

Bạn đã bao giờ muốn chạy các mô hình thị giác AI phức tạp ngay trên máy của mình, mà không phụ thuộc vào các dịch vụ đám mây đắt đỏ hay lo lắng về quyền riêng tư dữ liệu chưa? Chà, bạn thật may mắn! Hôm nay, chúng ta sẽ đi sâu vào cách chạy các mô hình Qwen 3 VL (Vision Language) cục bộ với Ollama và tin tôi đi, điều này sẽ thay đổi cuộc chơi cho quy trình phát triển AI của bạn.
Bây giờ, trước khi đi sâu vào các vấn đề kỹ thuật, hãy để tôi hỏi bạn điều này: Bạn có mệt mỏi với việc bị giới hạn tốc độ API, phải trả chi phí cao ngất ngưởng cho suy luận đám mây, hay đơn giản là muốn kiểm soát nhiều hơn các mô hình AI của mình không? Nếu bạn gật đầu đồng ý, thì hướng dẫn này được thiết kế đặc biệt dành cho bạn. Hơn nữa, nếu bạn đang tìm kiếm một công cụ mạnh mẽ để kiểm tra và gỡ lỗi các API AI cục bộ của mình, tôi thực sự khuyên bạn nên tải xuống Apidog miễn phí – đây là một nền tảng kiểm thử API tuyệt vời hoạt động trơn tru với các điểm cuối cục bộ của Ollama.
Trong hướng dẫn này, chúng ta sẽ đi qua mọi thứ bạn cần để chạy các mô hình Qwen 3 VL cục bộ bằng Ollama, từ cài đặt đến suy luận, khắc phục sự cố và thậm chí tích hợp với các công cụ như Apidog. Khi kết thúc hướng dẫn toàn diện này, bạn sẽ có một mô hình Qwen3-VL thị giác-ngôn ngữ hoạt động đầy đủ chức năng, riêng tư và phản hồi nhanh chóng chạy mượt mà trên máy cục bộ của bạn, đồng thời bạn sẽ được trang bị tất cả kiến thức cần thiết để tích hợp nó vào các dự án của mình.
Vậy thì, hãy thắt dây an toàn, lấy đồ uống yêu thích của bạn và cùng nhau bắt đầu hành trình thú vị này.
Tìm hiểu Qwen3-VL: Mô hình Thị giác-Ngôn ngữ mang tính Cách mạng

Tại sao lại là Qwen 3 VL? Và tại sao phải chạy cục bộ?
Trước khi đi vào các bước kỹ thuật, hãy cùng nói về lý do Qwen 3 VL quan trọng và tại sao việc chạy nó cục bộ lại là một yếu tố thay đổi cuộc chơi.
Qwen 3 VL là một phần của dòng Qwen của Alibaba, nhưng nó được thiết kế đặc biệt cho các tác vụ thị giác-ngôn ngữ. Không giống như các LLM truyền thống chỉ hiểu văn bản, Qwen 3 VL có thể:
- Phân tích hình ảnh và trả lời các câu hỏi về chúng (“Có gì trong bức ảnh này?”)
- Tạo chú thích chi tiết
- Trích xuất dữ liệu có cấu trúc từ biểu đồ, sơ đồ hoặc tài liệu
- Hỗ trợ RAG đa phương thức (tạo sinh tăng cường truy xuất) với ngữ cảnh hình ảnh
Và vì nó là mã nguồn mở (theo giấy phép Tongyi Qianwen), các nhà phát triển có thể sử dụng, sửa đổi và triển khai nó một cách tự do miễn là họ tuân thủ các điều khoản cấp phép.
Vậy, tại sao phải chạy nó cục bộ?
- Quyền riêng tư: Hình ảnh và lời nhắc của bạn không bao giờ rời khỏi máy của bạn.
- Chi phí: Không có phí API hoặc giới hạn sử dụng.
- Tùy chỉnh: Tinh chỉnh, lượng tử hóa hoặc tích hợp với các quy trình của riêng bạn.
- Truy cập ngoại tuyến: Hoàn hảo cho các môi trường an toàn hoặc cách ly mạng.
Nhưng việc triển khai cục bộ trước đây thường có nghĩa là phải vật lộn với các phiên bản CUDA, môi trường Python và các Dockerfile khổng lồ. Hãy chào đón Ollama.
Các Biến thể Mô hình: Phù hợp với mọi Trường hợp Sử dụng
Qwen3-VL có nhiều kích cỡ khác nhau để phù hợp với các cấu hình phần cứng và trường hợp sử dụng khác nhau. Dù bạn đang làm việc trên một chiếc laptop nhẹ hay có quyền truy cập vào một máy trạm mạnh mẽ, luôn có một mô hình Qwen3-VL phù hợp hoàn hảo với nhu cầu của bạn.
Các Mô hình Mật độ (Kiến trúc Truyền thống):
- Qwen3-VL-2B: Hoàn hảo cho các thiết bị biên và ứng dụng di động
- Qwen3-VL-4B: Cân bằng tuyệt vời giữa hiệu suất và sử dụng tài nguyên
- Qwen3-VL-8B: Tuyệt vời cho các tác vụ đa năng với khả năng suy luận vừa phải
- Qwen3-VL-32B: Các tác vụ cao cấp yêu cầu suy luận mạnh mẽ và ngữ cảnh rộng
Các Mô hình Hỗn hợp Chuyên gia (MoE) (Kiến trúc Hiệu quả):
- Qwen3-VL-30B-A3B: Hiệu suất hiệu quả chỉ với 3B tham số hoạt động
- Qwen3-VL-235B-A22B: Ứng dụng quy mô lớn với tổng cộng 235B tham số nhưng chỉ 22B hoạt động
Vẻ đẹp của các mô hình MoE là chúng chỉ kích hoạt một tập hợp con các mạng thần kinh "chuyên gia" cho mỗi lần suy luận, cho phép số lượng tham số khổng lồ mà vẫn giữ chi phí tính toán ở mức hợp lý.
Ollama: Cổng vào Sự Xuất Sắc của AI Cục bộ
Bây giờ chúng ta đã hiểu những gì Qwen3-VL mang lại, hãy nói về lý do tại sao Ollama là nền tảng lý tưởng để chạy các mô hình này cục bộ. Hãy hình dung Ollama như một nhạc trưởng của dàn nhạc – nó điều phối tất cả các quy trình phức tạp diễn ra phía sau hậu trường để bạn có thể tập trung vào điều quan trọng nhất: sử dụng các mô hình AI của mình.
Ollama là gì và tại sao nó hoàn hảo cho Qwen 3 VL
Ollama là một công cụ mã nguồn mở cho phép bạn chạy các mô hình ngôn ngữ lớn (và giờ đây, các mô hình đa phương thức) cục bộ chỉ với một lệnh duy nhất. Hãy coi nó như “Docker dành cho LLM” nhưng thậm chí còn đơn giản hơn.
Các tính năng chính:
- Tăng tốc GPU tự động (qua Metal trên macOS, CUDA trên Linux)
- Thư viện mô hình tích hợp (bao gồm Llama 3, Mistral, Gemma, và giờ là Qwen)
- REST API để tích hợp dễ dàng
- Nhẹ và thân thiện với người mới bắt đầu
Tuyệt vời nhất là, Ollama hiện hỗ trợ các mô hình Qwen 3 VL, bao gồm các biến thể như qwen3-vl:4b và qwen3-vl:8b. Đây là các phiên bản đã được lượng tử hóa, tối ưu hóa cho phần cứng cục bộ – nghĩa là bạn có thể chạy chúng trên các GPU phổ thông hoặc thậm chí là các laptop mạnh mẽ.
Sức mạnh Kỹ thuật đằng sau Ollama
Điều gì xảy ra phía sau hậu trường khi bạn chạy một lệnh Ollama? Nó giống như xem một điệu nhảy được biên đạo kỹ lưỡng của các quy trình công nghệ:
1.Tải xuống & Lưu trữ Mô hình: Ollama tự động tải xuống và lưu trữ trọng số mô hình một cách thông minh, đảm bảo thời gian khởi động nhanh chóng cho các mô hình thường xuyên được sử dụng.
2.Tối ưu hóa Lượng tử hóa: Các mô hình được tự động tối ưu hóa cho cấu hình phần cứng của bạn, chọn phương pháp lượng tử hóa tốt nhất (4-bit, 8-bit, v.v.) cho GPU và RAM của bạn.
3.Quản lý Bộ nhớ: Các kỹ thuật ánh xạ bộ nhớ tiên tiến đảm bảo sử dụng bộ nhớ GPU hiệu quả đồng thời duy trì hiệu suất cao.
4.Xử lý Song song: Ollama tận dụng nhiều lõi CPU và luồng GPU để đạt được thông lượng tối đa.
Điều kiện Tiên quyết: Những gì bạn cần trước khi cài đặt
Trước khi chúng ta cài đặt bất cứ thứ gì, hãy đảm bảo hệ thống của bạn đã sẵn sàng.
Yêu cầu Phần cứng
- RAM: Tối thiểu 16GB (khuyên dùng 32GB cho các mô hình 8B)
- GPU: NVIDIA GPU với 8GB+ VRAM (cho Linux) hoặc Apple Silicon Mac (M1/M2/M3 với 16GB+ bộ nhớ hợp nhất)
- Lưu trữ: 10–20GB dung lượng trống (các mô hình rất lớn!)
Yêu cầu Phần mềm
- Hệ điều hành: macOS (12+) hoặc Linux (khuyên dùng Ubuntu 20.04+)
- Ollama: Phiên bản mới nhất (v0.1.40+ để hỗ trợ Qwen 3 VL)
- Tùy chọn: Docker (nếu bạn thích triển khai bằng container), Python (cho các kịch bản nâng cao)
Hướng dẫn Cài đặt Từng Bước: Con đường đến với AI Cục bộ Thành thạo
Bước 1: Cài đặt Ollama - Nền tảng
Hãy bắt đầu với nền tảng của toàn bộ thiết lập của chúng ta. Cài đặt Ollama đáng ngạc nhiên là rất đơn giản – nó được thiết kế để mọi người đều có thể tiếp cận, từ những người mới làm quen với AI đến các nhà phát triển dày dạn kinh nghiệm.
Dành cho Người dùng macOS:
1.Truy cập ollama.com/download
2.Tải xuống trình cài đặt macOS
3.Mở tệp đã tải xuống và kéo Ollama vào thư mục Ứng dụng của bạn
4.Khởi chạy Ollama từ thư mục Ứng dụng hoặc tìm kiếm Spotlight của bạn
Quá trình cài đặt cực kỳ mượt mà trên macOS, và bạn sẽ thấy biểu tượng Ollama xuất hiện trên thanh menu của mình sau khi cài đặt hoàn tất.
Dành cho Người dùng Windows:
1.Điều hướng đến ollama.com/download
2.Tải xuống trình cài đặt Windows (tệp .exe)
3.Chạy trình cài đặt với quyền quản trị viên
4.Làm theo hướng dẫn cài đặt (nó khá trực quan)
5.Sau khi cài đặt, Ollama sẽ tự động khởi động ở chế độ nền
Người dùng Windows có thể thấy thông báo của Windows Defender – đừng lo lắng, điều này là bình thường trong lần chạy đầu tiên. Chỉ cần nhấp vào "Cho phép" và Ollama sẽ hoạt động hoàn hảo.
Dành cho Người dùng Linux:
Người dùng Linux có hai tùy chọn:
Tùy chọn A: Kịch bản Cài đặt (Khuyên dùng)
bash
curl -fsSL <https://ollama.com/install.sh> | sh
Tùy chọn B: Cài đặt Thủ công
bash
# Download the latest Ollama binarycurl -o ollama <https://ollama.com/download/ollama-linux-amd64>
# Make it executablechmod +x ollama
# Move to PATHsudo mv ollama /usr/local/bin/
Bước 2: Xác minh Cài đặt của bạn
Bây giờ Ollama đã được cài đặt, hãy đảm bảo mọi thứ hoạt động chính xác. Hãy coi đây là một bài kiểm tra nhanh để đảm bảo nền tảng của chúng ta vững chắc.
Mở terminal của bạn (hoặc dấu nhắc lệnh trên Windows) và chạy:
bash
ollama --version
Bạn sẽ thấy kết quả tương tự như:
ollama version is 0.1.0
Tiếp theo, hãy kiểm tra chức năng cơ bản:
bash
ollama serve
Lệnh này khởi động máy chủ Ollama. Bạn sẽ thấy thông báo cho biết máy chủ đang chạy trên http://localhost:11434. Hãy để máy chủ chạy – chúng ta sẽ sử dụng nó để kiểm tra cài đặt Qwen3-VL của mình.
Bước 3: Tải và Chạy Mô hình Qwen3-VL
Bây giờ đến phần thú vị! Hãy tải xuống và chạy mô hình Qwen3-VL đầu tiên của chúng ta. Chúng ta sẽ bắt đầu với một mô hình nhỏ hơn để thử nghiệm, sau đó chuyển sang các biến thể mạnh mẽ hơn.
Kiểm thử với Qwen3-VL-4B (Điểm khởi đầu tuyệt vời):
bash
ollama run qwen3-vl:4b
Lệnh này sẽ:
1.Tải xuống mô hình Qwen3-VL-4B (khoảng 2.8GB)
2.Tối ưu hóa nó cho phần cứng của bạn
3.Bắt đầu một phiên trò chuyện tương tác
Chạy các Biến thể Mô hình Khác:
Nếu bạn có phần cứng mạnh mẽ hơn, hãy thử các lựa chọn thay thế này:
bash
# For 8GB+ GPU systemsollama run qwen3-vl:8b
# For 16GB+ RAM systemsollama run qwen3-vl:32b
# For high-end systems with multiple GPUsollama run qwen3-vl:30b-a3b
# For maximum performance (requires serious hardware)ollama run qwen3-vl:235b-a22b
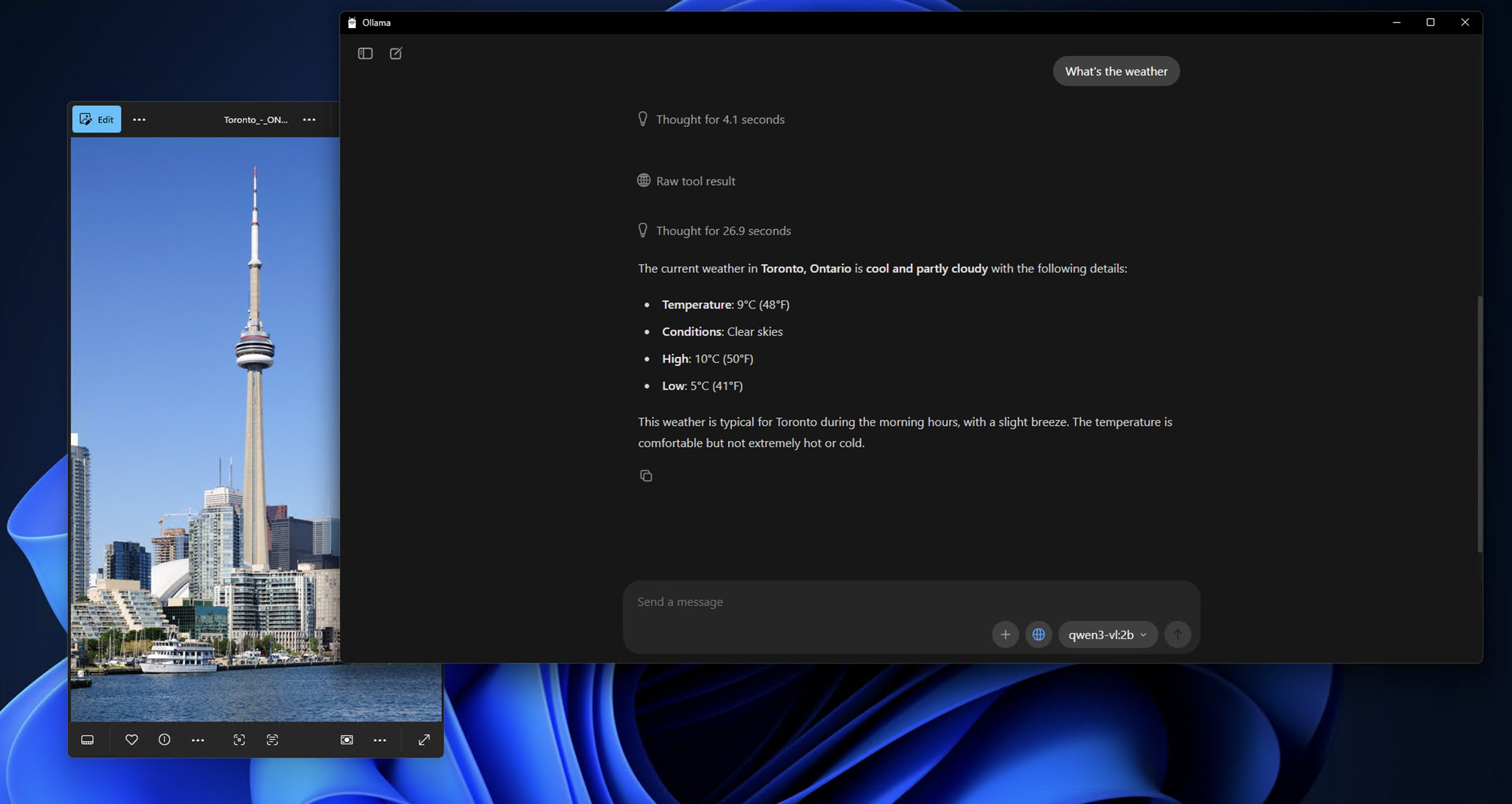
Bước 4: Tương tác Đầu tiên với Qwen3-VL Cục bộ của bạn
Khi mô hình đã được tải xuống và chạy, bạn sẽ thấy một dấu nhắc như sau:
Send a message (type /? for help)
Hãy kiểm tra khả năng của mô hình bằng một phân tích hình ảnh đơn giản:
Chuẩn bị một Hình ảnh Kiểm thử:
Tìm bất kỳ hình ảnh nào trên máy tính của bạn – đó có thể là một bức ảnh, ảnh chụp màn hình hoặc hình minh họa. Trong ví dụ này, tôi sẽ giả định bạn có một hình ảnh tên là test_image.jpg trong thư mục hiện tại của bạn.

Kiểm thử Trò chuyện Tương tác:
bash
What do you see in this image? /path/to/your/image.jpg
Thay thế: Sử dụng API để Kiểm thử
Nếu bạn muốn kiểm thử bằng lập trình, bạn có thể sử dụng Ollama API. Dưới đây là một bài kiểm thử đơn giản sử dụng curl:
bash
curl <http://localhost:11434/api/generate> \\
-H "Content-Type: application/json" \\
-d '{
"model": "qwen3-vl:4b",
"prompt": "What is in this image? Describe it in detail.",
"images": ["base64_encoded_image_data_here"]
}'

Bước 5: Các Tùy chọn Cấu hình Nâng cao
Bây giờ bạn đã có một cài đặt hoạt động, hãy khám phá một số tùy chọn cấu hình nâng cao để tối ưu hóa thiết lập của bạn cho phần cứng và trường hợp sử dụng cụ thể của bạn.
Tối ưu hóa Bộ nhớ:
Nếu bạn gặp vấn đề về bộ nhớ, bạn có thể điều chỉnh hành vi tải mô hình:
bash
# Set maximum memory usage (adjust based on your RAM)export OLLAMA_MAX_LOADED_MODELS=1
# Enable GPU offloadingexport OLLAMA_GPU=1
# Set custom port (if 11434 is already in use)export OLLAMA_HOST=0.0.0.0:11435
Các Tùy chọn Lượng tử hóa:
Đối với các hệ thống có VRAM hạn chế, bạn có thể buộc các mức lượng tử hóa cụ thể:
bash
# Load model with 4-bit quantization (more compatible, slower)ollama run qwen3-vl:4b --format json
# Load with 8-bit quantization (balanced)ollama run qwen3-vl:8b --format json
Cấu hình Đa GPU:
Nếu bạn có nhiều GPU, bạn có thể chỉ định GPU nào sẽ sử dụng:
bash
# Use specific GPU IDs (Linux/macOS)export CUDA_VISIBLE_DEVICES=0,1
ollama run qwen3-vl:30b-a3b
# On macOS with multiple Apple Silicon GPUsexport CUDA_VISIBLE_DEVICES=0,1
ollama run qwen3-vl:30b-a3b
Kiểm thử và Tích hợp với Apidog: Đảm bảo Chất lượng và Hiệu suất

Bây giờ bạn đã có Qwen3-VL chạy cục bộ, hãy nói về cách kiểm thử và tích hợp nó đúng cách vào quy trình phát triển của bạn. Đây là lúc Apidog thực sự tỏa sáng như một công cụ không thể thiếu cho các nhà phát triển AI.
Apidog không chỉ là một công cụ kiểm thử API khác – nó là một nền tảng toàn diện được thiết kế đặc biệt cho các quy trình phát triển API hiện đại. Khi làm việc với các mô hình AI cục bộ như Qwen3-VL, bạn cần một công cụ có thể:
1.Xử lý Cấu trúc JSON Phức tạp: Phản hồi của mô hình AI thường chứa JSON lồng nhau với các loại nội dung khác nhau
2.Hỗ trợ Tải lên Tệp: Nhiều mô hình AI cần đầu vào là hình ảnh, video hoặc tài liệu
3.Quản lý Xác thực: Kiểm thử an toàn các điểm cuối với xử lý xác thực phù hợp
4.Tạo Kiểm thử Tự động: Kiểm thử hồi quy để đảm bảo tính nhất quán về hiệu suất mô hình
5.Tạo Tài liệu: Tự động tạo tài liệu API từ các trường hợp kiểm thử của bạn
Khắc phục các Vấn đề Thường gặp
Ngay cả với sự đơn giản của Ollama, bạn vẫn có thể gặp phải những trở ngại. Dưới đây là các cách khắc phục cho những vấn đề thường gặp.
❌ “Không tìm thấy mô hình” hoặc “Mô hình không được hỗ trợ”
- Đảm bảo bạn đang sử dụng Ollama v0.1.40 trở lên
- Chạy lại
ollama pull qwen3-vl:4b– đôi khi quá trình tải xuống thất bại một cách âm thầm
❌ “Hết bộ nhớ” trên GPU
- Hãy thử phiên bản 4B thay vì 8B
- Đóng các ứng dụng nặng GPU khác (Chrome, trò chơi, v.v.)
- Trên Linux, kiểm tra VRAM bằng
nvidia-smi
❌ Hình ảnh không được nhận dạng
- Xác nhận hình ảnh dưới 4MB
- Sử dụng định dạng PNG hoặc JPG (tránh HEIC, BMP)
- Đảm bảo chuỗi base64 không có ký tự xuống dòng (sử dụng
base64 -w 0trên Linux)
❌ Suy luận chậm trên CPU
- Qwen 3 VL rất lớn ngay cả khi đã được lượng tử hóa. Hãy mong đợi 1–5 token/giây trên CPU
- Nâng cấp lên Apple Silicon hoặc NVIDIA GPU để tăng tốc gấp 10 lần
Các Trường hợp Sử dụng Thực tế cho Qwen 3 VL Cục bộ
Tại sao phải trải qua tất cả những rắc rối này? Dưới đây là các ứng dụng thực tế:
- Trí tuệ Tài liệu: Trích xuất bảng, chữ ký hoặc điều khoản từ các tệp PDF đã quét
- Công cụ Hỗ trợ Tiếp cận: Mô tả hình ảnh cho người dùng khiếm thị
- Bot Kiến thức Nội bộ: Trả lời các câu hỏi về sơ đồ hoặc bảng điều khiển nội bộ
- Giáo dục: Xây dựng một gia sư giải thích các bài toán từ ảnh
- Phân tích Bảo mật: Phân tích sơ đồ mạng hoặc ảnh chụp màn hình kiến trúc hệ thống
Vì nó là cục bộ, bạn tránh gửi các hình ảnh nhạy cảm đến các API của bên thứ ba – một lợi ích lớn cho các doanh nghiệp và nhà phát triển quan tâm đến quyền riêng tư.
Kết luận: Hành trình của bạn đến với Sự Xuất Sắc của AI Cục bộ
Chúc mừng! Bạn vừa hoàn thành một hành trình hoành tráng vào thế giới AI cục bộ với Qwen3-VL và Ollama. Đến bây giờ, bạn sẽ có được:
- Một cài đặt Qwen3-VL hoạt động đầy đủ chức năng chạy cục bộ
- Thiết lập kiểm thử toàn diện với Apidog
- Hiểu biết sâu sắc về khả năng và hạn chế của mô hình
- Kiến thức thực tế để tích hợp các mô hình này vào các ứng dụng thực tế
- Kỹ năng khắc phục sự cố để xử lý các vấn đề thường gặp
- Các chiến lược chống lỗi thời để tiếp tục thành công
Việc bạn đã đi được đến đây cho thấy sự cam kết của bạn trong việc tìm hiểu và tận dụng công nghệ AI tiên tiến. Bạn không chỉ cài đặt một mô hình – bạn đã có được chuyên môn về một công nghệ đang định hình lại cách chúng ta tương tác với thông tin hình ảnh và văn bản.
Tương lai là AI Cục bộ
Những gì chúng ta đã đạt được ở đây không chỉ là một thiết lập kỹ thuật – đó là một bước tiến tới một tương lai nơi AI dễ tiếp cận, riêng tư và nằm dưới sự kiểm soát của cá nhân. Khi các mô hình này tiếp tục cải thiện và trở nên hiệu quả hơn, chúng ta đang hướng tới một thế giới nơi các khả năng AI tinh vi có sẵn cho mọi người, bất kể ngân sách hay chuyên môn kỹ thuật của họ.
Hãy nhớ rằng, hành trình không kết thúc ở đây. Công nghệ AI phát triển nhanh chóng, và việc giữ sự tò mò, khả năng thích ứng và tham gia vào cộng đồng sẽ đảm bảo bạn tiếp tục tận dụng hiệu quả các công cụ mạnh mẽ này.
Những Suy nghĩ Cuối cùng
Chạy Qwen 3 VL cục bộ với Ollama không chỉ là một bản demo công nghệ hay về sự tiện lợi hoặc tiết kiệm chi phí – đó là một cái nhìn thoáng qua về tương lai của AI trên thiết bị. Khi các mô hình trở nên hiệu quả hơn và phần cứng mạnh mẽ hơn, chúng ta sẽ thấy nhiều nhà phát triển hơn triển khai các tính năng đa phương thức, riêng tư trực tiếp trong ứng dụng của họ. Giờ đây, bạn có các công cụ để khám phá công nghệ AI không giới hạn, thử nghiệm tự do và xây dựng các ứng dụng quan trọng đối với bạn và tổ chức của bạn.
Sự kết hợp giữa khả năng đa phương thức ấn tượng của Qwen3-VL và giao diện thân thiện với người dùng của Ollama tạo ra cơ hội đổi mới mà trước đây chỉ dành cho các tập đoàn lớn với nguồn lực khổng lồ. Giờ đây, bạn là một phần của cộng đồng các nhà phát triển đang phát triển, dân chủ hóa công nghệ AI.
Và với các công cụ như Ollama đơn giản hóa việc triển khai và Apidog hợp lý hóa việc phát triển API, rào cản gia nhập chưa bao giờ thấp hơn.
Vì vậy, dù bạn là một hacker độc lập, một nhà sáng lập startup, hay một kỹ sư doanh nghiệp, bây giờ là thời điểm hoàn hảo để thử nghiệm các mô hình thị giác-ngôn ngữ một cách an toàn, phải chăng và cục bộ.