
Việc Moonshot AI phát hành Kimi K2.5 đã thiết lập một tiêu chuẩn mới cho các mô hình nguồn mở. Với 1 nghìn tỷ tham số và kiến trúc Mixture-of-Experts (MoE), nó có thể cạnh tranh với các ông lớn độc quyền như GPT-4o. Tuy nhiên, kích thước khổng lồ của nó khiến việc chạy trở nên cực kỳ khó khăn.
Đối với các nhà phát triển và nhà nghiên cứu, việc chạy K2.5 cục bộ mang lại sự riêng tư không thể vượt qua, độ trễ bằng 0 (về mạng) và tiết kiệm chi phí mã thông báo API. Nhưng không giống như các mô hình 7B hoặc 70B nhỏ hơn, bạn không thể tải nó lên một chiếc máy tính xách tay chơi game tiêu chuẩn.
Hướng dẫn này khám phá cách tận dụng các kỹ thuật lượng tử hóa đột phá của Unsloth để chạy mô hình khổng lồ này trên phần cứng (tương đối) dễ tiếp cận bằng llama.cpp, và cách tích hợp nó vào quy trình làm việc phát triển của bạn với Apidog.
Tải xuống ứng dụng
Tại sao Kimi K2.5 khó chạy (Thử thách MoE)
Kimi K2.5 không chỉ "lớn"; nó còn phức tạp về kiến trúc. Nó sử dụng kiến trúc Mixture-of-Experts (MoE) với số lượng chuyên gia nhiều hơn đáng kể so với các mô hình mở thông thường như Mixtral 8x7B.
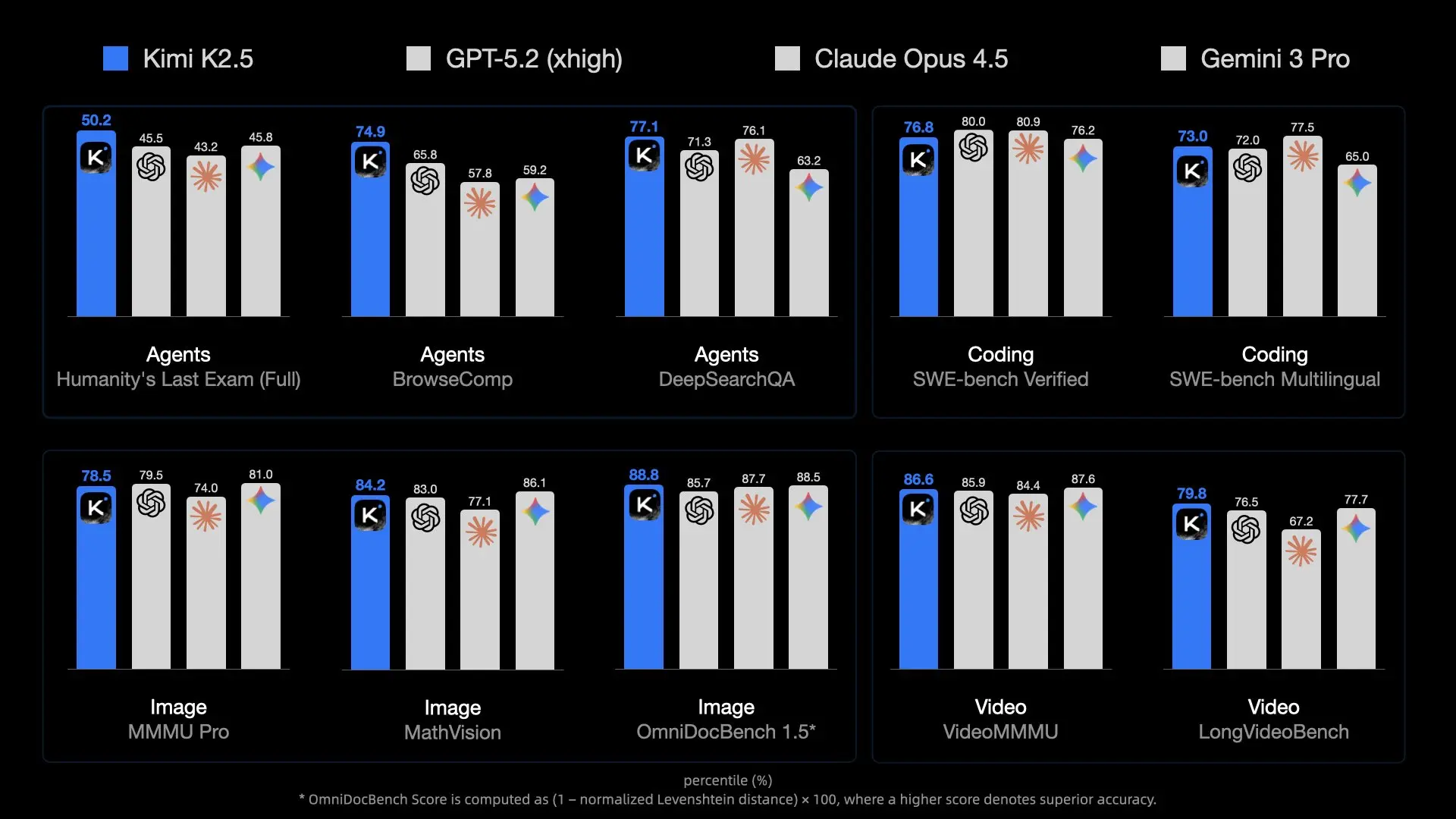
Vấn đề về quy mô
- Tổng tham số: ~1 nghìn tỷ. Ở độ chính xác FP16 tiêu chuẩn, điều này sẽ yêu cầu ~2 Terabyte VRAM.
- Tham số hoạt động: Mặc dù suy luận chỉ sử dụng một tập hợp con các tham số trên mỗi mã thông báo (nhờ MoE), bạn vẫn cần giữ toàn bộ mô hình trong bộ nhớ để định tuyến các mã thông báo một cách chính xác.
- Băng thông bộ nhớ: Nút thắt cổ chai thực sự không chỉ là dung lượng; mà là tốc độ. Di chuyển 240GB dữ liệu qua các kênh bộ nhớ cho mỗi lần tạo mã thông báo là một áp lực rất lớn đối với phần cứng tiêu dùng.
Đây là lý do tại sao lượng tử hóa (giảm số bit trên mỗi trọng số) là điều không thể thiếu. Nếu không có khả năng nén 1.58-bit cực cao của Unsloth, việc chạy mô hình này sẽ chỉ nằm trong lĩnh vực của các cụm siêu máy tính.
Yêu cầu phần cứng: Bạn có thể chạy nó không?
Lượng tử hóa "1.58-bit" là phép thuật giúp điều này khả thi, nén kích thước mô hình khoảng 60% mà không làm giảm trí thông minh.
Thông số kỹ thuật tối thiểu (Lượng tử hóa 1.58-bit)
- Dung lượng đĩa: >240 GB (Rất khuyến nghị dùng NVMe SSD)
- RAM + VRAM: >240 GB Tổng cộng
- Ví dụ 1: 2x RTX 3090 (48GB VRAM) + 256GB RAM hệ thống (Có thể thực hiện, nhưng chậm)
- Ví dụ 2: Mac Studio M2 Ultra với 192GB RAM (Không đủ, có thể bị lỗi hoặc hoán đổi dữ liệu nặng)
- Ví dụ 3: Máy chủ với 512GB RAM (Hoạt động tốt trên CPU)
- Tính toán: CPU hỗ trợ AVX2 hoặc GPU NVIDIA
Thông số kỹ thuật đề xuất (Hiệu suất)
Để đạt được tốc độ có thể sử dụng (>10 mã thông báo/giây):
- VRAM: Càng nhiều càng tốt. Chuyển các lớp sang GPU giúp tăng tốc độ đáng kể.
- Hệ thống: 4x GPU H100/H200 (Doanh nghiệp) HOẶC một máy trạm với 512GB RAM DDR5 (Người tiêu dùng/Người dùng chuyên nghiệp).
Lưu ý
Giải pháp: Unsloth Dynamic GGUF
Unsloth đã phát hành các phiên bản GGUF động của Kimi K2.5. Các tệp này cho phép bạn tải mô hình vào llama.cpp, công cụ có thể phân chia công việc một cách thông minh giữa CPU (RAM) và GPU (VRAM) của bạn.
Lượng tử hóa động là gì?
Lượng tử hóa tiêu chuẩn áp dụng cùng một mức nén cho mọi lớp. Cách tiếp cận "Động" của Unsloth thông minh hơn:
- Các lớp quan trọng (Attention/Routing): Được giữ ở độ chính xác cao hơn (ví dụ: 4-bit hoặc 6-bit) để duy trì trí thông minh.
- Các lớp Feed-Forward: Được nén mạnh mẽ xuống 1.58-bit hoặc 2-bit để tiết kiệm không gian.
Cách tiếp cận lai này cho phép một mô hình 1T chạy trong khoảng ~240GB đồng thời giữ lại khả năng suy luận vượt trội so với các mô hình 70B nhỏ hơn chạy ở độ chính xác đầy đủ.
- 1.58-bit (UD-TQ1_0): ~240GB. Phiên bản nhỏ nhất có thể hoạt động được.
- 2-bit (UD-Q2_K_XL): ~375GB. Khả năng suy luận tốt hơn, yêu cầu nhiều RAM hơn đáng kể.
- 4-bit (UD-Q4_K_XL): ~630GB. Hiệu suất gần như độ chính xác đầy đủ, chỉ dành cho phần cứng doanh nghiệp.
Hướng dẫn cài đặt từng bước
Chúng ta sẽ sử dụng llama.cpp vì nó cung cấp công cụ suy luận hiệu quả nhất cho các tác vụ phân chia CPU/GPU.
Bước 1: Cài đặt llama.cpp
Bạn cần biên dịch llama.cpp từ mã nguồn để đảm bảo bạn có hỗ trợ Kimi K2.5 mới nhất.
Mac/Linux:
# Cài đặt các phụ thuộc
sudo apt-get update && sudo apt-get install pciutils build-essential cmake curl libcurl4-openssl-dev -y
# Sao chép kho lưu trữ
git clone https://github.com/ggml-org/llama.cpp
cd llama.cpp
# Biên dịch với hỗ trợ CUDA (nếu bạn có GPU NVIDIA)
cmake -B build -DBUILD_SHARED_LIBS=OFF -DGGML_CUDA=ON
# HOẶC Biên dịch cho CPU/Mac Metal (mặc định)
# cmake -B build
# Biên dịch
cmake --build build --config Release -j --clean-first --target llama-cli llama-server
Bước 2: Tải xuống mô hình
Chúng ta sẽ tải xuống phiên bản GGUF của Unsloth. Phiên bản 1.58-bit được khuyến nghị cho hầu hết các thiết lập "phòng thí nghiệm tại nhà".
Bạn có thể sử dụng `huggingface-cli` hoặc `llama-cli` trực tiếp.
Tùy chọn A: Tải trực tiếp bằng llama-cli
# Tạo một thư mục cho mô hình
mkdir -p models/kimi-k2.5
# Tải xuống và chạy (điều này sẽ lưu vào bộ nhớ cache mô hình)
./build/bin/llama-cli \
-hf unsloth/Kimi-K2.5-GGUF:UD-TQ1_0 \
--model-url unsloth/Kimi-K2.5-GGUF \
--print-token-count 0
Tùy chọn B: Tải thủ công (Tốt hơn cho việc quản lý)
pip install huggingface_hub
# Tải xuống lượng tử hóa cụ thể
huggingface-cli download unsloth/Kimi-K2.5-GGUF \
--include "*UD-TQ1_0*" \
--local-dir models/kimi-k2.5
Bước 3: Chạy suy luận
Bây giờ, hãy khởi động mô hình. Chúng ta cần thiết lập các tham số lấy mẫu cụ thể được Moonshot AI khuyến nghị để đạt hiệu suất tối ưu (`temp 1.0`, `min-p 0.01`).
./build/bin/llama-cli \
-m models/kimi-k2.5/Kimi-K2.5-UD-TQ1_0-00001-of-00005.gguf \
--temp 1.0 \
--min-p 0.01 \
--top-p 0.95 \
--ctx-size 16384 \
--threads 16 \
--prompt "User: Write a Python script to scrape a website.\nAssistant:"
Các tham số chính:
- `--fit on`: Tự động chuyển các lớp sang GPU để phù hợp với VRAM khả dụng (rất quan trọng cho các thiết lập lai).
- `--ctx-size`: K2.5 hỗ trợ lên đến 256k, nhưng 16k an toàn hơn để bảo tồn bộ nhớ.
Chạy dưới dạng Máy chủ API cục bộ
Để tích hợp Kimi K2.5 với các ứng dụng của bạn hoặc Apidog, hãy chạy nó như một máy chủ tương thích OpenAI.
./build/bin/llama-server \
-m models/kimi-k2.5/Kimi-K2.5-UD-TQ1_0-00001-of-00005.gguf \
--port 8001 \
--alias "kimi-k2.5-local" \
--temp 1.0 \
--min-p 0.01 \
--ctx-size 16384 \
--host 0.0.0.0
API cục bộ của bạn hiện đã hoạt động tại http://127.0.0.1:8001/v1.
Kết nối Apidog với Kimi K2.5 cục bộ của bạn
Apidog là công cụ hoàn hảo để kiểm tra LLM cục bộ của bạn. Nó cho phép bạn xây dựng yêu cầu một cách trực quan, quản lý lịch sử hội thoại và gỡ lỗi việc sử dụng mã thông báo mà không cần viết các tập lệnh curl.
1. Tạo yêu cầu mới
Mở Apidog và tạo một dự án HTTP mới. Tạo yêu cầu POST đến:http://127.0.0.1:8001/v1/chat/completions
2. Cấu hình tiêu đề
Thêm các tiêu đề sau:
Content-Type:application/jsonAuthorization:Bearer not-needed(Các máy chủ cục bộ thường bỏ qua khóa, nhưng đây là một thói quen tốt)
3. Đặt phần thân yêu cầu
Sử dụng định dạng tương thích OpenAI:
{
"model": "kimi-k2.5-local",
"messages": [
{
"role": "system",
"content": "You are Kimi, running locally."
},
{
"role": "user",
"content": "Explain Quantum Computing in one sentence."
}
],
"temperature": 1.0,
"max_tokens": 1024
}
4. Gửi và xác minh
Nhấp vào Send. Bạn sẽ thấy luồng phản hồi.
Tại sao nên dùng Apidog?
- Theo dõi độ trễ: Xem chính xác thời gian mô hình cục bộ phản hồi (Thời gian đến mã thông báo đầu tiên).
- Quản lý lịch sử: Apidog giữ các phiên trò chuyện của bạn, giúp bạn dễ dàng kiểm tra khả năng hội thoại đa lượt của mô hình cục bộ.
- Tạo mã: Sau khi lời nhắc của bạn hoạt động, nhấp vào "Generate Code" trong Apidog để lấy đoạn mã Python/JS để sử dụng máy chủ cục bộ này trong ứng dụng của bạn.
Khắc phục sự cố chi tiết & Điều chỉnh hiệu suất
Chạy một mô hình 1T đẩy phần cứng tiêu dùng đến giới hạn của nó. Dưới đây là các mẹo nâng cao để giữ cho nó ổn định.
"Lỗi "Tải mô hình thất bại: hết bộ nhớ""
Đây là lỗi phổ biến nhất.
- Giảm ngữ cảnh: Hạ
--ctx-sizexuống 4096 hoặc 8192. - Đóng ứng dụng: Tắt Chrome, VS Code và Docker. Bạn cần từng byte RAM.
- Sử dụng Disk Offloading (Giải pháp cuối cùng):
llama.cppcó thể ánh xạ các phần mô hình vào đĩa, nhưng suy luận sẽ giảm xuống dưới 1 mã thông báo/giây.
"Đầu ra rác" hoặc Văn bản lặp lại
Kimi K2.5 rất nhạy cảm với việc lấy mẫu. Đảm bảo bạn đang sử dụng:
Temperature: 1.0 (Cao đáng ngạc nhiên, nhưng được khuyến nghị cho mô hình này)Min-P: 0.01 (Giúp loại bỏ các mã thông báo có xác suất thấp)Top-P: 0.95
Tốc độ tạo chậm
Nếu bạn đang nhận được 0.5 mã thông báo/giây, bạn có thể đang bị nghẽn cổ chai bởi băng thông RAM hệ thống hoặc tốc độ CPU.
- Tối ưu hóa: Đảm bảo
--threadskhớp với số lõi CPU vật lý của bạn (không phải luồng logic). - GPU Offload: Ngay cả việc chuyển 10 lớp sang một GPU nhỏ cũng có thể cải thiện đáng kể thời gian xử lý lời nhắc.
- Hỗ trợ NUMA: Nếu bạn đang sử dụng máy chủ có hai socket, hãy bật nhận biết NUMA trong các cờ biên dịch
llama.cppđể tối ưu hóa truy cập bộ nhớ.
Xử lý sự cố treo máy
Nếu mô hình tải nhưng bị lỗi trong quá trình tạo:
- Kiểm tra Swap: Đảm bảo bạn đã bật tệp hoán đổi lớn (100GB+). Ngay cả khi bạn có 256GB RAM, các đợt tăng đột biến tạm thời cũng có thể làm chết tiến trình.
- Tắt KV Cache Offload: Giữ bộ đệm KV trên CPU nếu VRAM hạn chế (`--no-kv-offload`).
Sẵn sàng xây dựng?
Cho dù bạn có thể chạy Kimi K2.5 cục bộ hay quyết định sử dụng API, Apidog cung cấp nền tảng hợp nhất để kiểm tra, tài liệu hóa và giám sát các tích hợp AI của bạn. Tải xuống Apidog miễn phí và bắt đầu thử nghiệm ngay hôm nay.
Tải xuống ứng dụng