điểm chuẩn sử dụng công cụ.
Ngoài ra, Tongyi DeepResearch còn tích hợp bộ nhớ tri thức neo theo thực thể, được lấy từ tổng hợp dữ liệu dựa trên đồ thị. Cơ chế này neo các phản hồi vào các thực thể thực tế, tăng cường khả năng truy xuất nguồn gốc. Ví dụ, trong một truy vấn về những tiến bộ trong điện toán lượng tử, tác nhân truy xuất và tổng hợp các bài báo thông qua các công cụ giống như WebSailor, làm nền tảng cho các đầu ra trong các nguồn có thể kiểm chứng. Do đó, kiến trúc không chỉ xử lý thông tin mà còn chủ động quản lý nó.
Để minh họa, hãy xem xét cách mô hình xử lý các đầu vào đa phương thức. Mặc dù chủ yếu dựa trên văn bản, các phần mở rộng thông qua kho lưu trữ GitHub cho phép tích hợp với các trình phân tích hình ảnh hoặc trình thực thi mã. Các nhà phát triển cấu hình những điều này trong tập lệnh suy luận, chỉ định đường dẫn cho các tập dữ liệu ở định dạng JSONL. Như vậy, kiến trúc thúc đẩy khả năng mở rộng, mời gọi sự đóng góp từ cộng đồng mã nguồn mở.
Tổng hợp dữ liệu tự động: Thúc đẩy khả năng của Tongyi DeepResearch
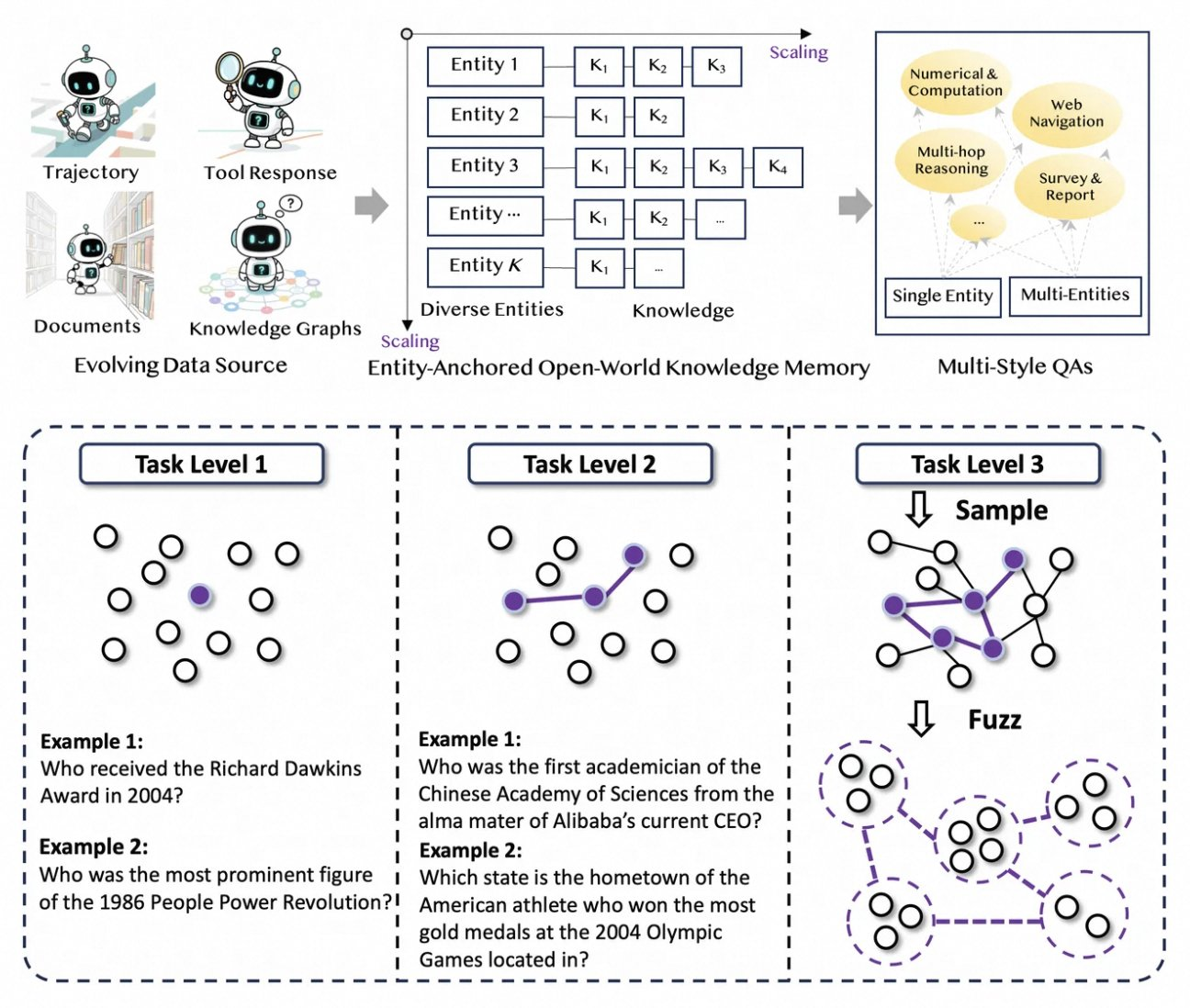
Tongyi DeepResearch phát triển mạnh nhờ một quy trình dữ liệu mới, hoàn toàn tự động, loại bỏ các nút thắt cổ chai trong việc chú thích thủ công. Quá trình này bắt đầu với AgentFounder, một công cụ tổng hợp tổ chức lại các kho ngữ liệu thô — tài liệu, thu thập dữ liệu web và biểu đồ tri thức — thành các cặp QA neo theo thực thể. Bước này tạo ra các quỹ đạo đa dạng để đào tạo trước liên tục (CPT), bao gồm các chuỗi suy luận, các lệnh gọi công cụ và cây quyết định.
Tiếp theo, quy trình tăng mức độ khó thông qua các bản nâng cấp lặp đi lặp lại. Để đào tạo sau, nó sử dụng các phương pháp dựa trên đồ thị như WebSailor-V2 để mô phỏng các thách thức "siêu nhân", chẳng hạn như các câu hỏi cấp độ Tiến sĩ được mô hình hóa thông qua lý thuyết tập hợp. Kết quả là, tập dữ liệu bao gồm hàng triệu tương tác có độ chính xác cao, đảm bảo mô hình tổng quát hóa trên các miền. Đáng chú ý, quá trình tự động hóa này mở rộng tuyến tính với tính toán, cho phép cập nhật liên tục mà không cần quản lý thủ công.
Hơn nữa, Tongyi DeepResearch kết hợp dữ liệu đa kiểu để tăng cường tính mạnh mẽ. Các bản ghi tổng hợp hành động ghi lại các mẫu sử dụng công cụ, trong khi các cặp QA đa giai đoạn tinh chỉnh kỹ năng lập kế hoạch. Trong thực tế, điều này tạo ra các tác nhân thích ứng với môi trường web nhiễu, lọc các đoạn không liên quan một cách hiệu quả. Đối với các nhà phát triển, kho lưu trữ cung cấp các tập lệnh để tái tạo quy trình này, cho phép tạo tập dữ liệu tùy chỉnh.
Bằng cách ưu tiên chất lượng hơn số lượng, chiến lược tổng hợp giải quyết các cạm bẫy phổ biến trong đào tạo tác nhân, như sự thay đổi phân phối. Do đó, các mô hình được đào tạo theo cách này thể hiện sự phù hợp vượt trội với các tác vụ trong thế giới thực, như đã thấy trong sự thống trị điểm chuẩn của nó.
Quy trình đào tạo từ đầu đến cuối: Từ CPT đến tối ưu hóa RL
Quá trình đào tạo của Tongyi DeepResearch diễn ra trong một quy trình liền mạch: CPT tác nhân, Tinh chỉnh có giám sát (SFT) và Học tăng cường (RL). Đầu tiên, CPT cho mô hình cơ sở tiếp xúc với dữ liệu tác nhân khổng lồ, truyền vào đó các ưu tiên điều hướng web và tín hiệu mới mẻ. Giai đoạn này kích hoạt các khả năng tiềm ẩn, chẳng hạn như lập kế hoạch ngầm, thông qua mô hình ngôn ngữ che mặt trên các quỹ đạo.

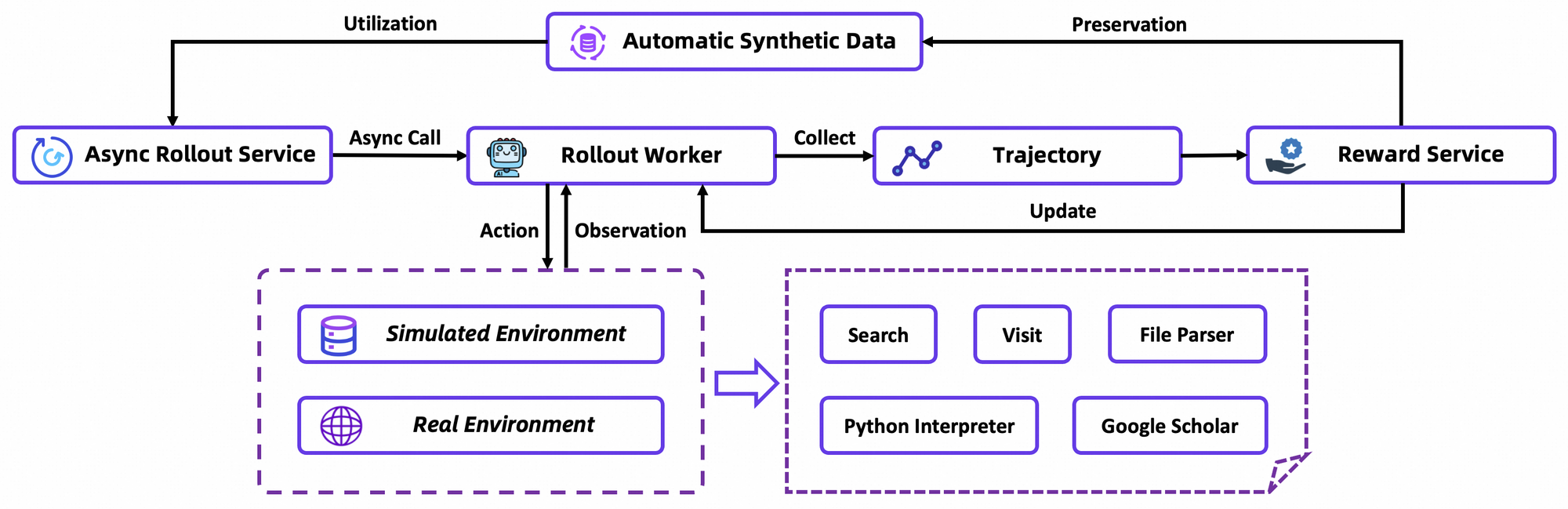
Sau CPT, SFT điều chỉnh mô hình theo các định dạng hướng dẫn, sử dụng các lần chạy mô phỏng để dạy cách hình thành hành động chính xác. Tại đây, mô hình học cách tạo ra các chu kỳ ReAct mạch lạc, giảm thiểu lỗi trong phân tích quan sát. Chuyển đổi một cách mượt mà, giai đoạn RL sử dụng Group Relative Policy Optimization (GRPO), một thuật toán theo chính sách tùy chỉnh.

GRPO tính toán các gradient chính sách cấp token với ước tính lợi thế "bỏ một" (leave-one-out), giảm phương sai trong các cài đặt không ổn định. Nó cũng lọc các mẫu tiêu cực một cách thận trọng, ổn định các bản cập nhật trong trình mô phỏng tùy chỉnh — một cơ sở dữ liệu Wikipedia ngoại tuyến được ghép nối với hộp cát công cụ. Các lần chạy không đồng bộ thông qua khung rLLM tăng tốc hội tụ, đạt SOTA với tính toán khiêm tốn.
Chi tiết hơn, môi trường RL mô phỏng các tương tác trình duyệt một cách trung thực, thưởng cho sự thành công nhiều bước hơn là các hành động đơn lẻ. Điều này thúc đẩy lập kế hoạch dài hạn, nơi các tác nhân lặp lại trên các lỗi một phần. Về mặt kỹ thuật, hàm mất mát kết hợp phân kỳ KL để bảo thủ, ngăn chặn sự sụp đổ chế độ. Các nhà phát triển tái tạo điều này thông qua các tập lệnh đánh giá của kho lưu trữ, đánh giá các chính sách tùy chỉnh.
Nhìn chung, quy trình này đánh dấu một bước đột phá: nó kết nối việc đào tạo trước với triển khai mà không có sự cô lập, tạo ra các tác nhân phát triển thông qua thử và sai.
Hiệu suất điểm chuẩn: Tongyi DeepResearch vượt trội như thế nào
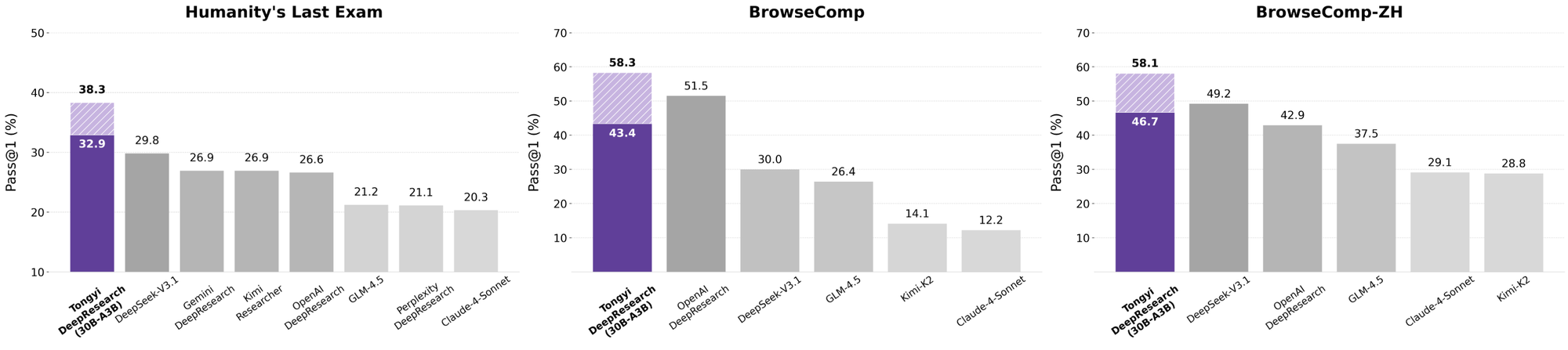
Tongyi DeepResearch tỏa sáng trong các điểm chuẩn tác nhân nghiêm ngặt, xác thực thiết kế của nó. Trên Humanity's Last Exam (HLE), một bài kiểm tra suy luận học thuật, nó đạt 32,9 ở chế độ ReAct — vượt qua OpenAI o3 ở mức 24,9. Khoảng cách này mở rộng ở chế độ Heavy lên 38,3, làm nổi bật hiệu quả của IterResearch.
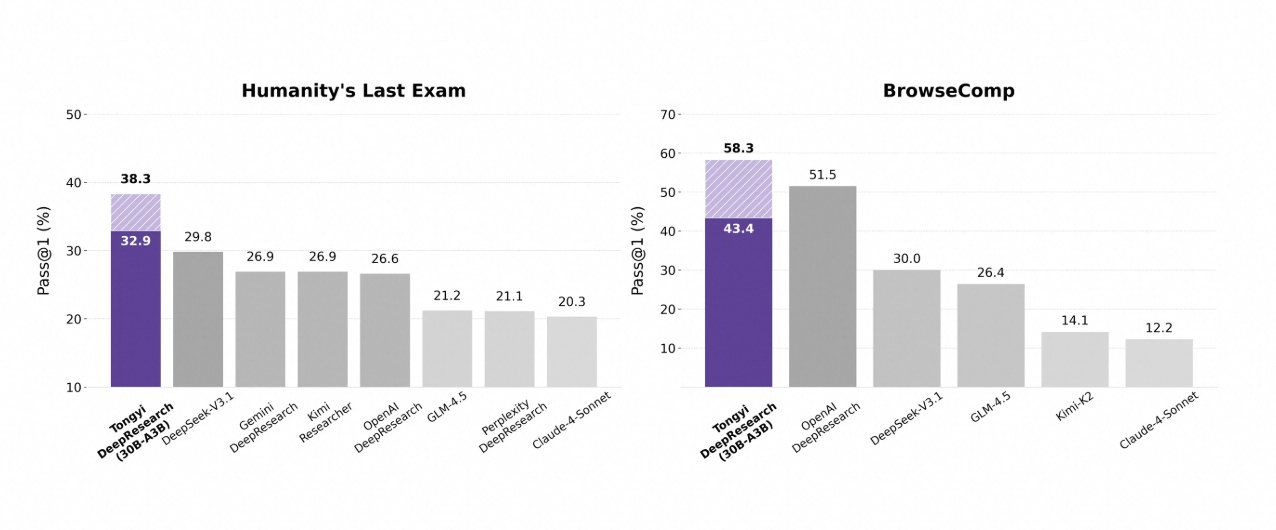
Tương tự, BrowseComp đánh giá việc tìm kiếm thông tin phức tạp; Tongyi đạt 43,4 (EN) và 46,7 (ZH), nhỉnh hơn o3 với 49,7 và 58,1 về hiệu quả. Điểm chuẩn xbench-DeepSearch, lấy người dùng làm trung tâm cho các truy vấn sâu, Tongyi đạt 75,0 so với 67,0 của o3, nhấn mạnh khả năng tổng hợp truy xuất vượt trội.
Các chỉ số khác củng cố điều này: FRAMES ở mức 90,6 (so với 84,0 của o3), GAIA ở mức 70,9 và SimpleQA ở mức 95,0. Một biểu đồ so sánh trực quan hóa những điều này, với các cột của Tongyi DeepResearch cao hơn Gemini, Claude và các mô hình khác trên HLE, BrowseComp, xbench, FRAMES, v.v. Các cột màu xanh lam biểu thị sự dẫn đầu của Tongyi, các đường cơ sở màu xám cho thấy sự thiếu hụt của các đối thủ cạnh tranh.
Những kết quả này bắt nguồn từ các tối ưu hóa có mục tiêu, như định tuyến chuyên gia chọn lọc cho các tác vụ tìm kiếm. Do đó, Tongyi DeepResearch không chỉ cạnh tranh mà còn dẫn đầu trong các tác nhân mã nguồn mở.
So sánh Tongyi DeepResearch với các nhà lãnh đạo ngành
Khi các nhà phát triển đánh giá các tác nhân AI, các so sánh sẽ tiết lộ giá trị thực. Tongyi DeepResearch, ở mức 30B-A3B, vượt trội hơn OpenAI o3 trong HLE (32,9 so với 24,9) và xbench (75,0 so với 67,0), mặc dù o3 có quy mô lớn hơn. So với Gemini của Google, nó đạt 35,2 trên BrowseComp-ZH, dẫn trước 10 điểm.
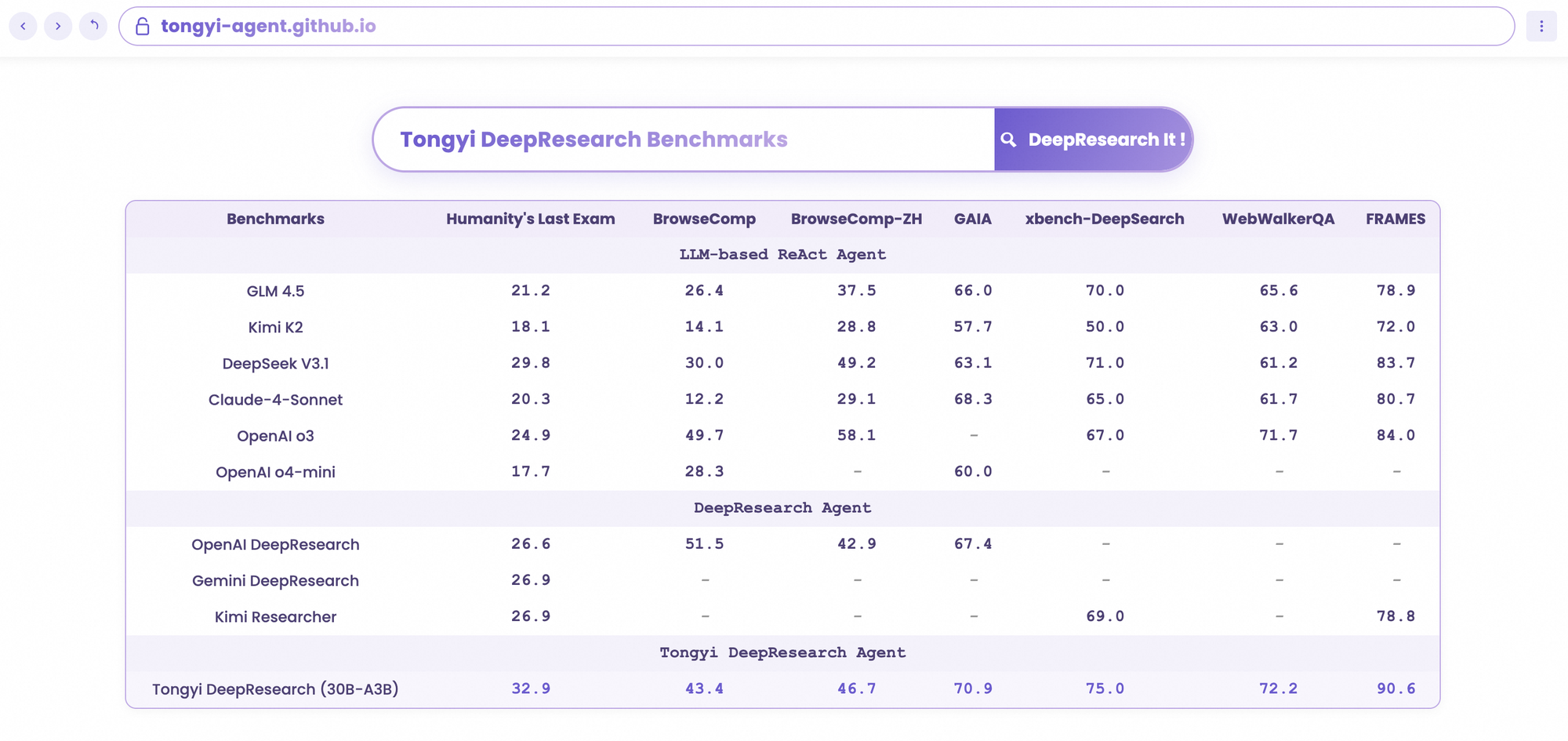
Các mô hình độc quyền như Claude 3.5 Sonnet tụt hậu trong việc sử dụng công cụ; 90,6 của Tongyi trên FRAMES làm lu mờ 84,3 của Sonnet. Các đối thủ mã nguồn mở, chẳng hạn như các biến thể Llama, tụt hậu xa hơn — ví dụ, 21,1 trên HLE. Tính thưa thớt MoE của Tongyi cho phép sự ngang bằng này, tiêu thụ ít tính toán suy luận hơn.
Hơn nữa, khả năng tiếp cận làm thay đổi cán cân: trong khi o3 yêu cầu tín dụng API, Tongyi chạy cục bộ thông qua Hugging Face. Đối với các quy trình làm việc nặng về API, hãy ghép nối nó với Apidog để mô phỏng các điểm cuối, mô phỏng các lệnh gọi công cụ một cách hiệu quả.
Về bản chất, Tongyi DeepResearch dân chủ hóa hiệu suất ưu tú, thách thức các hệ sinh thái đóng.
Ứng dụng trong thế giới thực: Tongyi DeepResearch trong hành động
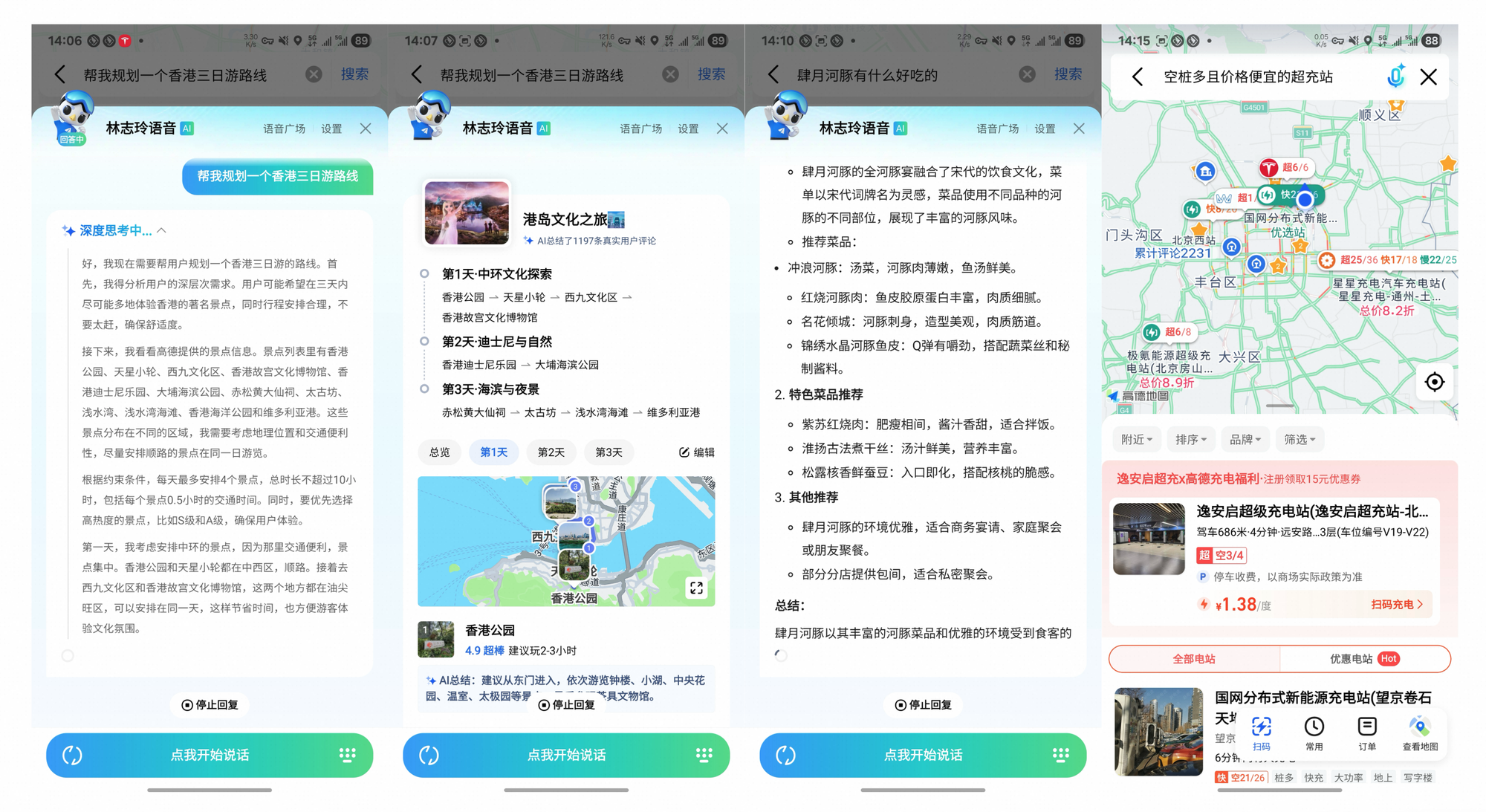
Tongyi DeepResearch vượt qua các điểm chuẩn, tạo ra tác động hữu hình. Trong Gaode Mate, ứng dụng điều hướng của Alibaba, nó lập kế hoạch các chuyến đi phức tạp — truy vấn các chuyến bay, khách sạn và sự kiện song song thông qua chế độ Heavy. Người dùng nhận được các hành trình tổng hợp với trích dẫn, giảm thời gian lập kế hoạch 70%.
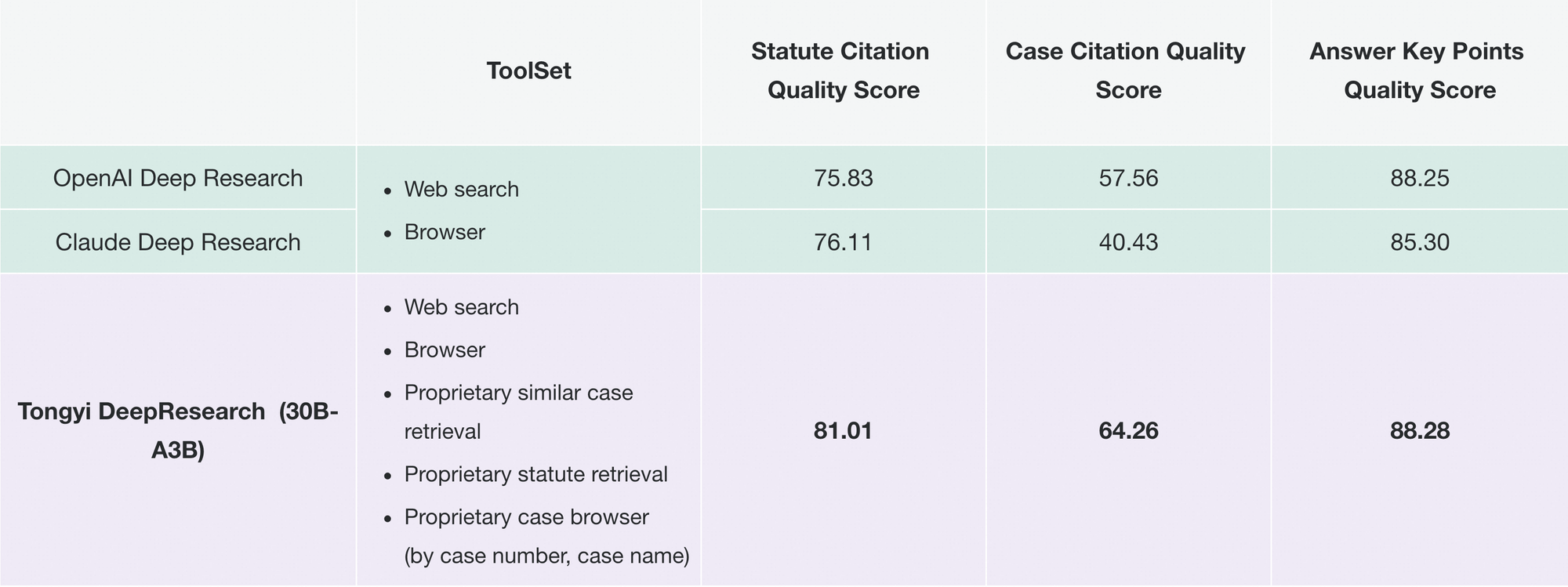
Tương tự, Tongyi FaRui cách mạng hóa nghiên cứu pháp lý. Tác nhân phân tích các đạo luật, đối chiếu các án lệ và tạo ra các bản tóm tắt với các liên kết có thể kiểm chứng. Các chuyên gia xác minh kết quả một cách nhanh chóng, giảm thiểu lỗi trong các lĩnh vực có rủi ro cao.
Ngoài ra, các doanh nghiệp còn điều chỉnh nó cho mục đích tình báo thị trường: thu thập dữ liệu đối thủ cạnh tranh, tổng hợp xu hướng. Tính mô-đun của kho lưu trữ hỗ trợ các phần mở rộng như vậy — thêm các công cụ tùy chỉnh thông qua cấu hình JSON.
Khi việc áp dụng ngày càng tăng, Tongyi DeepResearch tích hợp vào các hệ sinh thái như LangChain, khuếch đại các bầy tác nhân. Đối với các nhà phát triển API, Apidog bổ sung điều này bằng cách xác thực các tích hợp trước khi triển khai.
Những trường hợp này chứng minh khả năng mở rộng: từ các ứng dụng tiêu dùng đến các công cụ B2B, mô hình mang lại khả năng tự chủ đáng tin cậy.
Bắt đầu với Tongyi DeepResearch: Hướng dẫn dành cho nhà phát triển
Triển khai Tongyi DeepResearch dễ dàng với kho lưu trữ GitHub của nó. Bắt đầu bằng cách tạo môi trường Conda: conda create -n deepresearch python=3.10. Kích hoạt và cài đặt: pip install -r requirements.txt.
Chuẩn bị dữ liệu trong eval_data/ dưới dạng JSONL, với các khóa question và answer. Đối với các tệp, hãy thêm tên vào các câu hỏi và lưu trữ trong file_corpus/. Chỉnh sửa run_react_infer.sh cho đường dẫn mô hình (ví dụ: URL Hugging Face) và khóa API cho các công cụ.
Chạy: bash run_react_infer.sh. Kết quả đầu ra sẽ nằm trong các đường dẫn được chỉ định, sẵn sàng để phân tích.
Đối với chế độ Heavy, cấu hình các tham số IterResearch trong mã — đặt số lượng tác nhân và số vòng. Đánh giá điểm chuẩn thông qua các tập lệnh evaluation/, so sánh với các đường cơ sở.
Khắc phục sự cố bằng nhật ký; các vấn đề phổ biến như không khớp trình mã hóa được giải quyết thông qua kiểm tra tensor BF16. Để nâng cao, hãy tải Apidog miễn phí để mô phỏng API, kiểm thử các điểm cuối công cụ mà không cần gọi trực tiếp.
Thiết lập này trang bị cho bạn để tạo nguyên mẫu tác nhân một cách nhanh chóng.
Hướng đi tương lai: Mở rộng Tongyi DeepResearch hơn nữa
Trong tương lai, Tongyi Lab đặt mục tiêu mở rộng ngữ cảnh vượt quá 128K, cho phép các chân trời cực dài như phân tích dài bằng sách. Họ có kế hoạch xác thực trên các cơ sở MoE lớn hơn, thăm dò giới hạn khả năng mở rộng.
Các cải tiến RL bao gồm các lần chạy một phần để tăng hiệu quả và các phương pháp ngoài chính sách để giảm thiểu sự thay đổi. Các đóng góp của cộng đồng có thể tích hợp các công cụ thị giác hoặc đa ngôn ngữ, mở rộng phạm vi.
Khi mã nguồn mở phát triển, Tongyi DeepResearch sẽ là nền tảng cho những tiến bộ hợp tác, thúc đẩy các mục tiêu AGI.
Kết luận: Chào đón kỷ nguyên Tongyi DeepResearch
Tongyi DeepResearch biến đổi AI tác nhân, kết hợp hiệu quả, tính cởi mở và năng lực. Các điểm chuẩn, kiến trúc và ứng dụng của nó định vị nó là một nhà lãnh đạo, vượt trội hơn các đối thủ như các sản phẩm của OpenAI. Các nhà phát triển, hãy khai thác sức mạnh này — tải xuống mô hình, thử nghiệm và tích hợp với Apidog để có các API liền mạch.
Trong một lĩnh vực đang chạy đua hướng tới tự chủ, Tongyi DeepResearch thúc đẩy tiến bộ. Hãy bắt đầu xây dựng ngay hôm nay; những hiểu biết sâu sắc đang chờ đợi.
nút