
Giới thiệu về Llama 3.1 Instruct 405B
Llama 3.1 của Meta Instruct 405B đại diện cho một bước nhảy vọt quan trọng trong lĩnh vực các mô hình ngôn ngữ lớn (LLMs). Như tên gọi đã gợi ý, "gã khổng lồ" này sở hữu tới 405 tỷ tham số, khiến nó trở thành một trong những mô hình AI lớn nhất hiện có công khai đến nay. Quy mô khổng lồ này chuyển thành khả năng nâng cao trên một loạt các nhiệm vụ, từ hiểu và sinh ngôn ngữ tự nhiên đến lý luận phức tạp và giải quyết vấn đề.
Một trong những tính năng nổi bật của Llama 3.1 405B là cửa sổ ngữ cảnh mở rộng lên đến 128.000 token. Sự gia tăng đáng kể so với các phiên bản trước cho phép mô hình xử lý và sinh ra những đoạn văn bản dài hơn rất nhiều, mở ra những khả năng mới cho các ứng dụng như tạo nội dung dài, phân tích tài liệu sâu và tương tác hội thoại kéo dài.
Mô hình xuất sắc trong các lĩnh vực như:
- Tóm tắt văn bản và độ chính xác
- Lý luận và phân tích tinh vi
- Khả năng đa ngôn ngữ (hỗ trợ 8 ngôn ngữ)
- Phát sinh và hiểu mã
- Tiềm năng tinh chỉnh theo nhiệm vụ cụ thể
Với tính chất mã nguồn mở của mình, Llama 3.1 405B sẵn sàng dân chủ hóa quyền truy cập vào công nghệ AI tiên tiến, cho phép các nhà nghiên cứu, lập trình viên và doanh nghiệp tận dụng sức mạnh của nó cho một loạt các ứng dụng.
So sánh nhà cung cấp API Llama 3.1
Nhiều nhà cung cấp đám mây cung cấp quyền truy cập vào các mô hình Llama 3.1 thông qua API của họ. Hãy cùng so sánh một số tùy chọn nổi bật:
| Nhà cung cấp | Giá (mỗi triệu token) | Tốc độ đầu ra | Độ trễ | Tính năng chính |
|---|---|---|---|---|
| Together.ai | $7.50 (tỷ lệ pha trộn) | 70 token/giây | Vừa phải | Tốc độ đầu ra ấn tượng |
| Fireworks | $3.00 (tỷ lệ pha trộn) | Tốt | 0.57 giây (rất thấp) | Giá cả cạnh tranh nhất |
| Microsoft Azure | Thay đổi tùy thuộc vào mức sử dụng | Vừa phải | 0.00 giây (gần như ngay lập tức) | Độ trễ thấp nhất |
| Replicate | $9.50 (token đầu ra) | 29 token/giây | Cao hơn một số đối thủ | Mô hình giá thẳng thắn |
| Anakin AI | $9.90/tháng (mô hình Freemium) | Không được chỉ định | Không được chỉ định | Trình tạo ứng dụng AI không cần mã |
- Together.ai: Cung cấp tốc độ đầu ra ấn tượng 70 token/giây, rất phù hợp cho các ứng dụng yêu cầu phản hồi nhanh chóng. Giá cả cạnh tranh ở mức $7.50 mỗi triệu token, tạo sự cân bằng giữa hiệu suất và chi phí.
- Fireworks: Nổi bật với giá cả cạnh tranh nhất ở mức $3.00 mỗi triệu token và độ trễ rất thấp (0.57 giây). Điều này làm cho nó trở thành lựa chọn tuyệt vời cho các dự án nhạy cảm về chi phí mà cũng yêu cầu thời gian phản hồi nhanh.
- Microsoft Azure: Có độ trễ thấp nhất (gần như ngay lập tức) trong số các nhà cung cấp, điều này rất quan trọng cho các ứng dụng thời gian thực. Tuy nhiên, cấu trúc giá của nó thay đổi tùy thuộc vào các mức sử dụng, có thể khiến việc ước lượng chi phí trở nên phức tạp hơn.
- Replicate: Cung cấp một mô hình giá thẳng thắn ở mức $9.50 mỗi triệu token đầu ra. Mặc dù tốc độ đầu ra của nó (29 token/giây) thấp hơn Together.ai, nhưng nó vẫn cung cấp hiệu suất hợp lý cho nhiều trường hợp sử dụng.
- Anakin AI: Cách tiếp cận của Anakin AI khác biệt đáng kể với các nhà cung cấp khác, tập trung vào khả năng tiếp cận và tùy biến hơn là các chỉ số hiệu suất thô. Nó hỗ trợ nhiều mô hình AI, bao gồm GPT-3.5, GPT-4, và Claude 2 & 3, cung cấp sự linh hoạt cho nhiều nhiệm vụ AI. Nó bắt đầu với mô hình freemium, với các gói bắt đầu từ $9.90/tháng.
Cách thực hiện các cuộc gọi API đến các mô hình Llama 3.1 bằng Apidog
Để tận dụng sức mạnh của Llama 3.1, bạn sẽ cần thực hiện các cuộc gọi API đến nhà cung cấp mà bạn chọn. Trong khi quy trình cụ thể có thể thay đổi một chút giữa các nhà cung cấp, các nguyên tắc chung vẫn giữ nguyên.
Dưới đây là hướng dẫn từng bước về cách thực hiện cuộc gọi API bằng Apidog:
- Mở Apidog: Khởi động Apidog và tạo một yêu cầu mới.
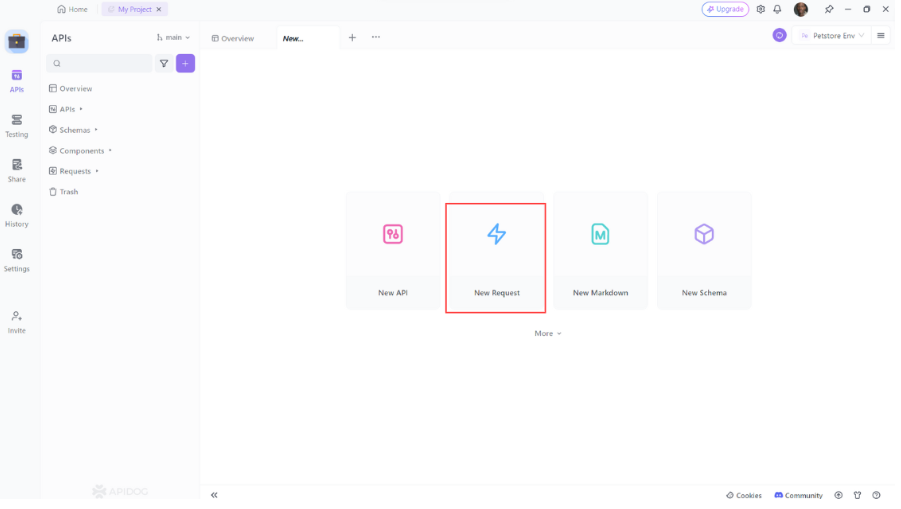
2. Chọn phương thức HTTP: Chọn "GET" làm phương thức yêu cầu hoặc "Post"
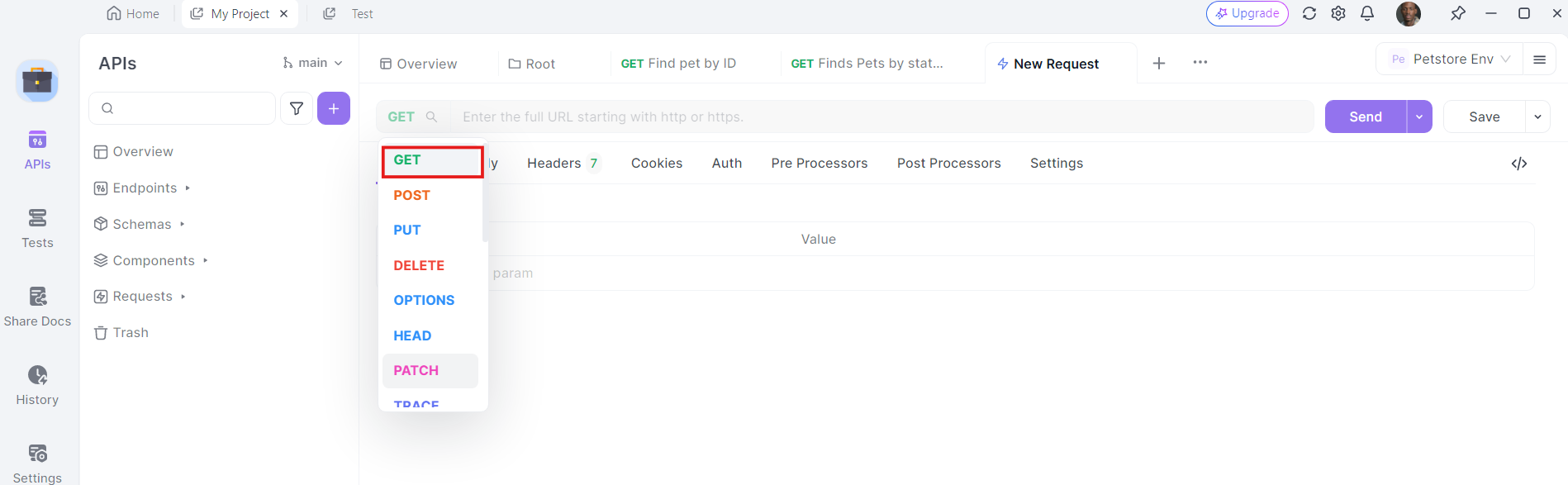
3. Nhập URL: Trong trường nhập URL, nhập điểm cuối mà bạn muốn gửi yêu cầu GET tới.
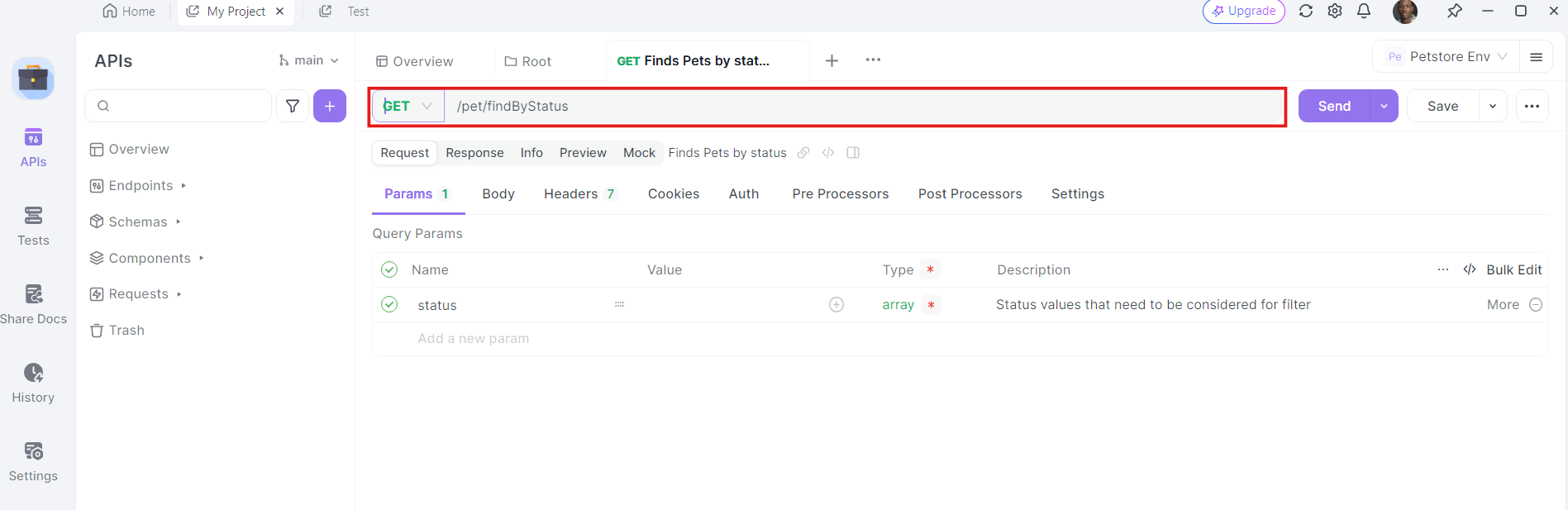
4. Thêm Headers: Bây giờ, đến lúc thêm các headers cần thiết. Nhấp vào tab "Headers" trong Apidog. Tại đây, bạn có thể chỉ định bất kỳ headers nào mà API yêu cầu. Các headers phổ biến cho các yêu cầu GET có thể bao gồm Authorization, Accept, và User-Agent.
Ví dụ:
- Authorization:
Bearer YOUR_ACCESS_TOKEN - Accept:
application/json
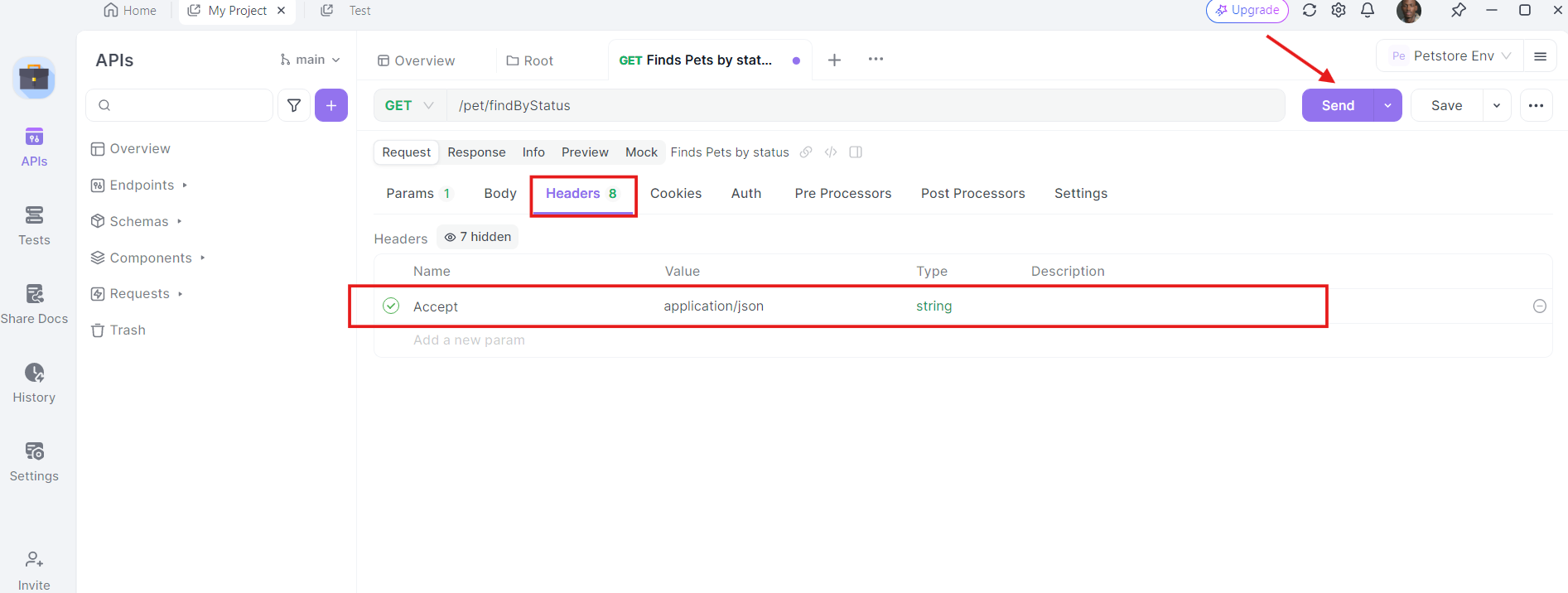
5. Gửi yêu cầu và kiểm tra phản hồi: Với URL, tham số truy vấn và headers đã sẵn sàng, giờ bạn có thể gửi yêu cầu API. Nhấp vào nút "Gửi" và Apidog sẽ thực hiện yêu cầu. Bạn sẽ thấy phản hồi hiển thị trong phần phản hồi.
Khi yêu cầu được gửi, Apidog sẽ hiển thị phản hồi từ máy chủ. Bạn có thể xem mã trạng thái, headers và nội dung của phản hồi. Điều này rất hữu ích cho việc gỡ lỗi và xác minh rằng các cuộc gọi API của bạn hoạt động như mong đợi.
Những thực hành tốt nhất khi sử dụng API Llama 3.1
Khi làm việc với API Llama 3.1, hãy nhớ giữ những thực hành tốt nhất này trong tâm trí:
- Thực hiện Streaming: Đối với các phản hồi dài hơn, bạn có thể muốn thực hiện streaming để nhận văn bản được sinh ra theo từng phần thời gian thực. Điều này có thể cải thiện trải nghiệm người dùng cho các ứng dụng yêu cầu phản hồi ngay lập tức.
- Tôn trọng giới hạn tỷ lệ: Hãy chú ý đến và tuân thủ các giới hạn tỷ lệ do nhà cung cấp API của bạn đặt ra để tránh gián đoạn dịch vụ.
- Thực hiện Caching: Đối với các lời nhắc hoặc truy vấn thường xuyên được sử dụng, hãy triển khai một hệ thống caching để giảm thiểu các cuộc gọi API và cải thiện thời gian phản hồi.
- Giám sát Sử dụng: Theo dõi việc sử dụng API của bạn để quản lý chi phí và đảm bảo bạn nằm trong hạn mức được phân bổ.
- Bảo mật: Không bao giờ tiết lộ khóa API của bạn trong mã phía client. Luôn thực hiện các cuộc gọi API từ một môi trường máy chủ an toàn.
- Lọc nội dung: Thực hiện lọc nội dung cho cả các lời nhắc đầu vào và các đầu ra được sinh ra để đảm bảo sử dụng mô hình một cách phù hợp.
- Tinh chỉnh: Cân nhắc việc tinh chỉnh mô hình trên dữ liệu chuyên ngành nếu bạn đang làm việc với các ứng dụng chuyên biệt.
- Phiên bản hóa: Theo dõi phiên bản mô hình Llama 3.1 cụ thể mà bạn đang sử dụng, vì các bản cập nhật có thể ảnh hưởng đến hành vi và đầu ra của mô hình.
Các trường hợp sử dụng thực tế
Hãy cùng xem một số trường hợp sử dụng thực tế nơi việc tích hợp Llama 3.1 với một API có thể tạo ra sự khác biệt:
1. Phân tích cảm xúc
Nếu bạn đang thực hiện một dự án phân tích cảm xúc, Llama 3.1 có thể giúp bạn phân loại văn bản thành tích cực, tiêu cực hoặc trung lập. Bằng cách tích hợp nó với một API, bạn có thể tự động hóa việc phân tích một lượng lớn dữ liệu, chẳng hạn như đánh giá của khách hàng hoặc bài đăng trên mạng xã hội.
2. Chatbot
Xây dựng một chatbot? Khả năng xử lý ngôn ngữ tự nhiên của Llama 3.1 có thể nâng cao sự hiểu biết và phản hồi của chatbot của bạn. Bằng cách sử dụng một API, bạn có thể tích hợp nó một cách dễ dàng với khung chatbot của bạn và cung cấp các tương tác thời gian thực.
3. Nhận diện hình ảnh
Đối với các dự án thị giác máy tính, Llama 3.1 có thể thực hiện các nhiệm vụ nhận diện hình ảnh. Bằng cách tận dụng một API, bạn có thể tải lên hình ảnh, nhận các phân loại thời gian thực và tích hợp các kết quả vào ứng dụng của bạn.
Khắc phục sự cố thường gặp
Đôi khi mọi thứ không diễn ra như kế hoạch. Dưới đây là một số vấn đề thường gặp bạn có thể gặp phải và cách khắc phục chúng:
1. Lỗi xác thực
Nếu bạn nhận được lỗi xác thực, hãy kiểm tra lại khóa API của bạn và đảm bảo rằng nó được cấu hình đúng trong Apidog.
2. Vấn đề mạng
Vấn đề mạng có thể làm cho các cuộc gọi API bị lỗi. Hãy đảm bảo rằng kết nối internet của bạn ổn định và thử lại. Nếu vấn đề vẫn tiếp diễn, hãy kiểm tra trang trạng thái của nhà cung cấp API để biết bất kỳ sự cố nào.
3. Giới hạn tỷ lệ
Các nhà cung cấp API thường thực thi các giới hạn tỷ lệ để ngăn chặn lạm dụng. Nếu bạn vượt quá giới hạn, bạn sẽ cần phải đợi trước khi thực hiện thêm yêu cầu. Hãy cân nhắc việc triển khai logic thử lại với khoảng thời gian tăng dần để xử lý giới hạn tỷ lệ một cách hiệu quả.
Kỹ thuật đặt câu hỏi với Llama 3.1 405B
Để có được kết quả tốt nhất từ Llama 3.1 405B, bạn sẽ cần thử nghiệm với các yêu cầu và tham số khác nhau. Hãy xem xét các yếu tố như:
- Kỹ thuật đặt câu hỏi: Tạo ra các yêu cầu rõ ràng và cụ thể để hướng dẫn đầu ra của mô hình.
- Nhiệt độ: Điều chỉnh tham số này để kiểm soát độ ngẫu nhiên của đầu ra.
- Token tối đa: Đặt một giới hạn phù hợp cho độ dài của văn bản được sinh ra.
Kết luận
Llama 3.1 405B đại diện cho một sự tiến bộ đáng kể trong lĩnh vực các mô hình ngôn ngữ lớn, cung cấp khả năng chưa từng có trong một gói mã nguồn mở. Bằng cách tận dụng sức mạnh của mô hình này thông qua các API được cung cấp bởi nhiều nhà cung cấp đám mây khác nhau, các lập trình viên và doanh nghiệp có thể mở khóa những khả năng mới trong các ứng dụng AI.
Tương lai của AI là mở, và với các công cụ như Llama 3.1 trong tay, các khả năng chỉ giới hạn bởi trí tưởng tượng và sự sáng tạo của chúng ta. Khi bạn khám phá và thử nghiệm với mô hình mạnh mẽ này, bạn không chỉ đang sử dụng một công cụ – bạn đang tham gia vào cuộc cách mạng trí tuệ nhân tạo đang diễn ra, giúp định hình tương lai của cách chúng ta tương tác và tận dụng trí thông minh máy móc.