
Nhóm Qwen của Alibaba một lần nữa đã đẩy xa ranh giới của trí tuệ nhân tạo với sự ra mắt của mô hình Qwen2.5-VL-32B-Instruct, một mô hình ngôn ngữ-đối tượng (VLM) đột phá hứa hẹn sẽ thông minh hơn và nhẹ hơn.
Được công bố vào ngày 24 tháng 3 năm 2025, mô hình 32 tỷ tham số này tạo ra sự cân bằng tối ưu giữa hiệu suất và hiệu quả, làm cho nó trở thành lựa chọn lý tưởng cho các nhà phát triển và nhà nghiên cứu. Dựa trên thành công của loạt Qwen2.5-VL, phiên bản mới này giới thiệu những tiến bộ đáng kể trong lý luận toán học, xác định sở thích của con người và các nhiệm vụ thị giác, tất cả đều duy trì kích thước dễ quản lý cho việc triển khai tại chỗ.
Đối với các nhà phát triển khao khát tích hợp mô hình mạnh mẽ này vào các dự án của họ, việc khám phá các công cụ API mạnh mẽ là rất cần thiết. Đó là lý do tại sao chúng tôi khuyên bạn nên tải xuống Apidog miễn phí — một nền tảng phát triển API dễ sử dụng giúp đơn giản hóa việc kiểm tra và tích hợp các mô hình như Qwen vào ứng dụng của bạn. Với Apidog, bạn có thể tương tác mượt mà với API Qwen, đơn giản hóa quy trình làm việc và mở khóa tiềm năng đầy đủ của VLM sáng tạo này. Tải xuống Apidog ngay hôm nay và bắt đầu xây dựng các ứng dụng thông minh hơn!
Công cụ API này cho phép bạn kiểm tra và gỡ lỗi các điểm cuối của mô hình dễ dàng. Tải xuống Apidog miễn phí ngay hôm nay và tinh giản quy trình làm việc của bạn trong khi khám phá khả năng của Mistral Small 3.1!
Qwen2.5-VL-32B: Một Mô Hình Ngôn Ngữ-Thị Giác Thông Minh Hơn
Điều Gì Làm Qwen2.5-VL-32B Trở Nên Độc Đáo?
Qwen2.5-VL-32B nổi bật như một mô hình ngôn ngữ-đối tượng 32 tỷ tham số được thiết kế để giải quyết những hạn chế của cả các mô hình lớn hơn và nhỏ hơn trong gia đình Qwen. Trong khi các mô hình 72 tỷ tham số như Qwen2.5-VL-72B cung cấp khả năng mạnh mẽ, thì chúng thường yêu cầu tài nguyên tính toán lớn, khiến chúng không thực tế cho việc triển khai tại chỗ. Ngược lại, các mô hình 7 tỷ tham số, mặc dù nhẹ hơn, có thể thiếu độ sâu cần thiết cho các nhiệm vụ phức tạp. Qwen2.5-VL-32B lấp đầy khoảng trống này bằng cách cung cấp hiệu suất cao với kích thước dễ quản lý hơn.
Mô hình này dựa trên loạt Qwen2.5-VL, đã nhận được sự tán thưởng rộng rãi nhờ khả năng đa phương thức của nó. Tuy nhiên, Qwen2.5-VL-32B giới thiệu những cải tiến quan trọng, bao gồm tối ưu hóa thông qua học tăng cường (RL). Cách tiếp cận này cải thiện sự đồng nhất của mô hình với sở thích của con người, đảm bảo đầu ra chi tiết và thân thiện với người dùng hơn. Thêm vào đó, mô hình chứng minh khả năng lý luận toán học vượt trội, một tính năng quan trọng cho các nhiệm vụ liên quan đến giải quyết vấn đề phức tạp và phân tích dữ liệu.

Cải Tiến Kỹ Thuật Chính
Qwen2.5-VL-32B tận dụng học tăng cường để tinh chỉnh phong cách đầu ra của nó, làm cho các phản hồi trở nên mạch lạc, chi tiết và được định dạng tốt cho tương tác với con người. Hơn nữa, khả năng lý luận toán học của nó đã thấy sự cải thiện đáng kể, như được chứng minh qua hiệu suất của nó trên các benchmark như MathVista và MMMU. Những cải tiến này xuất phát từ các quy trình đào tạo được tinh chỉnh với trọng tâm là độ chính xác và suy luận logic, đặc biệt trong các ngữ cảnh đa phương thức nơi văn bản và dữ liệu hình ảnh giao thoa.
Mô hình cũng xuất sắc trong việc hiểu và lý luận hình ảnh chi tiết, cho phép phân tích chính xác nội dung hình ảnh, chẳng hạn như biểu đồ, đồ thị và tài liệu. Khả năng này đưa Qwen2.5-VL-32B trở thành một ứng cử viên hàng đầu cho các ứng dụng yêu cầu suy luận logic hình ảnh tiên tiến và nhận diện nội dung.
Các Tiêu Chí Hiệu Suất Qwen2.5-VL-32B: Vượt Qua Các Mô Hình Lớn Hơn
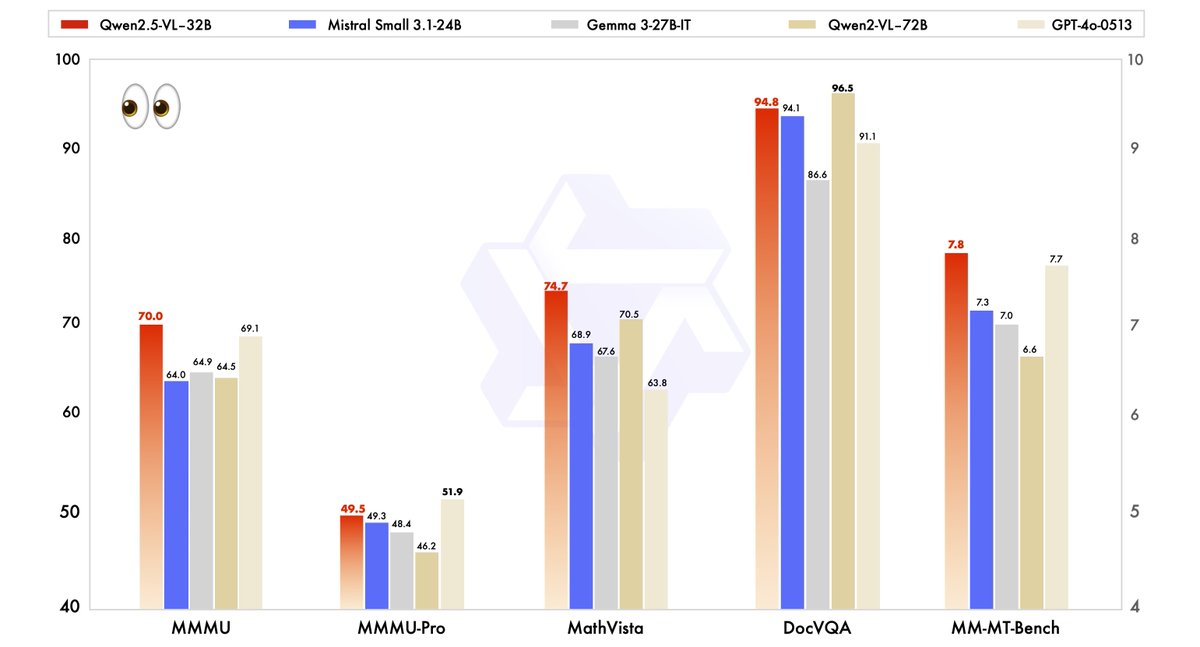
Hiệu suất của Qwen2.5-VL-32B đã được đánh giá nghiêm ngặt so với các mô hình hiện đại, bao gồm cả người anh lớn hơn của nó, Qwen2.5-VL-72B, cũng như các đối thủ như Mistral-Small-3.1–24B và Gemma-3–27B-IT. Kết quả nổi bật khả năng vượt trội của mô hình trong một số lĩnh vực chính.
- MMMU (Định Nghĩa Ngôn Ngữ Nhiều Tác Vụ): Qwen2.5-VL-32B đạt được điểm số 70.0, vượt qua 64.5 của Qwen2.5-VL-72B. Tiêu chí này kiểm tra lý luận phức tạp, nhiều bước trên nhiều đầu việc khác nhau, chứng minh khả năng nhận thức được cải thiện của mô hình.
- MathVista: Với điểm số 74.7, Qwen2.5-VL-32B vượt trội so với 70.5 của Qwen2.5-VL-72B, nhấn mạnh sức mạnh của nó trong các nhiệm vụ lý luận toán học và hình ảnh.
- MM-MT-Bench: Tiêu chí đánh giá trải nghiệm người dùng chủ quan này cho thấy Qwen2.5-VL-32B dẫn trước người tiền nhiệm của mình một cách đáng kể, phản ánh sự đồng nhất cải thiện với sở thích của con người.
- Các Nhiệm Vụ Dựa Trên Văn Bản (ví dụ: MMLU, MATH, HumanEval): Mô hình cạnh tranh hiệu quả với các mô hình lớn hơn như GPT-4o-Mini, đạt được điểm số 78.4 trên MMLU, 82.2 trên MATH và 91.5 trên HumanEval, mặc dù số lượng tham số của nó nhỏ hơn.
Các tiêu chí này cho thấy rằng Qwen2.5-VL-32B không chỉ tương đương mà thường vượt trội hơn hiệu suất của các mô hình lớn hơn, tất cả đều yêu cầu ít tài nguyên tính toán hơn. Sự cân bằng giữa sức mạnh và hiệu quả khiến nó trở thành một lựa chọn hấp dẫn cho các nhà phát triển và nhà nghiên cứu làm việc với phần cứng hạn chế.
Tại Sao Kích Thước Quan Trọng: Lợi Thế 32B
Kích thước 32 tỷ tham số của Qwen2.5-VL-32B tạo ra một điểm ngọt cho việc triển khai tại chỗ. Không giống như các mô hình 72B, yêu cầu tài nguyên GPU rộng lớn, mô hình nhẹ hơn này tích hợp mượt mà với các động cơ suy diễn như SGLang và vLLM, như đã lưu ý trong các kết quả tìm kiếm liên quan. Tính tương thích này đảm bảo triển khai nhanh hơn và tiêu thụ bộ nhớ thấp hơn, làm cho nó dễ tiếp cận với nhiều người dùng hơn, từ các công ty khởi nghiệp đến các doanh nghiệp lớn.
Hơn nữa, việc tối ưu hóa của mô hình cho tốc độ và hiệu quả không đánh đổi khả năng của nó. Khả năng xử lý các nhiệm vụ đa phương thức — chẳng hạn như nhận diện đối tượng, phân tích biểu đồ và xử lý các đầu ra có cấu trúc như hóa đơn và bảng — vẫn rất mạnh mẽ, định vị nó như một công cụ linh hoạt cho các ứng dụng trong thế giới thực.

Chạy Qwen2.5-VL-32B Tại Chỗ Với MLX
Để chạy mô hình mạnh mẽ này tại chỗ trên máy Mac của bạn với Apple Silicon, hãy thực hiện theo các bước sau:
Yêu Cầu Hệ Thống
- Một máy Mac với Apple Silicon (chip M1, M2 hoặc M3)
- Ít nhất 32GB RAM (64GB được khuyên dùng)
- 60GB+ dung lượng lưu trữ trống
- macOS Sonoma hoặc mới hơn
Các Bước Cài Đặt
- Cài đặt các phụ thuộc của Python
pip install mlx mlx-llm transformers pillow
- Tải mô hình xuống
git lfs install
git clone https://huggingface.co/Qwen/Qwen2.5-VL-32B-Instruct
- Chuyển đổi mô hình sang định dạng MLX
python -m mlx_llm.convert --model-name Qwen/Qwen2.5-VL-32B-Instruct --mlx-path ./qwen2.5-vl-32b-mlx
- Tạo một kịch bản đơn giản để tương tác với mô hình
import mlx.core as mx
from mlx_llm import load, generate
from PIL import Image
# Tải mô hình
model, tokenizer = load("./qwen2.5-vl-32b-mlx")
# Tải một hình ảnh
image = Image.open("path/to/your/image.jpg")
# Tạo một prompt với hình ảnh
prompt = "Bạn thấy gì trong hình ảnh này?"
outputs = generate(model, tokenizer, prompt=prompt, image=image, max_tokens=512)
print(outputs)
Các Ứng Dụng Thực Tế: Tận Dụng Qwen2.5-VL-32B
Các Nhiệm Vụ Thị Giác và Hơn Thế Nữa
Khả năng thị giác tiên tiến của Qwen2.5-VL-32B mở ra cánh cửa cho một loạt ứng dụng. Chẳng hạn, nó có thể phục vụ như một đại lý hình ảnh, tương tác một cách linh hoạt với giao diện máy tính hoặc điện thoại để thực hiện các nhiệm vụ như điều hướng hoặc trích xuất dữ liệu. Khả năng hiểu các video dài (lên đến một giờ) và xác định các đoạn liên quan càng nâng cao chức năng của nó trong phân tích video và định vị tạm thời.
Trong việc phân tích tài liệu, mô hình xuất sắc trong việc xử lý các nội dung đa cảnh, đa ngôn ngữ, bao gồm cả văn bản viết tay, bảng biểu, biểu đồ và công thức hóa học. Điều này làm cho nó có giá trị cho các ngành như tài chính, giáo dục và chăm sóc sức khỏe, nơi việc trích xuất dữ liệu có cấu trúc chính xác là rất quan trọng.
Lý Luận Văn Bản và Toán Học
Ngoài các nhiệm vụ thị giác, Qwen2.5-VL-32B tỏa sáng trong các ứng dụng dựa trên văn bản, đặc biệt là các ứng dụng liên quan đến lý luận toán học và lập trình. Điểm số cao của nó trên các benchmark như MATH và HumanEval cho thấy khả năng của nó trong việc giải quyết các bài toán đại số phức tạp, diễn giải đồ thị hàm và tạo ra các đoạn mã chính xác. Khả năng kép này trong thị giác và văn bản định vị Qwen2.5-VL-32B như một giải pháp toàn diện cho các thách thức AI đa phương thức.

Nơi Bạn Có Thể Sử Dụng Qwen2.5-VL-32B
Truy Cập Mã Nguồn Mở và API
Qwen2.5-VL-32B có sẵn theo giấy phép Apache 2.0, làm cho nó mã nguồn mở và dễ dàng truy cập cho các nhà phát triển toàn cầu. Bạn có thể truy cập mô hình thông qua một số nền tảng:
- Hugging Face: Mô hình được lưu trữ trên Hugging Face, nơi bạn có thể tải về để sử dụng tại chỗ hoặc tích hợp thông qua thư viện Transformers.
- ModelScope: Nền tảng ModelScope của Alibaba cung cấp một phương thức khác để truy cập và triển khai mô hình.
Để tích hợp một cách liền mạch, các nhà phát triển có thể sử dụng API Qwen, giúp đơn giản hóa việc tương tác với mô hình. Dù bạn đang xây dựng một ứng dụng tùy chỉnh hay thử nghiệm với các nhiệm vụ đa phương thức, API Qwen đảm bảo kết nối hiệu quả và hiệu suất mạnh mẽ.
Triển Khai Với Các Động Cơ Suy Diễn
Qwen2.5-VL-32B hỗ trợ triển khai với các động cơ suy diễn như SGLang và vLLM. Những công cụ này tối ưu hóa mô hình cho suy diễn nhanh, giảm độ trễ và tiêu thụ bộ nhớ. Bằng cách tận dụng những động cơ này, các nhà phát triển có thể triển khai mô hình trên phần cứng địa phương hoặc nền tảng đám mây, tùy chỉnh cho các trường hợp sử dụng cụ thể.
Để bắt đầu, hãy cài đặt các thư viện cần thiết (ví dụ: transformers, vllm) và theo dõi các hướng dẫn trên trang GitHub Qwen hoặc tài liệu Hugging Face. Quy trình này đảm bảo một sự tích hợp suôn sẻ, cho phép bạn khai thác tiềm năng đầy đủ của mô hình.
Tối Ưu Hóa Hiệu Suất Tại Chỗ
Khi chạy Qwen2.5-VL-32B tại chỗ, hãy xem xét các mẹo tối ưu hóa này:
- Quantization: Thêm cờ
--quantizetrong quá trình chuyển đổi để giảm yêu cầu bộ nhớ - Quản lý độ dài ngữ cảnh: Giới hạn số token đầu vào để có phản hồi nhanh hơn
- Đóng các ứng dụng tốn tài nguyên khi chạy mô hình
- Xử lý theo lô: Đối với nhiều hình ảnh, xử lý chúng theo lô thay vì từng cái một
Kết Luận: Tại Sao Qwen2.5-VL-32B Quan Trọng
Qwen2.5-VL-32B đại diện cho một cột mốc quan trọng trong sự phát triển của các mô hình ngôn ngữ-thị giác. Bằng cách kết hợp lập luận thông minh hơn, yêu cầu tài nguyên nhẹ hơn, và hiệu suất mạnh mẽ, mô hình 32 tỷ tham số này đáp ứng nhu cầu của cả các nhà phát triển và nhà nghiên cứu. Những tiến bộ của nó trong lý luận toán học, sự đồng nhất với sở thích của con người, và các nhiệm vụ thị giác đã định vị nó như một lựa chọn hàng đầu cho việc triển khai tại chỗ và các ứng dụng trong thế giới thực.
Dù bạn đang xây dựng các công cụ giáo dục, hệ thống thông tin doanh nghiệp, hoặc các giải pháp hỗ trợ khách hàng, Qwen2.5-VL-32B cung cấp tính linh hoạt và hiệu quả mà bạn cần. Với quyền truy cập thông qua các nền tảng mã nguồn mở và API Qwen, việc tích hợp mô hình này vào các dự án của bạn trở nên dễ dàng hơn bao giờ hết. Khi nhóm Qwen tiếp tục đổi mới, chúng tôi có thể kỳ vọng vào nhiều phát triển thú vị hơn trong tương lai của AI đa phương thức.
Công cụ API này cho phép bạn kiểm tra và gỡ lỗi các điểm cuối của mô hình dễ dàng. Tải xuống Apidog miễn phí ngay hôm nay và tinh giản quy trình làm việc của bạn trong khi khám phá khả năng của Mistral Small 3.1!