
Dòng sản phẩm Qwen của Alibaba tiếp tục phá vỡ các giới hạn trong các mô hình ngôn ngữ lớn, và Qwen3-Next-80B-A3B nổi bật như một ví dụ điển hình về sự kết hợp giữa hiệu quả và hiệu suất cao. Các kỹ sư và nhà phát triển tìm kiếm những mô hình cung cấp khả năng suy luận mạnh mẽ mà không tốn nhiều chi phí tính toán như các mô hình khổng lồ dày đặc. Mô hình này đáp ứng trực tiếp nhu cầu đó, tự hào với 80 tỷ tham số nhưng chỉ kích hoạt 3 tỷ tham số cho mỗi token. Nhờ đó, các nhóm đạt được tốc độ suy luận nhanh hơn và giảm chi phí đào tạo, làm cho nó trở nên lý tưởng cho các triển khai trong thế giới thực.
Trong bài đăng này, bạn sẽ khám phá các thành phần cốt lõi của Qwen3-Next-80B-A3B, phân tích kiến trúc đổi mới của nó, xem xét dữ liệu hiệu suất thực nghiệm và nắm vững API của nó thông qua các bước thực hành. Hơn nữa, bạn sẽ tích hợp các công cụ như Apidog để nâng cao quy trình làm việc của mình. Đến cuối bài, bạn sẽ có đủ kiến thức để triển khai mô hình này một cách hiệu quả vào các ứng dụng của mình.
Điều Gì Định Nghĩa Qwen3-Next-80B-A3B? Các Tính Năng Cốt Lõi và Đổi Mới
Qwen3-Next-80B-A3B xuất hiện từ dòng Qwen của Alibaba như một mô hình Mixture of Experts (MoE) thưa thớt được tối ưu hóa cho cả tốc độ và khả năng. Các nhà phát triển chỉ kích hoạt một phần nhỏ các tham số của nó trong quá trình suy luận, điều này mang lại khoản tiết kiệm tài nguyên đáng kể. Cụ thể, mô hình này sử dụng cấu hình MoE siêu thưa với 512 chuyên gia, định tuyến tới 10 chuyên gia cho mỗi token cùng với một chuyên gia chung. Kết quả là, nó cạnh tranh với hiệu suất của các đối tác dày đặc hơn như Qwen3-32B trong khi tiêu thụ ít năng lượng hơn nhiều.
Hơn nữa, mô hình hỗ trợ dự đoán đa token, một kỹ thuật giúp tăng tốc giải mã suy đoán. Tính năng này cho phép mô hình tạo ra nhiều token cùng lúc, tăng thông lượng trong các giai đoạn giải mã. Các nhà phát triển đánh giá cao điều này cho các ứng dụng yêu cầu phản hồi nhanh, chẳng hạn như chatbot hoặc công cụ phân tích thời gian thực.
Dòng sản phẩm này bao gồm các biến thể được điều chỉnh theo nhu cầu cụ thể: mô hình cơ sở để huấn luyện trước tổng quát, phiên bản hướng dẫn cho các tác vụ đàm thoại được tinh chỉnh, và biến thể tư duy cho các chuỗi suy luận nâng cao. Ví dụ, Qwen3-Next-80B-A3B-Thinking vượt trội trong việc giải quyết vấn đề phức tạp, vượt qua các mô hình như Gemini-2.5-Flash-Thinking trên các điểm chuẩn. Ngoài ra, nó xử lý 119 ngôn ngữ, cho phép triển khai đa ngôn ngữ mà không cần huấn luyện lại.
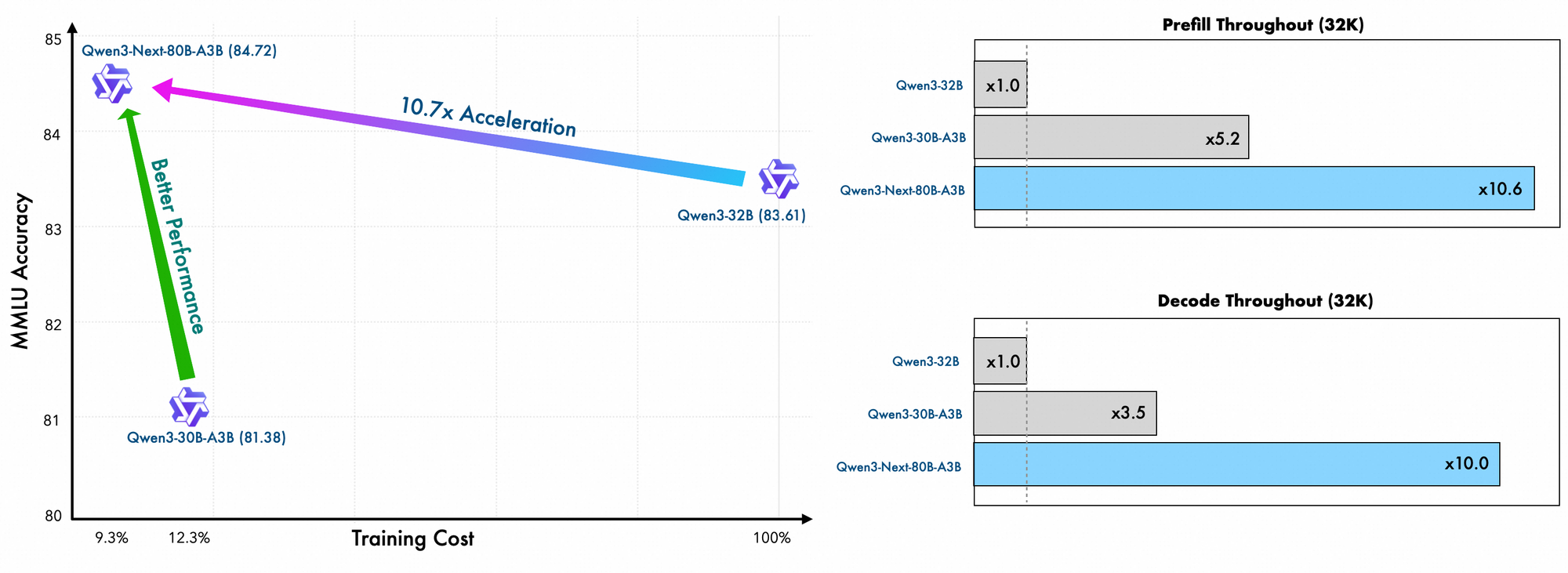
Chi tiết về quá trình huấn luyện cho thấy hiệu quả hơn nữa. Các kỹ sư của Alibaba huấn luyện trước mô hình này bằng các phương pháp hiệu quả về mặt mở rộng, chỉ tốn 10% chi phí so với Qwen3-32B. Họ tận dụng bố cục lai trên 48 lớp với kích thước ẩn 2048, đảm bảo phân phối tính toán cân bằng. Do đó, mô hình thể hiện khả năng hiểu ngữ cảnh dài vượt trội, duy trì độ chính xác vượt quá 32K token trong khi các mô hình khác gặp khó khăn.
Trong thực tế, những tính năng này giúp các nhà phát triển mở rộng giải pháp AI một cách hiệu quả về chi phí. Cho dù bạn xây dựng công cụ tìm kiếm doanh nghiệp hay trình tạo nội dung tự động, Qwen3-Next-80B-A3B đều cung cấp nền tảng cho các ứng dụng đổi mới. Dựa trên nền tảng này, phần tiếp theo sẽ xem xét các yếu tố kiến trúc giúp đạt được những hiệu quả đó.
Mổ Xẻ Kiến Trúc Của Qwen3-Next-80B-A3B: Bản Thiết Kế Kỹ Thuật
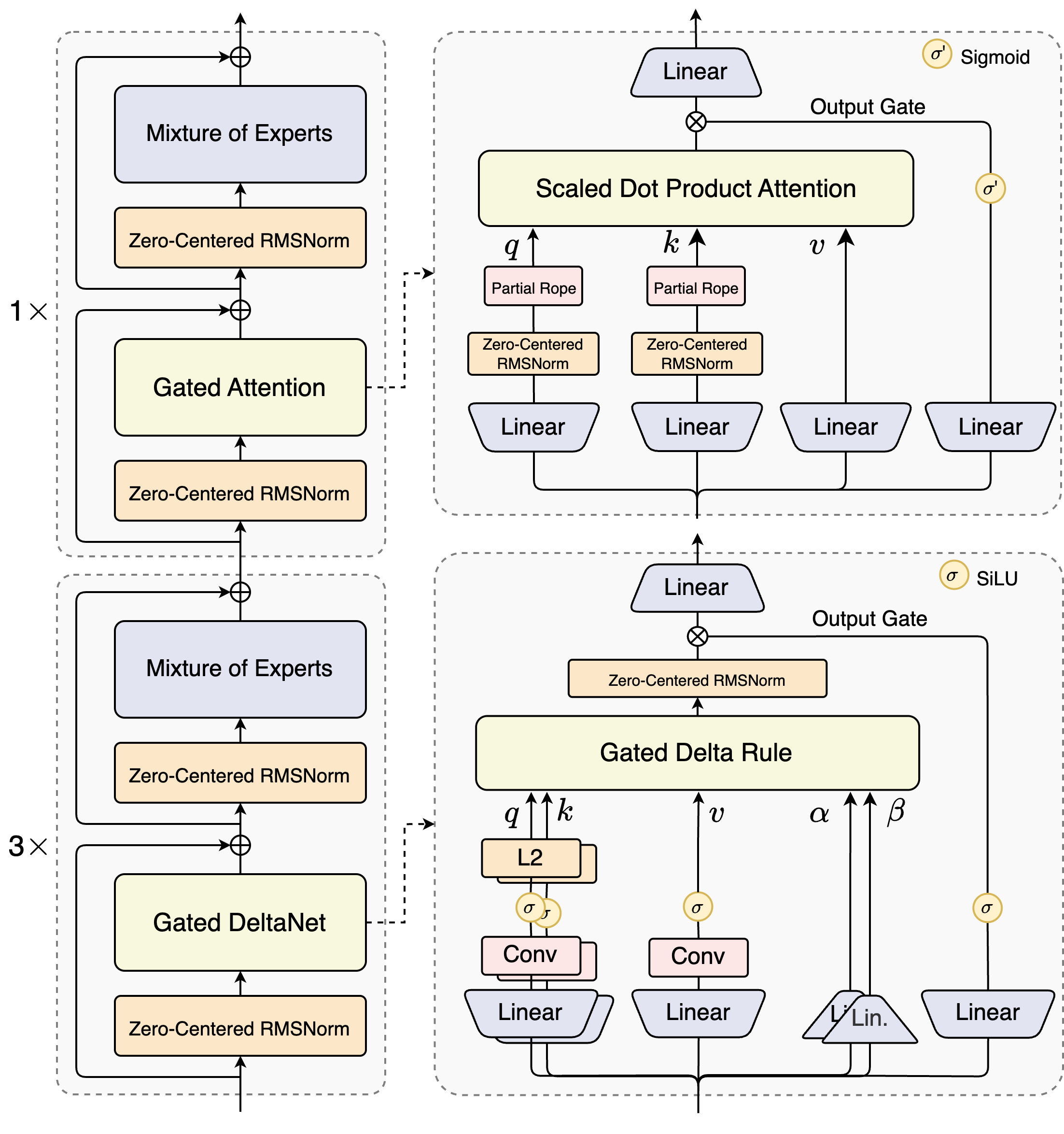
Các kiến trúc sư của Qwen3-Next-80B-A3B giới thiệu một thiết kế lai kết hợp các cơ chế cổng (gated mechanisms) với các kỹ thuật chuẩn hóa tiên tiến. Trọng tâm của nó là một lớp Mixture of Experts (MoE), nơi các chuyên gia chuyên về các đường dẫn tính toán riêng biệt. Mô hình định tuyến đầu vào một cách động, kích hoạt một tập hợp con để giảm thiểu chi phí. Ví dụ, khối attention có cổng xử lý các truy vấn, khóa và giá trị thông qua các nhúng RoPE một phần và các lớp RMSNorm tập trung vào số 0, tăng cường sự ổn định trong các chuỗi dài.
Hãy xem xét mô-đun attention tích vô hướng có tỷ lệ (scaled dot-product attention). Nó tích hợp các phép chiếu tuyến tính theo sau là các cổng đầu ra được điều chỉnh bởi các hàm kích hoạt sigmoid. Cấu hình này cho phép kiểm soát chính xác luồng thông tin, ngăn ngừa sự pha loãng trong các không gian chiều cao. Hơn nữa, RMSNorm tập trung vào số 0 đứng trước và sau các hoạt động này, tập trung các kích hoạt xung quanh số 0 để giảm thiểu các vấn đề về gradient trong quá trình huấn luyện.
Sơ đồ minh họa hai khối chính: khối trên tập trung vào attention có cổng với attention tích vô hướng có tỷ lệ, trong khi khối dưới nhấn mạnh DeltaNet có cổng. Trong đường dẫn attention (mở rộng 1x), đầu vào đi qua RMSNorm tập trung vào số 0, sau đó vào lõi attention có cổng. Tại đây, các phép chiếu truy vấn (q), khóa (k) và giá trị (v) sử dụng RoPE một phần để mã hóa vị trí. Sau attention, một RMSNorm và các lớp tuyến tính khác cấp vào MoE, nơi sử dụng đầu ra có cổng sigmoid.
Chuyển sang đường dẫn DeltaNet (mở rộng 3x), kiến trúc sử dụng quy tắc Delta có cổng để dự đoán tinh chỉnh. Nó có chuẩn hóa L2 trên q và k, các lớp tích chập để trích xuất đặc trưng cục bộ và các hàm kích hoạt SiLU cho phi tuyến tính. Cổng đầu ra, kết hợp với phép chiếu tuyến tính, đảm bảo đầu ra đa token mạch lạc. Thiết kế của khối này hỗ trợ giải mã suy đoán của mô hình, nơi nó dự đoán trước một số token, được xác minh trong các lượt tiếp theo.
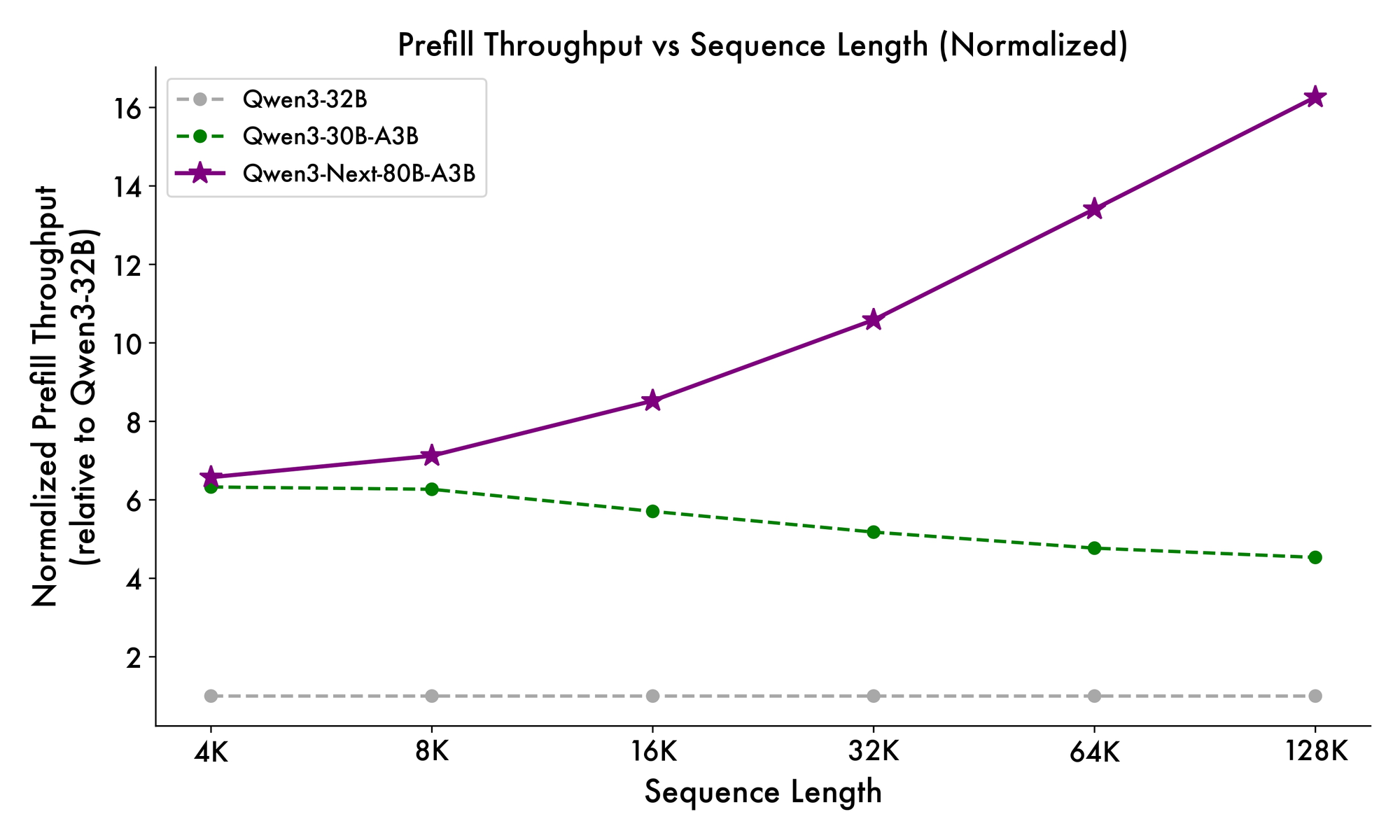
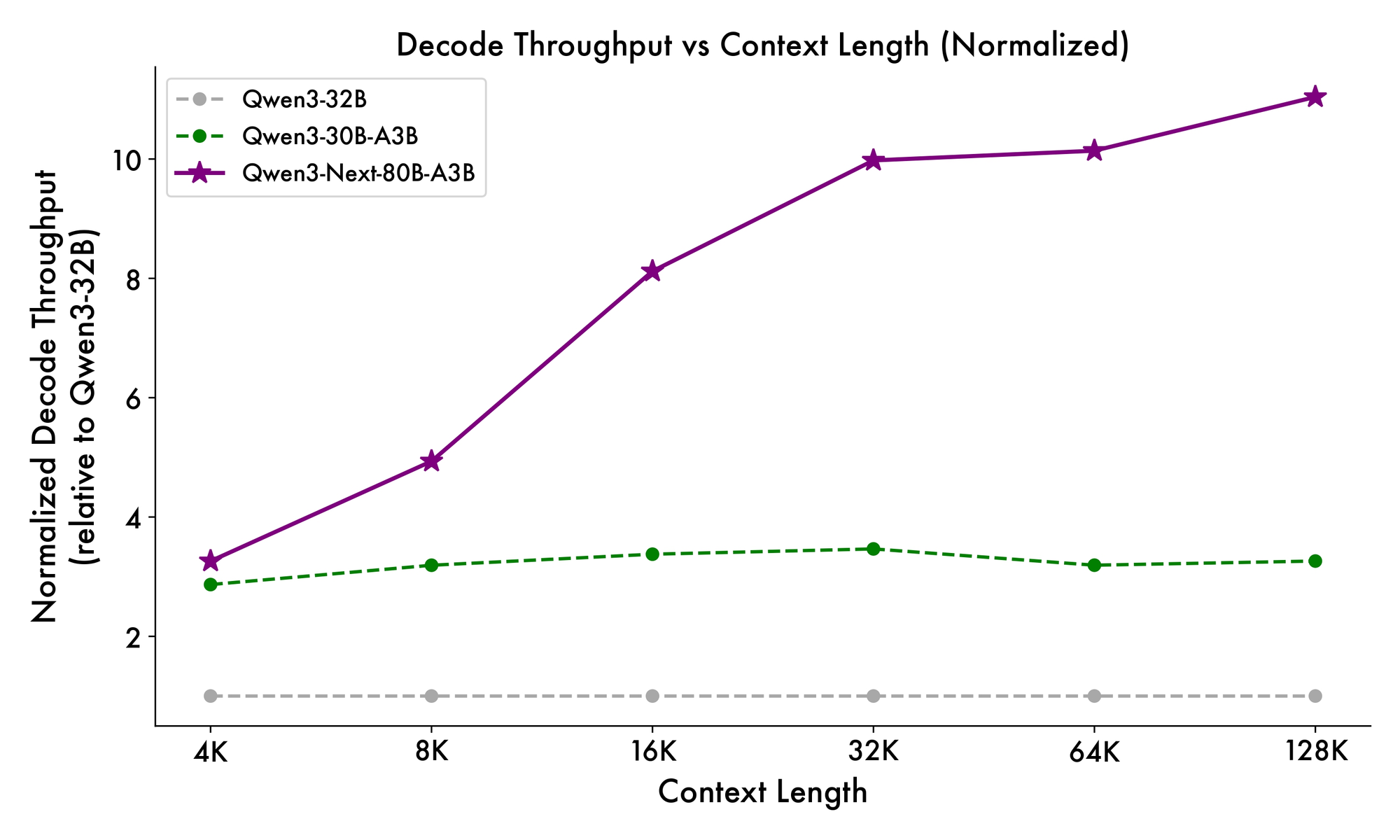
Hơn nữa, cấu trúc tổng thể tích hợp một chuyên gia chung trong MoE để xử lý các mẫu phổ biến trên các token, giảm sự dư thừa. Các nhúng rope một phần trong các phép chiếu bảo toàn tính bất biến quay cho các ngữ cảnh mở rộng. Như đã được chứng minh trong các điểm chuẩn, cấu hình này mang lại thông lượng cao hơn gần 7 lần ở độ dài ngữ cảnh 4K so với Qwen3-32B. Vượt quá 32K token, tốc độ vượt quá 10 lần, làm cho nó phù hợp cho các tác vụ phân tích tài liệu hoặc tạo mã.
Các nhà phát triển hưởng lợi từ tính mô-đun này khi tinh chỉnh. Bạn có thể hoán đổi các chuyên gia hoặc điều chỉnh ngưỡng định tuyến để chuyên biệt hóa mô hình cho các lĩnh vực như tài chính hoặc chăm sóc sức khỏe. Về cơ bản, kiến trúc không chỉ tối ưu hóa tính toán mà còn thúc đẩy khả năng thích ứng. Với những hiểu biết này, giờ đây bạn sẽ chuyển sang cách các yếu tố này chuyển thành những cải thiện hiệu suất có thể đo lường được.
Đánh Giá Qwen3-Next-80B-A3B: Các Chỉ Số Hiệu Suất Quan Trọng
Các đánh giá thực nghiệm định vị Qwen3-Next-80B-A3B là một nhà lãnh đạo trong AI định hướng hiệu quả. Trên các điểm chuẩn tiêu chuẩn như MMLU và HumanEval, mô hình cơ sở vượt trội hơn Qwen3-32B mặc dù chỉ sử dụng một phần mười số tham số hoạt động. Cụ thể, nó đạt 78.5% trên MMLU cho kiến thức tổng quát, vượt qua các đối thủ cạnh tranh từ 2-3 điểm trong các tập hợp con suy luận.
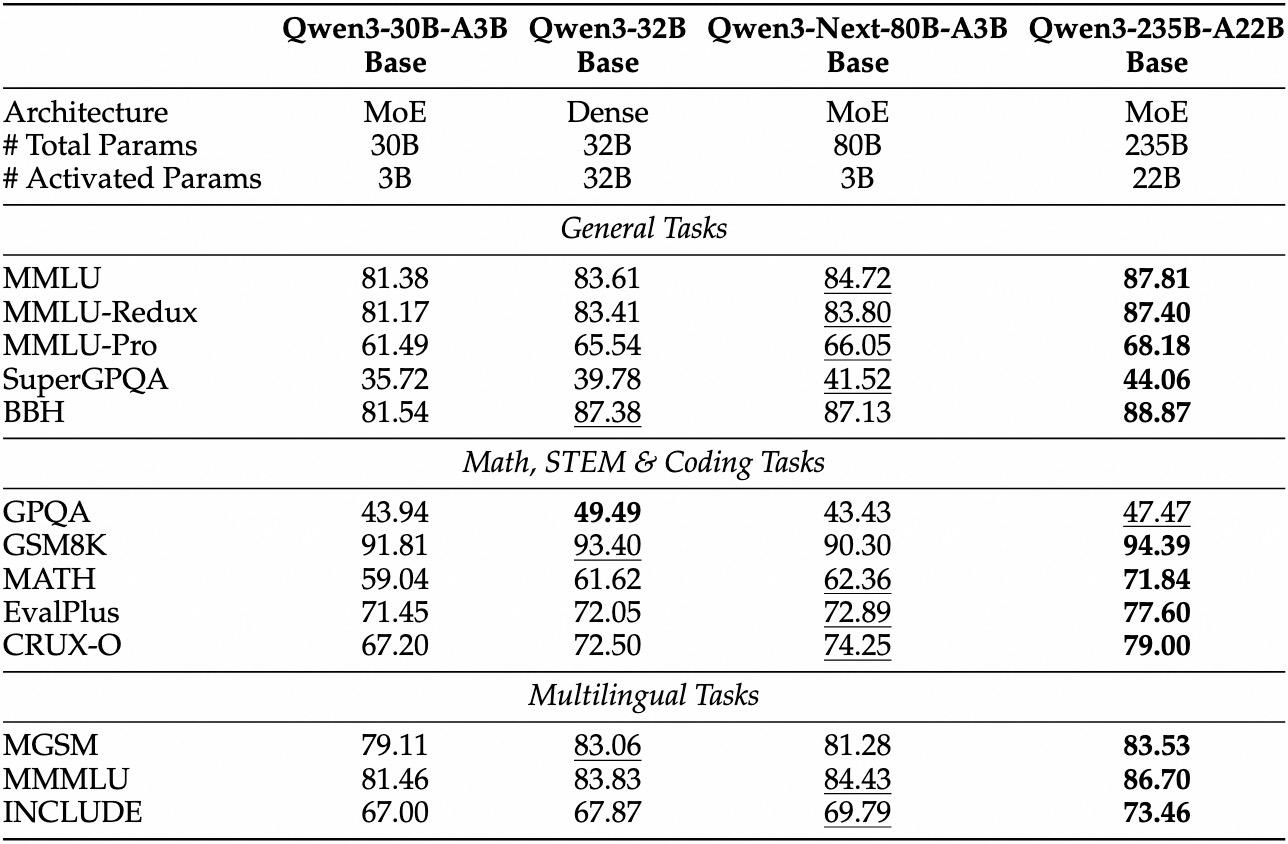
Đối với biến thể hướng dẫn, các tác vụ đàm thoại cho thấy điểm mạnh trong việc tuân thủ hướng dẫn. Nó đạt 85% trên MT-Bench, thể hiện các cuộc đối thoại đa lượt mạch lạc. Trong khi đó, mô hình tư duy nổi bật trong các kịch bản chuỗi suy nghĩ, đạt 92% trên GSM8K cho các bài toán toán học—vượt trội hơn Qwen3-30B-A3B-Thinking 4%.
Tốc độ suy luận là một nền tảng tạo nên sức hấp dẫn của nó. Ở ngữ cảnh 4K, thông lượng giải mã đạt 4 lần so với Qwen3-32B, mở rộng lên 10 lần ở các độ dài lớn hơn. Các giai đoạn tiền xử lý, quan trọng cho việc xử lý lời nhắc, cho thấy cải thiện 7 lần, nhờ MoE thưa thớt. Mức tiêu thụ điện năng giảm tương ứng, với chi phí huấn luyện chỉ bằng 10% so với các mô hình dày đặc hơn.
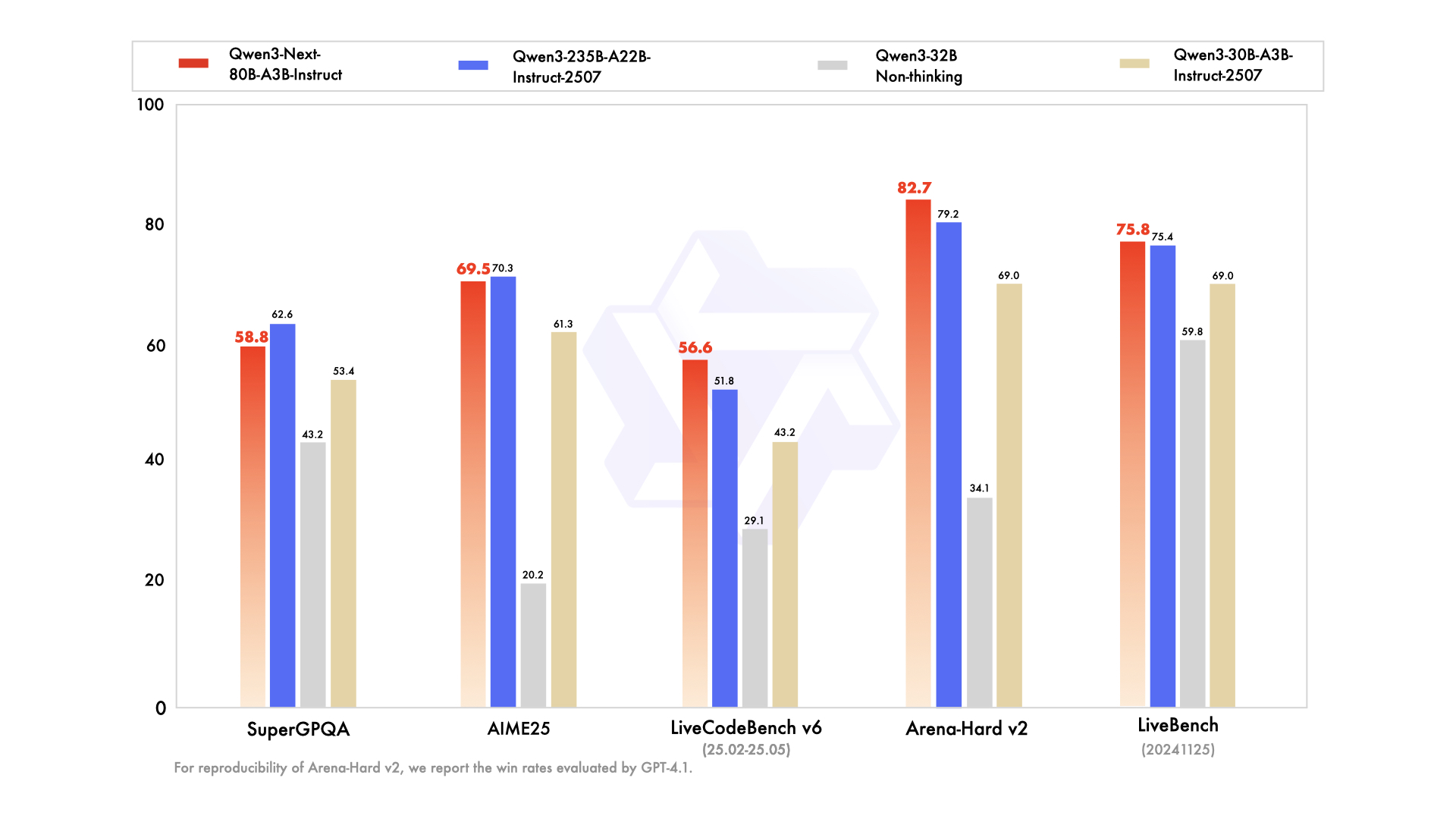
So sánh với các đối thủ cạnh tranh làm nổi bật lợi thế của nó. So với Llama 3.1-70B, Qwen3-Next-80B-A3B-Thinking dẫn đầu trong RULER (khả năng nhớ ngữ cảnh dài) 15%, ghi nhớ chính xác các chi tiết từ 128K token. So với DeepSeek-V2, nó cung cấp hỗ trợ đa ngôn ngữ tốt hơn mà không làm giảm tốc độ.

| Điểm chuẩn | Qwen3-Next-80B-A3B-Base | Qwen3-32B-Base | Llama 3.1-70B |
|---|---|---|---|
| MMLU | 78.5% | 76.2% | 77.8% |
| HumanEval | 82.1% | 79.5% | 81.2% |
| GSM8K | 91.2% | 88.7% | 90.1% |
| MT-Bench | 84.3% (Hướng dẫn) | 81.9% | 83.5% |
Bảng này nhấn mạnh hiệu suất vượt trội nhất quán. Do đó, các tổ chức áp dụng nó vào sản xuất, cân bằng chất lượng và chi phí. Chuyển từ lý thuyết sang thực hành, giờ đây bạn trang bị cho mình các công cụ truy cập API.
Thiết Lập Truy Cập API Qwen3-Next-80B-A3B: Điều Kiện Tiên Quyết và Xác Thực
Alibaba cung cấp API Qwen thông qua DashScope, nền tảng đám mây của họ, đảm bảo tích hợp liền mạch. Đầu tiên, hãy tạo một tài khoản Alibaba Cloud và điều hướng đến bảng điều khiển Model Studio. Chọn Qwen3-Next-80B-A3B từ danh sách mô hình—có sẵn ở các chế độ cơ sở, hướng dẫn và tư duy.
Lấy khóa API của bạn từ bảng điều khiển trong mục "API Keys." Khóa này xác thực các yêu cầu, với giới hạn tốc độ dựa trên cấp độ của bạn (gói miễn phí cung cấp 1 triệu token/tháng). Đối với các lệnh gọi tương thích với OpenAI, hãy đặt URL cơ sở thành https://dashscope.aliyuncs.com/compatible-mode/v1. Các điểm cuối DashScope gốc sử dụng https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation.
Cài đặt Python SDK qua pip: pip install dashscope. Thư viện này xử lý việc tuần tự hóa, thử lại và phân tích lỗi. Thay vào đó, hãy sử dụng các máy khách HTTP như requests cho các triển khai tùy chỉnh.
Các phương pháp bảo mật tốt nhất yêu cầu lưu trữ khóa trong các biến môi trường: export DASHSCOPE_API_KEY='your_key_here'. Do đó, mã của bạn vẫn có thể di chuyển giữa các môi trường. Với việc thiết lập hoàn tất, bạn tiến hành tạo lệnh gọi API đầu tiên của mình.
Hướng Dẫn Thực Hành: Sử Dụng API Qwen3-Next-80B-A3B Với Python và DashScope
DashScope đơn giản hóa các tương tác với Qwen3-Next-80B-A3B. Bắt đầu với một yêu cầu tạo cơ bản sử dụng biến thể hướng dẫn cho các phản hồi giống trò chuyện.
import os
from dashscope import Generation
os.environ['DASHSCOPE_API_KEY'] = 'your_api_key'
response = Generation.call(
model='qwen3-next-80b-a3b-instruct',
prompt='Explain the benefits of MoE architectures in LLMs.',
max_tokens=200,
temperature=0.7
)
if response.status_code == 200:
print(response.output['text'])
else:
print(f"Error: {response.message}")
Mã này gửi một lời nhắc và truy xuất tối đa 200 token. Mô hình phản hồi bằng một giải thích ngắn gọn, làm nổi bật những lợi ích về hiệu quả. Đối với chế độ tư duy, hãy chuyển sang 'qwen3-next-80b-a3b-thinking' và thêm hướng dẫn suy luận: "Hãy suy nghĩ từng bước trước khi trả lời."
Các tham số nâng cao tăng cường khả năng kiểm soát. Đặt top_p=0.9 cho lấy mẫu hạt nhân, hoặc repetition_penalty=1.1 để tránh lặp lại. Đối với ngữ cảnh dài, hãy chỉ định max_context_length=131072 để tận dụng khả năng 128K của mô hình.
Xử lý luồng cho các ứng dụng thời gian thực:
from dashscope import Streaming
for response in Streaming.call(
model='qwen3-next-80b-a3b-instruct',
prompt='Generate a Python function for sentiment analysis.',
max_tokens=500,
incremental_output=True
):
if response.status_code == 200:
print(response.output['text_delta'], end='', flush=True)
else:
print(f"Error: {response.message}")
break
Điều này tạo ra đầu ra từng token, lý tưởng cho các tích hợp giao diện người dùng. Xử lý lỗi bao gồm kiểm tra response.code cho các vấn đề về hạn mức (ví dụ: 10402 cho số dư không đủ).
Hơn nữa, việc gọi hàm mở rộng tiện ích. Định nghĩa các công cụ trong lược đồ JSON:
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}}
}
}
}]
response = Generation.call(
model='qwen3-next-80b-a3b-instruct',
prompt='What\'s the weather in Beijing?',
tools=tools,
tool_choice='auto'
)
Mô hình phân tích ý định và trả về một lệnh gọi công cụ, mà bạn thực thi bên ngoài. Mô hình này cung cấp sức mạnh cho các quy trình làm việc dựa trên tác nhân. Với những ví dụ này, bạn xây dựng các đường ống mạnh mẽ. Tiếp theo, hãy tích hợp Apidog để kiểm tra và tinh chỉnh các lệnh gọi này mà không cần mã hóa mỗi lần.
Nâng Cao Quy Trình Làm Việc Của Bạn: Tích Hợp Apidog Để Kiểm Thử API Qwen3-Next-80B-A3B
Apidog biến việc phát triển API thành một quy trình tinh gọn, đặc biệt đối với các điểm cuối AI như Qwen3-Next-80B-A3B. Nền tảng này kết hợp thiết kế, mô phỏng, kiểm thử và tài liệu trong một giao diện duy nhất, được hỗ trợ bởi AI để tự động hóa thông minh.
Bắt đầu bằng cách nhập lược đồ DashScope vào Apidog. Tạo một dự án mới, thêm điểm cuối POST https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation, và dán khóa API của bạn vào tiêu đề: X-DashScope-API-Key: your_key.
Thiết kế các yêu cầu trực quan: Đặt tham số mô hình thành 'qwen3-next-80b-a3b-instruct', nhập lời nhắc vào phần thân dưới dạng JSON {"input": {"messages": [{"role": "user", "content": "Your prompt here"}]}}. AI của Apidog đề xuất các trường hợp kiểm thử, tạo ra các biến thể như lời nhắc trường hợp biên hoặc mẫu nhiệt độ cao.
Chạy các bộ kiểm thử theo trình tự. Ví dụ, đánh giá độ trễ trên các nhiệt độ khác nhau:
- Kiểm thử 1: Nhiệt độ 0.1, độ dài lời nhắc 100 token.
- Kiểm thử 2: Nhiệt độ 1.0, ngữ cảnh 10K token.
Công cụ này theo dõi các chỉ số—thời gian phản hồi, mức sử dụng token, tỷ lệ lỗi—và trực quan hóa các xu hướng trong bảng điều khiển. Mô phỏng phản hồi để phát triển ngoại tuyến: Apidog mô phỏng đầu ra của Qwen dựa trên dữ liệu lịch sử, tăng tốc việc xây dựng giao diện người dùng.
Tài liệu được tạo tự động từ các bộ sưu tập của bạn. Xuất các thông số kỹ thuật OpenAPI với các ví dụ, bao gồm các chi tiết cụ thể của Qwen3-Next-80B-A3B như ghi chú định tuyến MoE. Các tính năng cộng tác cho phép các nhóm chia sẻ môi trường, đảm bảo kiểm thử nhất quán.
Trong một kịch bản, một nhà phát triển kiểm thử các lời nhắc đa ngôn ngữ. AI của Apidog phát hiện sự không nhất quán, đề xuất các bản sửa lỗi như thêm gợi ý ngôn ngữ. Kết quả là, thời gian tích hợp giảm 40%, theo báo cáo của người dùng. Đối với kiểm thử AI cụ thể, hãy tận dụng khả năng tạo dữ liệu thông minh của nó: Nhập một lược đồ, và nó sẽ tạo ra các lời nhắc thực tế mô phỏng lưu lượng truy cập sản xuất.
Hơn nữa, Apidog hỗ trợ các hook CI/CD, chạy các kiểm thử API trong các đường ống. Kết nối với GitHub Actions để tự động hóa xác thực sau triển khai. Cách tiếp cận vòng lặp kín này giảm thiểu lỗi trong các ứng dụng được hỗ trợ bởi Qwen.
Các Chiến Lược Nâng Cao: Tối Ưu Hóa Lệnh Gọi API Qwen3-Next-80B-A3B Cho Sản Xuất
Tối ưu hóa nâng cao việc sử dụng cơ bản lên độ tin cậy cấp doanh nghiệp. Đầu tiên, hãy nhóm các yêu cầu lại khi có thể—DashScope hỗ trợ tối đa 10 lời nhắc cho mỗi lệnh gọi, giảm chi phí cho các tác vụ song song như trang trại tóm tắt.
Theo dõi kinh tế token: Mô hình tính phí theo từng tham số hoạt động, vì vậy các lời nhắc ngắn gọn sẽ mang lại tiết kiệm. Sử dụng result_format='message' của API cho các đầu ra có cấu trúc, phân tích cú pháp JSON trực tiếp để tránh xử lý hậu kỳ.
import time
from dashscope import Generation
def call_with_retry(prompt, max_retries=3):
for attempt in range(max_retries):
response = Generation.call(model='qwen3-next-80b-a3b-instruct', prompt=prompt)
if response.status_code == 200:
return response
time.sleep(2 ** attempt)
raise Exception("Max retries exceeded")
Điều này xử lý các lỗi tạm thời như giới hạn tốc độ 429. Mở rộng theo chiều ngang bằng cách phân phối các lệnh gọi trên các khu vực—DashScope cung cấp các điểm cuối ở Singapore và Hoa Kỳ.
Các cân nhắc về bảo mật bao gồm làm sạch đầu vào để ngăn chặn tấn công prompt injection. Xác thực đầu vào của người dùng dựa trên danh sách trắng trước khi chuyển tiếp đến API. Ngoài ra, ghi nhật ký phản hồi ẩn danh để kiểm toán, tuân thủ GDPR.
Trong các trường hợp biên, như ngữ cảnh siêu dài, hãy chia nhỏ đầu vào và chuỗi dự đoán. Biến thể tư duy hỗ trợ ở đây: Nhắc với "Bước 1: Phân tích phần A; Bước 2: Tổng hợp với B." Điều này duy trì tính mạch lạc trên hơn 100K token.
Các nhà phát triển cũng khám phá việc tinh chỉnh thông qua nền tảng của Alibaba, mặc dù người dùng API vẫn tuân thủ kỹ thuật lời nhắc. Do đó, những chiến thuật này đảm bảo các triển khai có khả năng mở rộng, an toàn.
Tóm Lược: Tại Sao Qwen3-Next-80B-A3B Xứng Đáng Được Bạn Quan Tâm
Qwen3-Next-80B-A3B định nghĩa lại AI hiệu quả với MoE thưa thớt, các cổng lai và các điểm chuẩn vượt trội. Các nhà phát triển khai thác API của nó thông qua DashScope để tạo mẫu nhanh chóng, được tăng cường bởi các công cụ như Apidog để kiểm thử nghiêm ngặt.
Giờ đây bạn đã có bản thiết kế: từ những sắc thái kiến trúc đến tối ưu hóa sản xuất. Hãy triển khai những hiểu biết này để xây dựng các hệ thống nhanh hơn, thông minh hơn. Hãy thử nghiệm ngay hôm nay—tương lai của trí tuệ có thể mở rộng đang chờ đợi.