
Qwen-Image, một mô hình nền tảng hình ảnh MMDiT 20B tiên tiến từ nhóm Qwen của Alibaba Cloud, định nghĩa lại khả năng sáng tạo hình ảnh dựa trên AI. Ra mắt vào ngày 4 tháng 8 năm 2025, mô hình này mang đến khả năng vô song trong việc tạo ra hình ảnh chất lượng cao, hiển thị văn bản đa ngôn ngữ phức tạp và thực hiện chỉnh sửa hình ảnh chính xác. Cho dù bạn đang tạo hình ảnh tiếp thị năng động hay phân tích dữ liệu hình ảnh phức tạp, Qwen-Image trang bị cho các nhà phát triển những công cụ mạnh mẽ để biến ý tưởng thành hiện thực.
Qwen-Image là gì? Tổng quan kỹ thuật
Qwen-Image, một phần của chuỗi Qwen của Alibaba Cloud, là một mô hình biến đổi khuếch tán đa phương thức (MMDiT) với 20 tỷ tham số, được thiết kế cho cả việc tạo và chỉnh sửa hình ảnh. Không giống như các mô hình truyền thống chỉ tập trung vào việc tạo hình ảnh, Qwen-Image tích hợp khả năng hiển thị văn bản và hiểu hình ảnh tiên tiến, biến nó thành một công cụ đa năng cho các tác vụ sáng tạo và phân tích. Mô hình này, được mã nguồn mở theo giấy phép Apache 2.0, có thể truy cập thông qua các nền tảng như GitHub, Hugging Face và ModelScope, cho phép các nhà phát triển tích hợp nó vào các quy trình làm việc đa dạng.

Hơn nữa, Qwen-Image tận dụng một tập dữ liệu tiền huấn luyện mạnh mẽ, kết hợp hơn 30 nghìn tỷ token trên 119 ngôn ngữ, tập trung vào tiếng Trung và tiếng Anh. Tập dữ liệu mở rộng này, kết hợp với các kỹ thuật học tăng cường, cho phép mô hình xử lý các tác vụ phức tạp như hiển thị văn bản đa ngôn ngữ và thao tác đối tượng chính xác. Do đó, nó vượt trội hơn nhiều mô hình hiện có trên các điểm chuẩn như GenEval, DPG và LongText-Bench.
Các tính năng chính của Qwen-Image
Hiển thị văn bản vượt trội cho hình ảnh đa ngôn ngữ
Qwen-Image xuất sắc trong việc hiển thị văn bản phức tạp trong hình ảnh, một tính năng khiến nó khác biệt so với các đối thủ cạnh tranh. Nó hỗ trợ cả ngôn ngữ bảng chữ cái (ví dụ: tiếng Anh) và chữ tượng hình (ví dụ: tiếng Trung), đảm bảo tích hợp văn bản độ trung thực cao. Ví dụ, mô hình có thể tạo một áp phích phim với bố cục văn bản chính xác, chẳng hạn như tiêu đề “Imagination Unleashed” và phụ đề trên nhiều dòng, duy trì tính nhất quán về kiểu chữ. Khả năng này bắt nguồn từ việc huấn luyện trên các tập dữ liệu đa dạng, bao gồm LongText-Bench và ChineseWord, nơi nó đạt được hiệu suất tiên tiến nhất.
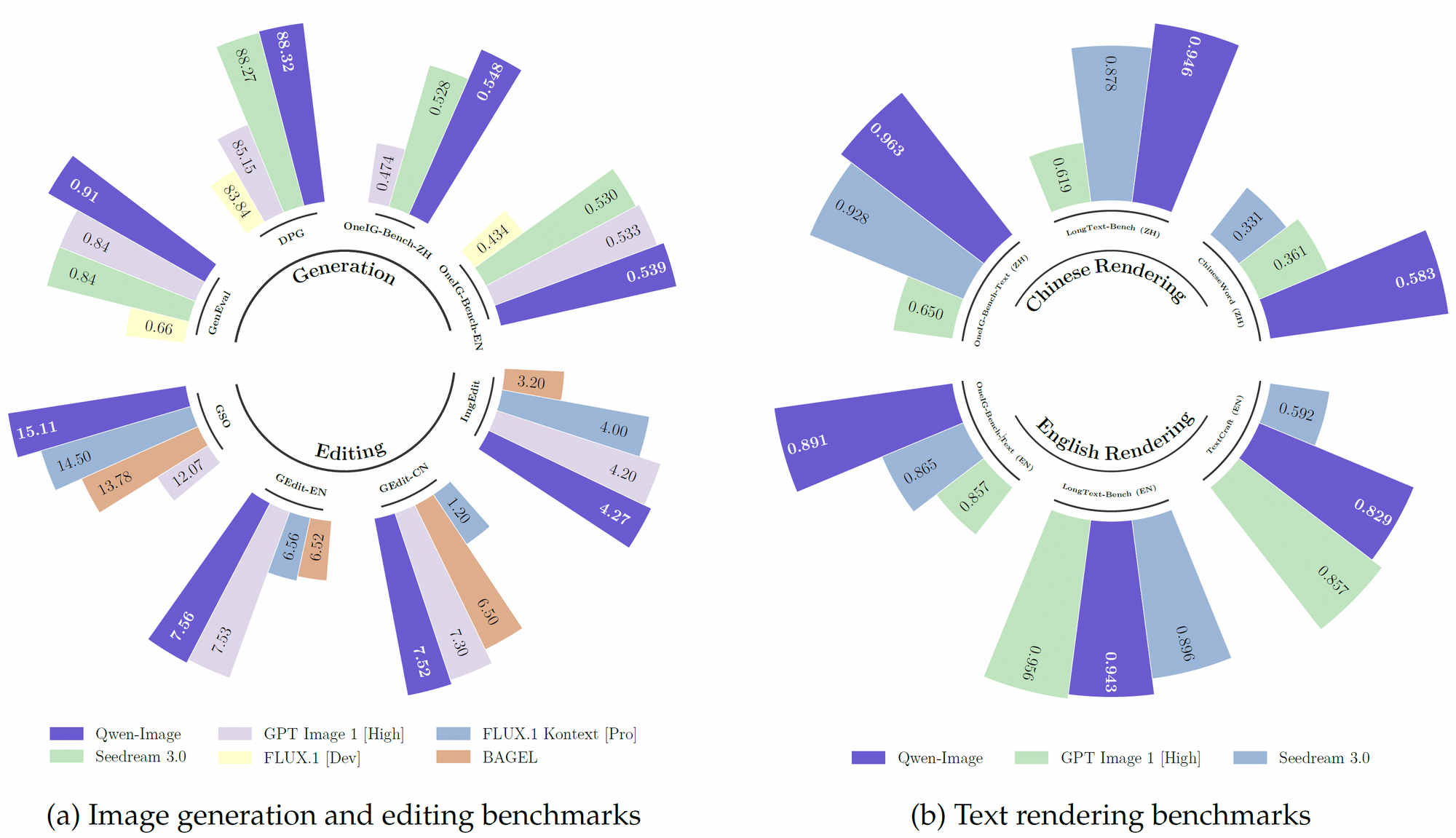
Hơn nữa, Qwen-Image xử lý bố cục nhiều dòng và ngữ nghĩa cấp đoạn văn với độ chính xác đáng kể. Trong một kịch bản thử nghiệm, nó đã hiển thị chính xác một bài thơ viết tay trên giấy ố vàng trong một hình ảnh, mặc dù văn bản chiếm chưa đến một phần mười không gian hình ảnh. Độ chính xác này làm cho nó lý tưởng cho các ứng dụng như bảng hiệu kỹ thuật số, thiết kế áp phích và trực quan hóa tài liệu.
Khả năng chỉnh sửa hình ảnh nâng cao
Ngoài việc hiển thị văn bản, Qwen-Image còn cung cấp các tính năng chỉnh sửa hình ảnh tinh vi. Nó hỗ trợ các thao tác như chuyển đổi phong cách, chèn đối tượng, tăng cường chi tiết và thao tác tư thế người. Ví dụ, người dùng có thể hướng dẫn mô hình “thêm bầu trời nắng vào hình ảnh này” hoặc “thay đổi bức tranh này thành phong cách Van Gogh,” và Qwen-Image sẽ đưa ra kết quả nhất quán. Mô hình huấn luyện đa nhiệm được tăng cường của nó đảm bảo rằng các chỉnh sửa vẫn giữ được ý nghĩa ngữ nghĩa và tính chân thực của hình ảnh.
Ngoài ra, khả năng chỉnh sửa văn bản trong hình ảnh của mô hình đặc biệt đáng chú ý. Các nhà phát triển có thể sửa đổi văn bản trên các biển báo hoặc áp phích mà không làm gián đoạn ngữ cảnh hình ảnh xung quanh, một tính năng có giá trị cho quảng cáo và tạo nội dung. Những khả năng này được hỗ trợ bởi khả năng hiểu hình ảnh sâu sắc của Qwen-Image, cho phép nó diễn giải và thao tác các yếu tố hình ảnh với độ chính xác.
Hiểu biết hình ảnh toàn diện
Qwen-Image không chỉ tạo hoặc chỉnh sửa – nó hiểu. Mô hình hỗ trợ một bộ các tác vụ hiểu hình ảnh, bao gồm phát hiện đối tượng, phân đoạn ngữ nghĩa, ước tính độ sâu, phát hiện cạnh (Canny), tổng hợp khung nhìn mới và siêu phân giải. Các tác vụ này được cung cấp bởi khả năng xử lý đầu vào độ phân giải cao và trích xuất các chi tiết tinh vi. Ví dụ, Qwen-Image có thể tạo hộp giới hạn cho các đối tượng được mô tả bằng ngôn ngữ tự nhiên, chẳng hạn như “phát hiện chó Husky trong cảnh tàu điện ngầm,” biến nó thành một công cụ mạnh mẽ cho phân tích hình ảnh.
Hơn nữa, việc hỗ trợ nhiều ngôn ngữ của nó nâng cao khả năng sử dụng trong các ứng dụng toàn cầu. Bằng cách tích hợp với các công cụ như Qwen-Plus Prompt Enhancement Tool, các nhà phát triển có thể tối ưu hóa lời nhắc để có hiệu suất đa ngôn ngữ tốt hơn, đảm bảo kết quả chính xác trên các ngữ cảnh ngôn ngữ đa dạng.
Hiệu suất vượt trội trên các điểm chuẩn
Qwen-Image liên tục vượt trội so với các đối thủ cạnh tranh trên nhiều điểm chuẩn công khai, bao gồm GenEval, DPG, OneIG-Bench, GEdit, ImgEdit và GSO. Hiệu suất vượt trội của nó trong việc hiển thị văn bản, đặc biệt là tiếng Trung, được thể hiện rõ trong các điểm chuẩn như TextCraft, nơi nó vượt qua các mô hình tiên tiến nhất hiện có. Ngoài ra, khả năng tạo hình ảnh tổng quát của nó hỗ trợ nhiều phong cách nghệ thuật, từ cảnh chân thực đến phong cách anime, biến nó thành một lựa chọn linh hoạt cho các chuyên gia sáng tạo.
Kiến trúc kỹ thuật của Qwen-Image
Biến đổi khuếch tán đa phương thức (MMDiT)
Về cốt lõi, Qwen-Image sử dụng kiến trúc Biến đổi khuếch tán đa phương thức (MMDiT), kết hợp sức mạnh của các mô hình khuếch tán và biến đổi. Cách tiếp cận lai này cho phép mô hình xử lý hiệu quả cả đầu vào hình ảnh và văn bản. Quá trình khuếch tán lặp đi lặp lại tinh chỉnh các đầu vào nhiễu thành hình ảnh mạch lạc, trong khi thành phần biến đổi xử lý các mối quan hệ phức tạp giữa văn bản và các yếu tố hình ảnh.
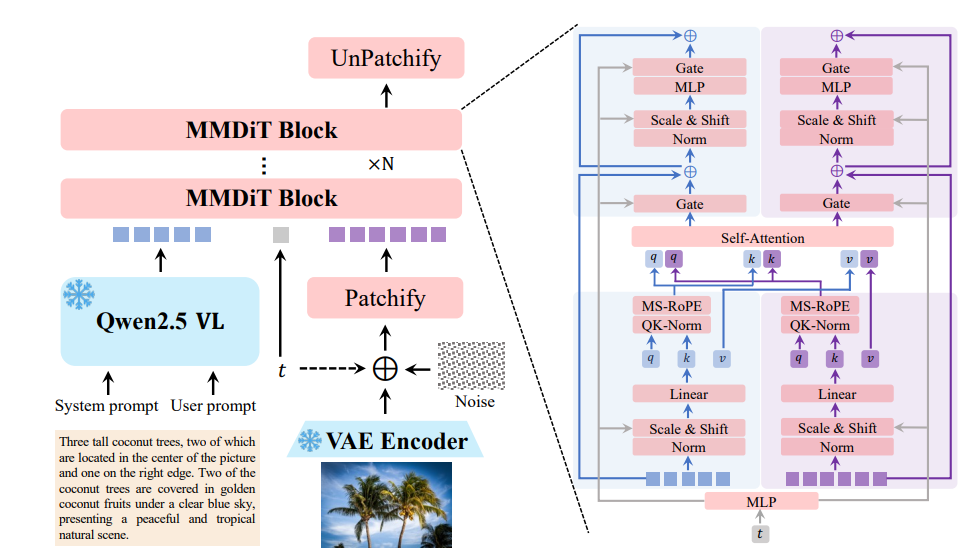
20 tỷ tham số của mô hình được tối ưu hóa cho hiệu quả, cho phép nó chạy trên phần cứng cấp người tiêu dùng chỉ với 4GB VRAM khi sử dụng các kỹ thuật như lượng tử hóa FP8 và offloading từng lớp. Khả năng truy cập này làm cho Qwen-Image phù hợp cho cả nhà phát triển doanh nghiệp và cá nhân.
Tiền huấn luyện và tinh chỉnh
Tập dữ liệu tiền huấn luyện của Qwen-Image là nền tảng cho hiệu suất của nó. Với hơn 30 nghìn tỷ token, tập dữ liệu bao gồm dữ liệu web, tài liệu giống PDF và dữ liệu tổng hợp được tạo bởi các mô hình như Qwen2.5-VL và Qwen2.5-Coder. Quá trình tiền huấn luyện diễn ra trong ba giai đoạn:

- Giai đoạn 1 (S1): Mô hình được tiền huấn luyện trên 30 nghìn tỷ token với độ dài ngữ cảnh 4K token, thiết lập các kỹ năng ngôn ngữ và hình ảnh cơ bản.
- Giai đoạn 2: Học tăng cường nâng cao khả năng suy luận và các khả năng cụ thể theo tác vụ của mô hình.
- Giai đoạn 3: Tinh chỉnh với các tập dữ liệu được tuyển chọn cải thiện sự phù hợp với sở thích người dùng và các tác vụ cụ thể như hiển thị văn bản và chỉnh sửa hình ảnh.
Cách tiếp cận đa giai đoạn này đảm bảo rằng Qwen-Image vừa mạnh mẽ vừa có khả năng thích ứng, có thể xử lý các tác vụ đa dạng với độ chính xác cao.
Tích hợp với các công cụ phát triển
Qwen-Image tích hợp liền mạch với các framework phát triển phổ biến như Diffusers và DiffSynth-Studio. Ví dụ, các nhà phát triển có thể sử dụng đoạn mã Python sau để tạo hình ảnh bằng Qwen-Image:
from diffusers import DiffusionPipeline
import torch
model_name = "Qwen/Qwen-Image"
torch_dtype = torch.bfloat16 if torch.cuda.is_available() else torch.float32
device = "cuda" if torch.cuda.is_available() else "cpu"
pipe = DiffusionPipeline.from_pretrained(model_name, torch_dtype=torch_dtype)
pipe = pipe.to(device)
prompt = "A coffee shop entrance with a chalkboard sign reading 'Qwen Coffee 😊 $2 per cup.'"
image = pipe(prompt).images[0]
image.save("qwen_coffee.png")
Đoạn mã này minh họa cách các nhà phát triển có thể tận dụng khả năng của Qwen-Image để tạo ra hình ảnh chất lượng cao với thiết lập tối thiểu. Các công cụ như Apidog còn đơn giản hóa việc tích hợp API, cho phép tạo mẫu và triển khai nhanh chóng.
Các ứng dụng thực tế của Qwen-Image
Tạo nội dung sáng tạo
Khả năng của Qwen-Image trong việc tạo ra các cảnh chân thực, tranh ấn tượng và hình ảnh theo phong cách anime biến nó thành một công cụ mạnh mẽ cho các nghệ sĩ và nhà thiết kế. Ví dụ, một nhà thiết kế đồ họa có thể tạo một áp phích phim với bố cục văn bản động và hình ảnh sống động, như được minh họa trong một trường hợp thử nghiệm nơi Qwen-Image tạo ra một áp phích cho “Imagination Unleashed” với một máy tính tương lai phát ra các sinh vật kỳ quái.

Quảng cáo và tiếp thị
Trong quảng cáo, khả năng hiển thị và chỉnh sửa văn bản của Qwen-Image cho phép tạo ra các chiến dịch hấp dẫn về mặt hình ảnh. Các nhà tiếp thị có thể tạo áp phích với vị trí văn bản chính xác hoặc chỉnh sửa hình ảnh hiện có để cập nhật thông điệp quảng cáo, đảm bảo tính nhất quán của thương hiệu và tính mạch lạc của hình ảnh.

Phân tích hình ảnh và tự động hóa
Đối với các ngành công nghiệp như thương mại điện tử và hệ thống tự động, các tác vụ hiểu hình ảnh của Qwen-Image—như phát hiện đối tượng và phân đoạn ngữ nghĩa—mang lại giá trị đáng kể. Các nền tảng bán lẻ có thể sử dụng mô hình để tự động gắn thẻ sản phẩm trong hình ảnh, trong khi các phương tiện tự hành có thể tận dụng khả năng ước tính độ sâu của nó để điều hướng.
Công cụ giáo dục
Khả năng của Qwen-Image trong việc tạo ra các hình ảnh giáo dục, chẳng hạn như sơ đồ với các chú thích văn bản chính xác, hỗ trợ các nền tảng học trực tuyến. Ví dụ, nó có thể tạo một hình minh họa chi tiết về một khái niệm khoa học với các thành phần được gắn nhãn, nâng cao sự tham gia và hiểu biết của học sinh.

So sánh Qwen-Image với các đối thủ cạnh tranh
Khi so sánh với các mô hình như DALL-E 3 và Stable Diffusion, Qwen-Image nổi bật với khả năng hiển thị văn bản đa ngôn ngữ và khả năng chỉnh sửa nâng cao. Trong khi DALL-E 3 xuất sắc trong việc tạo hình ảnh sáng tạo, nó lại gặp khó khăn với các bố cục văn bản phức tạp, đặc biệt là đối với các chữ tượng hình. Stable Diffusion, mặc dù đa năng, nhưng thiếu khả năng hiểu hình ảnh sâu sắc được cung cấp bởi bộ tác vụ hiểu biết của Qwen-Image.
Ngoài ra, tính chất mã nguồn mở và khả năng tương thích với phần cứng bộ nhớ thấp của Qwen-Image mang lại lợi thế cho các nhà phát triển có nguồn lực hạn chế. Hiệu suất của nó trên các điểm chuẩn như TextCraft và GEdit càng củng cố vị trí của nó như một mô hình hàng đầu trong AI đa phương thức.
Thách thức và hạn chế
Mặc dù có những điểm mạnh, Qwen-Image vẫn phải đối mặt với những thách thức. Việc mô hình phụ thuộc vào các tập dữ liệu lớn đặt ra những lo ngại về quyền riêng tư dữ liệu và nguồn gốc đạo đức, mặc dù Alibaba Cloud tuân thủ các hướng dẫn nghiêm ngặt. Ngoài ra, mặc dù mô hình hỗ trợ hơn 100 ngôn ngữ, hiệu suất của nó có thể khác nhau đối với các phương ngữ ít được đại diện hơn, đòi hỏi phải tinh chỉnh thêm.
Hơn nữa, yêu cầu tính toán của mô hình 20B tham số có thể đáng kể nếu không có các kỹ thuật tối ưu hóa như lượng tử hóa FP8. Các nhà phát triển phải cân bằng hiệu suất và hạn chế tài nguyên khi triển khai Qwen-Image trong môi trường sản xuất.
Triển vọng tương lai cho Qwen-Image
Trong tương lai, Qwen-Image dự kiến sẽ phát triển hơn nữa. Nhóm Qwen có kế hoạch phát hành một phiên bản mô hình dành riêng cho chỉnh sửa, nâng cao khả năng của nó cho các ứng dụng cấp chuyên nghiệp. Việc tích hợp với các framework mới nổi như vLLM và hỗ trợ liên tục cho các quy trình làm việc LoRA và tinh chỉnh sẽ mở rộng khả năng tiếp cận của nó.
Hơn nữa, những tiến bộ trong học tăng cường, như đã thấy trong các mô hình như Qwen3, cho thấy Qwen-Image có thể tích hợp khả năng suy luận sâu hơn, cho phép các tác vụ suy luận hình ảnh phức tạp hơn. Khi cộng đồng AI tiếp tục đóng góp vào sự phát triển của nó, Qwen-Image có tiềm năng định nghĩa lại việc tạo và hiểu hình ảnh.
Bắt đầu với Qwen-Image
Để bắt đầu sử dụng Qwen-Image, các nhà phát triển có thể truy cập trọng số mô hình trên GitHub hoặc Hugging Face. Blog chính thức tại qwenlm.github.io cung cấp hướng dẫn thiết lập chi tiết và các trường hợp sử dụng. Để có trải nghiệm thực tế, hãy truy cập Qwen Chat và chọn “Image Generation” để kiểm tra khả năng của mô hình.
Để tích hợp API, các công cụ như Apidog đơn giản hóa quy trình bằng cách cung cấp giao diện thân thiện với người dùng để kiểm thử và triển khai các tính năng của Qwen-Image. Tải xuống Apidog miễn phí để hợp lý hóa quy trình phát triển của bạn.
Kết luận: Tại sao Qwen-Image lại quan trọng
Qwen-Image đại diện cho một bước nhảy vọt đáng kể trong AI đa phương thức, kết hợp khả năng hiển thị văn bản tiên tiến, chỉnh sửa hình ảnh chính xác và hiểu hình ảnh mạnh mẽ. Tính khả dụng mã nguồn mở, quá trình tiền huấn luyện mở rộng và khả năng tương thích với các công cụ phát triển biến nó thành một lựa chọn linh hoạt cho các nhà sáng tạo, nhà phát triển và nhà nghiên cứu. Bằng cách giải quyết các thách thức như hỗ trợ đa ngôn ngữ và hiệu quả tài nguyên, Qwen-Image đặt ra một tiêu chuẩn mới cho việc tạo hình ảnh dựa trên AI.
Khi AI tiếp tục phát triển, các mô hình như Qwen-Image sẽ đóng vai trò then chốt trong việc thu hẹp khoảng cách giữa ngôn ngữ và hình ảnh, mở ra những khả năng mới cho các ứng dụng sáng tạo và phân tích. Cho dù bạn đang xây dựng một chiến dịch tiếp thị, phân tích dữ liệu hình ảnh hay tạo nội dung giáo dục, Qwen-Image đều cung cấp các công cụ để biến tầm nhìn của bạn thành hiện thực.