
Trong thế giới trí tuệ nhân tạo đang phát triển nhanh chóng, một cột mốc mới đã được thiết lập với sự ra mắt của Qwen 2.5 Omni 7B. Mô hình cách mạng này từ Alibaba Cloud đại diện cho một bước tiến vượt bậc trong AI đa phương thức, kết hợp khả năng xử lý và hiểu nhiều hình thức đầu vào trong khi tạo ra cả đầu ra văn bản và lời nói. Hãy cùng tìm hiểu điều gì làm cho mô hình này thực sự đặc biệt và cách nó đang định hình lại hiểu biết của chúng ta về khả năng của AI.
Ý nghĩa thực sự của "Omni" trong Qwen 2.5 Omni 7B
Thuật ngữ "Omni" trong Qwen 2.5 Omni 7B không chỉ là một thương hiệu thông minh—nó là một mô tả cơ bản về khả năng của mô hình. Khác với nhiều mô hình đa phương thức xuất sắc trong một hoặc hai loại dữ liệu, Qwen 2.5 Omni 7B được thiết kế từ đầu để tiếp nhận và hiểu:
- Văn bản (ngôn ngữ viết)
- Hình ảnh (thông tin thị giác)
- Âm thanh (âm thanh và ngôn ngữ nói)
- Video (nội dung thị giác chuyển động với yếu tố thời gian)
Voice Chat + Video Chat! Chỉ trong Qwen Chat (https://t.co/FmQ0B9tiE7)! Bạn có thể trò chuyện với Qwen giống như thực hiện cuộc gọi điện thoại hoặc gọi video! Kiểm tra demo tại https://t.co/42iDe4j1Hs
— Qwen (@Alibaba_Qwen) Ngày 26 tháng 3 năm 2025
Thêm vào đó, chúng tôi mã nguồn mở mô hình này, Qwen2.5-Omni-7B, dưới… pic.twitter.com/LHQOQrl9Ha
Điều còn ấn tượng hơn nữa là mô hình này không chỉ tiếp nhận những đầu vào đa dạng mà còn có thể đáp ứng bằng cả đầu ra văn bản và lời nói tự nhiên theo cách liên tục. Khả năng "từ bất kỳ đến bất kỳ" này đại diện cho một bước tiến quan trọng hướng tới các tương tác AI tự nhiên và giống người hơn.
Kiến trúc sáng tạo của Qwen 2.5 Omni 7B: Giải thích
Thinker-Talker: Một mô hình mới
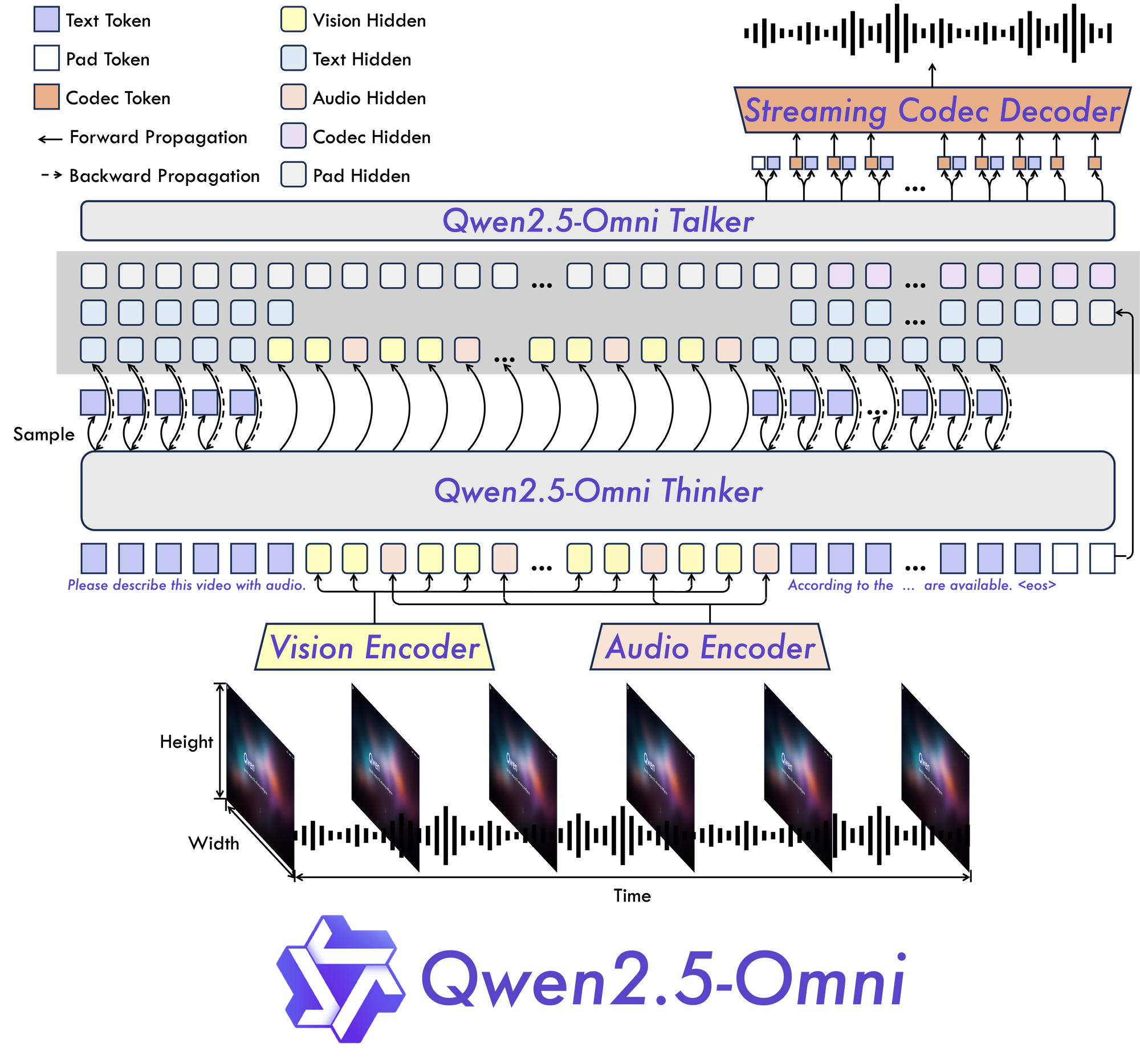
Tại trung tâm của Qwen 2.5 Omni 7B là kiến trúc "Thinker-Talker" cơ bản của nó. Thiết kế mới này tạo ra một mô hình được xây dựng đặc biệt để hoàn toàn đa phương thức, cho phép xử lý liền mạch giữa các loại thông tin khác nhau.
Như tên gọi gợi ý, kiến trúc này tách riêng sự xử lý nhận thức của thông tin (suy nghĩ) khỏi việc tạo ra các đầu ra (nói). Sự tách biệt này cho phép mô hình quản lý hiệu quả những phức tạp vốn có của dữ liệu đa phương thức và sản sinh các phản hồi thích hợp theo nhiều định dạng.
TMRoPE: Giải quyết thách thức đồng bộ tạm thời
Một trong những đổi mới quan trọng nhất trong Qwen 2.5 Omni 7B là cơ chế Time-aligned Multimodal RoPE (TMRoPE). Đột phá này giải quyết một trong những khía cạnh thách thức nhất của AI đa phương thức: đồng bộ hóa dữ liệu tạm thời từ các nguồn khác nhau.
Khi xử lý video và âm thanh đồng thời, mô hình cần hiểu cách các sự kiện hình ảnh đồng bộ với âm thanh hoặc lời nói tương ứng. Ví dụ, việc khớp chuyển động môi của một người với lời nói của họ yêu cầu sự đồng bộ tạm thời chính xác. TMRoPE cung cấp khung công nghệ tinh vi để đạt được sự đồng bộ này, cho phép mô hình xây dựng một hiểu biết mạch lạc về các đầu vào đa phương thức diễn ra theo thời gian.
Được thiết kế cho tương tác thời gian thực
Qwen 2.5 Omni 7B được xây dựng với các ứng dụng thời gian thực trong đầu. Kiến trúc hỗ trợ phát trực tiếp độ trễ thấp, cho phép xử lý đầu vào từng phần và tạo ra đầu ra ngay lập tức. Điều này rất lý tưởng cho các ứng dụng yêu cầu tương tác nhạy bén, chẳng hạn như trợ lý giọng nói, phân tích video trực tiếp hoặc dịch thuật thời gian thực.
Hiệu suất Qwen 2.5 Omni 7B: Các chuẩn mực nói lên điều đó
Bài kiểm tra thực sự của bất kỳ mô hình AI nào là hiệu suất của nó qua các chuẩn mực nghiêm ngặt, và Qwen 2.5 Omni 7B đạt được kết quả ấn tượng trên toàn bộ các lĩnh vực.
Đi đầu trong hiểu biết đa phương thức
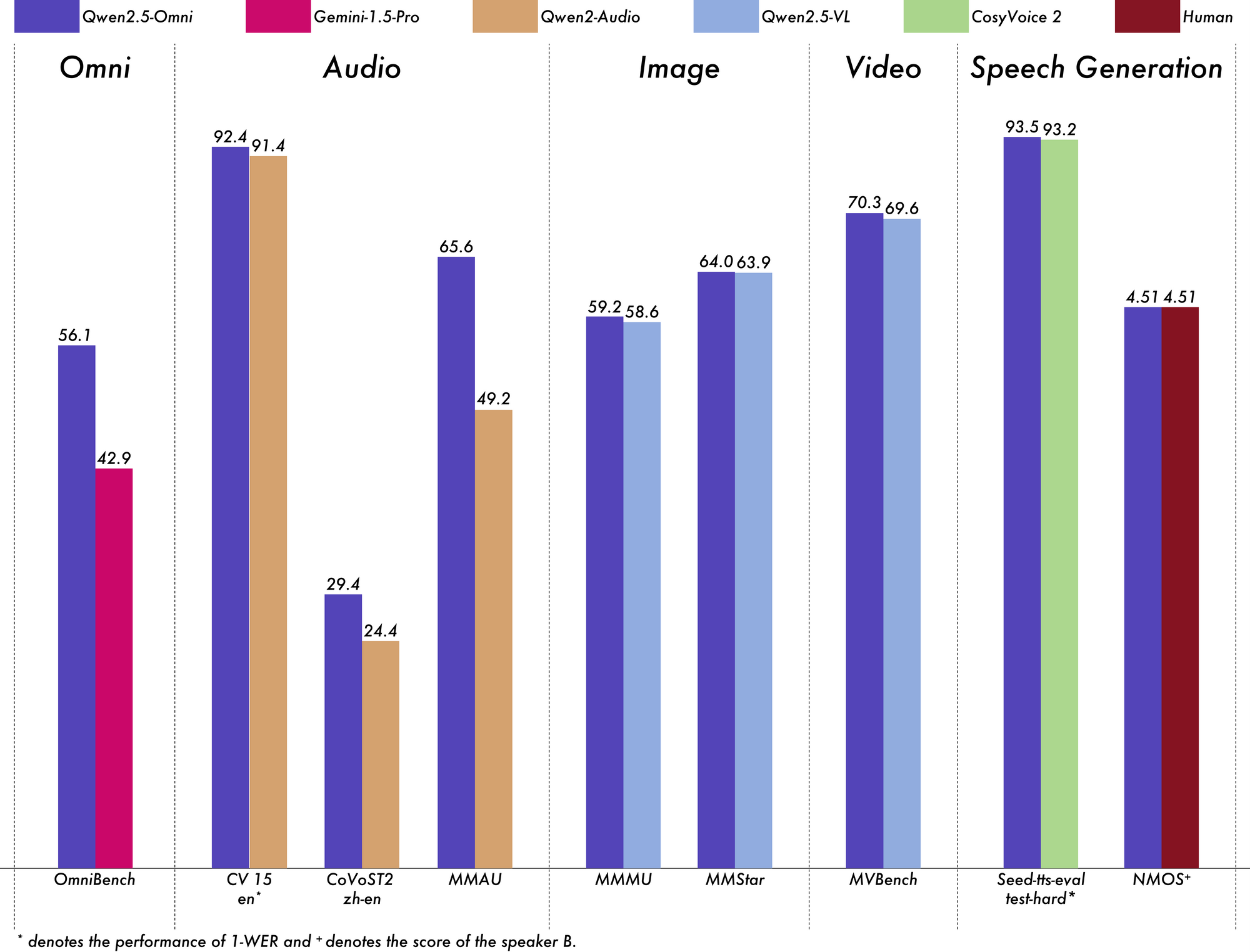
Trên chuẩn OmniBench cho hiểu biết đa phương thức nói chung, Qwen 2.5 Omni 7B đạt điểm trung bình 56.13%. Điều này vượt xa nhiều mô hình khác như Gemini-1.5-Pro (42.91%) và MIO-Instruct (33.80%). Hiệu suất xuất sắc của nó trong các loại chuẩn OmniBench cụ thể là rất đáng chú ý:
- Các nhiệm vụ tiếng nói: 55.25%
- Các nhiệm vụ sự kiện âm thanh: 60.00%
- Các nhiệm vụ âm nhạc: 52.83%
Hiệu suất toàn diện này chứng minh khả năng của mô hình trong việc tích hợp và lý luận hiệu quả trên nhiều phương thức.
Xuất sắc trong xử lý âm thanh
Đối với các nhiệm vụ chuyển đổi âm thanh thành văn bản, Qwen 2.5 Omni 7B cho thấy kết quả gần như vượt trội trong Nhận diện Giọng nói Tự động (ASR). Trên tập dữ liệu Librispeech, nó đạt được Tỷ lệ Lỗi Từ (WER) từ 1.6% đến 3.5%, tương đương với các mô hình chuyên dụng như Whisper-large-v3.
Trong Nhận diện sự kiện âm thanh trên tập dữ liệu Meld, nó đạt hiệu suất tốt nhất với điểm số 0.570. Mô hình này thậm chí còn xuất sắc trong hiểu biết âm nhạc, với điểm số 0.88 trên chuẩn GiantSteps Tempo.
Hiểu biết hình ảnh mạnh mẽ
Khi nói đến các nhiệm vụ chuyển đổi hình ảnh thành văn bản, Qwen 2.5 Omni 7B đạt được điểm số 59.2 trên chuẩn MMMU, rất gần với 60.0 của GPT-4o-mini. Trên nhiệm vụ RefCOCO Grounding, nó đạt độ chính xác 90.5%, vượt xa 73.2% của Gemini 1.5 Pro.
Hiểu biết video ấn tượng
Đối với các nhiệm vụ chuyển đổi video thành văn bản không có phụ đề, mô hình ghi được 64.3 trên Video-MME, gần ngang bằng hiệu suất của các mô hình video chuyên dụng. Khi có thêm phụ đề, hiệu suất tăng lên 72.4, thể hiện khả năng tích hợp hiệu quả nhiều nguồn thông tin của mô hình.
Tạo ra lời nói tự nhiên
Qwen 2.5 Omni 7B không chỉ hiểu—nó còn nói. Đối với việc sinh lời nói, nó đạt được điểm số sự tương đồng giữa các diễn giả từ 0.754 đến 0.752, tương đương với các mô hình chuyển văn bản thành lời nói chuyên dụng như Seed-TTS_RL. Điều này chứng tỏ khả năng của nó trong việc tạo ra lời nói tự nhiên giữ được những đặc điểm của giọng nói gốc của người nói.
Duy trì khả năng văn bản mạnh mẽ
Malgré les besoins multimodaux của mình, Qwen 2.5 Omni 7B vẫn thể hiện tốt trong các nhiệm vụ chỉ cần văn bản. Nó đạt kết quả tốt trong lý luận toán học (điểm GSM8K: 88.7%) và sinh mã. Mặc dù có một chút nảy sinh so với mô hình chỉ xử lý văn bản Qwen2.5-7B (điểm 91.6% trên GSM8K), sự giảm nhẹ này là một sự đánh đổi hợp lý để có được những khả năng đa phương thức toàn diện như vậy.
Các ứng dụng thực tế của Qwen 2.5 Omni 7B:
Qwen 2.5 Omni thật điên rồ!
— Jeff Boudier 🤗 (@jeffboudier) Ngày 26 tháng 3 năm 2025
Tôi không thể tin rằng một mô hình 7B
có thể nhận đầu vào văn bản, hình ảnh, âm thanh, video
cung cấp đầu ra văn bản và âm thanh
và hoạt động tốt như vậy!
Mã nguồn mở Apache 2.0
Hãy thử thôi, liên kết bên dưới!
Bạn thực sự đã làm nên điều tuyệt vời @Alibaba_Qwen ! pic.twitter.com/pn0dnwOqjY
Sự linh hoạt của Qwen 2.5 Omni 7B mở ra nhiều ứng dụng thực tiễn trong nhiều lĩnh vực.
Giao diện giao tiếp nâng cao
Các khả năng phát trực tiếp độ trễ thấp của nó làm cho nó trở nên lý tưởng cho các ứng dụng trò chuyện video và giọng nói thời gian thực. Hãy tưởng tượng những trợ lý ảo có thể nhìn, nghe và nói tự nhiên, hiểu cả những tín hiệu giao tiếp bằng lời và không bằng lời trong khi phản hồi bằng lời nói tự nhiên.
Phân tích nội dung nâng cao
Khả năng xử lý và hiểu các hình thức đa dạng của mô hình định vị nó như một công cụ mạnh mẽ cho phân tích nội dung toàn diện. Nó có thể trích xuất thông tin từ các tài liệu đa phương tiện, tự động xác định thông tin quan trọng từ văn bản, hình ảnh, âm thanh và video đồng thời.
Giao diện giọng nói dễ tiếp cận
Với hiệu suất vượt trội trong việc thực hiện các chỉ dẫn giọng nói từ đầu đến cuối, Qwen 2.5 Omni 7B cho phép tương tác tự nhiên và thực sự không cần sử dụng tay với công nghệ. Điều này có thể cách mạng hóa các tính năng truy cập cho người dùng khuyết tật hoặc các tình huống mà hoạt động không cần tay là rất cần thiết.
Sáng tạo nội dung
Khả năng tạo ra cả văn bản và lời nói tự nhiên mở ra những khả năng mới cho việc sáng tạo nội dung. Từ việc tự động tạo lồng ghép cho video đến việc tạo ra các tài liệu giáo dục tương tác phản hồi đến các câu hỏi của học sinh với những giải thích phù hợp, các ứng dụng rất phong phú.
Dịch vụ khách hàng đa phương thức
Các doanh nghiệp có thể triển khai Qwen 2.5 Omni 7B để cung cấp dịch vụ khách hàng có thể phân tích các truy vấn của khách hàng từ nhiều kênh—cuộc gọi thoại, trò chuyện video, tin nhắn viết—và phản hồi một cách tự nhiên và phù hợp với mỗi kênh.
Các yếu tố thực tế và hạn chế
Trong khi Qwen 2.5 Omni 7B đại diện cho một bước tiến quan trọng trong AI đa phương thức, có một số yếu tố thực tế cần lưu ý khi làm việc với nó.
Yêu cầu phần cứng
Các khả năng toàn diện của mô hình đi kèm với yêu cầu tính toán đáng kể. Việc xử lý ngay cả một video ngắn dài 15 giây với độ chính xác FP32 yêu cầu khoảng 93.56 GB bộ nhớ GPU. Ngay cả với độ chính xác BF16, một video dài 60 giây vẫn cần khoảng 60.19 GB.
Các yêu cầu này có thể hạn chế khả năng tiếp cận cho người dùng không có phần cứng cao cấp. Tuy nhiên, mô hình hỗ trợ nhiều tối ưu hóa như Flash Attention 2, có thể giúp cải thiện hiệu suất trên phần cứng tương thích.
Tùy chỉnh loại giọng nói
Điều thú vị là Qwen 2.5 Omni 7B hỗ trợ nhiều loại giọng nói cho đầu ra âm thanh của nó. Hiện tại, nó cung cấp hai tùy chọn giọng nói:
- Chelsie: Một giọng nữ được mô tả là "ngọt ngào, mượt mà" với "sự ấm áp nhẹ nhàng và độ rõ ràng rực rỡ"
- Ethan: Một giọng nam có đặc điểm là "rực rỡ, vui tươi" với "năng lượng lây lan và cảm giác ấm áp, gần gũi"
Sự tùy chỉnh này thêm một chiều cho sự linh hoạt của mô hình trong các ứng dụng thực tế.
Yếu tố tích hợp kỹ thuật
Khi triển khai Qwen 2.5 Omni 7B, có một số chi tiết kỹ thuật cần được chú ý:
- Mô hình yêu cầu các mẫu gợi ý cụ thể cho đầu ra âm thanh
- Cần có các cài đặt nhất quán cho các tham số
use_audio_in_videođể đảm bảo các cuộc trò chuyện đa vòng diễn ra đúng cách - Khả năng tương thích URL video phụ thuộc vào các phiên bản thư viện cụ thể (torchvision ≥ 0.19.0 cho sự hỗ trợ HTTPS)
- Mô hình hiện không có sẵn qua API Inference của Hugging Face do hạn chế trong việc hỗ trợ các mô hình "từ bất kỳ đến bất kỳ"
Tương lai của AI đa phương thức
Qwen 2.5 Omni 7B đại diện cho nhiều hơn một mô hình AI khác—đó là cái nhìn về tương lai của trí tuệ nhân tạo. Bằng cách kết hợp nhiều hình thức cảm quan trong một kiến trúc thống nhất và đầu đến cuối, nó đưa chúng ta đến gần hơn với các hệ thống AI có thể tiếp nhận và tương tác với thế giới giống như con người.
Sự tích hợp của TMRoPE cho việc đồng bộ tạm thời giải quyết một thách thức cơ bản trong xử lý đa phương thức, trong khi kiến trúc Thinker-Talker cung cấp một khuôn khổ để kết hợp hiệu quả các đầu vào đa dạng và tạo ra các đầu ra phù hợp. Hiệu suất mạnh mẽ của nó trên các chuẩn mực cho thấy các mô hình đa phương thức thống nhất có thể cạnh tranh và đôi khi vượt trội hơn các mô hình chuyên dụng theo đơn phương thức.
Với việc tài nguyên tính toán trở nên dễ tiếp cận hơn và các kỹ thuật triển khai mô hình hiệu quả được cải thiện, chúng ta có thể mong đợi thấy sự áp dụng rộng rãi hơn của AI thực sự đa phương thức như Qwen 2.5 Omni 7B. Các ứng dụng trải rộng trên hầu như mọi lĩnh vực—từ chăm sóc sức khỏe và giáo dục đến giải trí và dịch vụ khách hàng.
Kết luận
Qwen 2.5 Omni 7B là một thành tựu đáng chú ý trong sự phát triển của AI đa phương thức. Các khả năng "Omni" toàn diện, kiến trúc sáng tạo và hiệu suất ấn tượng giữa các phương thức thiết lập nó như một ví dụ điển hình cho thế hệ tiếp theo của các hệ thống trí tuệ nhân tạo.
Bằng cách kết hợp khả năng nhìn, nghe, đọc và nói trong một mô hình thống nhất, Qwen 2.5 Omni 7B phá vỡ những rào cản truyền thống giữa các khả năng AI khác nhau. Nó đại diện cho một bước tiến quan trọng hướng tới việc tạo ra các hệ thống AI có thể tương tác với con người và hiểu thế giới theo cách tự nhiên, trực quan hơn.
Mặc dù có những hạn chế thực tế cần xem xét, đặc biệt là về yêu cầu phần cứng, những thành tựu của mô hình này chỉ ra một tương lai đầy hứa hẹn nơi AI có thể xử lý và phản hồi một cách mượt mà đối với thế giới phong phú và đa phương thức mà chúng ta đang sống. Khi các công nghệ này tiếp tục phát triển và trở nên dễ tiếp cận hơn, chúng ta có thể mong đợi chúng sẽ biến đổi cách chúng ta tương tác với công nghệ qua vô số ứng dụng và lĩnh vực.
Qwen 2.5 Omni 7B không chỉ là một thành tựu công nghệ—nó là cái nhìn về một tương lai mà các ranh giới giữa các hình thức giao tiếp khác nhau bắt đầu tan biến, tạo ra những cách tương tác tự nhiên và trực quan hơn cho con người và AI.