
Trong thế giới trí tuệ nhân tạo đang phát triển nhanh chóng, khả năng truyền phát phản hồi từ các Mô hình Ngôn ngữ Lớn (LLMs) theo thời gian thực đã trở thành điều cần thiết để nâng cao tương tác người dùng và cải thiện hiệu suất ứng dụng tổng thể. Một trong những cách tốt nhất để đạt được điều này là thông qua Sự kiện do máy chủ gửi (SSE), một công nghệ mạnh mẽ được xây dựng trên giao thức HTTP cung cấp một kênh giao tiếp một chiều giữa máy chủ và khách hàng. Trong bài viết này, chúng ta sẽ tìm hiểu cách mà SSE hoạt động, cách nó có thể được sử dụng để truyền phát phản hồi LLM, và cách các công cụ như Apidog có thể đơn giản hóa việc gỡ lỗi và cải thiện hiệu quả phát triển.
Sự kiện do máy chủ gửi (SSE) là gì?
Sự kiện do máy chủ gửi là một công nghệ giao tiếp nhẹ, theo thời gian thực dựa trên giao thức HTTP. Với SSE, máy chủ thiết lập một kết nối liên tục, một chiều đến khách hàng. Máy chủ sẽ gửi các cập nhật đến khách hàng mà không yêu cầu khách hàng phải yêu cầu dữ liệu mới nhiều lần. Điều này làm cho SSE trở nên lý tưởng cho việc truyền phát nội dung động như cập nhật theo thời gian thực, thông báo trực tiếp, và trong trường hợp của các mô hình AI, phản hồi liên tục từ các LLM.
Sự đẹp đẽ của SSE nằm ở sự đơn giản và chi phí thấp. Khác với WebSockets, cho phép giao tiếp hai chiều, SSE được thiết kế cho các kịch bản mà máy chủ cần gửi dữ liệu liên tục đến khách hàng. Điều này đặc biệt hữu ích khi truyền phát nội dung được tạo ra bởi AI theo thời gian thực, vì khách hàng có thể thấy quá trình suy nghĩ của mô hình khi nó tạo ra từng phần của phản hồi.
Cách mà SSE hoạt động trong việc truyền phát LLM
Khi sử dụng LLMs, đặc biệt là với các mô hình phức tạp như DeepSeek R1, các phản hồi thường đến theo từng mảnh vụn. Với SSE, mỗi mảnh đó được gửi dưới dạng một "sự kiện" riêng biệt trong luồng. Điều này cho phép các nhà phát triển và người dùng cuối chứng kiến toàn bộ quá trình trong thời gian thực. Khi máy chủ gửi mỗi sự kiện, khách hàng được cập nhật ngay lập tức, đảm bảo rằng người dùng nhận được thông tin mới nhất có sẵn.
Lợi ích của việc sử dụng SSE cho các phản hồi mô hình AI
- Giao dữ liệu theo thời gian thực: SSE cho phép khách hàng nhận các cập nhật ngay khi chúng được tạo ra, không có sự chậm trễ.
- Giao tiếp hiệu quả: Máy chủ chỉ gửi dữ liệu khi có sự kiện mới xảy ra, giảm thiểu các yêu cầu không cần thiết và cải thiện hiệu quả của hệ thống.
- Thực hiện đơn giản phía khách hàng: Với SSE, các khách hàng không cần logic phức tạp để xử lý các cập nhật dữ liệu liên tục, vì chúng được tự động nhận và hiển thị.
Cài đặt gỡ lỗi SSE với Apidog
Để bắt đầu gỡ lỗi SSE bằng Apidog, hãy đảm bảo rằng bạn đang sử dụng phiên bản 2.6.49 trở lên. Apidog cung cấp một nền tảng thân thiện với người dùng để làm việc với các API, giúp dễ dàng xử lý các kết nối SSE và gỡ lỗi các luồng dữ liệu thời gian thực từ các LLM như DeepSeek R1.
Bước 1: Tạo một điểm cuối mới trong Apidog
Bắt đầu bằng cách tạo một dự án HTTP mới trong Apidog. Điều này cho phép bạn thiết lập một không gian làm việc để kiểm tra và gỡ lỗi các yêu cầu API của bạn. Khi dự án của bạn được thiết lập, hãy thêm một điểm cuối mới bằng cách nhập URL của mô hình AI. Đây là nơi luồng SSE sẽ xuất phát. Trong ví dụ này, chúng tôi sẽ sử dụng DeepSeek làm mô hình AI. (MẸO CHUYÊN NGHIỆP: Bạn có thể nhân bản dự án API DeepSeek có sẵn trong API Hub của Apidog).
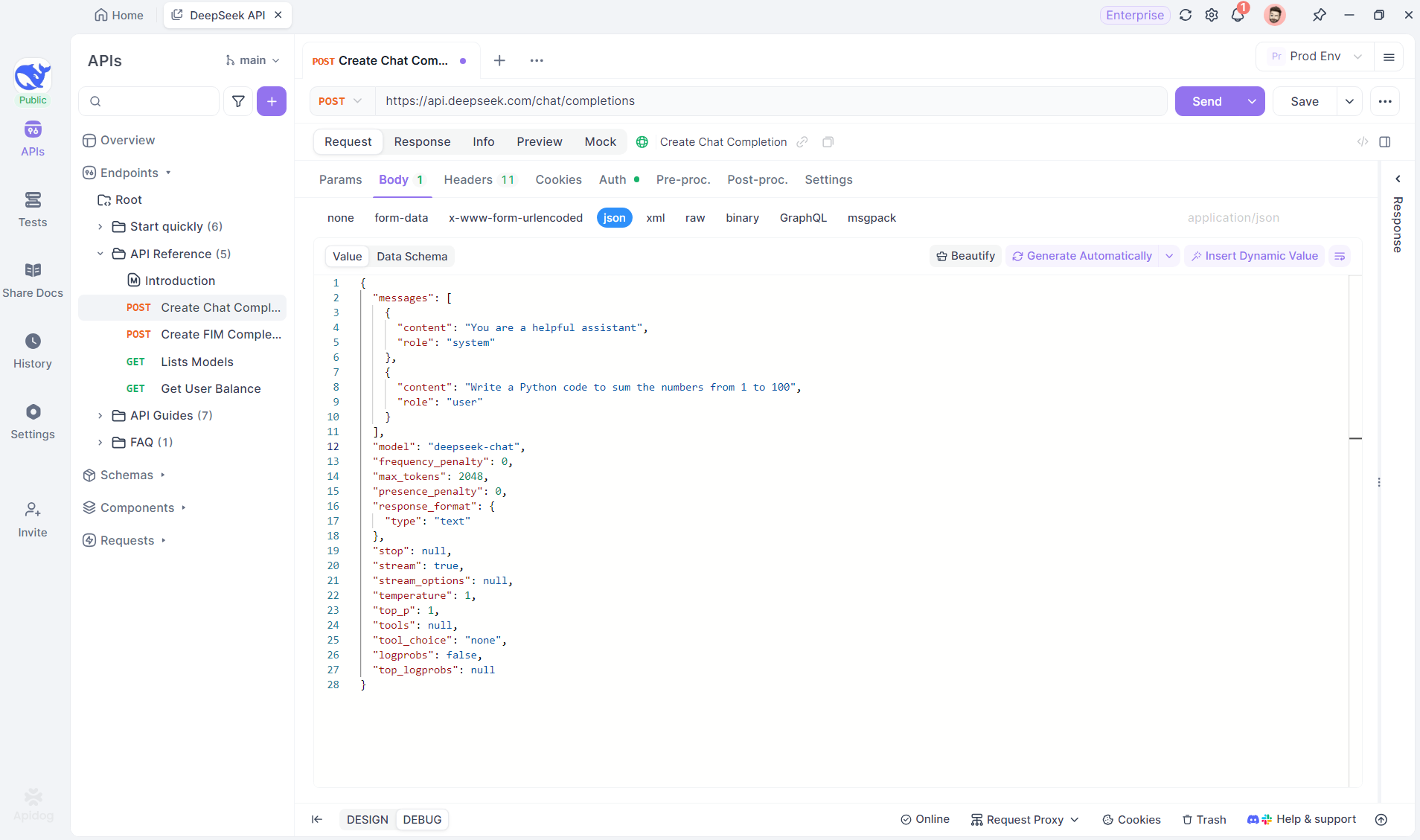
Bước 2: Gửi yêu cầu
Sau khi thêm điểm cuối, hãy gửi yêu cầu đến máy chủ bằng cách nhấn Gửi ở góc trên bên phải. Nếu tiêu đề phản hồi của máy chủ bao gồm Content-Type: text/event-stream, Apidog sẽ tự động nhận ra rằng dữ liệu đang được truyền phát qua SSE. Hệ thống thông minh của Apidog sẽ phân tích phản hồi này và hiển thị nó trong bảng phản hồi, cho phép bạn xem luồng thời gian thực khi nó được tạo ra.
Bước 3: Xem các phản hồi theo thời gian thực
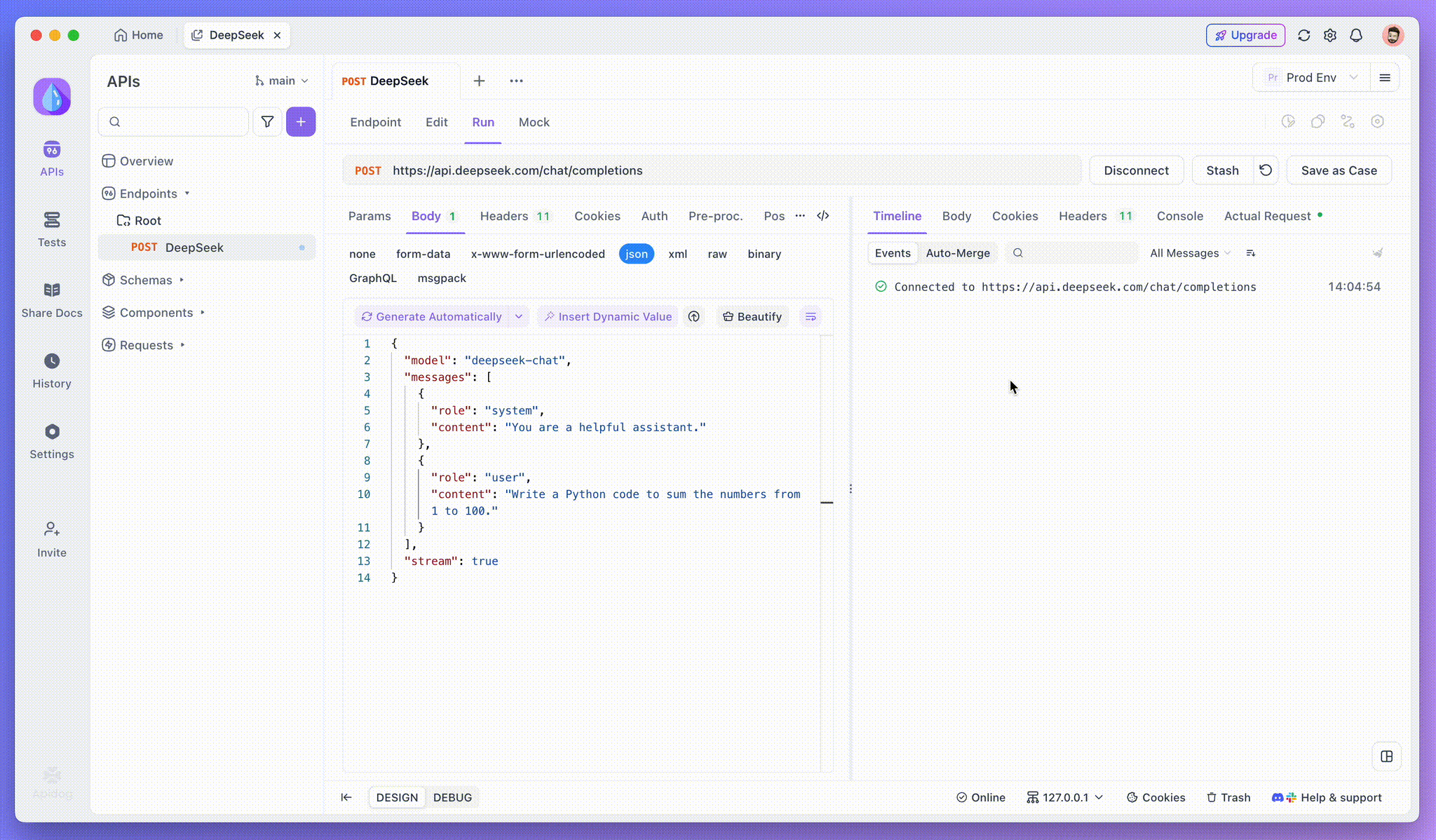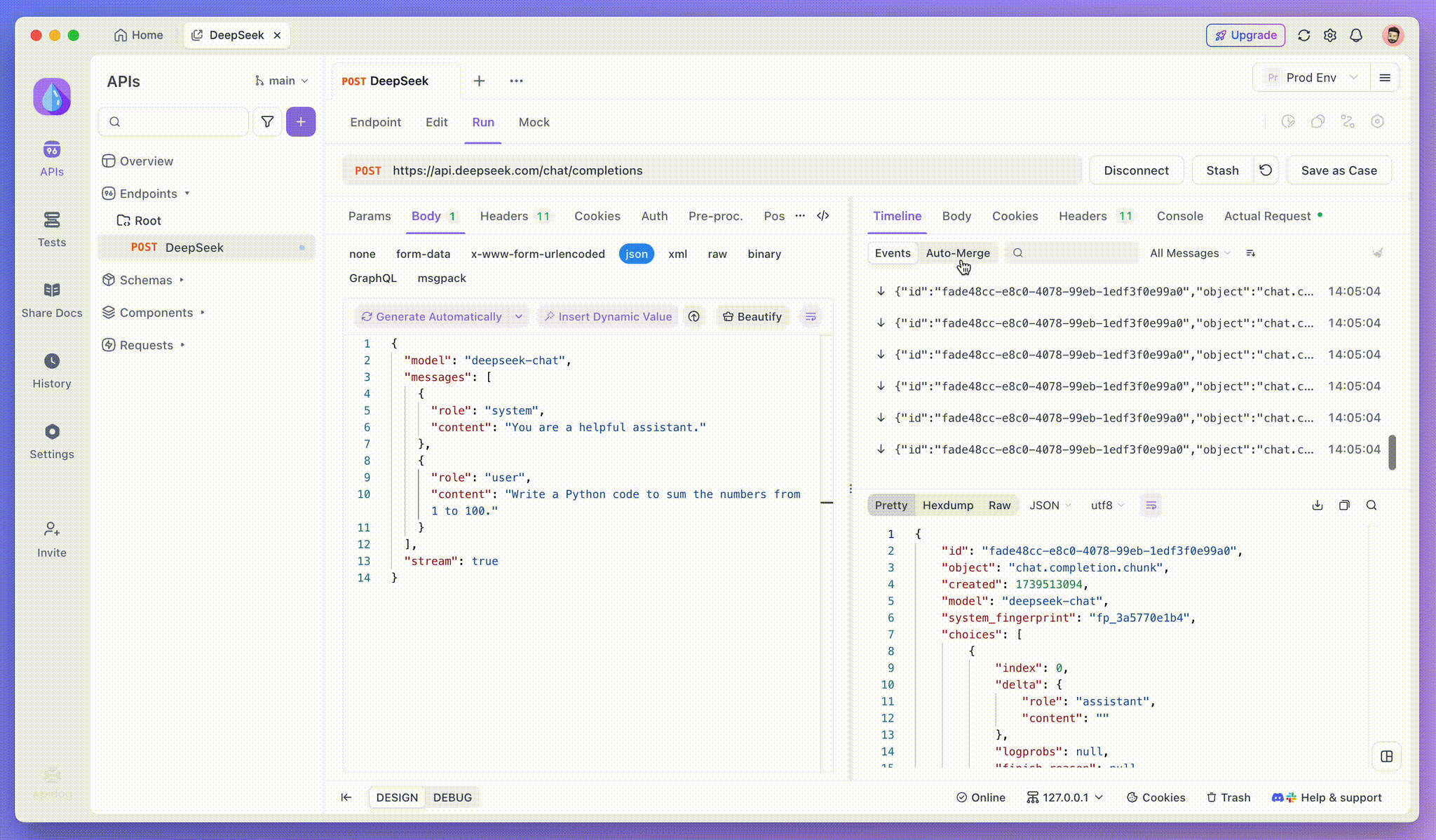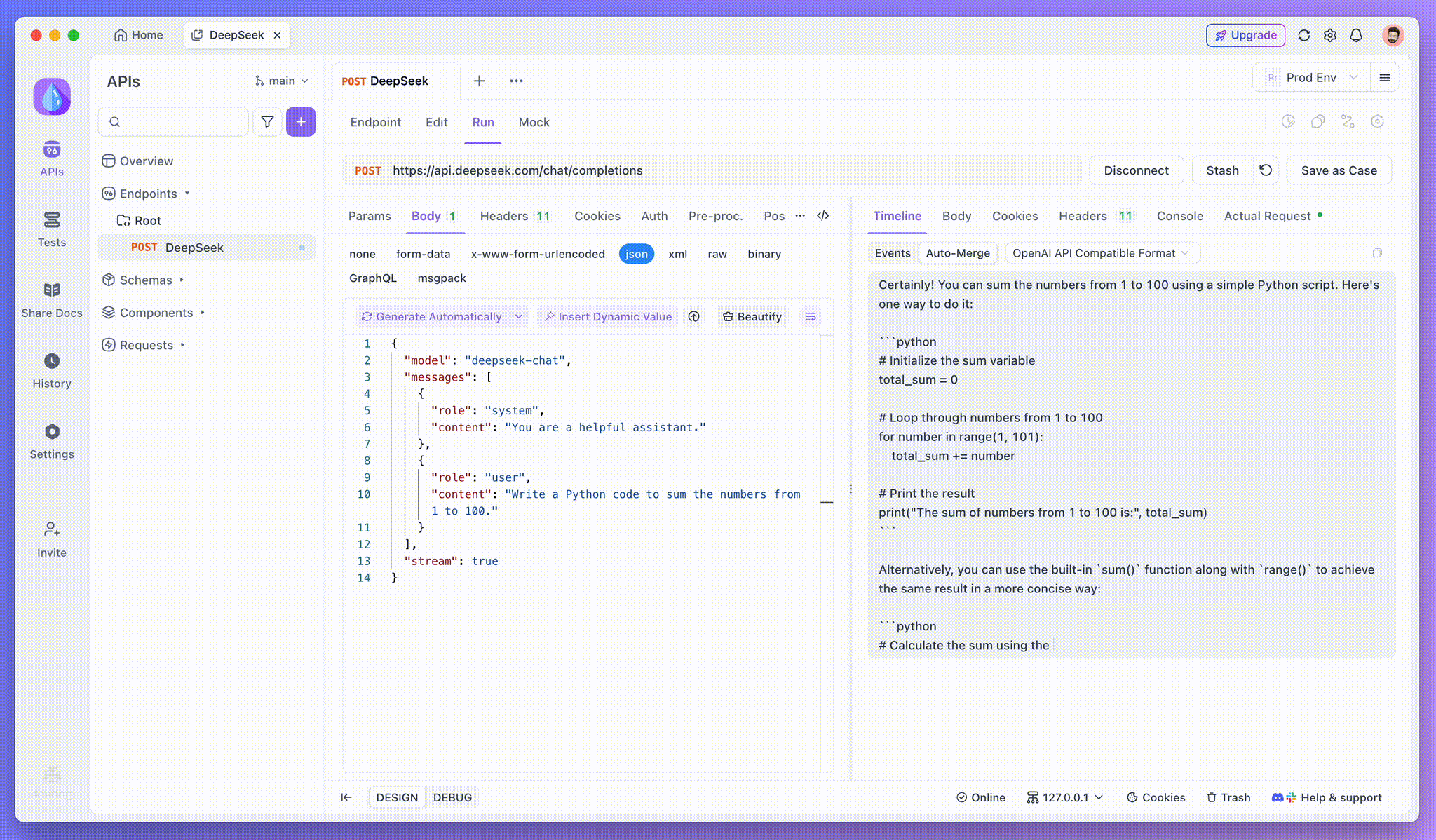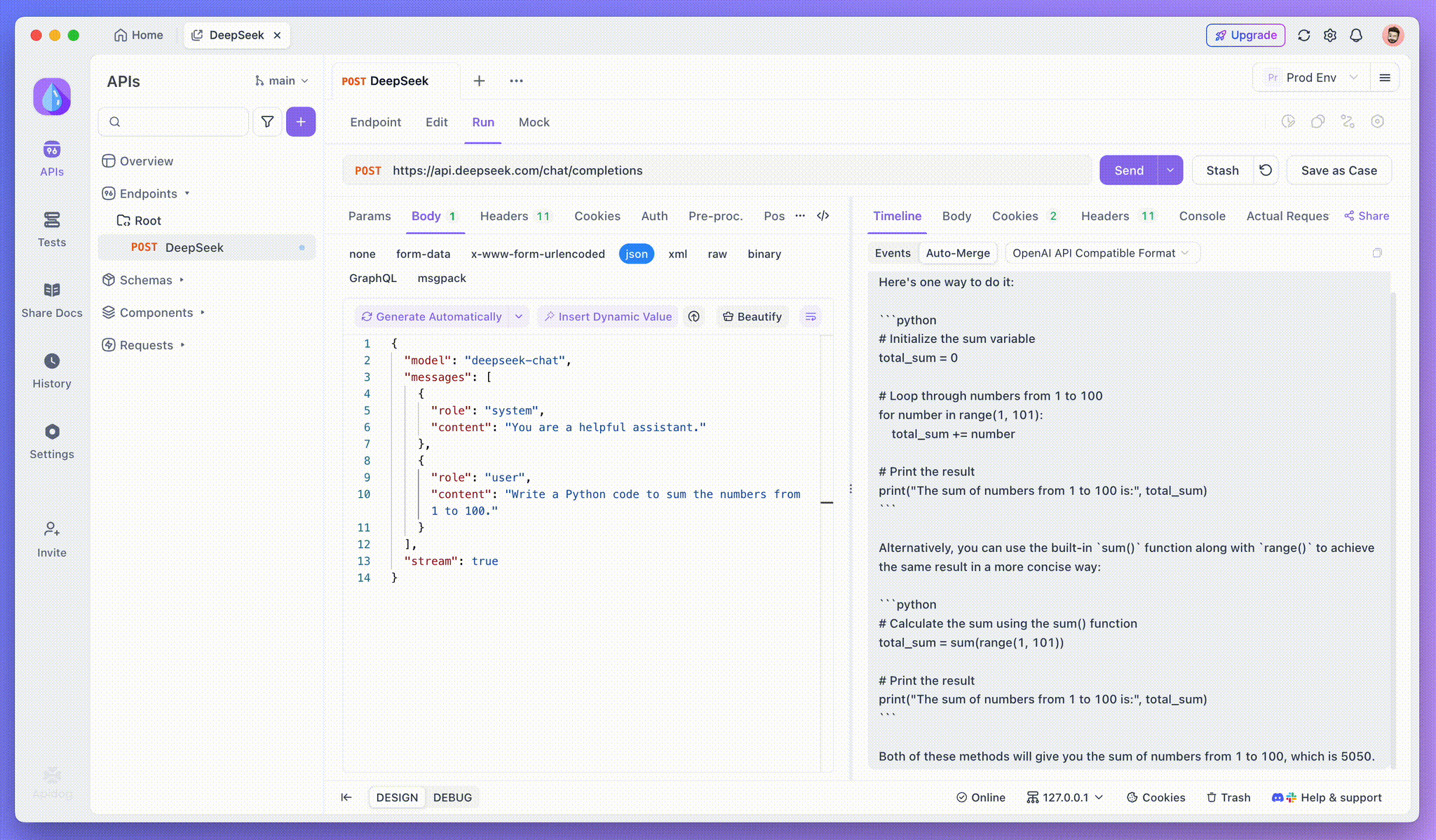
Chế độ Nhìn dọc của Apidog là nơi phép màu xảy ra. Khi mô hình AI truyền phát các phản hồi của mình, chế độ Nhìn dọc sẽ cập nhật một cách động, hiển thị từng mảnh của phản hồi theo thời gian thực. Chế độ này cho phép bạn theo dõi sự phát triển của quá trình suy nghĩ của AI, mang lại cho bạn cái nhìn quý giá về cách mà nó tạo ra đầu ra cuối cùng.
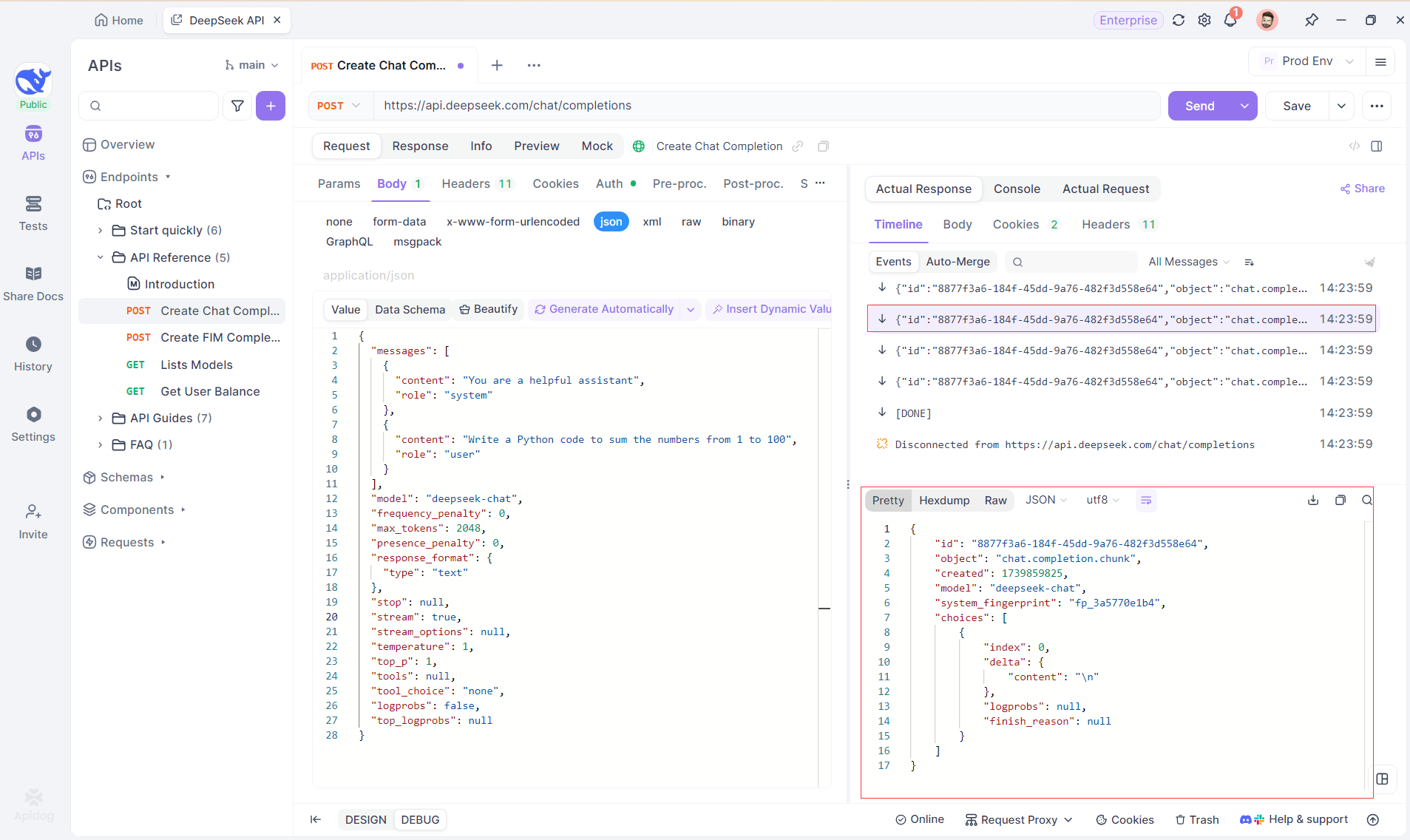
Bước 4: Xem phản hồi SSE trong một phản hồi hoàn chỉnh
Khi SSE cung cấp một cách mạnh mẽ để truyền phát dữ liệu, nó thường yêu cầu xử lý bổ sung để xử lý các phản hồi phân mảnh. Tính năng Auto-Merge của Apidog được thiết kế để giải quyết thách thức này. Khi truyền phát các phản hồi từ AI, dữ liệu thường đến trong nhiều mảnh, đặc biệt với các mô hình như OpenAI, Gemini hoặc Claude. Apidog tự động hợp nhất các mảnh này thành một phản hồi thống nhất, hoàn chỉnh.
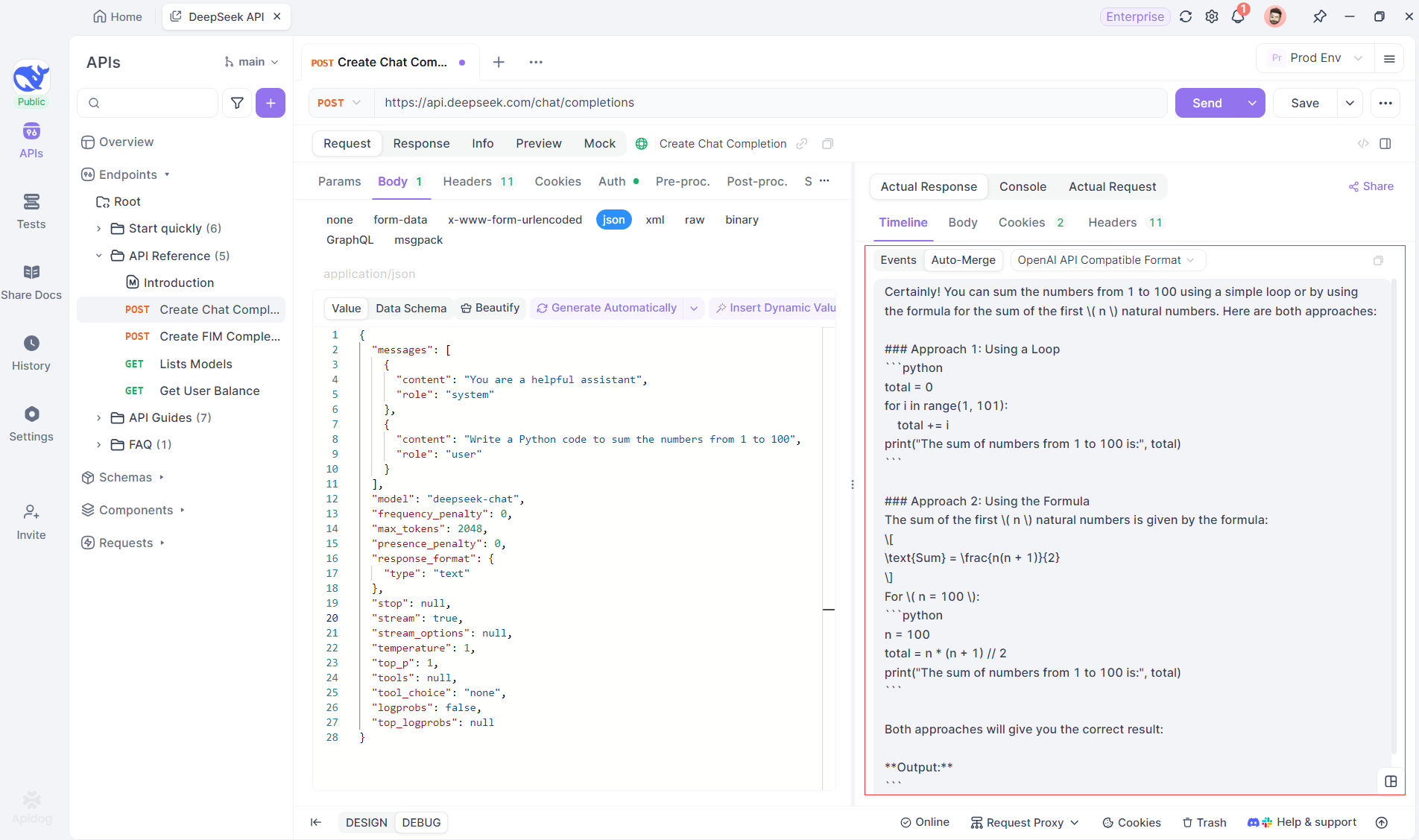
Tính năng này loại bỏ nhu cầu xử lý dữ liệu thủ công, cho phép các nhà phát triển tập trung vào việc phân tích đầu ra của AI thay vì phải xử lý các phức tạp của việc hợp nhất các thông điệp phân mảnh.
Hình dung quá trình suy nghĩ của các mô hình lý luận: Một trong những tính năng nổi bật khi làm việc với các mô hình lý luận như DeepSeek R1 là khả năng của Apidog để hiển thị quá trình suy nghĩ của mô hình trực tiếp trong chế độ Nhìn dọc.
Khi AI tạo ra các phản hồi, Apidog không chỉ hiển thị dữ liệu phản hồi mà còn cung cấp một biểu đồ hình ảnh về cách mà mô hình đã đạt được kết luận của nó. Điều này mang lại một cách trực quan hơn để gỡ lỗi và hiểu lý do đứng sau các phản hồi của AI.
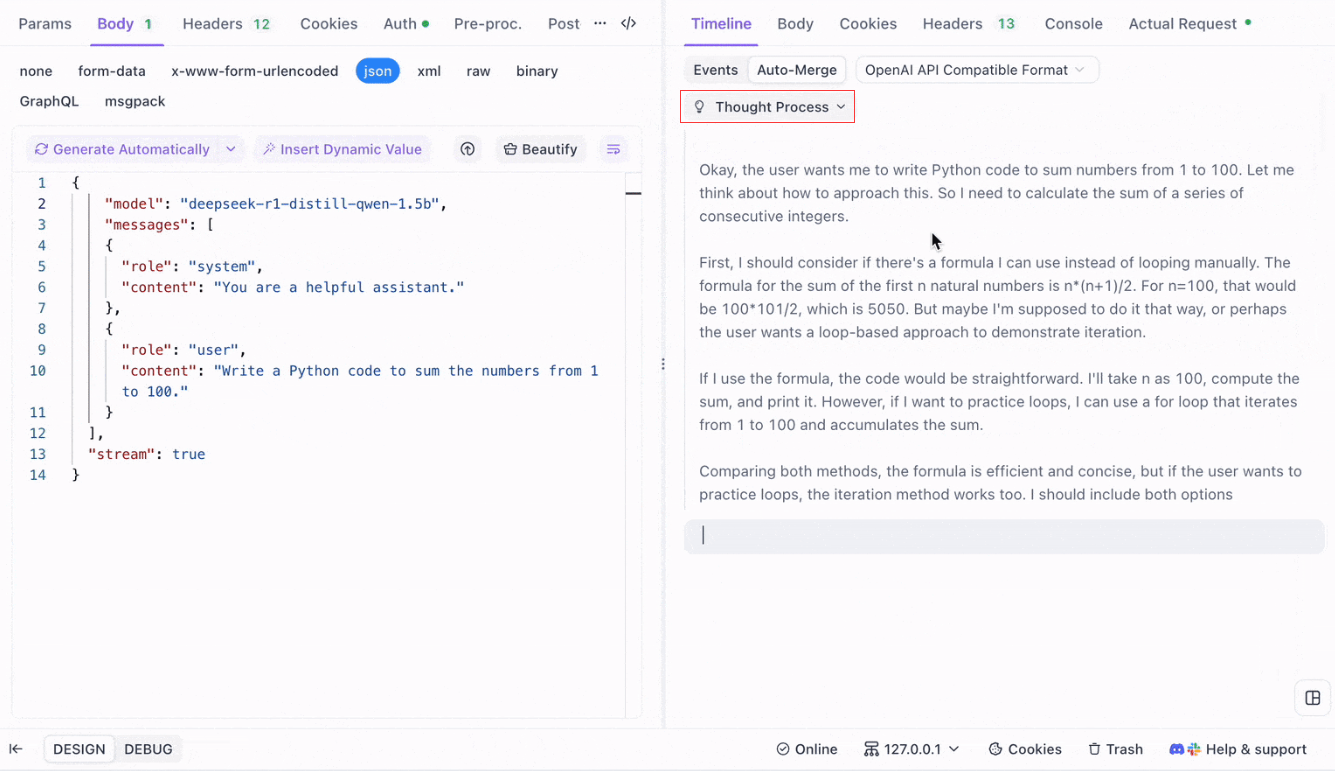
Định dạng được hỗ trợ cho việc tự động hợp nhất
Apidog có thể tự động nhận dạng và hợp nhất các phản hồi từ một số định dạng mô hình AI phổ biến:
- Định dạng API OpenAI
- Định dạng API Gemini
- Định dạng API Claude
Khi phản hồi từ mô hình AI khớp với bất kỳ định dạng nào trong số này, Apidog sẽ hợp nhất các mảnh thành một phản hồi hoàn chỉnh. Điều này làm cho việc gỡ lỗi các phản hồi SSE hiệu quả hơn, vì nhà phát triển không cần phải tự tay ghép các mảnh lại với nhau.
Tại sao sử dụng tự động hợp nhất cho việc gỡ lỗi LLM?
- Hiệu quả về thời gian: Các nhà phát triển có thể tránh được công việc tẻ nhạt của việc hợp nhất các mảnh phản hồi bằng tay.
- Cải thiện gỡ lỗi: Một phản hồi thống nhất và hoàn chỉnh cho phép phân tích rõ ràng hơn về hành vi của AI.
- Cái nhìn sâu sắc hơn: Hình dung quá trình suy nghĩ của mô hình thêm một lớp hiểu biết, đặc biệt với các mô hình phức tạp như DeepSeek R1.
Tùy chỉnh quy tắc gỡ lỗi SSE trong Apidog
Trong một số trường hợp, tính năng Tự động hợp nhất tích hợp sẵn có thể không hoạt động như mong đợi, đặc biệt là khi xử lý các mô hình AI tùy chỉnh hoặc định dạng không tiêu chuẩn. Apidog cho phép bạn tùy chỉnh cách phản hồi được xử lý bằng cách sử dụng Quy tắc chiết xuất JSONPath hoặc Ngữ cảnh hậu xử lý.
Cấu hình quy tắc chiết xuất JSONPath
Nếu phản hồi SSE ở định dạng JSON nhưng không tuân thủ các quy tắc nhận dạng tích hợp sẵn cho các định dạng như OpenAI, Claude hoặc Gemini, bạn có thể cấu hình JSONPath để chiết xuất nội dung cần thiết.
Ví dụ, hãy xem phản hồi SSE thô sau:
data: {"choices":[{"index":0,"message":{"role":"assistant","content":"H"},"logprobs":null,"finish_reason":"stop"}]}
data: {"choices":[{"index":0,"message":{"role":"assistant","content":"i"},"logprobs":null,"finish_reason":"stop"}]}Để chiết xuất nội dung của trường message.content, bạn sẽ cấu hình JSONPath như sau: $.choices[0].message.content
Cấu hình này sẽ lấy nội dung: Hi
Bằng cách sử dụng JSONPath, bạn có thể tùy chỉnh cách mà Apidog xử lý các phản hồi, đảm bảo rằng bạn luôn chiết xuất được dữ liệu chính xác.
Sử dụng ngữ cảnh hậu xử lý cho SSE không phải JSON
Đối với các phản hồi không phải JSON, Apidog cung cấp khả năng sử dụng Ngữ cảnh hậu xử lý để thao tác và chiết xuất dữ liệu từ luồng SSE. Điều này cho phép bạn viết các tập lệnh tùy chỉnh để xử lý các định dạng dữ liệu cụ thể không tuân theo cấu trúc JSON truyền thống.
Nếu bạn đang làm việc với một định dạng mô hình không được hỗ trợ, bạn cũng có thể liên hệ với hỗ trợ kỹ thuật của Apidog để yêu cầu thêm định dạng vào hỗ trợ tích hợp.
Những thực tiễn tốt nhất cho việc truyền phát phản hồi LLM với SSE
Khi truyền phát các phản hồi LLM bằng SSE, có một số thực tiễn tốt nhất mà bạn cần lưu ý để đảm bảo việc gỡ lỗi diễn ra mượt mà và hiệu quả:
- Đối phó với sự phân mảnh một cách duyên dáng: Luôn dự đoán rằng các phản hồi của mô hình AI có thể đến trong nhiều mảnh, và sử dụng tính năng
Tự động hợp nhấtđể đơn giản hóa quy trình này. - Kiểm tra với các mô hình AI khác nhau: Sử dụng các mô hình như OpenAI, Gemini và DeepSeek R1 để khám phá hành vi của các định dạng khác nhau và đảm bảo rằng cài đặt của bạn có thể xử lý nhiều loại phản hồi.
- Sử dụng chế độ Nhìn dọc để gỡ lỗi: Tận dụng chế độ Nhìn dọc của Apidog để có được phân tích từng bước theo thời gian thực về cách các phản hồi phát triển, đặc biệt là đối với các mô hình AI phức tạp.
- Tùy chỉnh cho các định dạng không tiêu chuẩn: Nếu cần thiết, hãy sử dụng JSONPath hoặc Ngữ cảnh hậu xử lý để xử lý các định dạng SSE không tiêu chuẩn hoặc để tinh chỉnh quy trình chiết xuất dữ liệu.
Kết luận: Nâng cao truyền phát LLM với SSE
Các sự kiện do máy chủ gửi cung cấp một cơ chế mạnh mẽ cho việc truyền phát các phản hồi theo thời gian thực từ các mô hình AI, đặc biệt là khi xử lý các LLM lớn và phức tạp. Bằng cách sử dụng các công cụ gỡ lỗi SSE của Apidog, bao gồm tính năng Tự động hợp nhất và hình dung được cải thiện, các nhà phát triển có thể đơn giản hóa quy trình xử lý các phản hồi phân mảnh và có được cái nhìn sâu sắc hơn vào hành vi của mô hình. Dù bạn đang gỡ lỗi các phản hồi từ các mô hình phổ biến như OpenAI hay làm việc với các giải pháp AI tùy chỉnh, Apidog đảm bảo rằng bạn có thể dễ dàng theo dõi, hợp nhất và phân tích dữ liệu SSE theo cách hiệu quả và sâu sắc.