
Các kỹ sư của Mistral AI đã thiết kế Magistral Small 1.2 như một mô hình 24 tỷ tham số ưu tiên hiệu quả suy luận. Phiên bản này được xây dựng trực tiếp dựa trên Mistral Small 1.1. Các kỹ sư đã áp dụng tinh chỉnh có giám sát (supervised fine-tuning) bằng cách sử dụng dấu vết từ Magistral Medium, sau đó là các giai đoạn học tăng cường (reinforcement learning). Do đó, mô hình này vượt trội trong logic đa bước mà không đòi hỏi quá nhiều tài nguyên tính toán.
Tìm hiểu sự phát triển của dòng mô hình Magistral
Nền tảng kiến trúc và thông số kỹ thuật
Magistral Small 1.2 được xây dựng trên nền tảng vững chắc của Magistral 1.1, tích hợp khả năng suy luận nâng cao thông qua tinh chỉnh có giám sát (SFT) từ các dấu vết của Magistral Medium kết hợp với tối ưu hóa học tăng cường (RL). Được xây dựng dựa trên Magistral 1.1, với các khả năng suy luận bổ sung, trải qua SFT từ các dấu vết của Magistral Medium và RL, đây là một mô hình suy luận nhỏ, hiệu quả với 24 tỷ tham số.

Hơn nữa, thiết kế kiến trúc cho phép các kịch bản triển khai hiệu quả. Magistral Small có thể được triển khai cục bộ, vừa vặn trong một chiếc RTX 4090 hoặc MacBook RAM 32GB sau khi được lượng tử hóa. Khả năng tiếp cận này giúp mô hình phù hợp cho cả môi trường doanh nghiệp và nhà phát triển cá nhân.
Các cải tiến kỹ thuật chính trong phiên bản 1.2
Việc chuyển đổi từ phiên bản 1.1 sang 1.2 mang đến một số cải tiến quan trọng, tác động đáng kể đến hiệu suất và khả năng sử dụng của mô hình. Đáng chú ý nhất, các bản cập nhật này giải quyết các hạn chế cơ bản đồng thời mở rộng giới hạn khả năng.
Đột phá tích hợp đa phương thức
Giờ đây, được trang bị bộ mã hóa thị giác, các mô hình này xử lý cả văn bản và hình ảnh một cách liền mạch. Sự tích hợp này đại diện cho một sự thay đổi mô hình từ suy luận chỉ dựa trên văn bản sang hiểu biết đa phương thức toàn diện. Kiến trúc bộ mã hóa thị giác cho phép các mô hình xử lý thông tin hình ảnh trong khi vẫn duy trì khả năng suy luận văn bản của chúng.
Kết quả tối ưu hóa hiệu suất
Cải thiện 15% trên các điểm chuẩn toán học và mã hóa như AIME 24/25 và LiveCodeBench v5/v6. Những cải thiện hiệu suất này trực tiếp chuyển thành các ứng dụng thực tế, đặc biệt mang lại lợi ích cho các nhà phát triển làm việc trong tính toán toán học, phát triển thuật toán và các kịch bản giải quyết vấn đề phức tạp.
Phân tích tính năng toàn diện
Khả năng suy luận nâng cao
Kiến trúc suy luận tích hợp các token tư duy chuyên biệt giúp cấu trúc quá trình suy luận nội bộ của mô hình. Việc triển khai sử dụng các token [THINK] và [/THINK] để gói gọn nội dung suy luận, tạo sự minh bạch trong quá trình ra quyết định của mô hình đồng thời ngăn ngừa sự nhầm lẫn trong quá trình xử lý lời nhắc.
Hơn nữa, hệ thống suy luận hoạt động thông qua các chuỗi suy luận logic mở rộng trước khi tạo ra các phản hồi cuối cùng. Cách tiếp cận này cho phép mô hình giải quyết các vấn đề phức tạp đòi hỏi phân tích đa bước, suy luận toán học và suy luận logic.
Cơ sở hạ tầng hỗ trợ đa ngôn ngữ
Các mô hình thể hiện khả năng hỗ trợ ngôn ngữ toàn diện trên các họ ngôn ngữ đa dạng. Các ngôn ngữ được hỗ trợ trải dài các khu vực Châu Âu, Châu Á, Trung Đông và Nam Á, bao gồm tiếng Anh, Pháp, Đức, Hy Lạp, Hindi, Indonesia, Ý, Nhật Bản, Hàn Quốc, Mã Lai, Nepal, Ba Lan, Bồ Đào Nha, Romania, Nga, Serbia, Tây Ban Nha, Thổ Nhĩ Kỳ, Ukraina, Việt Nam, Ả Rập, Bengali, Trung Quốc và Farsi.
Ngoài ra, khả năng đa ngôn ngữ mở rộng này đảm bảo khả năng tiếp cận toàn cầu và cho phép các nhà phát triển tạo ra các ứng dụng phục vụ thị trường quốc tế mà không yêu cầu triển khai mô hình riêng biệt cho các ngôn ngữ khác nhau.
Kiến trúc xử lý thị giác
Việc tích hợp bộ mã hóa thị giác cho phép phân tích và suy luận hình ảnh tinh vi. Mô hình xử lý nội dung hình ảnh và kết hợp nó với thông tin văn bản để tạo ra các phản hồi toàn diện. Khả năng này mở rộng ngoài nhận dạng hình ảnh đơn giản để bao gồm hiểu ngữ cảnh, suy luận không gian và giải quyết vấn đề thị giác.
Điểm chuẩn hiệu suất và phân tích so sánh
Hiệu suất suy luận toán học
Kết quả điểm chuẩn cho thấy những cải thiện đáng kể trên các chỉ số đánh giá chính. Magistral Small 1.2 đạt 86.14% trên AIME24 pass@1 và 77.34% trên AIME25 pass@1, thể hiện những tiến bộ đáng kể so với phiên bản 1.1 là 70.52% và 62.03% tương ứng.
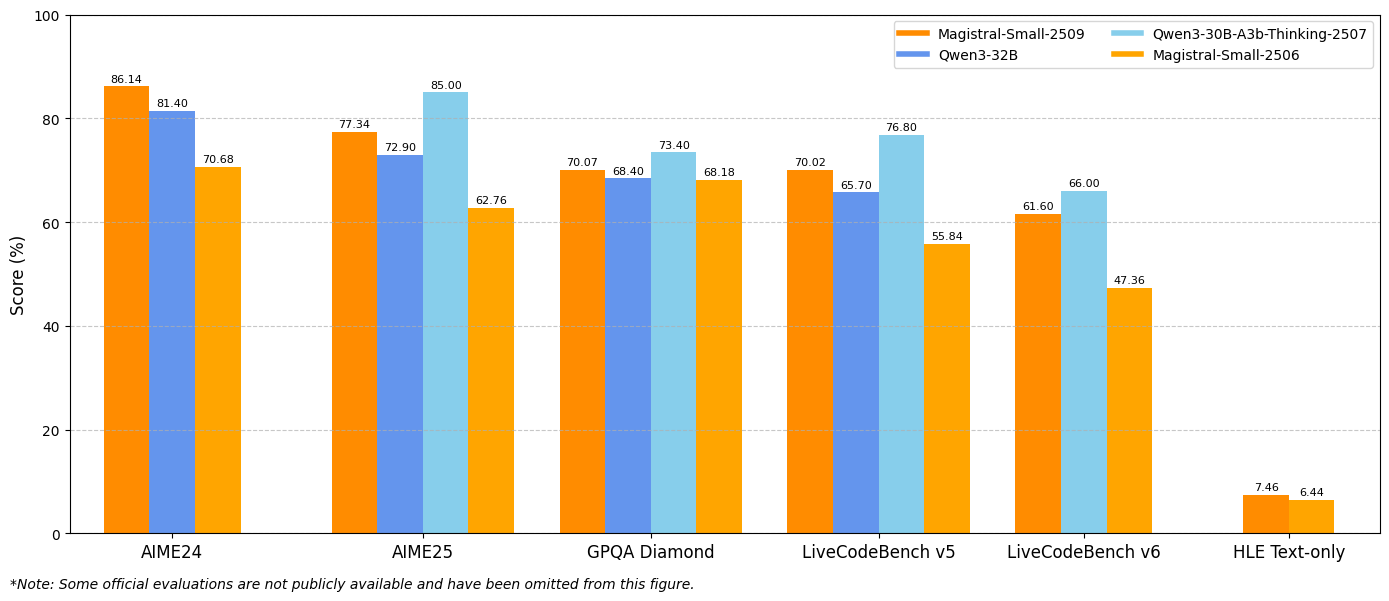
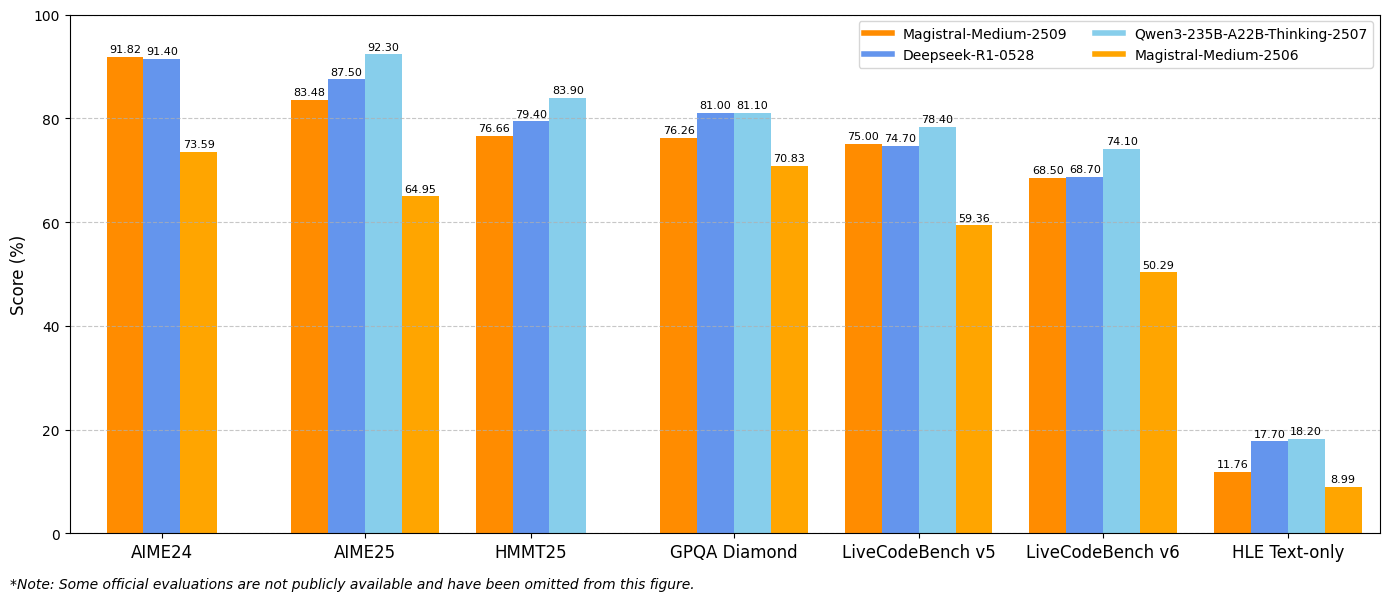
Tương tự, Magistral Medium 1.2 mang lại hiệu suất vượt trội với 91.82% trên AIME24 pass@1 và 83.48% trên AIME25 pass@1, vượt qua phiên bản 1.1 là 72.03% và 60.99%. Những cải tiến này cho thấy khả năng suy luận toán học được nâng cao, mang lại lợi ích trực tiếp cho tính toán khoa học, ứng dụng kỹ thuật và môi trường nghiên cứu.
Các chỉ số hiệu suất mã hóa
Các đánh giá của LiveCodeBench cho thấy những cải thiện đáng kể về khả năng mã hóa. Magistral Small 1.2 đạt 70.88% trên LiveCodeBench v5, trong khi Magistral Medium 1.2 đạt 75.00%. Những điểm số này đại diện cho những tiến bộ có ý nghĩa trong các tác vụ tạo mã, gỡ lỗi và triển khai thuật toán.
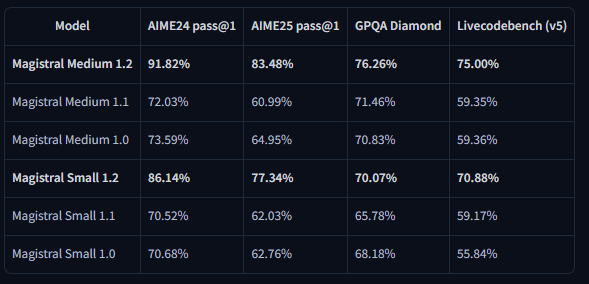
Hơn nữa, các mô hình thể hiện sự hiểu biết tốt hơn về các khái niệm lập trình, các mẫu kiến trúc phần mềm và các phương pháp gỡ lỗi. Hiệu suất mã hóa nâng cao này mang lại lợi ích cho các nhóm phát triển phần mềm, các khung kiểm thử tự động và môi trường lập trình giáo dục.
Kết quả GPQA Diamond
Kết quả điểm chuẩn General Purpose Question Answering (GPQA) Diamond thể hiện khả năng ứng dụng kiến thức rộng rãi của các mô hình. Magistral Small 1.2 đạt 70.07%, trong khi Magistral Medium 1.2 đạt 76.26%. Những điểm số này phản ánh khả năng của các mô hình trong việc xử lý các loại câu hỏi đa dạng đòi hỏi kiến thức liên ngành và suy luận.
Chiến lược triển khai và tích hợp
Cấu hình môi trường phát triển
Việc triển khai Magistral Small 1.2 và Magistral Medium 1.2 đòi hỏi các cấu hình kỹ thuật cụ thể để tối ưu hóa hiệu suất. Các tham số lấy mẫu được khuyến nghị bao gồm top_p: 0.95, temperature: 0.7 và max_tokens: 131072. Các cài đặt này cân bằng sự sáng tạo với tính nhất quán đồng thời hỗ trợ các chuỗi suy luận mở rộng.
Ngoài ra, các mô hình hỗ trợ nhiều khung triển khai khác nhau bao gồm vLLM, Transformers, llama.cpp và các định dạng lượng tử hóa chuyên biệt. Tính linh hoạt này cho phép tích hợp trên các môi trường tính toán và trường hợp sử dụng khác nhau.
Tích hợp API với Apidog
Apidog cung cấp các công cụ toàn diện để kiểm thử và tích hợp API Magistral vào các ứng dụng của bạn. Nền tảng này hỗ trợ các kịch bản kiểm thử API nâng cao, bao gồm xử lý đầu vào đa phương thức, phân tích dấu vết suy luận và giám sát hiệu suất. Thông qua giao diện của Apidog, các nhà phát triển có thể kiểm thử hiệu quả các kết hợp hình ảnh-văn bản, xác thực đầu ra suy luận và tối ưu hóa các tham số gọi API.
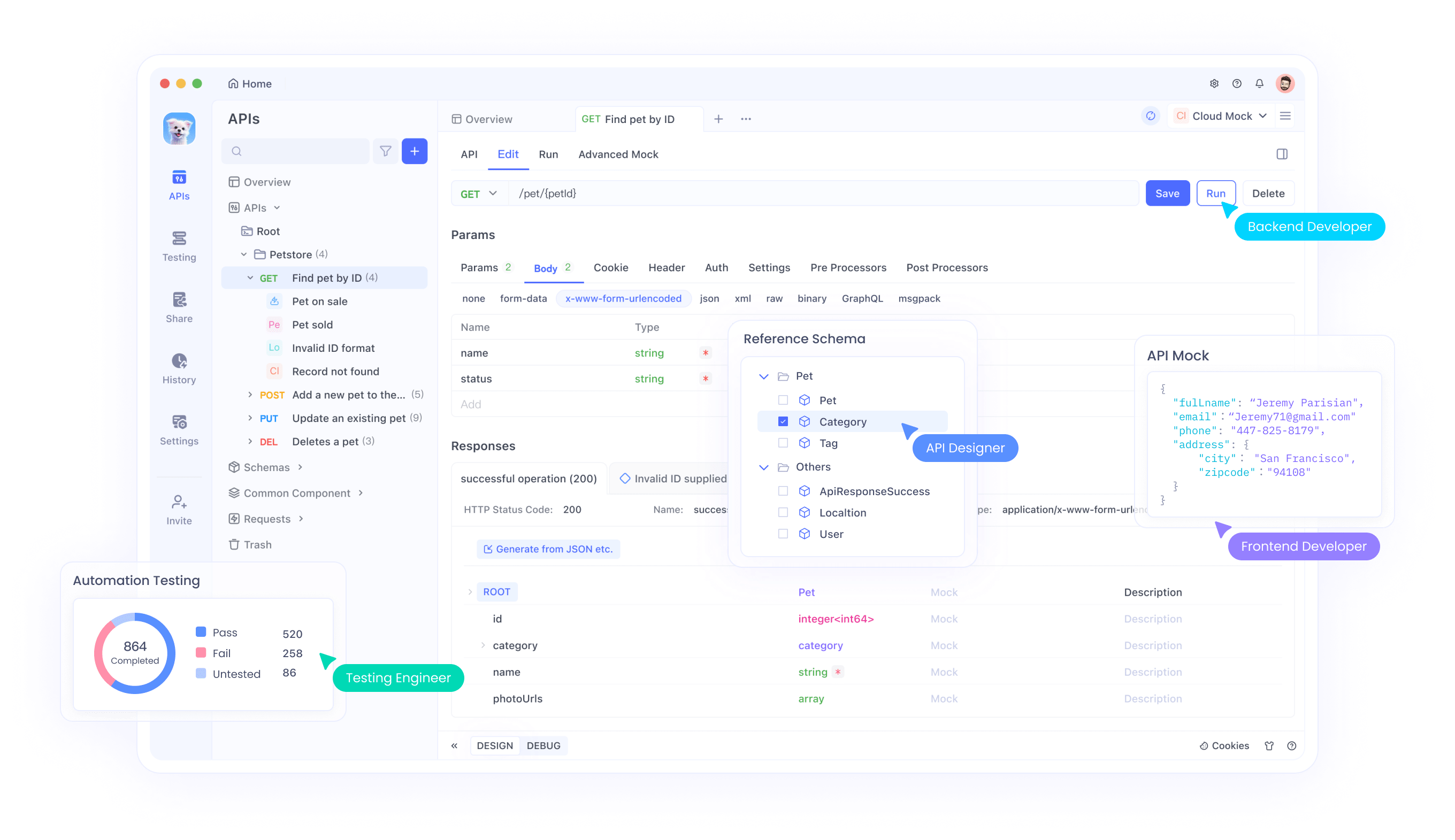
Hơn nữa, các tính năng cộng tác của Apidog cho phép các nhóm chia sẻ cấu hình kiểm thử API, tài liệu về các mẫu tích hợp và duy trì các tiêu chuẩn kiểm thử nhất quán trong suốt các chu kỳ phát triển. Cách tiếp cận hợp tác này giúp tăng tốc thời gian phát triển đồng thời đảm bảo triển khai API mạnh mẽ.
Tối ưu hóa lời nhắc hệ thống
Các mô hình yêu cầu các lời nhắc hệ thống được soạn thảo cẩn thận để đạt được hiệu suất tối ưu. Cấu trúc lời nhắc hệ thống được khuyến nghị bao gồm hướng dẫn suy luận, hướng dẫn định dạng và thông số kỹ thuật ngôn ngữ. Lời nhắc nên yêu cầu rõ ràng các quy trình tư duy bằng cách sử dụng các token chuyên biệt đồng thời duy trì định dạng phản hồi nhất quán.
Hơn nữa, việc tùy chỉnh lời nhắc hệ thống cho phép tối ưu hóa cụ thể cho ứng dụng. Các nhà phát triển có thể sửa đổi lời nhắc để nhấn mạnh các mẫu suy luận cụ thể, điều chỉnh định dạng đầu ra hoặc tích hợp các yêu cầu kiến thức chuyên biệt theo miền.
Tìm hiểu sâu về triển khai kỹ thuật
Yêu cầu về bộ nhớ và tính toán
Magistral Small 1.2 hoạt động hiệu quả trong các môi trường phần cứng hạn chế mà vẫn duy trì hiệu suất cao. Kiến trúc 24 tỷ tham số cho phép triển khai trên phần cứng cấp người tiêu dùng khi được lượng tử hóa đúng cách, giúp các khả năng suy luận nâng cao có thể tiếp cận được với các nhà phát triển cá nhân và các nhóm nhỏ.
Hơn nữa, các cải tiến về hiệu quả tính toán trong phiên bản 1.2 giảm độ trễ suy luận trong khi vẫn duy trì chất lượng suy luận. Tối ưu hóa này cho phép các ứng dụng thời gian thực và hệ thống tương tác yêu cầu tạo phản hồi ngay lập tức.
Cửa sổ ngữ cảnh và khả năng xử lý
Các mô hình hỗ trợ cửa sổ ngữ cảnh 128.000 token, cho phép xử lý các tài liệu mở rộng, các cuộc hội thoại phức tạp và các tác vụ phân tích quy mô lớn. Mặc dù hiệu suất có thể suy giảm ngoài 40.000 token, các mô hình vẫn duy trì chức năng hợp lý trên toàn bộ phạm vi ngữ cảnh.
Ngoài ra, khả năng ngữ cảnh mở rộng cho phép phân tích tài liệu toàn diện, các tác vụ suy luận dài và các cuộc hội thoại đa lượt với nhận thức ngữ cảnh được duy trì. Khả năng này hỗ trợ các ứng dụng doanh nghiệp yêu cầu xử lý thông tin mở rộng.
Kỹ thuật lượng tử hóa và tối ưu hóa
Các mô hình hỗ trợ nhiều định dạng lượng tử hóa khác nhau thông qua triển khai GGUF, cho phép triển khai trên các cấu hình phần cứng khác nhau. Các tối ưu hóa này giảm yêu cầu về bộ nhớ trong khi vẫn giữ được khả năng suy luận, giúp các mô hình có thể tiếp cận được trong các môi trường hạn chế tài nguyên.
Hơn nữa, các kỹ thuật tối ưu hóa chuyên biệt duy trì tốc độ suy luận trong khi hỗ trợ các hoạt động suy luận phức tạp. Những cải tiến kỹ thuật này đảm bảo khả năng triển khai thực tế trên các môi trường tính toán đa dạng.
Kiểm thử và xác thực với Apidog
Chiến lược kiểm thử API toàn diện
Apidog cung cấp các công cụ thiết yếu để xác thực tích hợp mô hình Magistral thông qua các khung kiểm thử toàn diện. Nền tảng này hỗ trợ kiểm thử đầu vào đa phương thức, xác thực dấu vết suy luận và đo điểm chuẩn hiệu suất. Các nhóm có thể tạo bộ kiểm thử để xác minh cả tính đúng đắn về chức năng và đặc điểm hiệu suất.
Khả năng kiểm thử tự động của Apidog cho phép các quy trình làm việc tích hợp liên tục, đảm bảo tính nhất quán về hiệu suất mô hình trong suốt các chu kỳ phát triển. Tự động hóa này giảm chi phí kiểm thử thủ công đồng thời duy trì các tiêu chuẩn đảm bảo chất lượng.
Giám sát và tối ưu hóa hiệu suất
Thông qua khả năng giám sát của Apidog, các nhóm phát triển có thể theo dõi các chỉ số hiệu suất API, xác định cơ hội tối ưu hóa và duy trì độ tin cậy của dịch vụ. Nền tảng này cung cấp phân tích chi tiết về thời gian phản hồi, chất lượng suy luận và các mẫu sử dụng tài nguyên.
Hơn nữa, dữ liệu giám sát cho phép các chiến lược tối ưu hóa chủ động nhằm cải thiện hiệu suất ứng dụng và trải nghiệm người dùng. Cách tiếp cận dựa trên dữ liệu này đảm bảo việc sử dụng mô hình tối ưu trên các môi trường sản xuất.
Kết luận
Magistral Small 1.2 và Magistral Medium 1.2 đại diện cho những tiến bộ đáng kể trong công nghệ suy luận AI đa phương thức. Sự kết hợp giữa hiệu suất toán học nâng cao, khả năng thị giác và tính minh bạch trong suy luận được cải thiện tạo ra các công cụ mạnh mẽ cho các ứng dụng đa dạng, từ nghiên cứu khoa học đến phát triển phần mềm.
Những cải thiện về khả năng tiếp cận thông qua các tùy chọn triển khai cục bộ và hỗ trợ API toàn diện dân chủ hóa quyền truy cập vào các khả năng suy luận nâng cao. Các tổ chức giờ đây có thể tích hợp suy luận AI tinh vi vào quy trình làm việc của họ mà không yêu cầu đầu tư cơ sở hạ tầng lớn.
Cho dù bạn đang phát triển các ứng dụng giáo dục, tiến hành nghiên cứu khoa học hay xây dựng các hệ thống phần mềm phức tạp, Magistral Small 1.2 và Magistral Medium 1.2 đều cung cấp các khả năng suy luận cần thiết cho các ứng dụng AI thế hệ tiếp theo. Kết hợp với các công cụ kiểm thử và tích hợp mạnh mẽ như Apidog, các mô hình này cho phép các quy trình phát triển toàn diện, đẩy nhanh đổi mới đồng thời duy trì các tiêu chuẩn chất lượng.