
Các nhà phát triển và những người đam mê AI không ngừng tìm kiếm các mô hình hiệu quả hoạt động tốt mà không đòi hỏi tài nguyên khổng lồ. Google giới thiệu Gemma 3 270M, một mô hình ngôn ngữ nhỏ gọn với 270 triệu tham số. Mô hình này nổi bật là nhỏ nhất trong dòng Gemma 3, được tối ưu hóa cho các tác vụ trên thiết bị. Bạn có được khả năng tạo văn bản, trả lời câu hỏi, tóm tắt và suy luận, tất cả trong khi giữ các hoạt động cục bộ.
Gemma 3 270M hỗ trợ độ dài ngữ cảnh 32.000 token, cho phép nó xử lý hiệu quả các đầu vào đáng kể. Ngoài ra, nó còn tích hợp các kỹ thuật lượng tử hóa như Q4_0 Quantization Aware Training (QAT), giảm nhu cầu tài nguyên mà không làm giảm chất lượng. Kết quả là, bạn đạt được hiệu suất gần với các mô hình độ chính xác đầy đủ nhưng với yêu cầu bộ nhớ và tính toán thấp hơn.
Tuy nhiên, điều làm cho Gemma 3 270M đặc biệt hấp dẫn nằm ở khả năng tiếp cận của nó. Bạn có thể chạy nó trên phần cứng tiêu chuẩn, bao gồm máy tính xách tay hoặc thậm chí thiết bị di động, thúc đẩy quyền riêng tư và các ứng dụng có độ trễ thấp. Tiếp theo, hãy xem xét cách mô hình này phù hợp với các xu hướng phát triển AI rộng lớn hơn, nơi hiệu quả thúc đẩy sự đổi mới.
Tìm hiểu kiến trúc của Gemma 3 270M
Google xây dựng Gemma 3 270M trên kiến trúc dựa trên transformer, với 170 triệu tham số cho embedding với từ vựng 256.000 token và 100 triệu cho các khối transformer. Thiết lập này cho phép hỗ trợ đa ngôn ngữ và xử lý các tác vụ chuyên biệt. Bạn được hưởng lợi từ các kỹ thuật như lượng tử hóa INT4, rotary position embeddings và group query attention, giúp tăng tốc độ suy luận và giảm nhẹ.
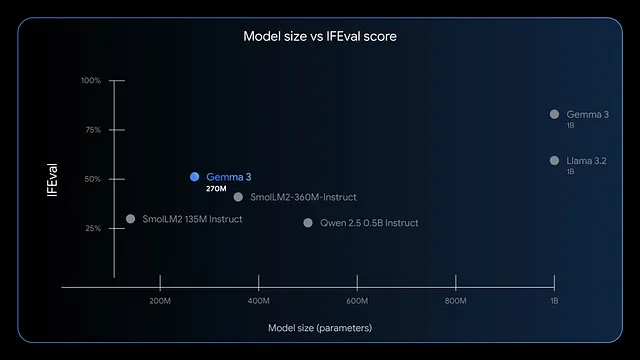
Hơn nữa, mô hình này vượt trội trong việc tuân thủ hướng dẫn và trích xuất dữ liệu. Các điểm chuẩn cho thấy điểm F1 cao trên IFEval, cho thấy hiệu suất mạnh mẽ trong các tác vụ đánh giá. So với các mô hình lớn hơn như GPT-4 hoặc Phi-3 Mini, Gemma 3 270M ưu tiên hiệu quả, sử dụng dưới 200MB ở chế độ 4-bit trên các thiết bị như Apple M4 Max.
Do đó, bạn triển khai nó cho các tình huống đòi hỏi phản hồi nhanh chóng, chẳng hạn như phân tích cảm xúc thời gian thực hoặc trích xuất thực thể chăm sóc sức khỏe. Tuy nhiên, kích thước nhỏ của nó không giới hạn sự sáng tạo; bạn áp dụng nó vào việc viết sáng tạo hoặc kiểm tra tuân thủ tài chính. Tiếp theo, hãy đánh giá những lợi thế của việc chạy mô hình này cục bộ.
Lợi ích khi chạy Gemma 3 270M cục bộ
Bạn tăng cường quyền riêng tư bằng cách giữ dữ liệu trên thiết bị của mình, tránh truyền tải lên đám mây có nguy cơ bị lộ. Gemma 3 270M giảm độ trễ, cung cấp phản hồi trong mili giây thay vì giây. Hơn nữa, nó cắt giảm chi phí vì bạn tránh được phí đăng ký cho các API dựa trên đám mây.
Ngoài ra, hiệu quả năng lượng của mô hình cũng nổi bật. Nó chỉ tiêu thụ 0,75% pin của Pixel 9 Pro cho 25 cuộc trò chuyện ở chế độ lượng tử hóa INT4. Đặc điểm này phù hợp với điện toán di động và biên, nơi năng lượng là quan trọng. Bạn cũng có thể tùy chỉnh mô hình dễ dàng thông qua fine-tuning với các công cụ như LoRA, chỉ yêu cầu dữ liệu tối thiểu.
Tuy nhiên, việc thực thi cục bộ trao quyền cho các nhóm nhỏ hoặc nhà phát triển cá nhân. Bạn có thể thử nghiệm tự do, lặp lại các ứng dụng như định tuyến truy vấn thương mại điện tử hoặc cấu trúc văn bản pháp lý. Khi bạn tiếp tục, hãy kiểm tra xem hệ thống của bạn có đáp ứng các yêu cầu hay không.
Yêu cầu hệ thống để suy luận Gemma 3 270M
Gemma 3 270M yêu cầu phần cứng khiêm tốn, giúp nó dễ tiếp cận. Đối với suy luận chỉ bằng CPU, bạn cần ít nhất 4GB RAM và bộ xử lý hiện đại như Intel Core i5 hoặc tương đương. Tuy nhiên, tăng tốc GPU giúp cải thiện tốc độ; một card NVIDIA với 2GB VRAM là đủ cho các phiên bản lượng tử hóa.
Cụ thể, ở chế độ 4-bit, mô hình vừa vặn trong bộ nhớ 200MB, cho phép chạy trên các thiết bị có tài nguyên hạn chế. Người dùng Apple silicon được hưởng lợi từ MLX-LM, đạt hơn 650 token mỗi giây trên M4 Max. Để fine-tuning, hãy cấp phát 8GB RAM và một GPU với 4GB VRAM để xử lý các tập dữ liệu nhỏ một cách hiệu quả.
Điều quan trọng là, các hệ điều hành như Windows, macOS hoặc Linux đều hoạt động, nhưng hãy đảm bảo Python 3.10+ để tương thích thư viện. Bộ nhớ yêu cầu khoảng 1GB cho các tệp mô hình. Với những điều này, bạn có thể cài đặt và chạy mà không gặp vấn đề gì. Bây giờ, hãy khám phá các phương pháp cài đặt.
Chọn công cụ phù hợp để chạy Gemma 3 270M cục bộ
Một số framework hỗ trợ Gemma 3 270M, mỗi framework đều có những điểm mạnh riêng. Hugging Face Transformers cung cấp sự linh hoạt cho việc viết script Python và tích hợp. LM Studio cung cấp giao diện thân thiện với người dùng để quản lý mô hình.
Ngoài ra, llama.cpp cho phép suy luận hiệu quả dựa trên C++, hoàn hảo cho việc tối ưu hóa cấp thấp. Đối với các thiết bị Apple, MLX tối ưu hóa hiệu suất trên chip M-series. Bạn chọn dựa trên chuyên môn của mình; người mới bắt đầu thích LM Studio, trong khi các nhà phát triển nghiêng về Transformers.
Do đó, những công cụ này dân chủ hóa quyền truy cập. Trong các phần sau, hãy làm theo hướng dẫn từng bước cho các phương pháp phổ biến.
Hướng dẫn từng bước: Chạy Gemma 3 270M với Hugging Face Transformers
Bạn bắt đầu bằng cách cài đặt các thư viện cần thiết. Mở terminal của bạn và thực thi:
pip install transformers torch
Lệnh này tải về Transformers và PyTorch. Tiếp theo, nhập các thành phần trong một script Python:
from transformers import AutoTokenizer, AutoModelForCausalLM
Tải mô hình và tokenizer:
model_name = "google/gemma-3-270m"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
device_map="auto" đặt mô hình lên GPU nếu có. Chuẩn bị đầu vào của bạn:
input_text = "Explain quantum computing in simple terms."
inputs = tokenizer(input_text, return_tensors="pt").to(model.device)
Tạo đầu ra:
outputs = model.generate(**inputs, max_new_tokens=200)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(response)
Điều này tạo ra một lời giải thích mạch lạc. Để tối ưu hóa, hãy thêm lượng tử hóa:
from transformers import BitsAndBytesConfig
quant_config = BitsAndBytesConfig(load_in_4bit=True)
model = AutoModelForCausalLM.from_pretrained(model_name, quantization_config=quant_config)
Lượng tử hóa làm giảm việc sử dụng bộ nhớ. Bạn xử lý lỗi bằng cách đảm bảo đăng nhập Hugging Face cho các mô hình có cổng truy cập:
from huggingface_hub import login
login(token="your_hf_token")
Lấy token từ tài khoản Hugging Face của bạn. Với thiết lập này, bạn có thể chạy suy luận nhiều lần. Tuy nhiên, đối với người dùng không dùng Python, hãy xem xét LM Studio tiếp theo.
Hướng dẫn từng bước: Chạy Gemma 3 270M với LM Studio
LM Studio cung cấp một giao diện trực quan. Tải xuống từ lmstudio.ai và cài đặt.
Khởi chạy ứng dụng, sau đó tìm kiếm "gemma-3-270m" trong trung tâm mô hình.
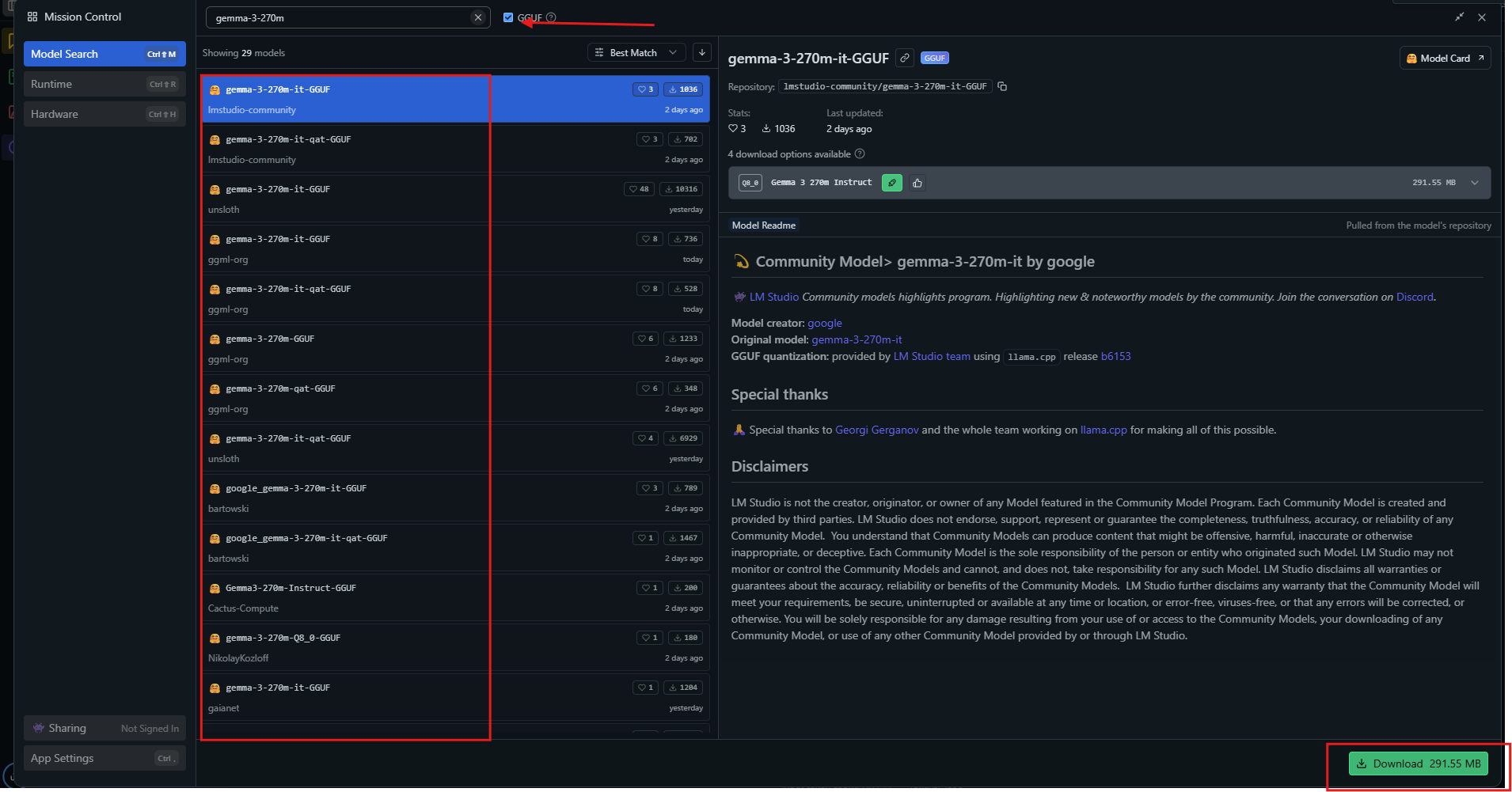
Chọn một biến thể lượng tử hóa như Q4_0 và tải xuống. Khi đã sẵn sàng, hãy tải mô hình từ thanh bên. Điều chỉnh cài đặt: đặt ngữ cảnh thành 32k, nhiệt độ thành 1.0.
Nhập một lời nhắc vào cửa sổ trò chuyện và nhấn gửi. LM Studio hiển thị các phản hồi với tốc độ token. Xuất các cuộc trò chuyện hoặc fine-tune thông qua các công cụ tích hợp.
Để sử dụng nâng cao, hãy bật GPU offloading trong cài đặt. LM Studio tự động chọn các nguồn tối ưu, đảm bảo khả năng tương thích. Phương pháp này phù hợp với những người học trực quan. Ngoài ra, hãy khám phá llama.cpp để tinh chỉnh hiệu suất.
Hướng dẫn từng bước: Chạy Gemma 3 270M với llama.cpp
llama.cpp cung cấp suy luận hiệu suất cao. Clone kho lưu trữ:
git clone https://github.com/ggerganov/llama.cpp
Xây dựng nó:
make -j
Tải xuống các tệp GGUF từ Hugging Face:
huggingface-cli download unsloth/gemma-3-270m-it-GGUF --include "*.gguf"
Chạy suy luận:
./llama-cli -m gemma-3-270m-it-Q4_K_M.gguf -p "Build a simple AI app."
Chỉ định các tham số như --n-gpu-layers 999 để sử dụng toàn bộ GPU. llama.cpp hỗ trợ các mức lượng tử hóa, cân bằng tốc độ và độ chính xác. Bạn biên dịch với CUDA cho GPU NVIDIA:
make GGML_CUDA=1
Điều này tăng tốc xử lý. llama.cpp vượt trội trong các hệ thống nhúng. Bây giờ, hãy áp dụng mô hình vào các ví dụ thực tế.
Ví dụ thực tế về việc sử dụng Gemma 3 270M cục bộ
Bạn tạo một bộ phân tích cảm xúc. Nhập các đánh giá của khách hàng và mô hình sẽ phân loại chúng là tích cực hay tiêu cực. Viết script bằng Python:
prompt = "Classify: This product is amazing!"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs)
print(tokenizer.decode(outputs[0]))
Gemma 3 270M xuất ra "Tích cực." Mở rộng sang tóm tắt:
text = "Long article here..."
prompt = f"Summarize: {text}"
# Generate summary
Nó cô đọng nội dung một cách hiệu quả. Đối với trả lời câu hỏi, truy vấn:
"Điều gì gây ra biến đổi khí hậu?"
Mô hình giải thích về khí nhà kính. Trong chăm sóc sức khỏe, trích xuất các thực thể từ ghi chú. Những cách sử dụng này thể hiện tính linh hoạt. Hơn nữa, fine-tune để chuyên biệt hóa.
Fine-tuning Gemma 3 270M cục bộ
Fine-tuning điều chỉnh mô hình. Sử dụng thư viện PEFT của Hugging Face:
pip install peft
Tải với cấu hình LoRA:
from peft import LoraConfig, get_peft_model
lora_config = LoraConfig(r=16, lora_alpha=32, target_modules=["q_proj", "v_proj"])
model = get_peft_model(model, lora_config)
Chuẩn bị một tập dữ liệu, sau đó huấn luyện:
from transformers import Trainer, TrainingArguments
trainer = Trainer(model=model, args=TrainingArguments(output_dir="./results"))
trainer.train()
LoRA yêu cầu ít dữ liệu, hoàn thành nhanh chóng trên phần cứng khiêm tốn. Lưu và tải lại bộ điều hợp. Điều này giúp tăng hiệu suất trên các tác vụ tùy chỉnh như dự đoán nước đi cờ vua. Tuy nhiên, hãy theo dõi hiện tượng overfitting.
Mẹo tối ưu hóa hiệu suất cho Gemma 3 270M
Bạn tối đa hóa tốc độ bằng cách lượng tử hóa thành 4-bit hoặc 8-bit. Sử dụng batching cho nhiều suy luận. Đặt temperature thành 1.0, top_k=64, top_p=0.95 theo khuyến nghị.
Trên GPU, bật mixed precision. Đối với các ngữ cảnh dài, quản lý KV cache cẩn thận. Theo dõi VRAM bằng các công cụ như nvidia-smi. Cập nhật thư viện thường xuyên để tối ưu hóa.
Do đó, những tinh chỉnh này mang lại hơn 130 token mỗi giây trên phần cứng phù hợp. Tránh các lỗi phổ biến như token BOS kép trong lời nhắc. Với thực hành, bạn đạt được các lần chạy hiệu quả.
Kết luận
Giờ đây bạn đã có kiến thức để chạy Gemma 3 270M cục bộ. Từ thiết lập đến tối ưu hóa, mỗi bước đều xây dựng khả năng. Thử nghiệm, fine-tune và triển khai để hiện thực hóa tiềm năng của nó. Các mô hình nhỏ như thế này tạo ra những tác động lớn trong khả năng tiếp cận AI.