
Cảnh quan trí tuệ nhân tạo đã được chuyển biến cơ bản với sự ra mắt của Llama 4 từ Meta - không chỉ thông qua các cải tiến từng bước, mà còn thông qua những đột phá kiến trúc định nghĩa lại tỷ lệ hiệu suất trên chi phí trong toàn ngành. Các mô hình mới này đại diện cho sự hội tụ của ba đổi mới quan trọng: đa mô thức gốc thông qua các kỹ thuật fusion sớm, kiến trúc hỗn hợp thưa thớt (MoE) cải thiện đáng kể hiệu quả tham số, và mở rộng cửa sổ ngữ cảnh kéo dài đến 10 triệu token chưa từng có.
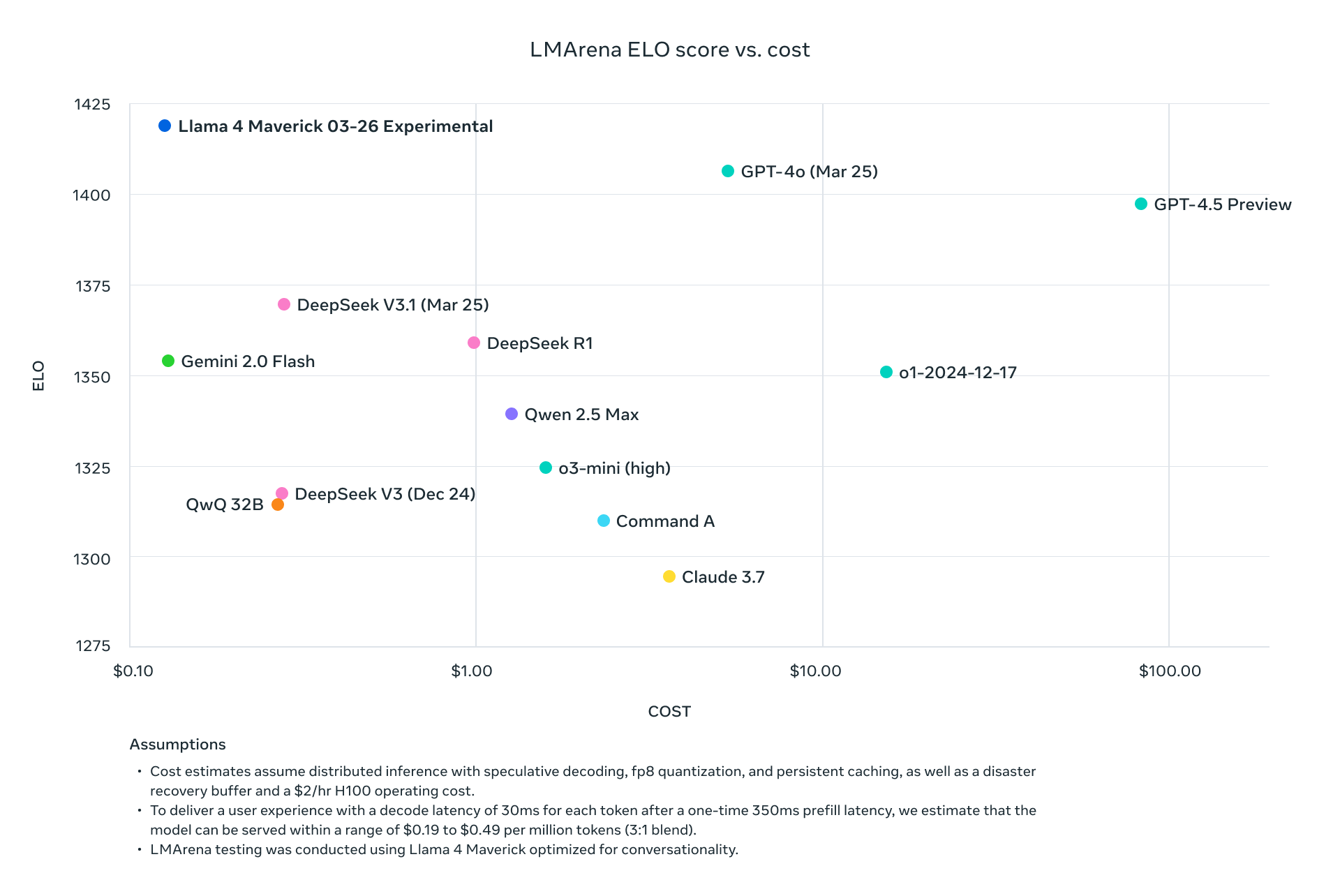
Llama 4 Scout và Maverick không chỉ cạnh tranh với các nhà lãnh đạo ngành hiện tại - mà còn vượt trội hơn họ một cách có hệ thống trên các tiêu chuẩn đo lường trong khi giảm đáng kể yêu cầu tính toán. Với Maverick đạt được kết quả tốt hơn GPT-4o với chi phí khoảng một phần chín mỗi token, và Scout phù hợp trên một GPU H100 trong khi duy trì hiệu suất vượt trội so với các mô hình yêu cầu nhiều GPU, Meta đã thay đổi cơ bản kinh tế của việc triển khai AI tiên tiến.
Phân tích kỹ thuật này phân tích các đổi mới kiến trúc làm động lực cho các mô hình này, trình bày dữ liệu đo lường toàn diện trên các nhiệm vụ lý luận, lập trình, đa ngôn ngữ và đa mô thức, và xem xét cấu trúc giá API trên các nhà cung cấp lớn. Đối với các nhà ra quyết định kỹ thuật đánh giá các lựa chọn hạ tầng AI, chúng tôi cung cấp các so sánh hiệu suất/chi phí chi tiết và các chiến lược triển khai để tối đa hóa hiệu quả của các mô hình đột phá này trong môi trường sản xuất.
Bạn có thể tải xuống Meta Llama 4 mã nguồn mở và trọng số mở trên Hugging Face, tính đến hôm nay:
https://huggingface.co/collections/meta-llama/llama-4-67f0c30d9fe03840bc9d0164

Llama 4 đã lưu trữ cửa sổ ngữ cảnh 10M như thế nào?
Triển khai Hỗn hợp Chuyên gia (MoE)
Tất cả các mô hình Llama 4 sử dụng một kiến trúc MoE tinh vi thay đổi cơ bản phương trình hiệu quả:
| Mô hình | Tham số hoạt động | Số lượng Chuyên gia | Tổng Tham số | Phương pháp Kích hoạt Tham số |
|---|---|---|---|---|
| Llama 4 Scout | 17B | 16 | 109B | Định tuyến theo từng token |
| Llama 4 Maverick | 17B | 128 | 400B | Chuyên gia định tuyến chung + đơn lẻ theo từng token |
| Llama 4 Behemoth | 288B | 16 | ~2T | Định tuyến theo từng token |
Thiết kế MoE trong Llama 4 Maverick đặc biệt tinh vi, sử dụng các lớp dày đặc và MoE luân phiên. Mỗi token kích hoạt chuyên gia chung cộng với một trong 128 chuyên gia được định tuyến, có nghĩa là chỉ khoảng 17B trong tổng số 400B tham số được kích hoạt để xử lý bất kỳ token nào nhất định.
Kiến trúc Đa Mô Thức
Kiến trúc Đa Mô Thức của Llama 4:
├── Token Văn Bản
│ └── Đường dẫn xử lý văn bản gốc
├── Mã hóa Hình Ảnh (MetaCLIP Nâng cao)
│ ├── Xử lý hình ảnh
│ └── Chuyển đổi hình ảnh thành chuỗi token
└── Lớp Fusion Sớm
└── Hợp nhất các token văn bản và hình ảnh trong khung xương mô hình
Cách tiếp cận fusion sớm này cho phép tiền huấn luyện trên hơn 30 triệu token từ dữ liệu văn bản, hình ảnh và video trộn lẫn, dẫn đến khả năng đa mô thức đồng nhất hơn nhiều so với các phương pháp retrofitting.
Kiến trúc iRoPE cho Cửa sổ Ngữ cảnh Mở rộng
Cửa sổ ngữ cảnh 10M token của Llama 4 Scout tận dụng kiến trúc iRoPE đổi mới:
# Mã giả cho kiến trúc iRoPE
def iRoPE_layer(tokens, layer_index):
if layer_index % 2 == 0:
# Lớp chẵn: Chú ý xen kẽ mà không có nhúng vị trí
return attention_no_positional(tokens)
else:
# Lớp lẻ: RoPE (Nhúng vị trí quay)
return attention_with_rope(tokens)
def inference_scaling(tokens, temperature_factor):
# Kích thước nhiệt độ trong quá trình suy diễn cải thiện sự tổng quát độ dài
return scale_attention_scores(tokens, temperature_factor)
Kiến trúc này cho phép Scout xử lý các tài liệu có độ dài chưa từng có trong khi duy trì sự nhất quán, với hệ số tỉ lệ khoảng 80 lần lớn hơn so với các cửa sổ ngữ cảnh của các mô hình Llama trước đó.
Phân Tích Tiêu Chuẩn Toàn Diện
Tiêu Chuẩn Hiệu Suất Đo Lường Thông Thường
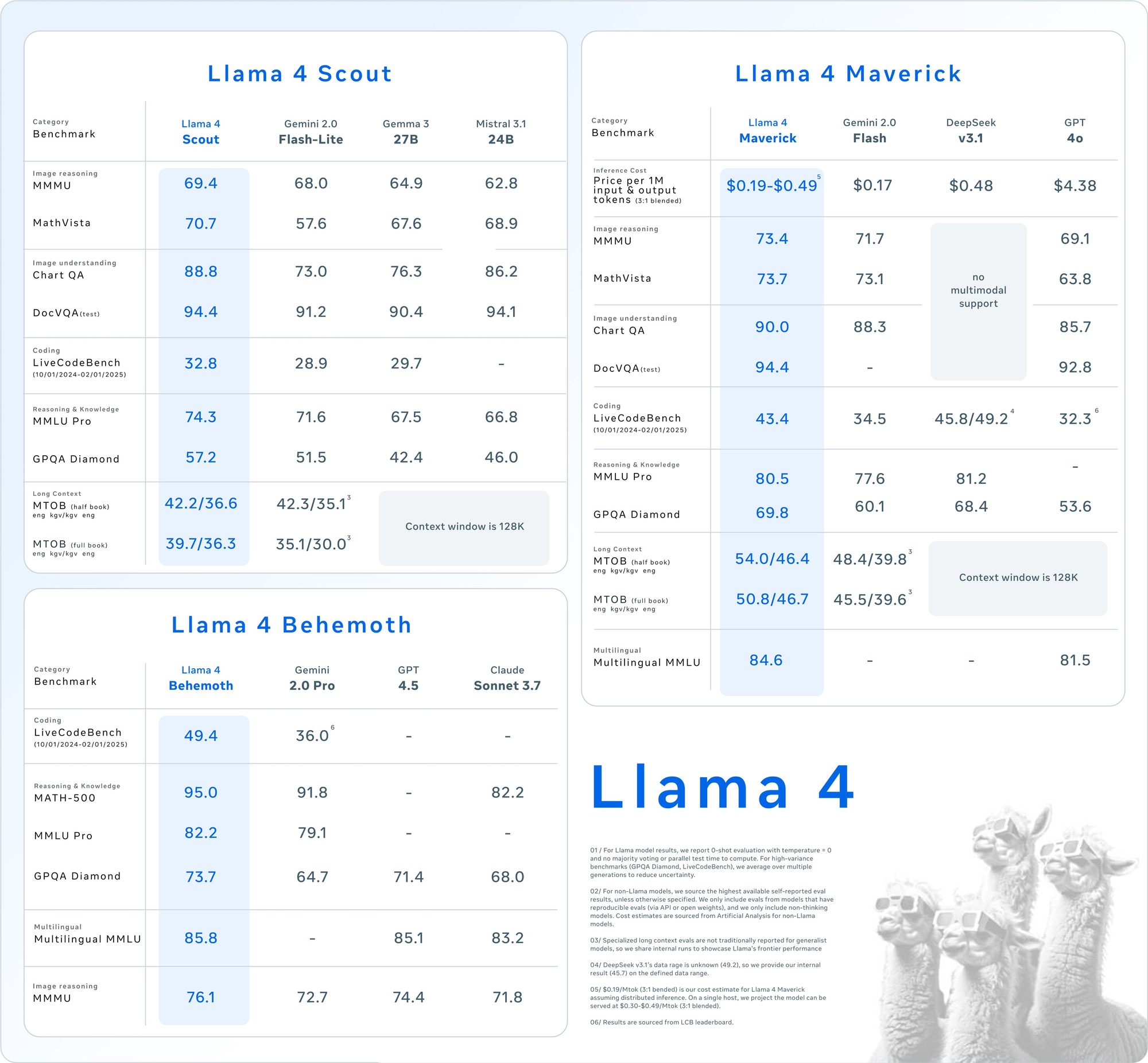
Kết quả đo lường chi tiết qua các bộ đánh giá lớn tiết lộ vị trí cạnh tranh của các mô hình Llama 4:
| Danh mục | Tiêu chuẩn | Llama 4 Maverick | GPT-4o | Gemini 2.0 Flash | DeepSeek v3.1 |
|---|---|---|---|---|---|
| Lý luận hình ảnh | MMMU | 73.4 | 69.1 | 71.7 | Không hỗ trợ đa mô thức |
| MathVista | 73.7 | 63.8 | 73.1 | Không hỗ trợ đa mô thức | |
| Hiểu hình ảnh | ChartQA | 90.0 | 85.7 | 88.3 | Không hỗ trợ đa mô thức |
| DocVQA (kiểm tra) | 94.4 | 92.8 | - | Không hỗ trợ đa mô thức | |
| Lập trình | LiveCodeBench | 43.4 | 32.3 | 34.5 | 45.8/49.2 |
| Lý luận & Kiến thức | MMLU Pro | 80.5 | - | 77.6 | 81.2 |
| GPQA Diamond | 69.8 | 53.6 | 60.1 | 68.4 | |
| Đa ngôn ngữ | MMLU Đa ngôn ngữ | 84.6 | 81.5 | - | - |
| Ngữ cảnh dài | MTOB (nửa cuốn sách) eng→kgv/kgv→eng | 54.0/46.4 | Ngữ cảnh giới hạn ở 128K | 48.4/39.8 | Ngữ cảnh giới hạn ở 128K |
| MTOB (cuốn sách đầy đủ) eng→kgv/kgv→eng | 50.8/46.7 | Ngữ cảnh giới hạn ở 128K | 45.5/39.6 | Ngữ cảnh giới hạn ở 128K |
Phân Tích Kỹ Thuật về Hiệu suất theo Danh mục
Khả Năng Xử Lý Đa Mô Thức
Llama 4 thể hiện hiệu suất vượt trội trên các nhiệm vụ đa mô thức, với Maverick đạt 73.4% trên MMMU so với 69.1% của GPT-4o và 71.7% của Gemini 2.0 Flash. Khoảng cách hiệu suất này càng rộng hơn trên MathVista, nơi Maverick đạt 73.7% so với 63.8% của GPT-4o.
<