
Cảnh quan của các mô hình ngôn ngữ lớn (LLMs) đang phát triển với tốc độ chóng mặt. Các mô hình đang trở nên mạnh mẽ hơn, có khả năng hơn và, quan trọng nhất, dễ tiếp cận hơn. Nhóm Qwen gần đây đã công bố Qwen3, thế hệ mới nhất của LLMs, với hiệu suất ấn tượng trên nhiều tiêu chuẩn khác nhau, bao gồm lập trình, toán học và lý luận tổng quát. Với các mô hình hàng đầu như Mixture-of-Experts (MoE) Qwen3-235B-A22B đối đầu với các gã khổng lồ đã được thiết lập và thậm chí các mô hình dày đặc nhỏ hơn như Qwen3-4B cạnh tranh với các mô hình 72B của thế hệ trước, Qwen3 đại diện cho một bước tiến quan trọng.
Một khía cạnh chính của việc phát hành này là việc mở trọng số của một số mô hình, bao gồm hai biến thể MoE (Qwen3-235B-A22B và Qwen3-30B-A3B) và sáu mô hình dày đặc từ 0.6B đến 32B tham số. Sự cởi mở này mời gọi các nhà phát triển, nghiên cứu viên và những người đam mê khám phá, sử dụng và xây dựng trên những công cụ mạnh mẽ này. Trong khi các API dựa trên đám mây mang lại sự tiện lợi, nhu cầu chạy các mô hình tinh vi này trên máy cục bộ đang gia tăng, xuất phát từ nhu cầu về riêng tư, kiểm soát chi phí, tùy biến và khả năng truy cập ngoại tuyến.
May mắn thay, hệ sinh thái công cụ cho việc thực thi LLM trên địa phương đã trưởng thành đáng kể. Hai nền tảng nổi bật đơn giản hóa quá trình này là Ollama và vLLM. Ollama cung cấp một cách cực kỳ thân thiện với người dùng để bắt đầu với nhiều mô hình khác nhau, trong khi vLLM cung cấp một giải pháp phục vụ hiệu suất cao được tối ưu hóa cho thông lượng và hiệu quả, đặc biệt cho các mô hình lớn hơn. Bài viết này sẽ hướng dẫn bạn hiểu về Qwen3 và thiết lập các mô hình mạnh mẽ này trên máy cục bộ của bạn bằng cả Ollama và vLLM.
Bạn có muốn một nền tảng tích hợp, All-in-One cho nhóm phát triển của bạn làm việc cùng nhau với năng suất tối đa?
Apidog đáp ứng tất cả các yêu cầu của bạn, và thay thế Postman với giá cả phải chăng hơn rất nhiều!
Qwen 3 là gì và các tiêu chuẩn
Qwen3 đại diện cho thế hệ thứ ba của các mô hình ngôn ngữ lớn (LLMs) được phát triển bởi nhóm Qwen, phát hành vào tháng 4 năm 2025. Phiên bản này đánh dấu một bước tiến đáng kể so với các phiên bản trước, tập trung vào khả năng lý luận nâng cao, hiệu suất thông qua các đổi mới về kiến trúc như Mixture-of-Experts (MoE), hỗ trợ đa ngôn ngữ rộng rãi và cải thiện hiệu suất trên một loạt các tiêu chuẩn. Việc phát hành bao gồm việc mở trọng số của một số mô hình theo giấy phép Apache 2.0, thúc đẩy khả năng tiếp cận cho nghiên cứu và phát triển.
Kiến trúc Mô hình Qwen 3 và Giải thích về các Biến thể
Gia đình Qwen3 bao gồm cả các mô hình dày đặc truyền thống và các kiến trúc MoE thưa, phục vụ cho các ngân sách tính toán và yêu cầu hiệu suất khác nhau.
Các Mô hình Dày đặc: Những mô hình này sử dụng tất cả các tham số của chúng trong quá trình suy diễn. Các chi tiết kiến trúc chính bao gồm:
| Mô hình | Số lớp | Heads Chú ý (Query / Key-Value) | Liên kết Từ Vựng | Độ dài Ngữ cảnh Tối đa |
|---|---|---|---|---|
| Qwen3-0.6B | 28 | 16 / 8 | Có | 32,768 tokens (32K) |
| Qwen3-1.7B | 28 | 16 / 8 | Có | 32,768 tokens (32K) |
| Qwen3-4B | 36 | 32 / 8 | Có | 32,768 tokens (32K) |
| Qwen3-8B | 36 | 32 / 8 | Không | 131,072 tokens (128K) |
| Qwen3-14B | 40 | 40 / 8 | Không | 131,072 tokens (128K) |
| Qwen3-32B | 64 | 64 / 8 | Không | 131,072 tokens (128K) |
Lưu ý: Chú ý nhóm Truy vấn (GQA) được sử dụng trong tất cả các mô hình, thể hiện qua số lượng khác nhau của các heads Truy vấn và Key-Value.
Các Mô hình Mixture-of-Experts (MoE): Những mô hình này tận dụng tính thưa bằng cách chỉ kích hoạt một tập hợp "chuyên gia" của các Mạng Feed-Forward (FFNs) cho mỗi token trong quá trình suy diễn. Điều này cho phép có tổng số tham số lớn trong khi duy trì chi phí tính toán gần với các mô hình dày đặc nhỏ hơn.
| Mô hình | Số lớp | Heads Chú ý (Query / Key-Value) | # Chuyên gia (Tổng / Kích hoạt) | Độ dài Ngữ cảnh Tối đa |
|---|---|---|---|---|
| Qwen3-30B-A3B | 48 | 32 / 4 | 128 / 8 | 131,072 tokens (128K) |
| Qwen3-235B-A22B | 94 | 64 / 4 | 128 / 8 | 131,072 tokens (128K) |
Lưu ý: Cả hai mô hình MoE đều sử dụng tổng cộng 128 chuyên gia nhưng chỉ kích hoạt 8 cho mỗi token, giảm tải tính toán đáng kể so với một mô hình dày đặc có kích thước tương đương.
Các Tính Năng Kỹ Thuật Chính của Qwen 3
Các Chế Độ Tư Duy Kết Hợp: Một đặc điểm nổi bật của Qwen3 là khả năng hoạt động trong hai chế độ khác nhau, có thể kiểm soát bởi người dùng:
- Chế Độ Tư Duy (Mặc định): Mô hình thực hiện lý luận nội bộ, từng bước (theo kiểu Chain-of-Thought) trước khi tạo ra phản hồi cuối cùng. Quá trình suy nghĩ ẩn này được bao bọc, thường được đánh dấu bởi các token đặc biệt (ví dụ: xuất ra nội dung
<think>...</think>trước khi đưa ra câu trả lời cuối cùng khi sử dụng các cấu hình framework cụ thể). Chế độ này tăng cường hiệu suất cho các nhiệm vụ phức tạp cần suy luận logic, lý luận toán học hoặc kế hoạch. Nó cho phép cải thiện hiệu suất có thể mở rộng tương ứng với ngân sách lý luận tính toán được phân bổ. - Chế Độ Không Tư Duy: Mô hình tạo ra một phản hồi trực tiếp mà không có giai đoạn lý luận nội bộ rõ ràng, tối ưu hóa cho tốc độ và giảm chi phí tính toán cho các truy vấn đơn giản hơn.
Các người dùng có thể chuyển đổi linh hoạt giữa các chế độ này, có thể theo từng lượt trong các cuộc hội thoại nhiều lượt bằng cách sử dụng các thẻ như/thinkvà/no_thinktrong các gợi ý của họ (theo quy định của framework), cho phép kiểm soát chi tiết về sự đánh đổi giữa độ trễ/chi phí và độ sâu lý luận.
Hỗ Trợ Đa Ngôn Ngữ Rộng Rãi: Các mô hình Qwen3 được huấn luyện trước trên một tập dữ liệu đa dạng cho phép hỗ trợ 119 ngôn ngữ và phương ngữ thuộc các gia đình ngôn ngữ lớn (Ấn-Âu, Hán-Tạng, Afro-Á, Áo-Đại Dương, Dravidian, Turk, v.v.), làm cho chúng phù hợp với nhiều ứng dụng toàn cầu khác nhau.
Phương Pháp Đào Tạo Nâng Cao:
- Huấn luyện trước: Các mô hình đã được huấn luyện trước trên một tập dữ liệu quy mô lớn gồm hàng triệu triệu token. Giai đoạn huấn luyện trước cuối cùng liên quan đến việc sử dụng dữ liệu dài với chất lượng cao để mở rộng cửa sổ ngữ cảnh hiệu quả lên đến 32K tokens lúc ban đầu, với các mở rộng tiếp theo lên 128K cho các mô hình lớn hơn.
- Huấn luyện sau: Một quy trình bốn giai đoạn tinh vi đã được áp dụng để trang bị cho các mô hình khả năng tuân theo hướng dẫn, kỹ năng lý luận và cơ chế tư duy kết hợp:
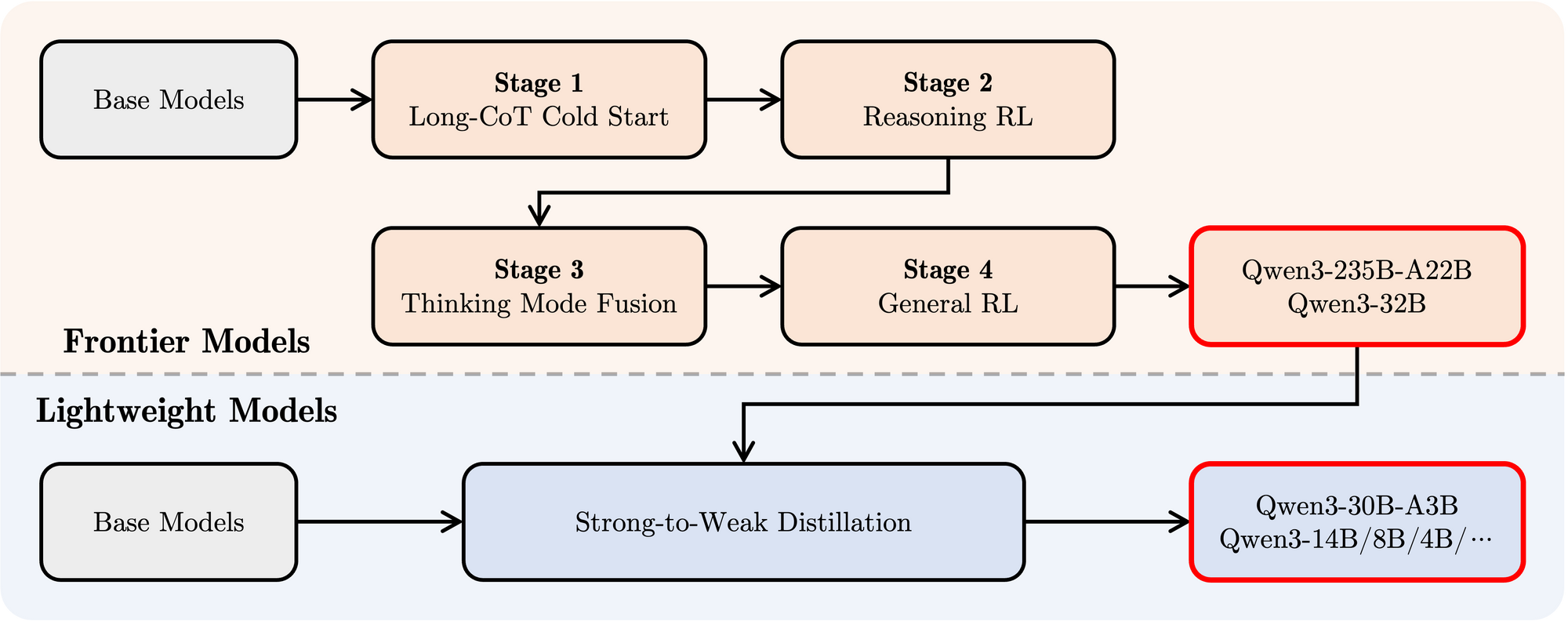
- Khởi động Lạnh CoT Dài: Huấn luyện tinh chỉnh có giám sát (SFT) trên dữ liệu Chain-of-Thought (CoT) dài đa dạng trải dài trên toán học, lập trình, suy luận logic và STEM để xây dựng khả năng lý luận cơ bản.
- Học Tăng Cường Dựa Trên Lý Luận (RL): Mở rộng tài nguyên tính toán cho RL bằng cách sử dụng phần thưởng dựa trên quy tắc để nâng cao khám phá và khai thác đặc biệt cho các nhiệm vụ lý luận.
- Kết hợp Chế Độ Tư Duy: Tích hợp khả năng phi tư duy bằng cách tinh chỉnh mô hình được nâng cao lý luận trên một sự kết hợp của dữ liệu CoT dài và dữ liệu huấn luyện hướng dẫn tiêu chuẩn do mô hình Giai đoạn 2 tạo ra. Điều này kết hợp lý luận sâu với việc tạo ra phản hồi nhanh chóng.
- Học Tăng Cường Chung: Áp dụng RL cho nhiều nhiệm vụ miền chung (tuân thủ hướng dẫn, tuân thủ định dạng, khả năng của tác nhân) để tinh chỉnh hành vi tổng thể và giảm thiểu đầu ra không mong muốn.
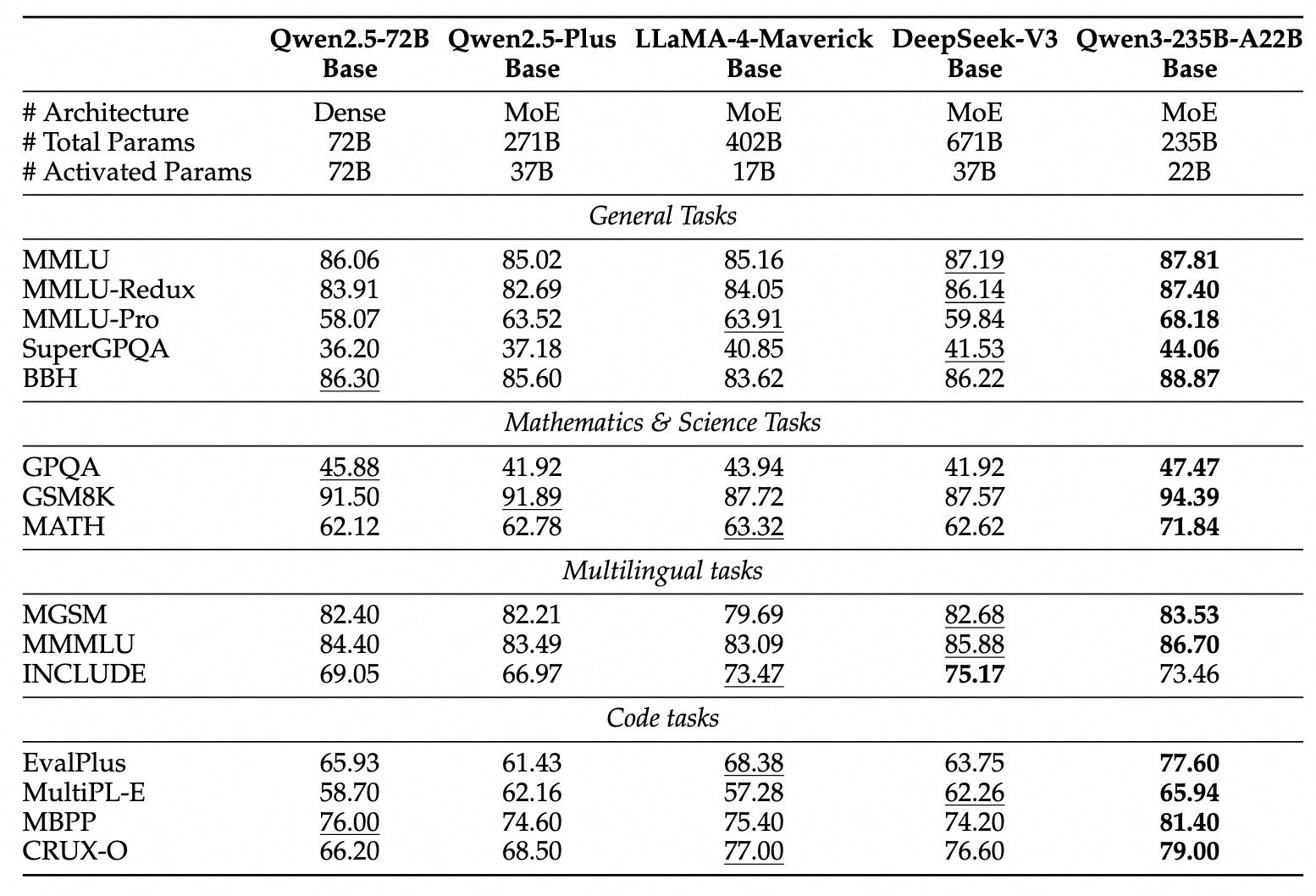
Hiệu Suất Tiêu Chuẩn của Qwen 3
Qwen3 thể hiện hiệu suất cạnh tranh cao so với các mô hình hàng đầu hiện tại khác:
MoE Hàng Đầu: Mô hình Qwen3-235B-A22B đạt được kết quả tương đương với các mô hình hàng đầu như DeepSeek-R1, o1 và o3-mini của Google, Grok-3 và Gemini-2.5-Pro trên nhiều tiêu chuẩn đánh giá lập trình, toán học và khả năng tổng quát.
MoE Nhỏ Hơn: Mô hình Qwen3-30B-A3B vượt trội hơn đáng kể so với các mô hình như QwQ-32B, mặc dù chỉ kích hoạt một phần (3B so với 32B) của các tham số trong quá trình suy diễn, nhấn mạnh hiệu quả của kiến trúc MoE.
Các Mô hình Dày đặc: Do các tiến bộ về kiến trúc và đào tạo, các mô hình dày đặc Qwen3 thường đạt hoặc vượt qua hiệu suất của các mô hình dày đặc lớn hơn Qwen2.5. Ví dụ:
Qwen3-1.7B≈Qwen2.5-3BQwen3-4B≈Qwen2.5-7B(và đối đầu vớiQwen2.5-72B-Instructtrong một số khía cạnh)Qwen3-8B≈Qwen2.5-14BQwen3-14B≈Qwen2.5-32BQwen3-32B≈Qwen2.5-72B
Đáng chú ý, các mô hình dày đặc cơ bản của Qwen3 cho thấy cải thiện hiệu suất mạnh mẽ so với các mô hình tiền nhiệm trong các nhiệm vụ STEM, lập trình và lý luận.
Hiệu Quả MoE: Các mô hình cơ bản MoE Qwen3 đạt được hiệu suất tương đương với các mô hình dày đặc Qwen2.5 lớn hơn đáng kể trong khi chỉ kích hoạt khoảng 10% các tham số, mang lại sự tiết kiệm đáng kể cả trong huấn luyện và tính toán suy diễn.
Các kết quả tiêu chuẩn này nhấn mạnh vị trí của Qwen3 như một dòng mô hình tiên tiến cung cấp hiệu suất cao và, đặc biệt đối với các biến thể MoE, cải thiện hiệu quả tính toán. Các mô hình này có sẵn qua các nền tảng tiêu chuẩn như Hugging Face, ModelScope và Kaggle, và được hỗ trợ bởi các framework triển khai phổ biến như Ollama, vLLM, SGLang, LMStudio và llama.cpp, tạo điều kiện cho việc tích hợp vào nhiều quy trình và ứng dụng khác nhau, bao gồm cả thực thi cục bộ.
Cách Chạy Qwen 3 Trên Máy Tính Địa Phương Với Ollama
Ollama đã trở nên cực kỳ phổ biến vì tính đơn giản của nó trong việc tải xuống, quản lý và chạy LLMs trên máy tính cục bộ. Nó trừu tượng hóa nhiều phức tạp, cung cấp một giao diện dòng lệnh và một máy chủ API.
1. Cài đặt:
Cài đặt Ollama thường là đơn giản. Truy cập trang web chính thức của Ollama (ollama.com) và làm theo hướng dẫn tải xuống cho hệ điều hành của bạn (macOS, Linux, Windows).
2. Kéo Các Mô Hình Qwen3:
Ollama duy trì một thư viện các mô hình sẵn có. Để chạy một mô hình Qwen3 cụ thể, bạn sử dụng lệnh ollama run. Nếu mô hình không có sẵn trên máy cục bộ, Ollama sẽ tự động tải xuống. Nhóm Qwen đã làm cho nhiều biến thể Qwen3 có sẵn trực tiếp trên thư viện của Ollama.
Bạn có thể tìm thấy các thẻ Qwen3 có sẵn trên trang Qwen3 của trang web Ollama (ví dụ: ollama.com/library/qwen3). Các thẻ phổ biến có thể bao gồm:
qwen3:0.6bqwen3:1.7bqwen3:4bqwen3:8bqwen3:14bqwen3:32bqwen3:30b-a3b(Mô hình MoE nhỏ hơn)
Để chạy mô hình 4B, chẳng hạn, chỉ cần mở terminal của bạn và nhập:
ollama run qwen3:4b
Lệnh này sẽ tải xuống mô hình (nếu cần) và bắt đầu một phiên trò chuyện tương tác.
3. Tương Tác Với Mô Hình:
Khi lệnh ollama run đang hoạt động, bạn có thể nhập các gợi ý trực tiếp vào terminal. Ollama cũng khởi động một máy chủ cục bộ (thường là ở http://localhost:11434) mà cung cấp một API tương thích với tiêu chuẩn OpenAI. Bạn có thể tương tác với chương trình này bằng cách sử dụng các công cụ như curl hoặc nhiều thư viện khách trong Python, JavaScript, v.v.
4. Các Yêu Cầu Về Phần Cứng:
Chạy LLMs trên máy cục bộ yêu cầu tài nguyên đáng kể.
- RAM: Ngay cả các mô hình nhỏ hơn (0.6B, 1.7B) cũng cần một vài gigabyte RAM. Các mô hình lớn hơn (8B, 14B, 32B, 30B-A3B) cần rất nhiều, thường là 16GB, 32GB, hoặc thậm chí 64GB+, tùy thuộc vào mức độ lượng tử hóa mà Ollama sử dụng.
- VRAM (GPU): Để có hiệu suất chấp nhận được, một GPU chuyên dụng với đủ VRAM được khuyến khích sử dụng. Ollama tự động sử dụng các GPU tương thích (NVIDIA, Apple Silicon). Số lượng VRAM quy định mô hình lớn nhất mà bạn có thể thoải mái chạy hoàn toàn trên GPU, điều này làm tăng tốc độ suy diễn một cách đáng kể.
- CPU: Trong khi Ollama có thể chạy các mô hình trên CPU, hiệu suất sẽ chậm hơn nhiều so với trên GPU.
Ollama rất tốt để bắt đầu nhanh chóng, phát triển địa phương, thử nghiệm và ứng dụng trò chuyện cho một người dùng, đặc biệt trên phần cứng tiêu dùng (trong giới hạn).
Cách Chạy Ollama Trên Máy Tính Địa Phương Với vLLM
vLLM là một thư viện phục vụ LLM hiệu suất cao kết hợp các tối ưu hóa như PagedAttention để cải thiện tốc độ suy diễn và hiệu suất bộ nhớ một cách đáng kể, làm cho nó rất lý tưởng cho các ứng dụng đòi hỏi và phục vụ các mô hình lớn hơn. Nhóm vLLM cung cấp hỗ trợ xuất sắc cho các kiến trúc mới, bao gồm hỗ trợ Ngày 0 cho Qwen3 ngay khi phát hành.
1. Cài đặt:
Cài đặt vLLM bằng pip. Thông thường, nên sử dụng môi trường ảo:
pip install -U vllm
Đảm bảo bạn có các yêu cầu cần thiết, thường là một GPU NVIDIA tương thích với bộ công cụ CUDA thích hợp đã được cài đặt. Tham khảo tài liệu vLLM để biết các yêu cầu cụ thể.
2. Phục Vụ Các Mô Hình Qwen3:
vLLM sử dụng lệnh vllm serve để tải một mô hình và khởi động một máy chủ API tương thích với OpenAI. Nhóm Qwen và tài liệu vLLM cung cấp hướng dẫn về cách chạy Qwen3.
Dựa trên thông tin đã cung cấp và việc sử dụng vLLM thông thường, đây là cách bạn có thể phục vụ mô hình lớn Qwen3-235B MoE bằng cách sử dụng lượng tử hóa FP8 (để giảm sử dụng bộ nhớ) và phân chia tensor trên 4 GPU:
vllm serve Qwen/Qwen3-235B-A22B-FP8 \
--enable-reasoning \
--reasoning-parser deepseek_r1 \
--tensor-parallel-size 4
Hãy phân tích lệnh này:
Qwen/Qwen3-235B-A22B-FP8: Đây là định danh của mô hình, có thể chỉ đến một vị trí kho Hugging Face.FP8cho thấy việc sử dụng lượng tử hóa số thực 8 bit, giảm mức tiêu thụ bộ nhớ của mô hình so với FP16 hoặc BF16, điều này rất quan trọng cho một mô hình lớn như vậy.--enable-reasoning: Cờ này rất quan trọng để kích hoạt khả năng tư duy kết hợp của Qwen3 trong vLLM.--reasoning-parser deepseek_r1: Đầu ra tư duy của Qwen3 có một định dạng cụ thể. vLLM yêu cầu một parser để xử lý điều này. Bài viết blog cho biết rằng đối với vLLM, parserdeepseek_r1nên được sử dụng (trong khi SGLang sử dụng một parserqwen3). Điều này đảm bảo vLLM có thể diễn giải đúng và có khả năng tách các bước tư duy khỏi phản hồi cuối cùng.--tensor-parallel-size 4: Cờ này chỉ định vLLM phân phối trọng số và tính toán của mô hình trên 4 GPU. Phân chia tensor là điều cần thiết để chạy các mô hình quá lớn không thể vừa vặn trên một GPU. Bạn sẽ điều chỉnh số này dựa trên số lượng GPU có sẵn của bạn.
Bạn có thể điều chỉnh lệnh này cho các mô hình Qwen3 khác (ví dụ: Qwen/Qwen3-30B-A3B hoặc Qwen/Qwen3-32B) và điều chỉnh các tham số như tensor-parallel-size dựa trên phần cứng của bạn.
3. Tương Tác Với Máy Chủ vLLM:
Khi vllm serve đang chạy, nó cung cấp một máy chủ API (mặc định là http://localhost:8000) phản ánh đặc tả API của OpenAI. Bạn có thể tương tác với nó bằng cách sử dụng các công cụ tiêu chuẩn:
- curl:
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen3-235B-A22B-FP8", # Sử dụng tên mô hình bạn đã phục vụ
"prompt": "Giải thích khái niệm Mixture-of-Experts trong LLMs.",
"max_tokens": 150,
"temperature": 0.7
}'
- Python OpenAI Client:
from openai import OpenAI
# Chỉ đến máy chủ vLLM cục bộ
client = OpenAI(base_url="http://localhost:8000/v1", api_key="EMPTY")
completion = client.completions.create(
model="Qwen/Qwen3-235B-A22B-FP8", # Sử dụng tên mô hình bạn đã phục vụ
prompt="Viết một câu chuyện ngắn về một robot phát hiện âm nhạc.",
max_tokens=200
)
print(completion.choices[0].text)
4. Hiệu Suất và Các Trường Hợp Sử Dụng:
vLLM nổi bật trong các kịch bản yêu cầu throughput cao (nhiều yêu cầu mỗi giây) và độ trễ thấp. Các tối ưu hóa của nó làm cho nó phù hợp cho:
- Xây dựng các ứng dụng được cung cấp bởi LLMs cục bộ.
- Phục vụ các mô hình cho nhiều người dùng đồng thời.
- Triển khai các mô hình lớn cần cấu hình multi-GPU.
- Môi trường sản xuất nơi hiệu suất là rất quan trọng.
Kiểm Tra API Cục Bộ Ollama Với Apidog
Apidog là một công cụ kiểm tra API rất phù hợp với chế độ API của Ollama. Nó cho phép bạn gửi yêu cầu, xem phản hồi và gỡ lỗi thiết lập Qwen 3 của bạn một cách hiệu quả.
Dưới đây là cách sử dụng Apidog với Ollama:
- Tạo một yêu cầu API mới:
- Điểm đến:
http://localhost:11434/api/generate - Gửi yêu cầu và theo dõi phản hồi trong timeline theo thời gian thực của Apidog.
- Sử dụng trích xuất JSONPath của Apidog để tự động phân tích phản hồi, một tính năng nổi bật hơn so với các công cụ như Postman.


Phản Hồi Streaming:
- Đối với các ứng dụng thời gian thực, hãy kích hoạt streaming:
- Tính năng Tự động Ghép của Apidog tổng hợp các thông điệp streaming, đơn giản hóa quá trình gỡ lỗi.
curl http://localhost:11434/api/generate -d '{"model": "gemma3:4b-it-qat", "prompt": "Viết một bài thơ về AI.", "stream": true}'

Quá trình này đảm bảo mô hình của bạn hoạt động như mong đợi, khiến Apidog trở thành một bổ sung quý giá.
Kết Luận
Việc phát hành bộ mô hình Qwen3 mạnh mẽ và đa dạng, kết hợp với các công cụ thực thi cục bộ trưởng thành như Ollama và vLLM, đánh dấu một thời điểm thú vị cho các chuyên gia AI. Dù bạn ưu tiên tính đơn giản plug-and-play của Ollama cho việc sử dụng cá nhân và thử nghiệm hay khả năng phục vụ hiệu suất cao của vLLM để xây dựng các ứng dụng robust, việc chạy các LLM tiên tiến trên máy địa phương trở nên khả thi hơn bao giờ hết.
Bằng cách mang các mô hình như Qwen3-30B-A3B hoặc thậm chí các biến thể dày đặc lớn hơn lên phần cứng của riêng bạn, bạn sẽ có quyền kiểm soát chưa từng có, sự riêng tư và tính hiệu quả về chi phí. Bạn có thể tận dụng các tính năng tiên tiến của chúng, như tư duy kết hợp và hỗ trợ đa ngôn ngữ rộng rãi, cho các dự án sáng tạo. Khi các hệ sinh thái phần cứng và phần mềm tiếp tục cải thiện, sức mạnh của các mô hình ngôn ngữ lớn sẽ ngày càng trở nên dân chủ hóa, chuyển từ các máy chủ đám mây xa xôi ngay vào máy tính cục bộ của chúng ta. Hãy thử nghiệm với Qwen3 bằng Ollama và vLLM để trải nghiệm những điều tiên tiến nhất của cuộc cách mạng AI cục bộ này.
Bạn có muốn một nền tảng tích hợp, All-in-One cho nhóm phát triển của bạn làm việc cùng nhau với năng suất tối đa?
Apidog đáp ứng tất cả các yêu cầu của bạn, và thay thế Postman với giá cả phải chăng hơn rất nhiều!