
Bạn có bao giờ muốn chạy một mô hình ngôn ngữ mạnh mẽ trên máy tính của mình không? Giới thiệu QwQ-32B, mô hình LLM mới nhất và mạnh mẽ nhất của Alibaba hiện có. Dù bạn là một nhà phát triển, nhà nghiên cứu hay chỉ là một người đam mê công nghệ, việc chạy QwQ-32B cục bộ có thể mở ra một thế giới cơ hội—from việc xây dựng các ứng dụng AI tùy chỉnh đến việc thử nghiệm với các tác vụ xử lý ngôn ngữ tự nhiên tiên tiến.
Trong hướng dẫn này, chúng tôi sẽ hướng dẫn bạn từng bước một. Chúng tôi sẽ sử dụng các công cụ như Ollama và LM Studio để làm cho việc cài đặt trở nên dễ dàng nhất có thể.
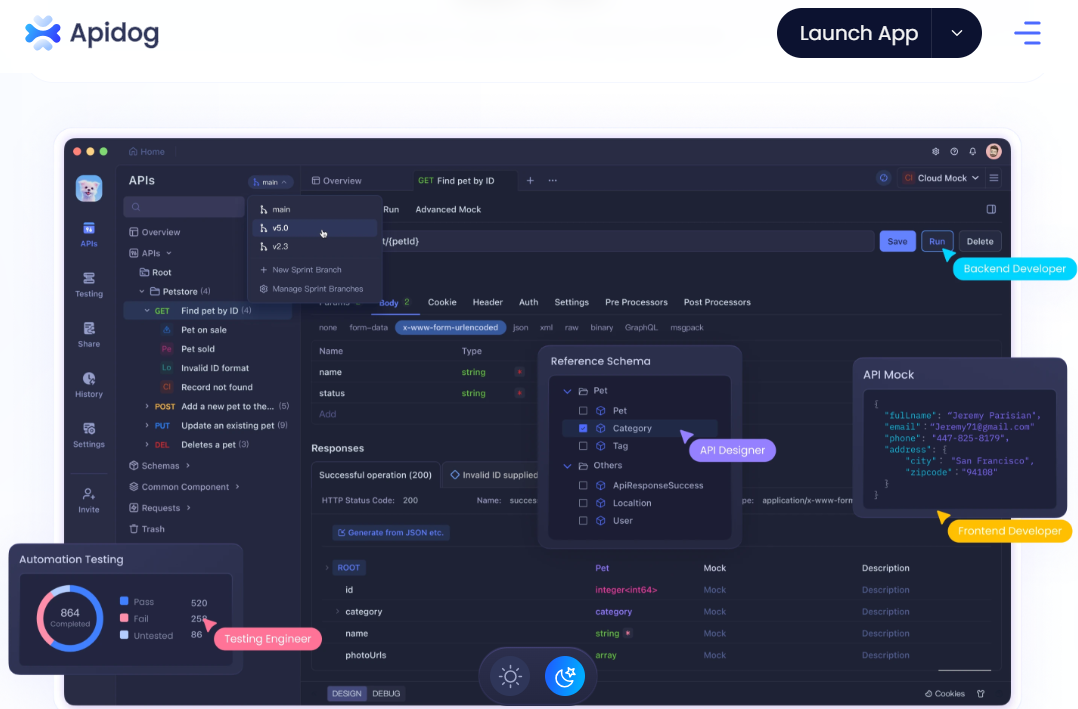
Vì bạn muốn sử dụng API với Ollama với một Công cụ Kiểm Tra API, đừng quên kiểm tra Apidog. Đây là một công cụ tuyệt vời để tối ưu hóa quy trình làm việc với API của bạn, và điều tốt nhất là? Bạn có thể tải về miễn phí!
Chuẩn bị để bắt đầu chưa? Hãy bắt tay vào làm!
1. Hiểu về QwQ-32B?
Trước khi chúng ta đi vào các chi tiết kỹ thuật, hãy dành một chút thời gian để hiểu QwQ-32B là gì. QwQ-32B là một mô hình ngôn ngữ tiên tiến với 32 tỷ tham số, được thiết kế để xử lý các tác vụ ngôn ngữ tự nhiên phức tạp như tạo văn bản, dịch thuật và tóm tắt. Đây là một công cụ linh hoạt cho các nhà phát triển và nhà nghiên cứu đang tìm cách đẩy ranh giới của AI.
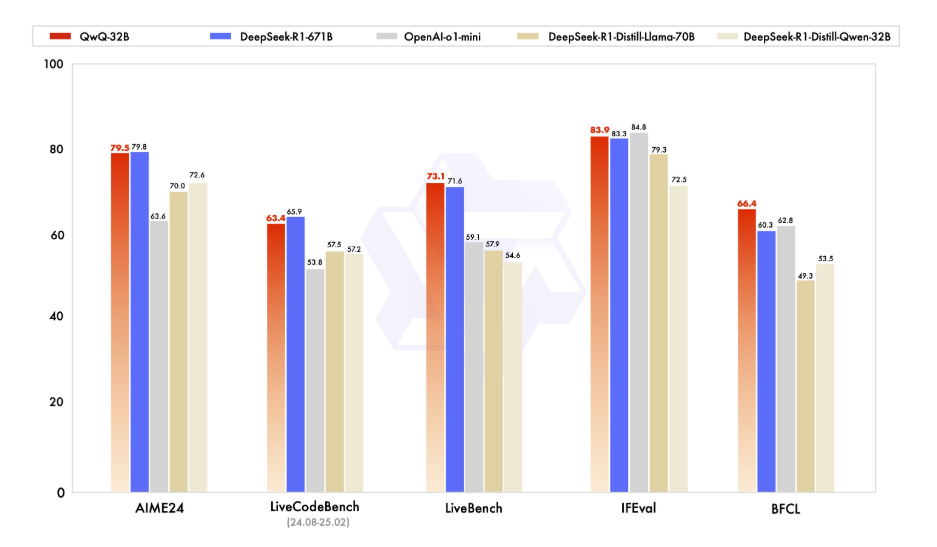
Chạy QwQ-32B cục bộ giúp bạn kiểm soát hoàn toàn mô hình, cho phép bạn tùy chỉnh để phù hợp với các trường hợp sử dụng cụ thể mà không phải dựa vào các dịch vụ đám mây. Bảo mật, Tùy chỉnh, Chi phí-hiệu quả, và Truy cập Offline là một vài trong số nhiều tính năng mà bạn có thể tận dụng khi chạy mô hình này cục bộ.
2. Điều kiện tiên quyết
Máy tính của bạn sẽ cần đáp ứng các yêu cầu sau trước khi bạn có thể chạy QwQ-32B cục bộ:
- Phần cứng: Một máy tính mạnh mẽ với ít nhất 16GB RAM và một GPU cao cấp với tối thiểu 24GB VRAM (ví dụ: NVIDIA RTX 3090 hoặc tốt hơn) để có hiệu suất tối ưu.
- Phần mềm: Python 3.8 hoặc mới hơn, Git, và một trình quản lý gói như pip hoặc conda.
- Công cụ: Ollama và LMStudio (chúng tôi sẽ đề cập đến chúng sau).
3. Chạy QwQ-32B cục bộ bằng cách sử dụng Ollama
Ollama là một framework nhẹ nhàng giúp đơn giản hóa quá trình chạy các mô hình ngôn ngữ lớn cục bộ. Đây là cách cài đặt:
Bước 1: Tải xuống và cài đặt Ollama:
- Đối với Windows và macOS, tải tệp thực thi từ trang web chính thức của Ollama và chạy nó để cài đặt. Sau đó, làm theo hướng dẫn cài đặt đơn giản được cung cấp trong quá trình cài đặt.
- Đối với người dùng Linux, bạn có thể sử dụng lệnh sau:
curl -fsSL https://ollama.ai/install.sh | sh
- Xác minh Cài đặt: Sau khi cài đặt, nếu bạn muốn xác minh rằng bạn đã cài đặt Ollama đúng, hãy mở terminal và chạy:
ollama --version
- Nếu việc cài đặt thành công, bạn sẽ thấy số phiên bản.
Bước 2: Tìm mô hình QwQ-32B
- Quay lại trang web Ollama và tìm đến phần "Models".
- Sử dụng thanh tìm kiếm để tìm "QwQ-32B."
- Ngay khi bạn tìm thấy mô hình QwQ-32B, bạn sẽ thấy lệnh cài đặt được cung cấp trên trang.
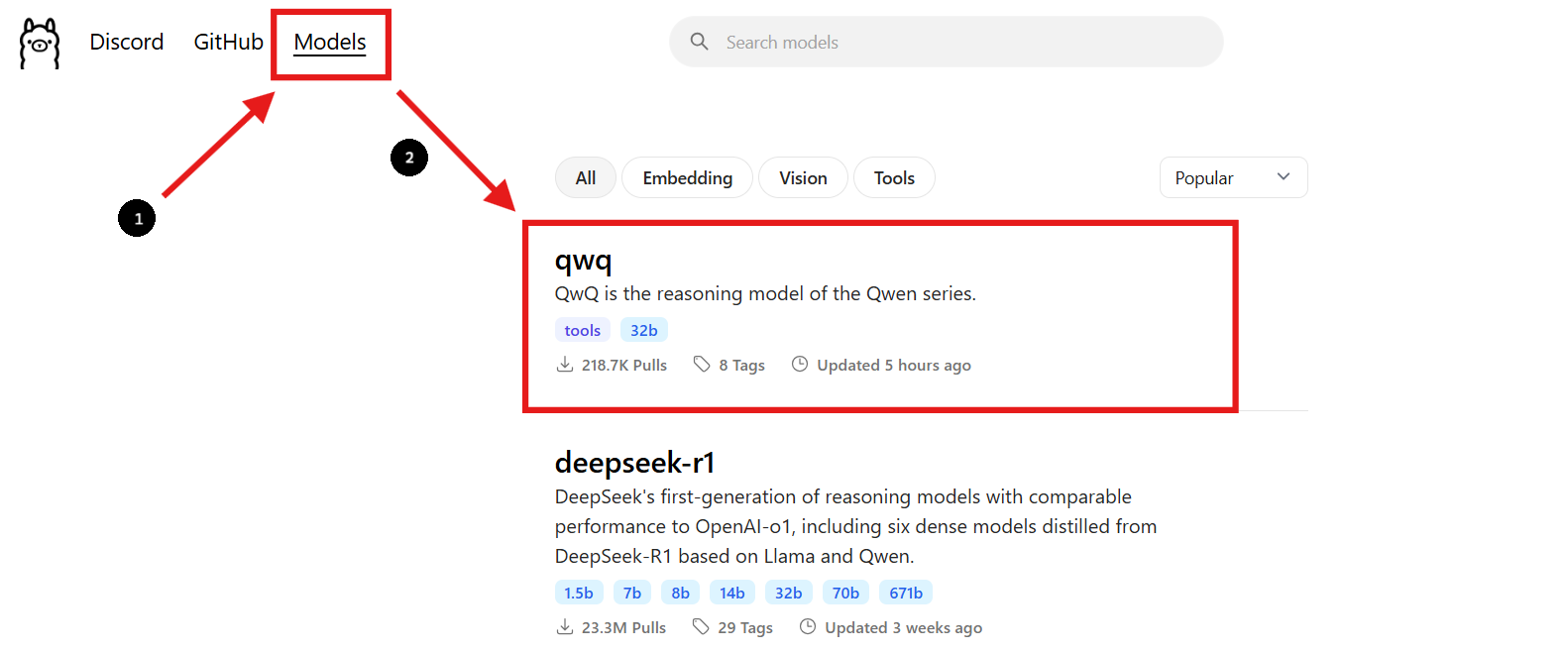
Bước 3: Tải mô hình QwQ-32B
- Mở một cửa sổ terminal mới để tải mô hình và chạy lệnh sau:
ollama pull qwq:32b- Sau khi việc tải hoàn tất, bạn có thể xác minh rằng mô hình đã được cài đặt bằng cách chạy lệnh sau:
ollama list
- Lệnh này sẽ liệt kê tất cả các mô hình bạn đã tải xuống bằng Ollama, xác nhận rằng QwQ-32B có sẵn.
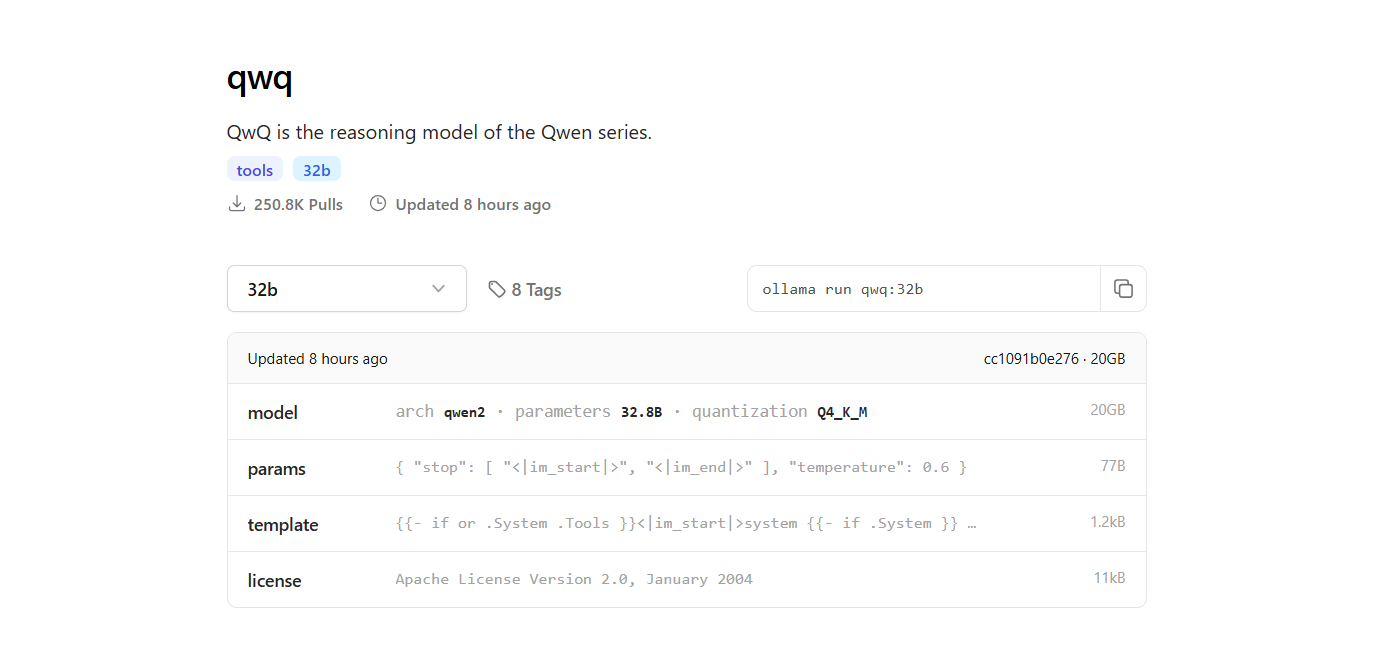
Bước 4: Chạy mô hình QwQ-32B
Chạy mô hình trong terminal:
- Để tương tác với mô hình QwQ-32B trực tiếp trong terminal, sử dụng lệnh sau:
ollama run qwq:32b
- Bạn có thể đặt câu hỏi hoặc cung cấp các gợi ý trong terminal, và mô hình sẽ phản hồi theo cách tương ứng.
Sử dụng Giao diện Chat Tương tác:
- Ngoài ra, bạn có thể sử dụng các công cụ như Chatbox hoặc OpenWebUI để tạo một giao diện GUI tương tác để trò chuyện với mô hình QwQ-32B.
- Các giao diện này cung cấp một cách thân thiện hơn để tương tác với mô hình, đặc biệt nếu bạn thích giao diện đồ họa hơn là giao diện dòng lệnh.
4. Chạy QwQ-32B cục bộ bằng cách sử dụng LM Studio
LM Studio là một giao diện thân thiện cho việc chạy và quản lý các mô hình ngôn ngữ cục bộ. Đây là cách thiết lập:
Bước 1: Tải xuống LM Studio:
- Để bắt đầu, hãy truy cập trang web chính thức của LM Studio tại lmstudio.ai. Đây là nơi bạn có thể tải ứng dụng LM Studio cho hệ điều hành của bạn.
- Trên trang của họ, tìm đến phần tải xuống và chọn phiên bản phù hợp với hệ điều hành của bạn (Windows, macOS hoặc Linux).
Bước 2: Cài đặt LM Studio:
- Làm theo các hướng dẫn cài đặt đơn giản cho hệ điều hành của bạn.
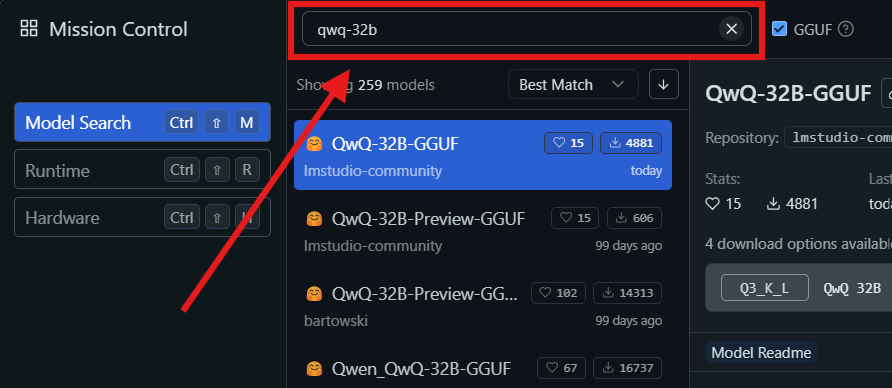
Bước 3: Tìm và Tải mô hình QwQ-32B:
- Mở LM Studio và tìm đến phần “Mô Hình của Tôi”.
- Nhấp vào biểu tượng tìm kiếm và gõ "QwQ-32B" vào thanh tìm kiếm.
- Chọn phiên bản mong muốn của mô hình QwQ-32B từ kết quả tìm kiếm. Bạn có thể tìm thấy các phiên bản định lượng khác nhau, chẳng hạn như một mô hình định lượng 4-bit, giúp giảm mức sử dụng bộ nhớ trong khi vẫn duy trì hiệu suất.
Bước 4: Chạy QwQ-32B Cục bộ trong LM Studio
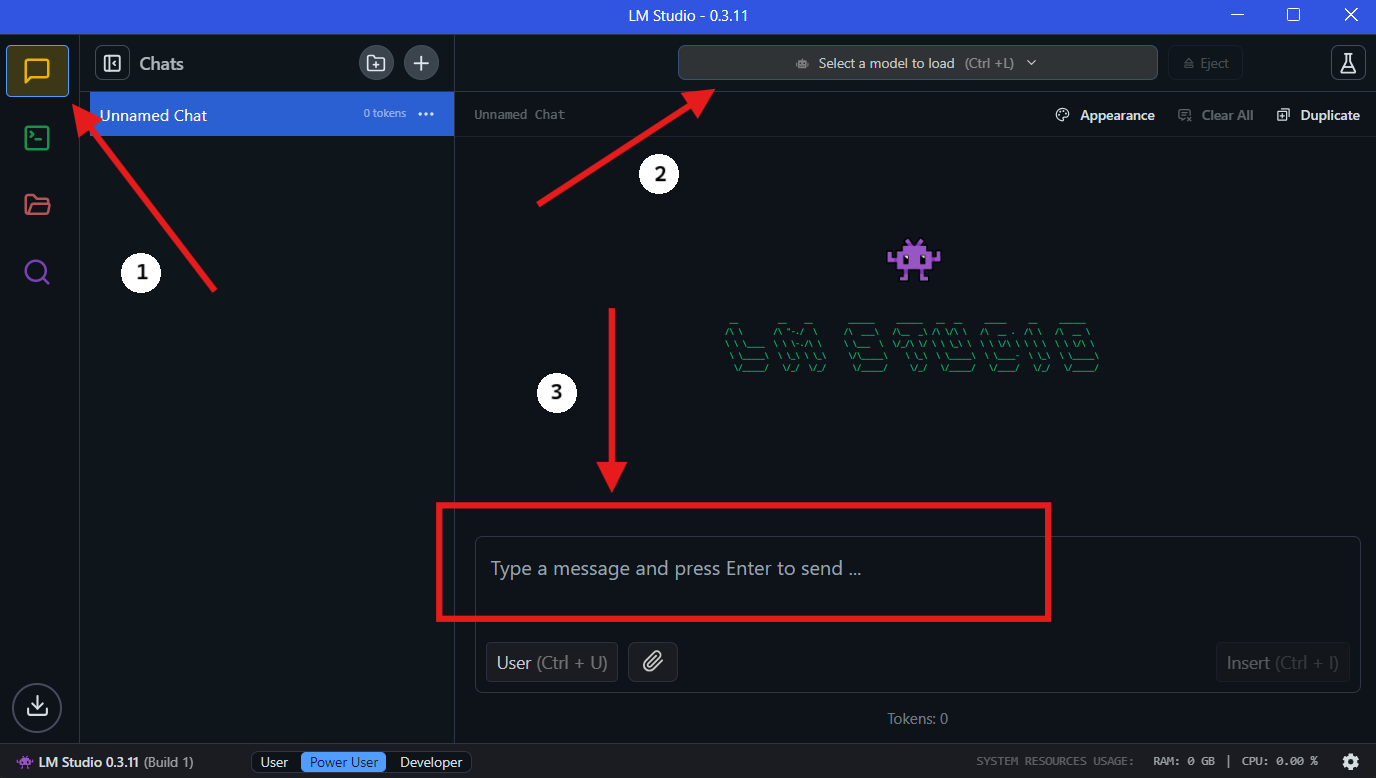
- Chọn Mô Hình: Ngay khi việc tải hoàn tất, hãy chuyển đến phần "Chat" trong LM Studio. Trong giao diện chat, chọn mô hình QwQ-32B từ menu xổ xuống.
- Tương tác với QwQ-32B: Bắt đầu đặt câu hỏi hoặc cung cấp các gợi ý trong cửa sổ chat. Mô hình sẽ xử lý đầu vào của bạn và tạo ra các phản hồi.
- Cấu hình Cài đặt: Bạn có thể điều chỉnh cài đặt của mô hình dựa trên sở thích của mình trong tab "cấu hình nâng cao".
5. Tối ưu hóa quy trình phát triển API với Apidog
Tích hợp QwQ-32B vào các ứng dụng của bạn yêu cầu quản lý API hiệu quả. Apidog là một nền tảng phát triển API hợp tác tất cả trong một, giúp đơn giản hóa quy trình này. Các tính năng chính của Apidog bao gồm Thiết kế API, Tài liệu API và Gỡ lỗi API. Để làm cho quá trình tích hợp diễn ra suôn sẻ, hãy làm theo các bước sau để thiết lập Apidog để quản lý và kiểm tra các API của bạn với QwQ-32B.

Bước 1: Tải xuống và Cài đặt Apidog
- Truy cập trang web chính thức của Apidog và tải phiên bản tương thích với hệ điều hành của bạn (Windows, macOS hoặc Linux).
- Làm theo các hướng dẫn cài đặt để thiết lập Apidog trên máy của bạn.
Bước 2: Tạo một Dự Án API Mới
- Mở Apidog và tạo một dự án API mới.
- Xác định các điểm kết nối API của bạn, chỉ định định dạng yêu cầu và phản hồi để tương tác với QwQ-32B.
Bước 3: Kết nối QwQ-32B với Apidog thông qua API cục bộ
Để tương tác với QwQ-32B thông qua một API, bạn cần phơi bày mô hình bằng cách sử dụng một máy chủ cục bộ. Sử dụng FastAPI hoặc Flask để tạo một API cho mô hình QwQ-32B cục bộ của bạn.
Ví dụ: Thiết lập một máy chủ FastAPI cho QwQ-32B:
from fastapi import FastAPI
from pydantic import BaseModel
import subprocess
app = FastAPI()
class RequestData(BaseModel):
prompt: str
@app.post("/generate")
async def generate_text(request: RequestData):
result = subprocess.run(
["python", "run_model.py", request.prompt],
capture_output=True, text=True
)
return {"response": result.stdout}
# Chạy với: uvicorn script_name:app --reload
Bước 4: Kiểm tra các cuộc gọi API với Apidog
- Mở Apidog và tạo một yêu cầu POST đến
http://localhost:8000/generate. - Nhập một gợi ý mẫu trong thân yêu cầu và nhấp vào "Gửi".
- Nếu mọi thứ được cấu hình chính xác, bạn sẽ nhận được một phản hồi được tạo ra từ QwQ-32B.
Bước 5: Tự động hóa Kiểm tra và Gỡ lỗi API
- Sử dụng các tính năng kiểm tra tích hợp sẵn của Apidog để mô phỏng các đầu vào khác nhau và phân tích cách QwQ-32B phản hồi.
- Điều chỉnh các tham số yêu cầu và tối ưu hóa hiệu suất API bằng cách theo dõi thời gian phản hồi.
🚀 Với Apidog, việc quản lý quy trình làm việc API trở nên dễ dàng, đảm bảo tích hợp mượt mà giữa QwQ-32B và các ứng dụng của bạn.
6. Mẹo để Tối ưu hóa Hiệu suất
Chạy một mô hình với 32 tỷ tham số có thể tiêu tốn tài nguyên. Dưới đây là một vài mẹo để tối ưu hóa hiệu suất:
- Sử dụng GPU cao cấp: Một GPU mạnh mẽ sẽ tăng tốc đáng kể quá trình suy diễn.
- Điều chỉnh kích thước batch: Thử nghiệm với các kích thước batch khác nhau để tìm cài đặt tối ưu.
- Theo dõi mức sử dụng tài nguyên: Sử dụng các công cụ như
htophoặcnvidia-smiđể theo dõi mức sử dụng CPU và GPU.
7. Khắc phục các vấn đề thường gặp
Chạy QwQ-32B cục bộ đôi khi có thể gặp khó khăn. Dưới đây là một số vấn đề thường gặp và cách khắc phục chúng:
- Hết bộ nhớ: Giảm kích thước batch hoặc nâng cấp phần cứng của bạn.
- Hiệu suất chậm: Đảm bảo rằng trình điều khiển GPU của bạn được cập nhật.
- Mô hình không tải: Kiểm tra lại đường dẫn mô hình và tính toàn vẹn của tệp.
8. Suy nghĩ cuối cùng
Chạy QwQ-32B cục bộ là một cách mạnh mẽ để khai thác khả năng của các mô hình AI tiên tiến mà không cần phụ thuộc vào các dịch vụ đám mây. Với các công cụ như Ollama và LM Studio, quy trình này trở nên dễ tiếp cận hơn bao giờ hết.
Và hãy nhớ rằng, nếu bạn đang làm việc với API, Apidog là công cụ bạn nên sử dụng để kiểm tra và tài liệu. Tải về miễn phí và nâng cao quy trình làm việc API của bạn lên tầm cao mới!