
Việc chạy các mô hình ngôn ngữ lớn (LLM) cục bộ từng là lĩnh vực dành cho những người dùng CLI chuyên sâu và những người mày mò hệ thống. Nhưng điều đó đang thay đổi nhanh chóng. Ollama, nổi tiếng với giao diện dòng lệnh đơn giản để chạy các LLM mã nguồn mở trên máy cục bộ, vừa phát hành ứng dụng máy tính để bàn gốc cho macOS và Windows.
Và chúng không chỉ là những trình bao bọc cơ bản. Các ứng dụng này mang đến những tính năng mạnh mẽ giúp các nhà phát triển trò chuyện với mô hình, phân tích tài liệu, viết tài liệu và thậm chí làm việc với hình ảnh dễ dàng hơn đáng kể.
Trong bài viết này, chúng ta sẽ khám phá cách trải nghiệm máy tính để bàn mới cải thiện quy trình làm việc của nhà phát triển, những tính năng nổi bật và nơi những công cụ này thực sự tỏa sáng trong cuộc sống lập trình hàng ngày.
Tại Sao LLM Cục Bộ Vẫn Quan Trọng
Trong khi các công cụ dựa trên đám mây như ChatGPT, Claude và Gemini thống trị các tiêu đề, có một phong trào ngày càng tăng hướng tới phát triển AI ưu tiên cục bộ. Các nhà phát triển muốn các công cụ có những đặc điểm sau:
- Riêng tư - Mã và tài liệu của bạn vẫn nằm trên máy của bạn.
- Có thể tùy chỉnh - Bạn chọn mô hình, giới hạn bộ nhớ và phần cứng.
- Thân thiện với ngoại tuyến - Không phụ thuộc vào API bên ngoài hoặc thời gian hoạt động.
- Nhanh chóng - Không có độ trễ mạng hoặc tắc nghẽn máy chủ.
Ollama đi thẳng vào xu hướng này, cho phép bạn chạy các mô hình như LLaMA, Mistral, Gemma, Codellama, Mixtral và các mô hình khác một cách nguyên bản trên máy của bạn - giờ đây với trải nghiệm mượt mà hơn nhiều.
Bước 1: Tải xuống Ollama cho Máy tính để bàn
Truy cập ollama.com và tải xuống phiên bản mới nhất cho hệ thống của bạn:
- macOS (Apple Silicon hoặc Intel)
- Windows 10/11 (x64)
Cài đặt nó như một ứng dụng máy tính để bàn thông thường. Không cần thiết lập dòng lệnh để bắt đầu.
Bước 2: Khởi chạy và Chọn một Mô hình
Sau khi cài đặt, hãy mở ứng dụng Ollama dành cho máy tính để bàn. Giao diện sạch sẽ và trông giống như một cửa sổ trò chuyện đơn giản.
Bạn sẽ được nhắc chọn một mô hình để tải xuống và chạy. Một số tùy chọn bao gồm:
llama3– trợ lý đa năngcodellama– tuyệt vời để tạo mã và tái cấu trúcmistral– nhanh, nhỏ và chính xácgemma– mô hình mã nguồn mở được Google hỗ trợ
Chọn một mô hình và ứng dụng sẽ tự động tải xuống và tải nó.
Trải Nghiệm Khởi Đầu Mượt Mà Hơn cho Nhà Phát triển - Cách Dễ Dàng Hơn để Trò Chuyện với Mô hình
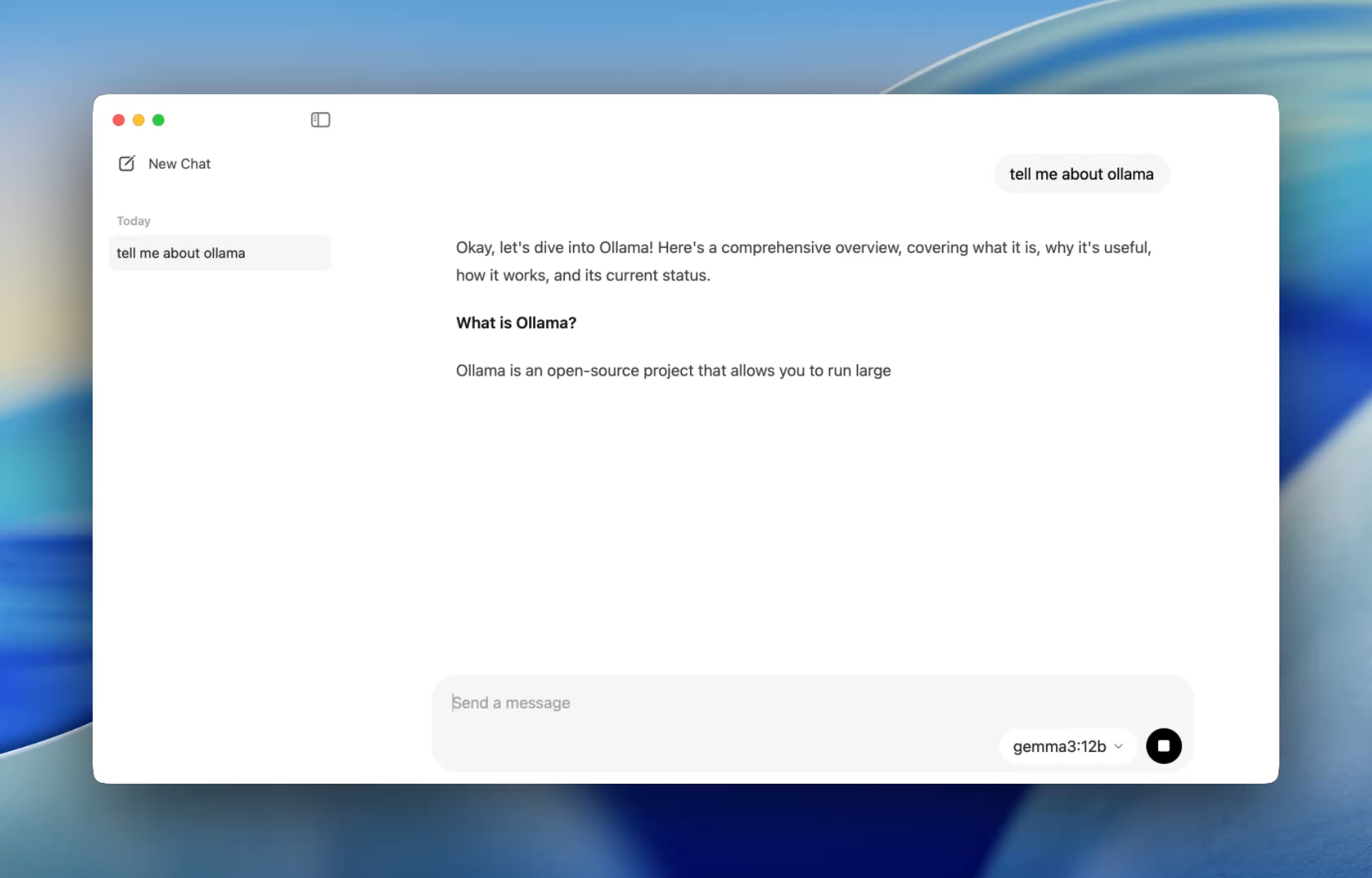
Trước đây, việc sử dụng Ollama có nghĩa là phải mở một terminal và đưa ra các lệnh ollama run để bắt đầu một phiên mô hình. Giờ đây, ứng dụng máy tính để bàn mở ra như bất kỳ ứng dụng gốc nào, cung cấp một giao diện trò chuyện đơn giản và sạch sẽ.
Giờ đây bạn có thể trò chuyện với các mô hình theo cách tương tự như trong ChatGPT — nhưng hoàn toàn ngoại tuyến. Điều này hoàn hảo cho:
- Hỗ trợ đánh giá mã
- Tạo kiểm thử
- Mẹo tái cấu trúc
- Học API hoặc ngôn ngữ mới
Ứng dụng cung cấp cho bạn quyền truy cập ngay lập tức vào các mô hình cục bộ như codellama hoặc mistral mà không cần thiết lập gì ngoài việc cài đặt đơn giản.
Và đối với các nhà phát triển yêu thích tùy chỉnh, CLI vẫn hoạt động ngầm cho phép bạn bật/tắt độ dài ngữ cảnh, lời nhắc hệ thống và phiên bản mô hình thông qua terminal nếu cần.
Kéo. Thả. Đặt câu hỏi.
Trò chuyện với Tệp
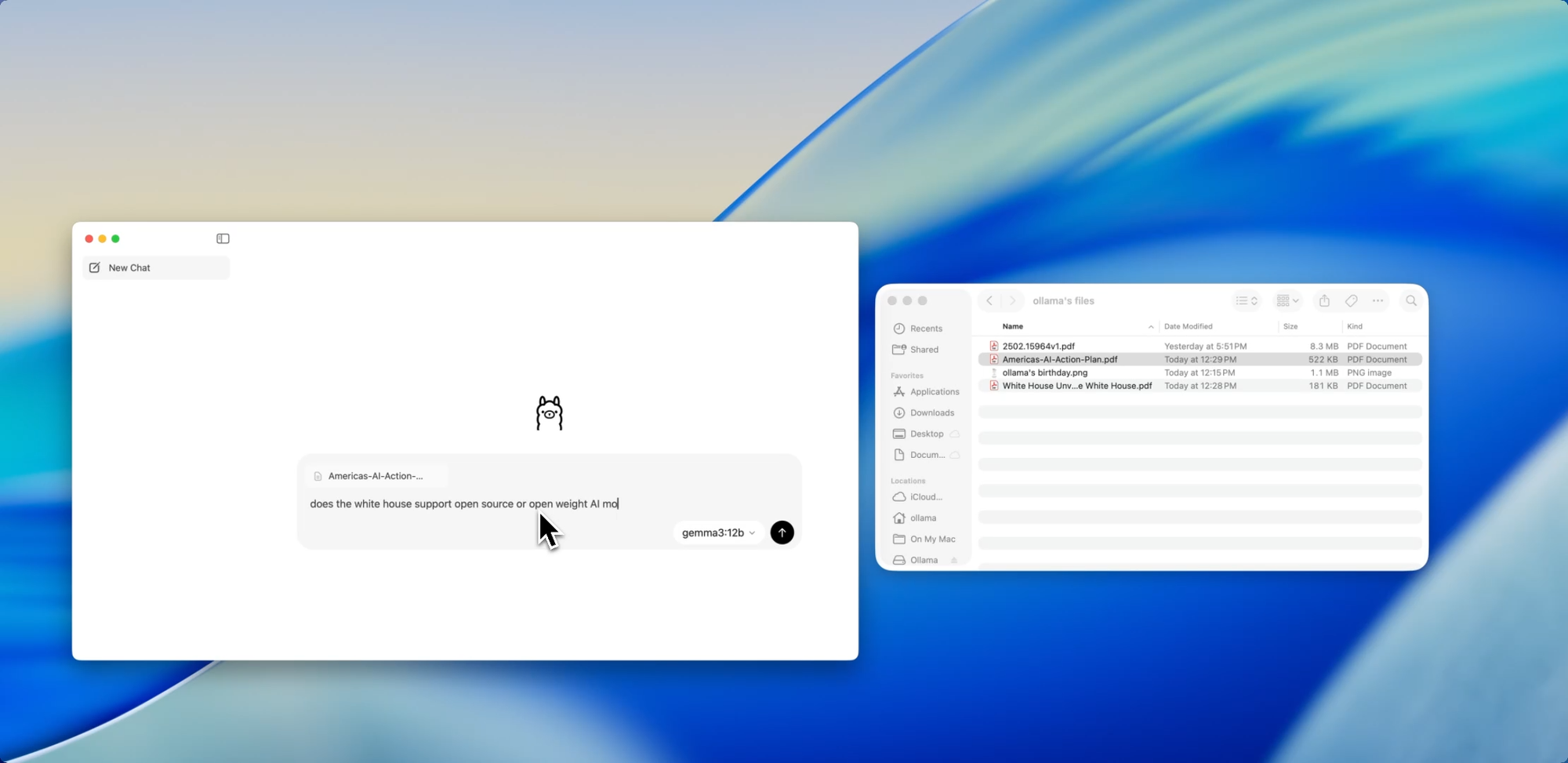
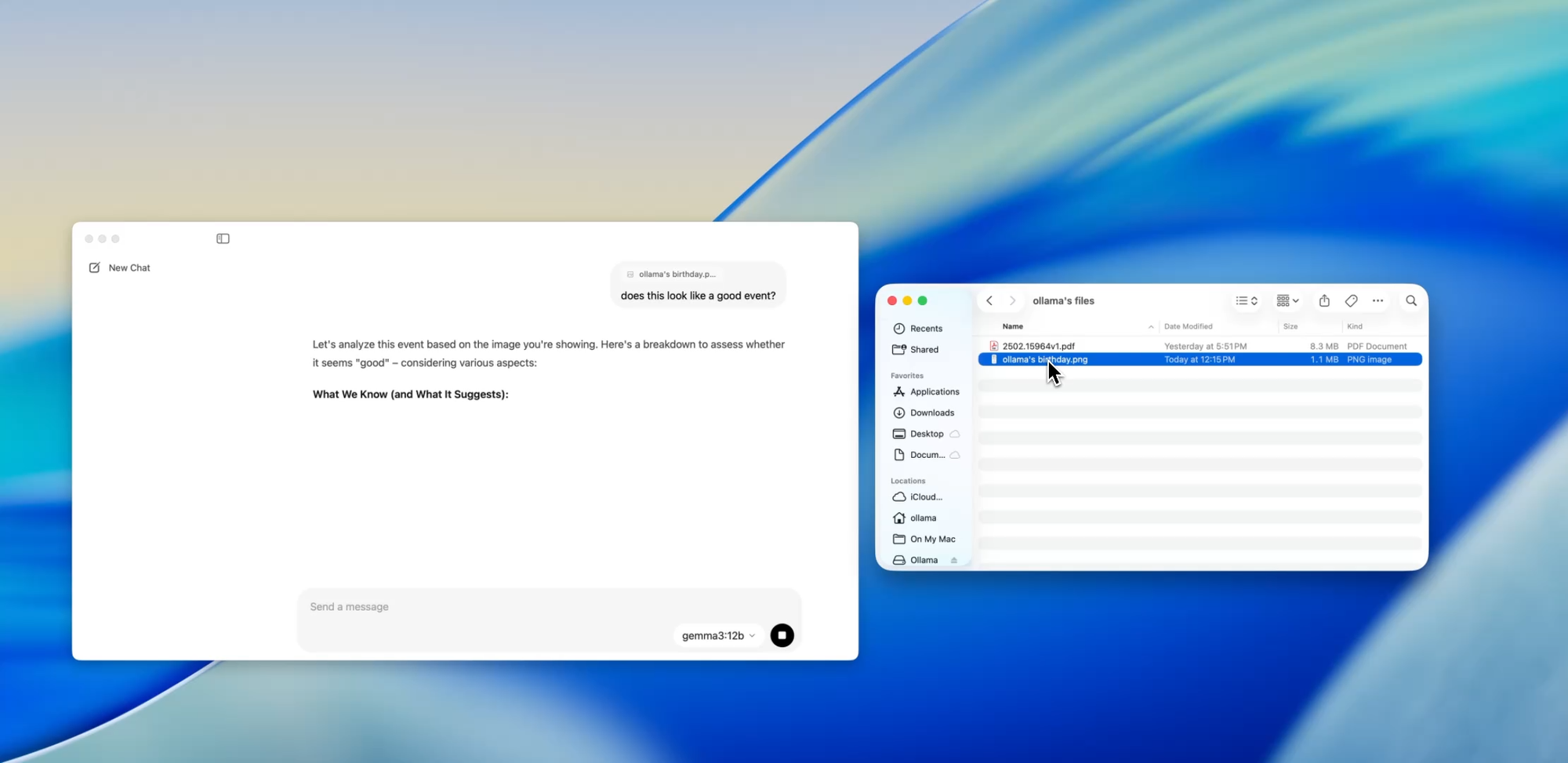
Một trong những tính năng thân thiện với nhà phát triển nhất trong ứng dụng mới là nhập tệp. Chỉ cần kéo một tệp vào cửa sổ trò chuyện — dù đó là tệp .pdf, .md hay .txt — và mô hình sẽ đọc nội dung của nó.
Cần hiểu một tài liệu thiết kế dài 60 trang? Muốn trích xuất các TODO từ một README lộn xộn? Hay tóm tắt bản tóm tắt sản phẩm của khách hàng? Kéo nó vào và đặt các câu hỏi bằng ngôn ngữ tự nhiên như:
- “Các tính năng chính được thảo luận trong tài liệu này là gì?”
- “Tóm tắt điều này trong một đoạn văn.”
- “Có phần nào bị thiếu hoặc không nhất quán không?”
Tính năng này có thể giảm đáng kể thời gian dành cho việc quét tài liệu, xem xét thông số kỹ thuật hoặc làm quen với các dự án mới.
Vượt Xa Văn Bản
Hỗ trợ Đa phương thức
Một số mô hình trong Ollama (chẳng hạn như những mô hình dựa trên Llava) hiện hỗ trợ đầu vào hình ảnh. Điều đó có nghĩa là bạn có thể tải lên một hình ảnh và mô hình sẽ diễn giải và phản hồi nó.
Một số trường hợp sử dụng bao gồm:
- Đọc biểu đồ hoặc đồ thị từ ảnh chụp màn hình
- Mô tả các bản mô phỏng giao diện người dùng (UI)
- Xem lại các ghi chú viết tay đã được quét
- Phân tích các đồ họa thông tin đơn giản
Mặc dù điều này vẫn còn ở giai đoạn đầu so với các công cụ như GPT-4 Vision, việc có hỗ trợ đa phương thức được tích hợp vào một ứng dụng ưu tiên cục bộ là một bước tiến lớn đối với các nhà phát triển xây dựng hệ thống đa đầu vào hoặc kiểm thử giao diện AI.
Tài Liệu Riêng Tư, Cục Bộ — Theo Lệnh Của Bạn
Viết Tài Liệu
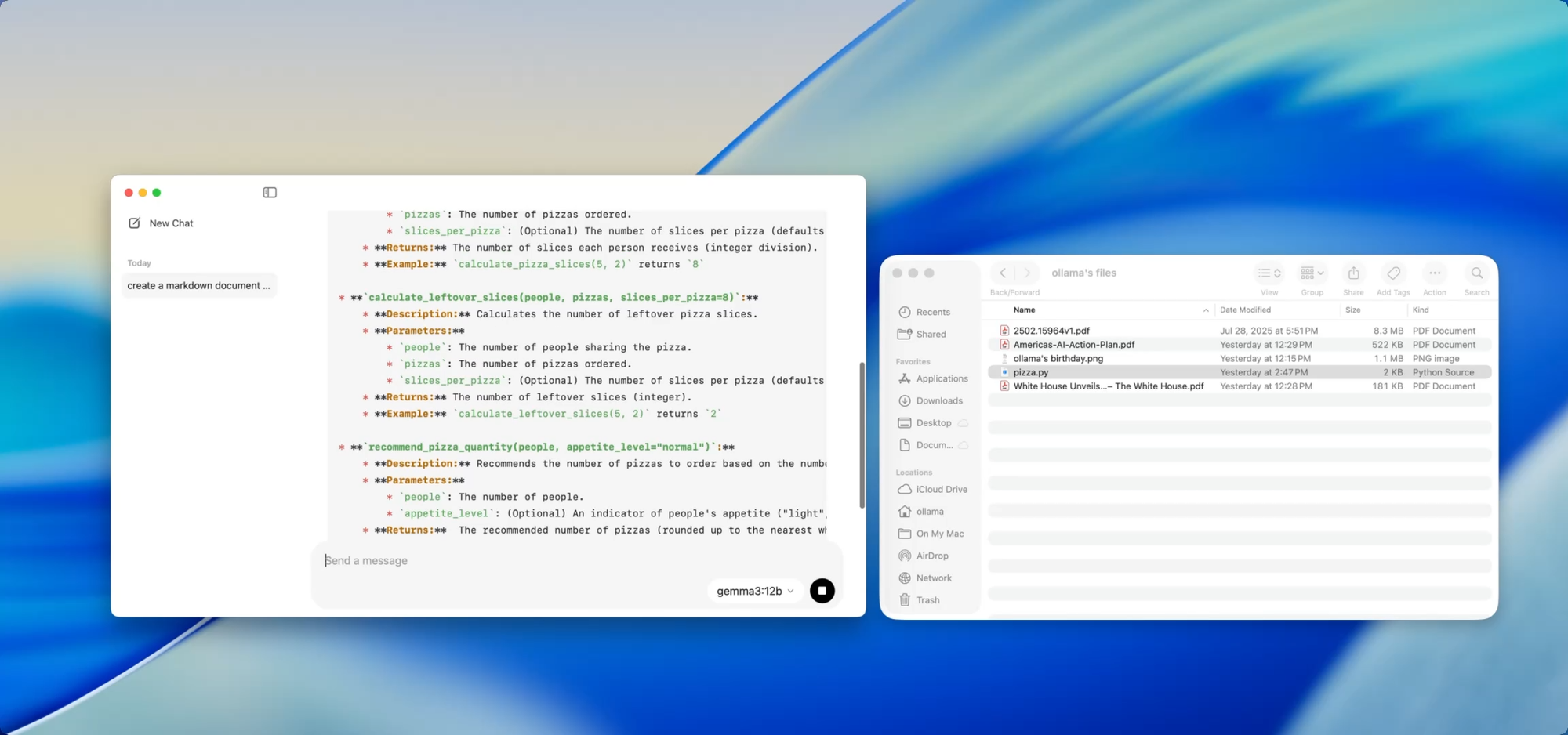
Nếu bạn đang duy trì một codebase ngày càng lớn, bạn biết nỗi đau của việc tài liệu bị lạc hậu. Với Ollama, bạn có thể sử dụng các mô hình cục bộ để giúp tạo hoặc cập nhật tài liệu mà không cần đẩy mã nhạy cảm lên đám mây.
Chỉ cần kéo một tệp — chẳng hạn utils.py — vào ứng dụng và hỏi:
- “Viết docstrings cho các hàm này.”
- “Tạo một bản tổng quan Markdown về chức năng của tệp này.”
- “Mô-đun này sử dụng những phụ thuộc nào?”
Điều này thậm chí còn trở nên mạnh mẽ hơn khi kết hợp với các công cụ như [Deepdocs] tự động hóa quy trình làm việc tài liệu bằng AI. Bạn có thể tải trước các tệp README hoặc schema của dự án, sau đó đặt các câu hỏi tiếp theo hoặc tạo nhật ký thay đổi, ghi chú di chuyển hoặc hướng dẫn cập nhật — tất cả đều cục bộ.
Điều Chỉnh Hiệu Suất Ngầm
Với bản phát hành mới này, Ollama cũng đã cải thiện hiệu suất trên mọi mặt:
- Tăng tốc GPU được tối ưu hóa tốt hơn cho Apple Silicon và các card Nvidia/AMD hiện đại.
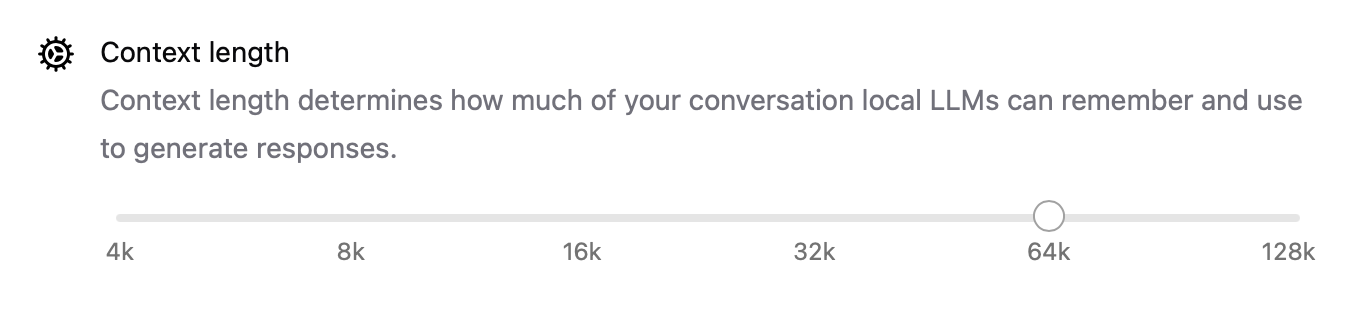
- Độ dài ngữ cảnh hiện có thể cấu hình với các cài đặt như
num_ctx=8192, vì vậy bạn có thể xử lý các đầu vào dài hơn. - Chế độ mạng cho phép Ollama chạy như một máy chủ API cục bộ mà bạn có thể gọi từ các ứng dụng hoặc thiết bị khác trên mạng LAN của mình.
- Giờ đây bạn có thể thay đổi vị trí lưu trữ cho các mô hình đã tải xuống — hoàn hảo nếu bạn đang làm việc từ ổ đĩa ngoài hoặc muốn cô lập các mô hình theo từng dự án.
Những nâng cấp này làm cho ứng dụng trở nên linh hoạt cho mọi thứ, từ tác nhân cục bộ đến công cụ phát triển và trợ lý nghiên cứu cá nhân.
CLI và GUI: Tốt nhất của cả hai thế giới
Phần tốt nhất? Ứng dụng máy tính để bàn mới không thay thế terminal — nó bổ sung cho terminal.
Bạn vẫn có thể:
ollama pull codellama
ollama run codellama
Hoặc hiển thị máy chủ mô hình:
ollama serve --host 0.0.0.0
Vì vậy, nếu bạn đang xây dựng một giao diện AI, tác nhân hoặc plugin tùy chỉnh dựa trên một LLM cục bộ, giờ đây bạn có thể xây dựng dựa trên API của Ollama và sử dụng GUI để tương tác trực tiếp hoặc kiểm thử.
Kiểm thử API của Ollama cục bộ với Apidog
Bạn muốn tích hợp Ollama vào ứng dụng AI của mình hoặc kiểm thử các điểm cuối API cục bộ của nó? Bạn có thể khởi động API REST của Ollama bằng cách sử dụng:
bash tollama serve
Sau đó, sử dụng Apidog để kiểm thử, gỡ lỗi và ghi lại các điểm cuối LLM cục bộ của bạn.

Tại sao nên sử dụng Apidog với Ollama:
- Giao diện trực quan để gửi yêu cầu POST đến máy chủ
http://localhost:11434cục bộ của bạn - Hỗ trợ tạo yêu cầu và xác thực phản hồi có sự hỗ trợ của AI
- Hoàn hảo cho các ứng dụng AI tự lưu trữ, khung tác nhân hoặc công cụ nội bộ
- Hoạt động liền mạch với quy trình làm việc LLM cục bộ và máy chủ mô hình tùy chỉnh
Các Trường Hợp Sử Dụng Thực Tế Dành cho Nhà Phát triển
Đây là nơi ứng dụng Ollama mới tỏa sáng trong các quy trình làm việc thực tế của nhà phát triển:
| Trường hợp sử dụng | Cách Ollama hỗ trợ |
|---|---|
| Trợ lý đánh giá mã | Chạy codellama cục bộ để nhận phản hồi tái cấu trúc |
| Cập nhật tài liệu | Yêu cầu mô hình viết lại, tóm tắt hoặc sửa các tệp tài liệu |
| Chatbot phát triển cục bộ | Nhúng vào ứng dụng của bạn dưới dạng trợ lý nhận biết ngữ cảnh |
| Công cụ nghiên cứu ngoại tuyến | Tải các tệp PDF hoặc sách trắng và đặt các câu hỏi chính |
| Sân chơi LLM cá nhân | Thử nghiệm kỹ thuật prompt và tinh chỉnh |
Đối với các nhóm lo lắng về quyền riêng tư dữ liệu hoặc ảo giác mô hình, các quy trình làm việc LLM ưu tiên cục bộ mang lại một lựa chọn thay thế ngày càng hấp dẫn.
Lời Kết
Phiên bản máy tính để bàn của Ollama khiến các LLM cục bộ không còn giống một thử nghiệm khoa học tạm bợ mà giống một công cụ phát triển hoàn thiện hơn.
Với sự hỗ trợ tương tác tệp, đầu vào đa phương thức, viết tài liệu và hiệu suất gốc, đây là một lựa chọn nghiêm túc cho các nhà phát triển quan tâm đến tốc độ, tính linh hoạt và khả năng kiểm soát.
Không có khóa API đám mây.
- Không theo dõi ngầm.
- Không tính phí theo token.
- Chỉ đơn giản là suy luận cục bộ nhanh chóng với lựa chọn bất kỳ mô hình mã nguồn mở nào phù hợp với nhu cầu của bạn.
Nếu bạn tò mò về việc chạy LLM trên máy của mình, hoặc nếu bạn đã sử dụng Ollama và muốn có trải nghiệm mượt mà hơn, thì bây giờ là lúc để thử lại.