
Thế giới các mô hình ngôn ngữ lớn (LLM) đang phát triển với tốc độ chóng mặt, nhưng những thách thức về hiệu quả và khả năng thích ứng theo thời gian thực vẫn còn tồn tại. Vào ngày 10 tháng 9 năm 2025, Moonshot AI—lực lượng đổi mới đứng sau dòng sản phẩm Kimi—đã ra mắt checkpoint-engine, một middleware mã nguồn mở định nghĩa lại việc cập nhật trọng số trong các công cụ suy luận LLM. Được thiết kế riêng cho học tăng cường (RL), công cụ nhẹ này có thể làm mới một mô hình khổng lồ 1 nghìn tỷ tham số như Kimi-K2 trên hàng nghìn GPU chỉ trong 20 giây, giảm đáng kể thời gian ngừng hoạt động và tăng cường khả năng mở rộng.
Bài viết này đi sâu vào cơ chế của checkpoint-engine, từ kiến trúc đến các điểm chuẩn, đồng thời làm nổi bật ý nghĩa của nó đối với RL và sự phù hợp với hệ sinh thái rộng lớn hơn. Bằng cách mã nguồn mở viên ngọc quý này, Moonshot AI trao quyền cho cộng đồng để đẩy xa hơn ranh giới của LLM. Hãy cùng khám phá sự đổi mới này từng lớp một.
Tìm hiểu về Checkpoint-Engine: Các khái niệm cốt lõi và kiến trúc
Checkpoint-Engine là gì?
Về cốt lõi, checkpoint-engine là một middleware giúp cập nhật trọng số tại chỗ, liền mạch cho LLM trong quá trình suy luận. Điều này rất quan trọng trong RL, nơi các mô hình phát triển thông qua phản hồi lặp lại mà không cần đào tạo lại hoàn toàn. Các phương pháp truyền thống làm chậm hệ thống với thời gian tải lại kéo dài; checkpoint-engine khắc phục điều này bằng một phương pháp tinh gọn, chi phí thấp.
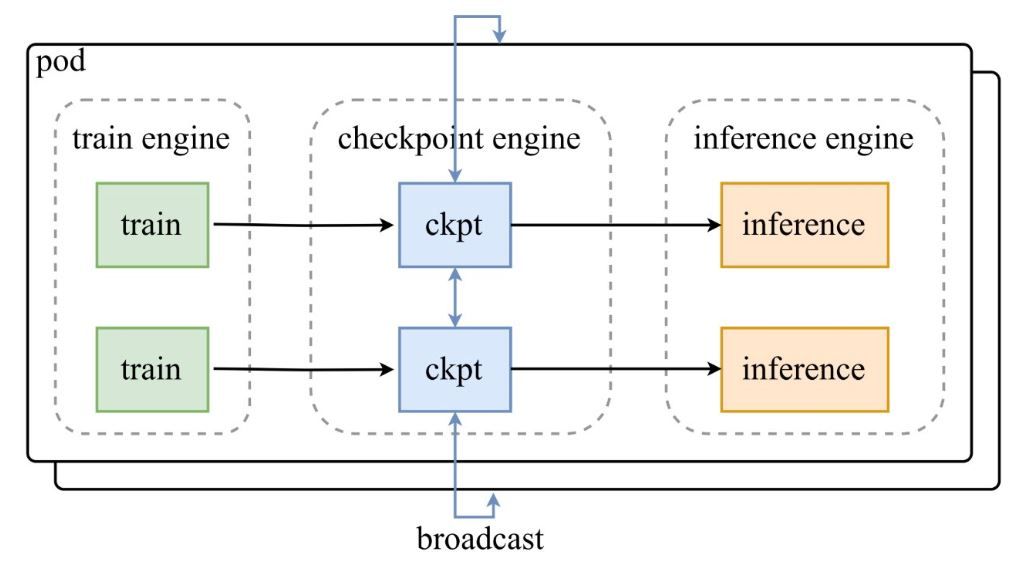
Như được thể hiện trong sơ đồ kiến trúc từ bài đăng thông báo của Moonshot AI, một nhóm các công cụ đào tạo (train engines) cung cấp các checkpoint cho checkpoint-engine trung tâm, sau đó checkpoint-engine này phát sóng các bản cập nhật đến các công cụ suy luận (inference engines). Kho lưu trữ GitHub đi sâu vào mã nguồn, làm nổi bật lớp ParameterServer như là bộ điều phối cập nhật.
Các thành phần kiến trúc
- Train Engine (Công cụ Đào tạo): Tạo ra các trọng số mới từ quá trình đào tạo RL đang diễn ra, ghi lại các tinh chỉnh chính sách trong môi trường động.
- Checkpoint Engine (Công cụ Checkpoint): Lõi của middleware, được đặt cùng với suy luận để giảm thiểu độ trễ. Nó xử lý việc thu thập siêu dữ liệu và thực hiện cập nhật thông qua chế độ Broadcast hoặc P2P.
- Inference Engine (Công cụ Suy luận): Tích hợp các bản cập nhật ngay lập tức, duy trì tính liên tục của dịch vụ trên các cụm GPU phân tán.
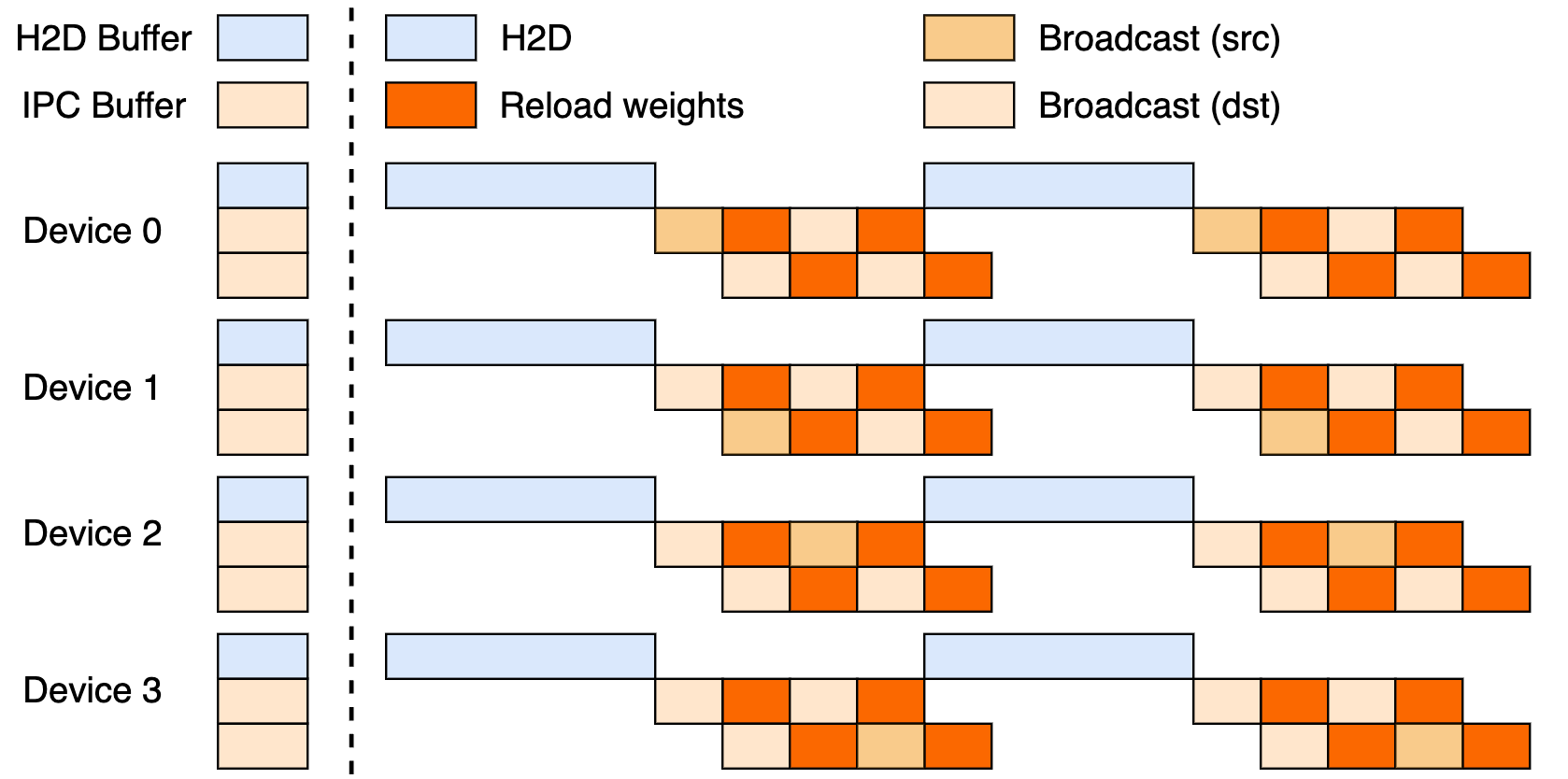
Thiết lập này tận dụng một pipeline ba giai đoạn: truyền dữ liệu từ Host đến Device (H2D), phát sóng giữa các worker sử dụng CUDA IPC và tải lại có mục tiêu. Bằng cách chồng chéo các giai đoạn này, nó tối đa hóa việc sử dụng GPU và hạn chế các nút thắt cổ chai trong việc truyền dữ liệu.
Cập nhật Broadcast so với P2P
Broadcast nổi bật trong các bản cập nhật đồng bộ, toàn cụm—chế độ mặc định của nó để đạt tốc độ cao nhất, phân nhóm dữ liệu để luồng tối ưu. Trong khi đó, P2P xuất sắc trong các kịch bản linh hoạt, như mở rộng quy mô trong thời gian cao điểm, bằng cách sử dụng RDMA thông qua mooncake-transfer-engine để tránh gián đoạn. Tính hai mặt này làm cho checkpoint-engine trở nên linh hoạt cho cả triển khai ổn định và linh hoạt.
Điểm chuẩn hiệu suất: Nhanh đến mức nào là đủ?
Cập nhật một mô hình nghìn tỷ tham số trong 20 giây
Thành tựu nổi bật của Checkpoint-engine? Cập nhật 1 nghìn tỷ tham số của Kimi-K2 trên hàng nghìn GPU chỉ trong khoảng 20 giây. Điều này xuất phát từ việc sử dụng pipeline thông minh: lập kế hoạch siêu dữ liệu đặt kích thước nhóm hiệu quả, các socket ZeroMQ điều phối việc truyền dữ liệu, và các giai đoạn H2D/broadcast chồng chéo giúp ẩn độ trễ.
Hãy so sánh điều này với các kỹ thuật cũ, vốn có thể làm hệ thống ngừng hoạt động trong nhiều phút giữa các lần xáo trộn dữ liệu lớn. Triết lý cập nhật tại chỗ của Checkpoint-engine giúp suy luận hoạt động trơn tru, lý tưởng cho nhu cầu thích ứng nhanh chóng của RL.
Phân tích điểm chuẩn
Bảng điểm chuẩn cho thấy kết quả xuất sắc trên các mô hình và thiết lập, được kiểm tra với vLLM v0.10.2rc1:
| Mô hình | Thông tin thiết bị | Thu thập siêu dữ liệu | Cập nhật (Broadcast) | Cập nhật (P2P) |
|---|---|---|---|---|
| GLM-4.5-Air (BF16) | 8xH800 TP8 | 0.17s | 3.94s (1.42GiB) | 8.83s (4.77GiB) |
| Qwen3-235B-A22B-Instruct-2507 (BF16) | 8xH800 TP8 | 0.46s | 6.75s (2.69GiB) | 16.47s (4.05GiB) |
| DeepSeek-V3.1 (FP8) | 16xH20 TP16 | 1.44s | 12.22s (2.38GiB) | 25.77s (3.61GiB) |
| Kimi-K2-Instruct (FP8) | 16xH20 TP16 | 1.81s | 15.45s (2.93GiB) | 36.24s (4.46GiB) |
| DeepSeek-V3.1 (FP8) | 256xH20 TP16 | 1.40s | 13.88s (2.54GiB) | 33.30s (3.86GiB) |
| Kimi-K2-Instruct (FP8) | 256xH20 TP16 | 1.88s | 21.50s (2.99GiB) | 34.49s (4.57GiB) |
Bạn có thể tái tạo những kết quả này thông qua ví dụ examples/update.py trong kho lưu trữ. Các lần chạy FP8 cần các bản vá vLLM, nhấn mạnh hiệu quả ở quy mô lớn.
Ý nghĩa đối với Học tăng cường
RL phát triển mạnh nhờ các lần lặp nhanh; chu kỳ dưới 20 giây của checkpoint-engine cho phép các vòng lặp học tập liên tục, vượt trội so với các phương pháp theo lô. Điều này mở khóa các ứng dụng phản hồi nhanh—từ các tác nhân thích ứng đến các chatbot đang phát triển—nơi mỗi giây đều quan trọng trong việc tinh chỉnh chính sách.
Triển khai kỹ thuật: Đi sâu vào cơ sở mã nguồn
Khả năng tiếp cận mã nguồn mở
Việc Moonshot AI phát hành trên GitHub dân chủ hóa các công cụ RL ưu việt. ParameterServer là nền tảng cho các bản cập nhật, cung cấp Broadcast (chia sẻ CUDA IPC nhanh) và P2P (RDMA cho người mới). Các ví dụ như update.py và các bài kiểm thử (test_update.py) giúp việc bắt đầu dễ dàng hơn.
Khả năng tương thích bắt đầu với vLLM (thông qua các tiện ích mở rộng worker), với các hook cho SGLang đang được xem xét tiếp theo. Pipeline ba giai đoạn một phần gợi ý về tiềm năng chưa được khai thác.
Các kỹ thuật tối ưu hóa
Những điểm thông minh chính bao gồm:
- Pipelined Overlaps (Chồng chéo Pipeline): Giao tiếp và sao chép chạy đồng thời, giảm đáng kể thời gian thực tế.
- Bucket Optimization (Tối ưu hóa nhóm): Kích thước được điều chỉnh dựa trên siêu dữ liệu phù hợp với việc phân chia và mạng lưới.
- ZeroMQ Control (Kiểm soát ZeroMQ): Tín hiệu độ trễ thấp đến các công cụ suy luận.
Những kỹ thuật này giải quyết các trở ngại liên quan đến hàng nghìn tỷ tham số, từ xung đột PCIe đến tình trạng thiếu bộ nhớ (chuyển sang chế độ nối tiếp nếu cần).
Những hạn chế hiện tại
Kênh P2P của rank-0 có thể bị tắc nghẽn ở quy mô lớn, và pipeline hoàn chỉnh đang chờ được hoàn thiện. Việc tập trung vào vLLM giới hạn phạm vi, nhưng các bản vá giúp khắc phục khoảng trống FP8 cho các mô hình như DeepSeek-V3.1. Hãy theo dõi kho lưu trữ để biết các phát triển tiếp theo.
Tích hợp với các Framework hiện có: vLLM và hơn thế nữa
Hợp tác với vLLM
Checkpoint-engine kết hợp tự nhiên với PagedAttention của vLLM để suy luận RL mượt mà. Bộ đôi này đạt được đồng bộ hóa 20 giây trên các mô hình 1T, như đã được hé lộ trong các bản cập nhật của vLLM—một sự ghi nhận cho sự hợp tác mở rộng thông lượng.
Các mở rộng tiềm năng cho Claude và Apidog
Mở rộng sang Claude của Anthropic có thể truyền tải động lực RL vào các cuộc trò chuyện tập trung vào an toàn của nó, cho phép tinh chỉnh trực tiếp. Apidog hoàn toàn phù hợp cho việc mô phỏng điểm cuối trong quá trình điều chỉnh ZeroMQ—tải Apidog miễn phí để tạo nguyên mẫu các cầu nối này một cách dễ dàng.
Tác động đến hệ sinh thái rộng lớn hơn
Việc tích hợp vào Ollama hoặc LM Studio có thể nội địa hóa sức mạnh của mô hình nghìn tỷ tham số, san bằng sân chơi cho các nhà phát triển độc lập. Hiệu ứng lan tỏa này thúc đẩy một cảnh quan AI toàn diện hơn.
Triển vọng tương lai: Điều gì đang chờ đợi Checkpoint-Engine?
Cải thiện khả năng mở rộng và hiệu suất
Việc triển khai pipeline hoàn chỉnh có thể rút ngắn thêm vài giây, trong khi việc phân cấp P2P loại bỏ các nút thắt cổ chai để đạt được độ đàn hồi thực sự. Các điều chỉnh RDMA hứa hẹn khả năng vượt trội trên nền tảng đám mây.
Đóng góp từ cộng đồng
Mã nguồn mở mời gọi các bản sửa lỗi và chuyển đổi—hãy nghĩ đến việc hợp nhất SGLang hoặc các chế độ không phụ thuộc PCIe. Những phản hồi sớm trên Twitter tràn đầy sự phấn khích, thúc đẩy đà phát triển.
Ứng dụng trong công nghiệp
Từ dịch thuật thời gian thực đến RL tự lái, checkpoint-engine phù hợp với các lĩnh vực có sự thay đổi lớn. Tốc độ của nó giữ cho các mô hình luôn mới mẻ, vượt trội so với các đối thủ về sự linh hoạt.
Một kỷ nguyên mới cho suy luận LLM?
Checkpoint-engine báo hiệu một tương lai LLM linh hoạt, giải quyết các vấn đề về trọng số với phong cách mã nguồn mở. Việc làm mới 1T tham số trong 20 giây đó, được hỗ trợ bởi kiến trúc thông minh và các điểm chuẩn, củng cố vị thế của nó trong RL—bất kể những hạn chế nào.
Kết hợp nó với Apidog cho quy trình phát triển hoặc Claude cho các tính năng thông minh lai, và sự đổi mới sẽ bùng nổ. Theo dõi GitHub, tải Apidog miễn phí và tham gia cuộc cách mạng định hình lại suy luận ngay hôm nay!