Nhóm Qwen tại Alibaba Cloud đã phát hành hai bổ sung mạnh mẽ cho dòng mô hình ngôn ngữ lớn (LLM) của họ: Qwen3-4B-Instruct-2507 và Qwen3-4B-Thinking-2507. Các mô hình này mang lại những tiến bộ đáng kể trong khả năng suy luận, tuân thủ hướng dẫn và hiểu ngữ cảnh dài, với hỗ trợ gốc cho độ dài ngữ cảnh 256K token. Được thiết kế cho các nhà phát triển, nhà nghiên cứu và những người đam mê AI, các mô hình này cung cấp khả năng mạnh mẽ cho các tác vụ từ lập trình đến giải quyết vấn đề phức tạp. Ngoài ra, các công cụ như Apidog, một nền tảng quản lý API miễn phí, có thể hợp lý hóa việc kiểm thử và tích hợp các mô hình này vào ứng dụng của bạn.
Tìm hiểu các mô hình Qwen3-4B
Dòng Qwen3 đại diện cho sự phát triển mới nhất trong dòng mô hình ngôn ngữ lớn của Alibaba Cloud, kế nhiệm dòng Qwen2.5. Cụ thể, Qwen3-4B-Instruct-2507 và Qwen3-4B-Thinking-2507 được điều chỉnh cho các trường hợp sử dụng riêng biệt: mô hình trước vượt trội trong đối thoại đa năng và tuân thủ hướng dẫn, trong khi mô hình sau được tối ưu hóa cho các tác vụ suy luận phức tạp. Cả hai mô hình đều hỗ trợ độ dài ngữ cảnh gốc 262.144 token, cho phép chúng xử lý các bộ dữ liệu lớn, tài liệu dài hoặc các cuộc hội thoại đa lượt một cách dễ dàng. Hơn nữa, khả năng tương thích của chúng với các framework như Hugging Face Transformers và các công cụ triển khai như Apidog giúp chúng dễ tiếp cận cho cả ứng dụng cục bộ và trên nền tảng đám mây.
Qwen3-4B-Instruct-2507: Tối ưu hóa hiệu quả
Mô hình Qwen3-4B-Instruct-2507 hoạt động ở chế độ không suy nghĩ (non-thinking mode), tập trung vào các phản hồi chất lượng cao, hiệu quả cho các tác vụ đa năng. Mô hình này đã được tinh chỉnh để nâng cao khả năng tuân thủ hướng dẫn, suy luận logic, hiểu văn bản và khả năng đa ngôn ngữ. Đáng chú ý, nó không tạo ra các khối <think></think>, làm cho nó lý tưởng cho các tình huống ưu tiên câu trả lời nhanh, trực tiếp hơn là suy luận từng bước.
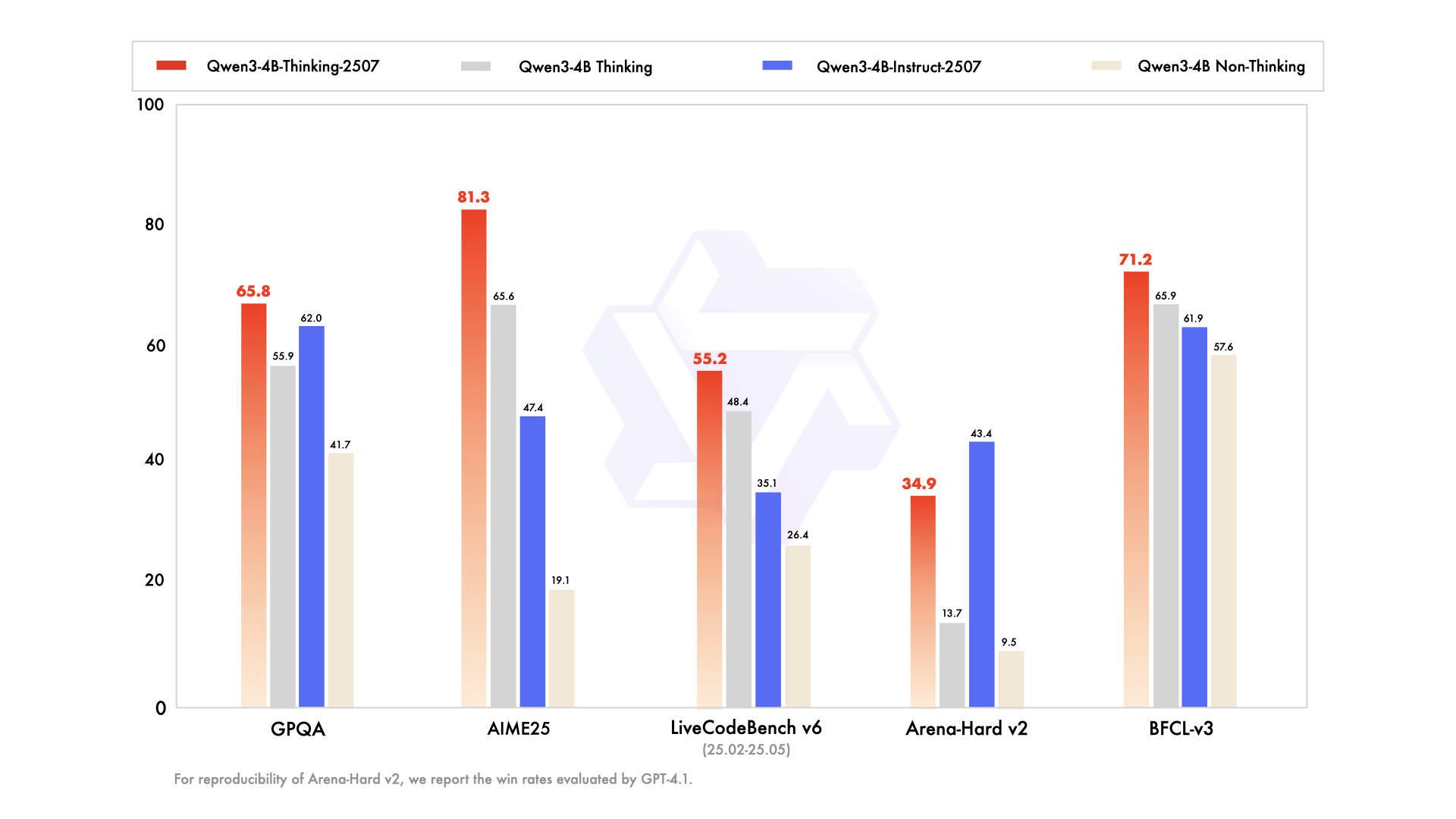
Các cải tiến chính bao gồm:
- Cải thiện khả năng chung: Mô hình thể hiện hiệu suất vượt trội trong toán học, khoa học, lập trình và sử dụng công cụ, làm cho nó linh hoạt cho các ứng dụng kỹ thuật.
- Hỗ trợ đa ngôn ngữ: Nó bao gồm hơn 100 ngôn ngữ và phương ngữ, đảm bảo hiệu suất mạnh mẽ trong các ứng dụng toàn cầu.
- Hiểu ngữ cảnh dài: Với độ dài ngữ cảnh 256K token, nó xử lý các đầu vào mở rộng, chẳng hạn như tài liệu pháp lý hoặc cơ sở mã dài, mà không bị cắt bớt.
- Căn chỉnh với sở thích người dùng: Mô hình cung cấp các phản hồi tự nhiên và hấp dẫn hơn, vượt trội trong viết sáng tạo và đối thoại đa lượt.
Đối với các nhà phát triển tích hợp mô hình này vào API, Apidog cung cấp giao diện thân thiện với người dùng để kiểm thử và quản lý các điểm cuối API, đảm bảo triển khai liền mạch. Hiệu quả này làm cho Qwen3-4B-Instruct-2507 trở thành lựa chọn hàng đầu cho các ứng dụng yêu cầu phản hồi nhanh chóng, chính xác.
Qwen3-4B-Thinking-2507: Được xây dựng cho suy luận sâu
Ngược lại, Qwen3-4B-Thinking-2507 được thiết kế cho các tác vụ đòi hỏi suy luận chuyên sâu, chẳng hạn như giải quyết vấn đề logic, toán học và các bài kiểm tra học thuật. Mô hình này hoạt động độc quyền ở chế độ suy nghĩ (thinking mode), tự động kết hợp các quy trình chuỗi suy nghĩ (CoT) để phân tích các vấn đề phức tạp. Đầu ra của nó có thể bao gồm thẻ </think> đóng mà không có thẻ <think> mở, vì mẫu trò chuyện mặc định nhúng hành vi suy nghĩ.
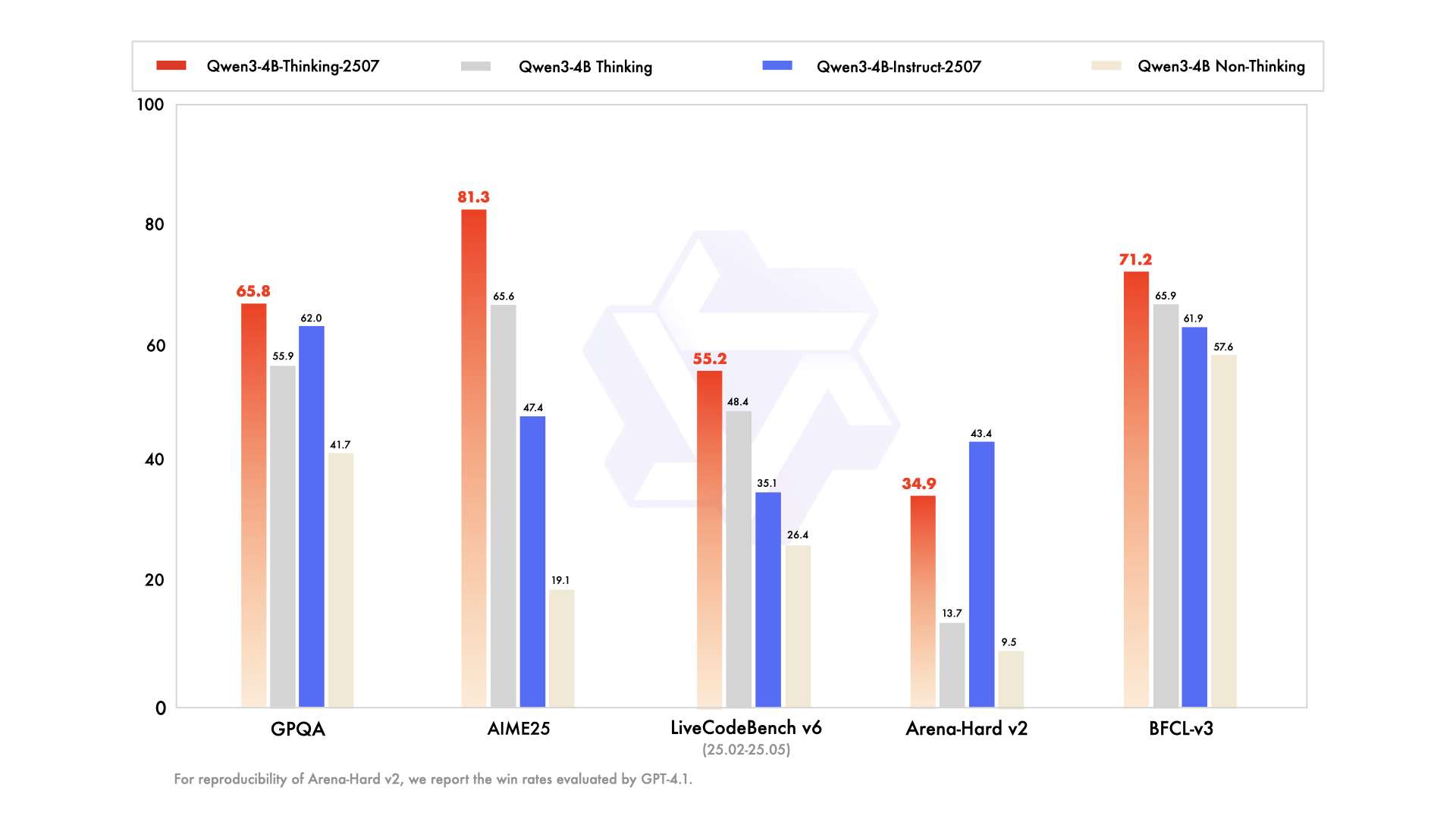
Các cải tiến chính bao gồm:
- Khả năng suy luận nâng cao: Mô hình đạt được kết quả tiên tiến nhất trong số các mô hình suy nghĩ mã nguồn mở, đặc biệt trong các lĩnh vực STEM và lập trình.
- Tăng cường độ sâu suy nghĩ: Nó vượt trội trong các tác vụ yêu cầu suy luận cấp chuyên gia của con người, với độ dài suy nghĩ mở rộng để phân tích kỹ lưỡng.
- Độ dài ngữ cảnh 256K: Giống như phiên bản Instruct của nó, nó hỗ trợ các cửa sổ ngữ cảnh lớn, lý tưởng để xử lý các bộ dữ liệu lớn hoặc các truy vấn phức tạp.
- Tích hợp công cụ: Mô hình tận dụng các công cụ như Qwen-Agent để hợp lý hóa quy trình làm việc của tác nhân, nâng cao tiện ích của nó trong các hệ thống tự động.
Đối với các nhà phát triển làm việc với các ứng dụng chuyên sâu về suy luận, Apidog có thể tạo điều kiện kiểm thử API, đảm bảo rằng đầu ra của mô hình phù hợp với kết quả mong đợi. Mô hình này đặc biệt phù hợp cho môi trường nghiên cứu và các kịch bản giải quyết vấn đề phức tạp.
Thông số kỹ thuật và kiến trúc
Cả hai mô hình Qwen3-4B đều là một phần của dòng Qwen3, bao gồm các kiến trúc dày đặc (dense) và hỗn hợp chuyên gia (MoE). Chỉ định 4B đề cập đến 4 tỷ tham số của chúng, đạt được sự cân bằng giữa hiệu quả tính toán và hiệu suất. Do đó, các mô hình này có thể truy cập được trên phần cứng cấp người tiêu dùng, không giống như các mô hình lớn hơn như Qwen3-235B-A22B, đòi hỏi tài nguyên đáng kể.
Điểm nổi bật về kiến trúc
- Thiết kế mô hình dày đặc: Không giống như các mô hình MoE, các mô hình Qwen3-4B sử dụng kiến trúc dày đặc, đảm bảo hiệu suất nhất quán trên các tác vụ mà không cần kích hoạt tham số chọn lọc.
- YaRN để mở rộng ngữ cảnh: Các mô hình tận dụng YaRN để mở rộng độ dài ngữ cảnh của chúng từ 32.768 lên 262.144 token, cho phép xử lý ngữ cảnh dài mà không làm giảm đáng kể hiệu suất.
- Quy trình đào tạo: Nhóm Qwen đã sử dụng quy trình đào tạo bốn giai đoạn, bao gồm khởi động chuỗi suy nghĩ dài (long chain-of-thought cold start), học tăng cường dựa trên suy luận, hợp nhất chế độ suy nghĩ và học tăng cường chung. Cách tiếp cận này nâng cao cả khả năng suy luận và đối thoại.
- Hỗ trợ lượng tử hóa: Cả hai mô hình đều hỗ trợ lượng tử hóa FP8, giảm yêu cầu bộ nhớ trong khi vẫn duy trì độ chính xác. Ví dụ, Qwen3-4B-Thinking-2507-FP8 có sẵn cho các môi trường bị hạn chế tài nguyên.
Yêu cầu phần cứng
Để chạy các mô hình này một cách hiệu quả, hãy xem xét những điều sau:
- Bộ nhớ GPU: Khuyến nghị tối thiểu 8GB VRAM cho các mô hình được lượng tử hóa FP8, trong khi các mô hình bfloat16 có thể yêu cầu 16GB trở lên.
- RAM: Để có hiệu suất tối ưu, 16GB bộ nhớ thống nhất (VRAM + RAM) là đủ cho hầu hết các tác vụ.
- Framework suy luận: Cả hai mô hình đều tương thích với Hugging Face Transformers (phiên bản ≥4.51.0), vLLM (≥0.8.5) và SGLang (≥0.4.6.post1). Các công cụ cục bộ như Ollama và LMStudio cũng hỗ trợ Qwen3.
Đối với các nhà phát triển triển khai các mô hình này, Apidog đơn giản hóa quy trình bằng cách cung cấp các công cụ để giám sát và kiểm thử hiệu suất API, đảm bảo tích hợp hiệu quả với các framework suy luận.
Tích hợp với Hugging Face và ModelScope
Các mô hình Qwen3-4B có sẵn trên cả Hugging Face và ModelScope, mang lại sự linh hoạt cho các nhà phát triển. Dưới đây, chúng tôi cung cấp một đoạn mã để minh họa cách sử dụng Qwen3-4B-Instruct-2507 với Hugging Face Transformers.

from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-4B-Instruct-2507"tokenizer = AutoTokenizer.from_pretrained(model_name)model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto", device_map="auto")
prompt = "Write a Python function to calculate Fibonacci numbers."messages = [{"role": "user", "content": prompt}]text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(**model_inputs, max_new_tokens=16384)output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()content = tokenizer.decode(output_ids, skip_special_tokens=True)print("Generated Code:\n", content)Đối với Qwen3-4B-Thinking-2507, cần phân tích bổ sung để xử lý nội dung suy nghĩ:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-4B-Thinking-2507"tokenizer = AutoTokenizer.from_pretrained(model_name)model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto", device_map="auto")
prompt = "Solve the equation 2x^2 + 3x - 5 = 0."messages = [{"role": "user", "content": prompt}]text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(**model_inputs, max_new_tokens=32768)output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
try:index = len(output_ids) - output_ids[::-1].index(151668) # tokenexcept ValueError:index = 0thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")print("Thinking Process:\n", thinking_content)print("Solution:\n", content)Các đoạn mã này minh họa sự dễ dàng tích hợp các mô hình Qwen vào quy trình làm việc Python. Đối với các triển khai dựa trên API, Apidog có thể giúp kiểm thử các điểm cuối này, đảm bảo hiệu suất đáng tin cậy.
Tối ưu hóa hiệu suất và các phương pháp hay nhất
Để tối đa hóa hiệu suất của các mô hình Qwen3-4B, hãy xem xét các khuyến nghị sau:
- Tham số lấy mẫu: Đối với Qwen3-4B-Instruct-2507, sử dụng
temperature=0.7,top_p=0.8,top_k=20vàmin_p=0. Đối với Qwen3-4B-Thinking-2507, sử dụngtemperature=0.6,top_p=0.95,top_k=20vàmin_p=0. Tránh giải mã tham lam để ngăn ngừa suy giảm hiệu suất. - Quản lý độ dài ngữ cảnh: Nếu gặp vấn đề hết bộ nhớ, hãy giảm độ dài ngữ cảnh xuống 32.768 token. Tuy nhiên, đối với các tác vụ suy luận, hãy duy trì độ dài ngữ cảnh trên 131.072 token.
- Hình phạt hiện diện: Đặt
presence_penaltytrong khoảng từ 0 đến 2 để giảm lặp lại, nhưng tránh các giá trị cao để ngăn ngừa trộn lẫn ngôn ngữ. - Framework suy luận: Sử dụng vLLM hoặc SGLang để suy luận thông lượng cao và tận dụng Apidog để giám sát hiệu suất API.
So sánh Qwen3-4B-Instruct-2507 và Qwen3-4B-Thinking-2507
Mặc dù cả hai mô hình đều chia sẻ cùng một kiến trúc 4 tỷ tham số, nhưng triết lý thiết kế của chúng khác nhau:
- Qwen3-4B-Instruct-2507: Ưu tiên tốc độ và hiệu quả, làm cho nó phù hợp với chatbot, hỗ trợ khách hàng và các ứng dụng đa năng.
- Qwen3-4B-Thinking-2507: Tập trung vào suy luận sâu, lý tưởng cho nghiên cứu học thuật, giải quyết vấn đề phức tạp và các tác vụ yêu cầu quy trình chuỗi suy nghĩ.
Các nhà phát triển có thể chuyển đổi giữa các chế độ bằng cách sử dụng lời nhắc /think và /no_think, cho phép linh hoạt dựa trên yêu cầu tác vụ. Apidog có thể hỗ trợ kiểm thử các chuyển đổi chế độ này trong các ứng dụng điều khiển bằng API.
Hỗ trợ cộng đồng và hệ sinh thái
Các mô hình Qwen3-4B được hưởng lợi từ một hệ sinh thái mạnh mẽ, với sự hỗ trợ từ Hugging Face, ModelScope và các công cụ như Ollama, LMStudio và llama.cpp. Bản chất mã nguồn mở của các mô hình này, được cấp phép theo Apache 2.0, khuyến khích sự đóng góp và tinh chỉnh của cộng đồng. Ví dụ, Unsloth cung cấp các công cụ để tinh chỉnh nhanh hơn 2 lần với ít VRAM hơn 70%, làm cho các mô hình này dễ tiếp cận hơn với nhiều đối tượng.
Kết luận
Các mô hình Qwen3-4B-Instruct-2507 và Qwen3-4B-Thinking-2507 đánh dấu một bước nhảy vọt đáng kể trong dòng Qwen của Alibaba Cloud, cung cấp các khả năng vô song trong việc tuân thủ hướng dẫn, suy luận và xử lý ngữ cảnh dài. Với độ dài ngữ cảnh 256K token, hỗ trợ đa ngôn ngữ và khả năng tương thích với các công cụ như Apidog, các mô hình này trao quyền cho các nhà phát triển xây dựng các ứng dụng thông minh, có khả năng mở rộng. Cho dù bạn đang tạo mã, giải phương trình hay tạo chatbot đa ngôn ngữ, các mô hình này đều mang lại hiệu suất vượt trội. Hãy bắt đầu khám phá tiềm năng của chúng ngay hôm nay và sử dụng Apidog để hợp lý hóa các tích hợp API của bạn để có trải nghiệm phát triển liền mạch.