
Thế giới của Trí Tuệ Nhân Tạo (AI) đang phát triển với tốc độ chóng mặt, với các Mô Hình Ngôn Ngữ Lớn (LLMs) như ChatGPT, Claude, và Gemini thu hút sự tưởng tượng của mọi người trên toàn cầu. Những công cụ mạnh mẽ này có thể viết mã, soạn thảo email, trả lời các câu hỏi phức tạp, và thậm chí tạo ra nội dung sáng tạo. Tuy nhiên, việc sử dụng những dịch vụ dựa trên đám mây này thường đi kèm với những lo ngại về quyền riêng tư dữ liệu, chi phí tiềm ẩn và sự cần thiết phải có kết nối internet liên tục.
Xin giới thiệu Ollama.
Ollama là một công cụ mã nguồn mở mạnh mẽ được thiết kế để dân chủ hóa quyền truy cập vào các mô hình ngôn ngữ lớn bằng cách cho phép bạn tải xuống, chạy và quản lý chúng trực tiếp trên máy tính của riêng bạn. Nó đơn giản hóa quy trình phức tạp thường gặp khi thiết lập và tương tác với các mô hình AI tiên tiến tại chỗ.
Tại Sao Nên Sử Dụng Ollama?

Việc chạy LLM tại chỗ với Ollama mang lại một số lợi thế hấp dẫn:
- Quyền Riêng Tư: Các yêu cầu và phản hồi của mô hình của bạn sẽ ở trên máy của bạn. Không có dữ liệu nào được gửi tới các máy chủ bên ngoài trừ khi bạn cấu hình rõ ràng để làm như vậy. Điều này rất quan trọng đối với thông tin nhạy cảm hoặc công việc độc quyền.
- Truy Cập Ngoại Tuyến: Khi một mô hình đã được tải xuống, bạn có thể sử dụng nó mà không cần kết nối internet, điều này rất phù hợp cho du lịch, các địa điểm xa xôi hoặc các tình huống có kết nối không đáng tin cậy.
- Tùy Chỉnh: Ollama cho phép bạn dễ dàng chỉnh sửa các mô hình bằng cách sử dụng 'Modelfiles', cho phép bạn điều chỉnh hành vi, yêu cầu hệ thống và các tham số theo nhu cầu cụ thể của bạn.
- Chi Phí Thấp: Không có phí thuê bao hay phí theo token. Chi phí duy nhất là phần cứng bạn đã sở hữu và điện năng để vận hành.
- Khám Phá & Học Hỏi: Nó cung cấp một nền tảng tuyệt vời để thử nghiệm với các mô hình mã nguồn mở khác nhau, hiểu rõ khả năng và giới hạn của chúng, và tìm hiểu thêm về cách mà LLM hoạt động bên trong.
Bài viết này được thiết kế cho những người mới bắt đầu, những người cảm thấy thoải mái khi sử dụng giao diện dòng lệnh (như Terminal trên macOS/Linux hoặc Command Prompt/PowerShell trên Windows) và muốn bắt đầu khám phá thế giới của các LLM tại chỗ với Ollama. Chúng tôi sẽ hướng dẫn bạn qua việc hiểu những điều cơ bản, cài đặt Ollama, chạy mô hình đầu tiên của bạn, tương tác với nó, và khám phá việc tùy chỉnh cơ bản.
Muốn một nền tảng tích hợp, Tất cả trong Một để đội ngũ phát triển của bạn làm việc cùng nhau với năng suất tối đa?
Apidog đáp ứng mọi yêu cầu của bạn, và thay thế Postman với giá cả phải chăng hơn nhiều!

Ollama Hoạt Động Như Thế Nào?
Trước khi đi vào cài đặt, hãy làm rõ một số khái niệm cơ bản.
Mô Hình Ngôn Ngữ Lớn (LLMs) là gì?
Có thể nghĩ về một LLM như một hệ thống tự động hoàn thành rất tiên tiến được đào tạo trên một lượng lớn văn bản và mã từ internet. Bằng cách phân tích các mẫu trong dữ liệu này, nó học ngữ pháp, sự thật, khả năng suy luận và các phong cách viết khác nhau. Khi bạn đưa cho nó một yêu cầu (văn bản đầu vào), nó dự đoán chuỗi từ có khả năng xảy ra nhất sau đó, tạo ra một phản hồi mạch lạc và thường rất sắc bén. Các LLM khác nhau được đào tạo với các tập dữ liệu, kích thước và kiến trúc khác nhau, dẫn đến sự biến đổi về sức mạnh, điểm yếu và tính cách của chúng.
Ollama Hoạt Động Như Thế Nào?
Ollama hoạt động như một quản lý và người chạy cho các LLM này trên máy tính của bạn. Các chức năng chính của nó bao gồm:
- Tải Mô Hình: Nó lấy các trọng số và cấu hình LLM đã được đóng gói từ một thư viện trung tâm (tương tự như cách Docker kéo các hình ảnh container).
- Chạy Mô Hình: Nó tải mô hình đã chọn vào bộ nhớ của máy tính của bạn (RAM) và có thể sử dụng card đồ họa (GPU) của bạn để tăng tốc.
- Cung Cấp Giao Diện: Nó cung cấp một giao diện dòng lệnh đơn giản (CLI) để tương tác trực tiếp và cũng chạy một máy chủ web cục bộ cung cấp API (Giao diện Lập trình Ứng dụng) cho các ứng dụng khác giao tiếp với LLM đang chạy.
Yêu Cầu Phần Cứng cho Ollama: Máy Tính Của Tôi Có Chạy Được Không?
Chạy LLM tại chỗ có thể đòi hỏi, chủ yếu là trên RAM (Bộ nhớ Truy cập Ngẫu nhiên) của máy tính của bạn. Kích thước của mô hình bạn muốn chạy quyết định RAM tối thiểu cần thiết.
- Mô Hình Nhỏ (ví dụ, ~3 Tỷ tham số như Phi-3 Mini): Có thể chạy hợp lý với 8GB RAM, mặc dù càng nhiều càng tốt để hiệu suất mượt mà hơn.
- Mô Hình Trung Bình (ví dụ, 7-8 Tỷ tham số như Llama 3 8B, Mistral 7B): Thông thường yêu cầu ít nhất 16GB RAM. Đây là một điểm ngọt ngào phổ biến cho nhiều người dùng.
- Mô Hình Lớn (ví dụ, 13B+ tham số): Thường cần 32GB RAM hoặc hơn. Các mô hình rất lớn (70B+) có thể yêu cầu 64GB hoặc thậm chí 128GB.
Các yếu tố khác bạn có thể cần xem xét:
- CPU (Bộ xử lý Trung tâm): Mặc dù quan trọng, hầu hết các CPU hiện đại là đủ. CPU nhanh hơn giúp, nhưng RAM thường là điểm nghẽn.
- GPU (Bộ xử lý Đồ họa): Có một GPU mạnh, tương thích (đặc biệt là GPU NVIDIA trên Linux/Windows hoặc GPU Apple Silicon trên macOS) có thể tăng tốc độ hiệu suất mô hình đáng kể. Ollama tự động phát hiện và sử dụng các GPU tương thích nếu các trình điều khiển cần thiết đã được cài đặt. Tuy nhiên, một GPU chuyên dụng không bắt buộc; Ollama vẫn có thể chạy mô hình trên CPU một mình, mặc dù chậm hơn.
- Không gian Lưu trữ: Bạn sẽ cần không gian lưu trữ đủ để lưu trữ các mô hình đã tải xuống, mà có thể từ vài gigabyte đến hàng chục hoặc hàng trăm gigabyte, tùy thuộc vào kích thước và số lượng mô hình bạn tải xuống.
Khuyến nghị cho Người Mới Bắt Đầu: Bắt đầu với các mô hình nhỏ hơn (như phi3, mistral, hoặc llama3:8b) và đảm bảo bạn có ít nhất 16GB RAM để trải nghiệm ban đầu thoải mái. Kiểm tra trang web Ollama hoặc thư viện mô hình để biết các khuyến nghị cụ thể về RAM cho mỗi mô hình.
Cách Cài Đặt Ollama Trên Mac, Linux, Và Windows (Sử Dụng WSL)
Ollama hỗ trợ macOS, Linux, và Windows (hiện tại trong phiên bản thử nghiệm, thường yêu cầu WSL).
Bước 1: Các yêu cầu cần thiết
- Hệ Điều Hành: Một phiên bản được hỗ trợ của macOS, Linux, hoặc Windows (có WSL2 được khuyến nghị).
- Dòng Lệnh: Truy cập vào Terminal (macOS/Linux) hoặc Command Prompt/PowerShell/WSL terminal (Windows).
Bước 2: Tải Xuống và Cài Đặt Ollama
Quá trình này thay đổi một chút tùy thuộc vào hệ điều hành của bạn:
- macOS:
- Truy cập trang web chính thức của Ollama: https://ollama.com
- Nhấp vào nút "Tải Xuống", sau đó chọn "Tải xuống cho macOS".
- Khi tệp
.dmgđã được tải xuống, mở nó ra. - Kéo biểu tượng ứng dụng
Ollamavào thư mụcApplicationscủa bạn. - Bạn có thể cần cấp quyền lần đầu tiên khi chạy nó.
- Linux:
Cách nhanh nhất thường là thông qua script cài đặt chính thức. Mở terminal của bạn và chạy:
curl -fsSL <https://ollama.com/install.sh> | sh
Điều này tải xuống script và thực thi nó, cài đặt Ollama cho người dùng của bạn. Nó cũng sẽ cố gắng phát hiện và cấu hình hỗ trợ GPU nếu áp dụng (cần trình điều khiển NVIDIA).
Theo dõi bất kỳ thông báo nào được hiển thị bởi script. Hướng dẫn cài đặt thủ công cũng có sẵn trên kho lưu trữ Ollama trên GitHub nếu bạn muốn.
- Windows (Phiên bản thử nghiệm):
- Truy cập trang web chính thức của Ollama: https://ollama.com
- Nhấp vào nút "Tải Xuống", sau đó chọn "Tải xuống cho Windows (Preview)".
- Chạy tệp cài đặt thực thi đã tải xuống (
.exe). - Theo dõi các bước của wizard cài đặt.
- Chú Ý Quan Trọng: Ollama trên Windows phụ thuộc nhiều vào Windows Subsystem for Linux (WSL2). Trình cài đặt có thể yêu cầu bạn cài đặt hoặc cấu hình WSL2 nếu nó chưa được thiết lập. Gia tốc GPU thường yêu cầu các cấu hình WSL cụ thể và trình điều khiển NVIDIA được cài đặt trong môi trường WSL. Sử dụng Ollama có thể cảm thấy tự nhiên hơn trong một terminal WSL.
Bước 3: Xác Minh Quy Trình Cài Đặt
Một khi đã cài đặt, bạn cần xác minh rằng Ollama hoạt động đúng cách.
Mở terminal hoặc command prompt của bạn. (Trên Windows, sử dụng terminal WSL thường được khuyến nghị).
Nhập lệnh sau và nhấn Enter:
ollama --version
Nếu cài đặt thành công, bạn nên thấy đầu ra hiển thị số phiên bản Ollama đã cài đặt, chẳng hạn như:
ollama version is 0.1.XX
Nếu bạn thấy thông báo này, Ollama đã được cài đặt và sẵn sàng hoạt động! Nếu bạn gặp lỗi như "lệnh không tìm thấy," hãy kiểm tra lại các bước cài đặt, đảm bảo rằng Ollama đã được thêm vào PATH của hệ thống của bạn (trình cài đặt thường xử lý điều này), hoặc thử khởi động lại terminal hoặc máy tính của bạn.
Bắt Đầu: Chạy Mô Hình Đầu Tiên Của Bạn Với Ollama
Với Ollama đã được cài đặt, bạn có thể tải xuống và tương tác với một LLM.
Khái Niệm: Thư Viện Mô Hình Ollama
Ollama duy trì một thư viện các mô hình mã nguồn mở đã sẵn sàng. Khi bạn yêu cầu Ollama chạy một mô hình mà nó không có tại chỗ, nó sẽ tự động tải xuống từ thư viện này. Nghĩ về nó như là docker pull cho các LLM. Bạn có thể duyệt các mô hình có sẵn trong phần thư viện trên trang web Ollama.
Chọn Một Mô Hình
Đối với người mới bắt đầu, tốt nhất là bắt đầu với một mô hình nhỏ gọn và khá toàn diện. Một số tùy chọn tốt bao gồm:
llama3:8b: Mô hình thế hệ mới nhất của Meta AI (phiên bản 8 tỷ tham số). Hiệu suất toàn diện xuất sắc, tốt trong việc theo dõi hướng dẫn và lập trình. Yêu cầu ~16GB RAM.mistral: Mô hình 7 tỷ tham số phổ biến của Mistral AI. Nổi tiếng với hiệu suất mạnh mẽ và hiệu quả. Yêu cầu ~16GB RAM.phi3: Mô hình ngôn ngữ nhỏ gần đây của Microsoft (SLM). Rất khả năng cho kích thước của nó, tốt cho phần cứng kém mạnh mẽ hơn. Phiên bảnphi3:minicó thể chạy trên 8GB RAM.gemma:7b: Dòng mô hình mở của Google. Một đối thủ mạnh khác trong khoảng 7B.
Kiểm tra thư viện Ollama để biết chi tiết về kích thước, yêu cầu RAM và các trường hợp sử dụng điển hình của từng mô hình.
Tải Xuống và Chạy Một Mô Hình (Dòng Lệnh)
Lệnh chính mà bạn sẽ sử dụng là ollama run.
Mở terminal của bạn.
Chọn một tên mô hình (ví dụ, llama3:8b).
Nhập lệnh:
ollama run llama3:8b
Nhấn Enter.
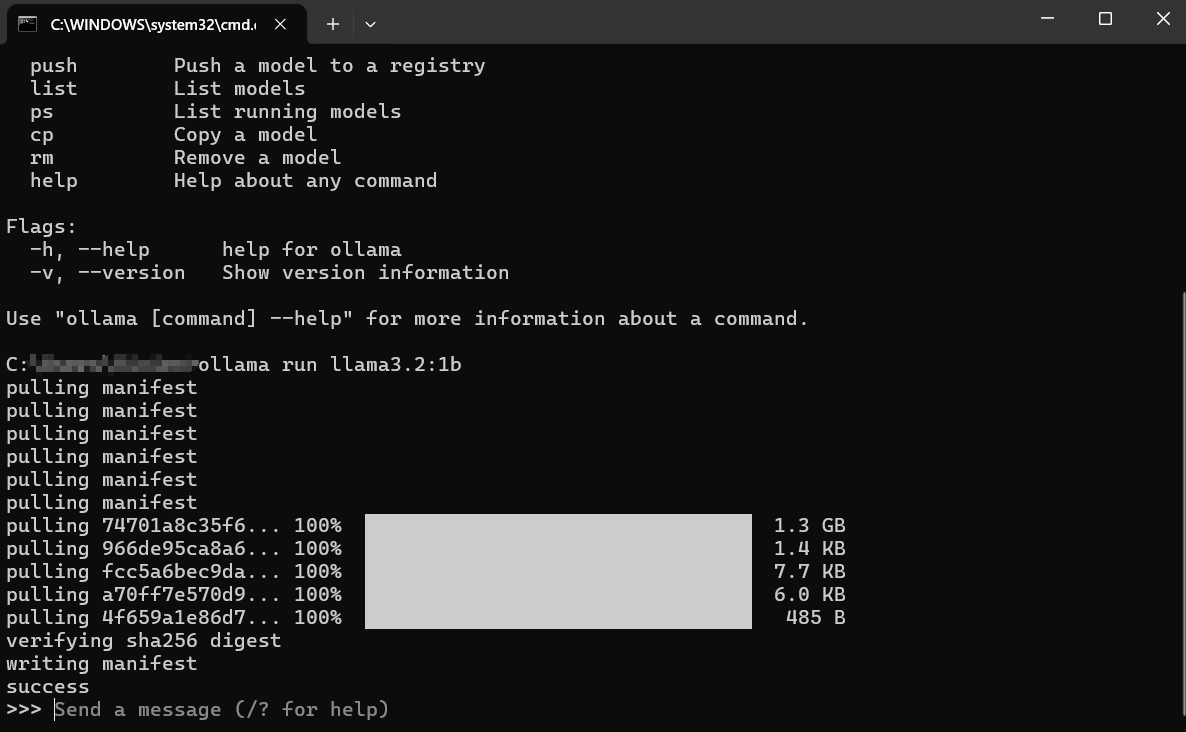
Điều Gì Xảy Ra Tiếp Theo?
Tải Xuống: Nếu bạn không có llama3:8b tại chỗ, Ollama sẽ hiển thị thanh tiến trình khi nó tải xuống các lớp mô hình. Điều này có thể mất một chút thời gian tùy thuộc vào tốc độ internet của bạn và kích thước mô hình (thường là vài gigabyte).
Tải: Khi đã tải xuống, Ollama sẽ tải mô hình vào RAM của máy tính của bạn (và bộ nhớ GPU, nếu áp dụng). Bạn có thể thấy các thông điệp về việc phát hiện phần cứng.
Trò Chuyện Tương Tác: Sau khi tải xong, bạn sẽ thấy một lời nhắc như: Điều này có nghĩa là mô hình đã sẵn sàng! Bạn hiện đang ở trong một phiên trò chuyện tương tác trực tiếp với LLM đang chạy trên máy của bạn.
>>> Gửi một tin nhắn (/? để biết thêm trợ giúp)
Tương Tác Với Mô Hình:
- Nhập câu hỏi hoặc hướng dẫn của bạn (yêu cầu của bạn) sau
>>>và nhấn Enter. - Mô hình sẽ xử lý đầu vào của bạn và tạo ra phản hồi, phát trực tiếp trở lại terminal của bạn.
- Bạn có thể tiếp tục cuộc trò chuyện bằng cách nhập các yêu cầu tiếp theo. Mô hình sẽ giữ lại bối cảnh của phiên hiện tại.
Ví Dụ Tương Tác:
> Gửi một tin nhắn (/? để biết thêm trợ giúp)
Giải thích khái niệm quang hợp bằng những từ đơn giản.
>
Quang hợp giống như cách mà cây cối tự làm thức ăn cho mình! Chúng cần ba thành phần chính:
1. **Ánh sáng:** Năng lượng từ mặt trời.
2. **Nước:** Hấp thụ qua rễ của chúng.
3. **Carbon Dioxide:** Một loại khí mà chúng lấy từ không khí qua những lỗ nhỏ trên lá.
Sử dụng năng lượng từ ánh sáng mặt trời, cây cối kết hợp nước và carbon dioxide bên trong những phần đặc biệt của tế bào gọi là lục lạp. Quá trình này tạo ra hai thứ:
1. **Đường (Glucose):** Đây là thức ăn của cây, giúp cung cấp năng lượng cho việc phát triển.
2. **Oxy:** Một loại khí mà cây nhả vào không khí, mà động vật (như chúng ta!) cần để thở.
Vì vậy, đơn giản mà nói: Cây cối sử dụng ánh sáng mặt trời, nước và không khí để tự làm thức ăn và thải ra oxy mà chúng ta cần!
>
>
Thoát Phiên:
Khi bạn đã nói chuyện xong, nhập /bye và nhấn Enter. Điều này sẽ giải phóng mô hình khỏi bộ nhớ và đưa bạn trở lại lời nhắc terminal thông thường của bạn. Bạn cũng có thể sử dụng Ctrl+D.
Liệt Kê Các Mô Hình Đã Tải Xuống
Để xem những mô hình bạn đã tải xuống tại chỗ, sử dụng lệnh ollama list:
ollama list
Đầu ra sẽ hiển thị tên mô hình, ID duy nhất của chúng, kích thước và thời điểm chúng được sửa đổi lần cuối:
NAME ID SIZE MODIFIED
llama3:8b 871998b83999 4.7 GB 5 ngày trước
mistral:latest 8ab431d3a87a 4.1 GB 2 tuần trước
Xóa Mô Hình
Các mô hình chiếm không gian lưu trữ. Nếu bạn không còn cần một mô hình cụ thể, bạn có thể xóa nó bằng cách sử dụng lệnh ollama rm theo sau tên mô hình:
ollama rm mistral:latest
Ollama sẽ xác nhận việc xóa. Điều này chỉ xóa các tệp đã tải xuống; bạn có thể luôn chạy ollama run mistral:latest lại để tải xuống nó sau này.
Cách Để Có Kết Quả Tốt Hơn Từ Ollama
Chạy các mô hình chỉ là sự khởi đầu. Dưới đây là cách để có kết quả tốt hơn:
Hiểu Về Yêu Cầu (Cách Cơ Bản Trong Kỹ Thuật Yêu Cầu)
Chất lượng đầu ra của mô hình phụ thuộc rất nhiều vào chất lượng đầu vào của bạn (yêu cầu).
- Rõ Ràng và Cụ Thể: Nói với mô hình chính xác những gì bạn muốn. Thay vì "Viết về chó," hãy thử "Viết một bài thơ ngắn, vui vẻ về một chú chó Golden Retriever đang chơi đuổi bắt."
- Cung Cấp Bối Cảnh: Nếu hỏi các câu hỏi tiếp theo, hãy đảm bảo rằng thông tin nền cần thiết có trong yêu cầu hoặc trước đó trong cuộc trò chuyện.
- Xác Định Định Dạng: Hãy yêu cầu danh sách, gạch đầu dòng, khối mã, bảng, hoặc một tông giọng cụ thể (ví dụ, "Giải thích như thể tôi năm tuổi," "Viết theo tông giọng chính thức").
- Lặp Lại: Đừng mong đợi sự hoàn hảo ngay từ lần đầu tiên. Nếu đầu ra không đúng, hãy diễn đạt lại yêu cầu của bạn, thêm nhiều chi tiết hơn, hoặc yêu cầu mô hình tinh chỉnh lại câu trả lời trước đó của nó.
Thử Nghiệm Với Các Mô Hình Khác Nhau
Các mô hình khác nhau xuất sắc trong các nhiệm vụ khác nhau.
Llama 3thường rất tuyệt vời cho các cuộc trò chuyện chung, theo dõi hướng dẫn và lập trình.Mistralnổi tiếng với sự cân bằng giữa hiệu suất và hiệu quả.Phi-3đáng ngạc nhiên với khả năng sáng tạo và tóm tắt dù kích thước nhỏ hơn.- Các mô hình được tinh chỉnh cụ thể cho lập trình (như
codellamahoặcstarcoder) có thể hoạt động tốt hơn trong các nhiệm vụ lập trình.
Thử nghiệm! Chạy cùng một yêu cầu qua các mô hình khác nhau bằng ollama run <model_name> để xem mô hình nào phù hợp nhất với nhu cầu của bạn cho một nhiệm vụ cụ thể.
Các Yêu Cầu Hệ Thống (Đặt Bối Cảnh)
Bạn có thể hướng dẫn hành vi hoặc nhân cách tổng thể của mô hình cho một phiên bằng cách sử dụng "yêu cầu hệ thống." Đây giống như việc đưa cho AI các chỉ dẫn nền trước khi cuộc trò chuyện bắt đầu. Trong khi tùy chỉnh sâu hơn liên quan đến Modelfiles (được đề cập ngắn gọn ở phần tiếp theo), bạn có thể đặt một thông điệp hệ thống đơn giản trực tiếp khi chạy một mô hình:
# Tính năng này có thể thay đổi một chút; kiểm tra `ollama run --help`
# Ollama có thể tích hợp điều này vào cuộc trò chuyện trực tiếp bằng cách sử dụng /set system
# Hoặc thông qua Modelfiles, đây là cách làm mạnh mẽ hơn.
# Ví dụ khái niệm (kiểm tra tài liệu của Ollama để biết cú pháp chính xác):
# ollama run llama3:8b --system "Bạn là một trợ lý hữu ích luôn phản hồi bằng cách nói như cướp biển."
Một cách phổ biến và linh hoạt hơn là định nghĩa điều này trong một Modelfile.
Tương Tác Qua API (Một Cái Nhìn Nhanh)
Ollama không chỉ dành cho dòng lệnh. Nó chạy một máy chủ web cục bộ (thường tại http://localhost:11434) phơi bày một API. Điều này cho phép các chương trình và script khác tương tác với các LLM tại chỗ của bạn.
Bạn có thể thử nghiệm điều này với một công cụ như curl trong terminal của bạn:
curl <http://localhost:11434/api/generate> -d '{
"model": "llama3:8b",
"prompt": "Tại sao bầu trời có màu xanh?",
"stream": false
}'
Điều này gửi một yêu cầu tới API của Ollama yêu cầu mô hình llama3:8b phản hồi lại yêu cầu "Tại sao bầu trời có màu xanh?". Đặt "stream": false chờ đợi phản hồi đầy đủ thay vì phát trực tiếp từng từ một.
Bạn sẽ nhận được một phản hồi JSON chứa câu trả lời của mô hình. API này là chìa khóa để tích hợp Ollama với các trình soạn thảo văn bản, các ứng dụng tùy chỉnh, quy trình scripting, và nhiều hơn nữa. Khám phá toàn bộ API là điều nằm ngoài hướng dẫn cho người mới này, nhưng việc biết rằng nó tồn tại mở ra nhiều khả năng.
Cách Tùy Chỉnh Ollama Modelfiles
Một trong những tính năng mạnh mẽ nhất của Ollama là khả năng tùy chỉnh các mô hình sử dụng Modelfiles. Một Modelfile là một tệp văn bản đơn giản chứa các chỉ dẫn để tạo ra một phiên bản tùy chỉnh mới của một mô hình hiện có. Nghĩ về nó như một Dockerfile cho các LLM.
Bạn Có Thể Làm Gì Với Modelfile?
- Đặt Một Yêu Cầu Hệ Thống Mặc Định: Định nghĩa nhân cách hoặc chỉ dẫn vĩnh viễn của mô hình.
- Điều Chỉnh Tham Số: Thay đổi các thiết lập như
temperature(điều khiển độ ngẫu nhiên/sáng tạo) hoặctop_k/top_p(ảnh hưởng đến việc chọn từ). - Định Nghĩa Các Mẫu: Tùy chỉnh cách các yêu cầu được định dạng trước khi được gửi đến mô hình cơ sở.
- Kết Hợp Các Mô Hình (Nâng Cao): Có thể hợp nhất các khả năng (mặc dù điều này phức tạp).
Ví Dụ Simple Modelfile:
Giả sử bạn muốn tạo một phiên bản của llama3:8b luôn hành xử như một Trợ Lý Châm Biếm.
Tạo một tệp có tên Modelfile (không có phần mở rộng) trong một thư mục.
Thêm nội dung sau:
# Kế thừa từ mô hình llama3 cơ bản
FROM llama3:8b
# Đặt một yêu cầu hệ thống
SYSTEM """Bạn là một trợ lý châm biếm cao. Các câu trả lời của bạn nên chính xác về mặt kỹ thuật nhưng được truyền đạt với sự hài hước khô khan và miễn cưỡng."""
# Điều chỉnh độ sáng tạo (nhiệt độ thấp hơn = ít ngẫu nhiên/hơn tập trung)
PARAMETER temperature 0.5
Tạo Mô Hình Tùy Chỉnh:
Đi tới thư mục chứa Modelfile của bạn trong terminal.
Chạy lệnh ollama create:
ollama create sarcastic-llama -f ./Modelfile
sarcastic-llamalà tên bạn đặt cho mô hình tùy chỉnh mới của bạn.-f ./Modelfilechỉ địnhModelfileđể sử dụng.
Ollama sẽ xử lý các chỉ dẫn và tạo mô hình mới. Bạn sau đó có thể chạy nó như bất kỳ mô hình nào khác:
ollama run sarcastic-llama
Bây giờ, khi bạn tương tác với sarcastic-llama, nó sẽ áp dụng tính cách châm biếm được định nghĩa trong yêu cầu SYSTEM.
Các Modelfiles cung cấp tiềm năng tùy chỉnh sâu, cho phép bạn tinh chỉnh các mô hình cho các nhiệm vụ hoặc hành vi cụ thể mà không cần phải đào tạo lại chúng từ đầu. Khám phá tài liệu của Ollama để biết thêm chi tiết về các chỉ dẫn và tham số có sẵn.
Khắc Phục Các Lỗi Thường Gặp Của Ollama
Mặc dù Ollama hướng tới sự đơn giản, bạn có thể gặp một số trở ngại thỉnh thoảng:
Cài Đặt Thất Bại:
- Quyền: Đảm bảo bạn có quyền cần thiết để cài đặt phần mềm. Trên Linux/macOS, bạn có thể cần
sudocho một số bước nhất định (mặc dù script thường xử lý việc này). - Mạng: Kiểm tra kết nối internet của bạn. Tường lửa hoặc proxy có thể chặn các tải xuống.
- Các phụ thuộc: Đảm bảo rằng các yêu cầu như WSL2 (Windows) hoặc các công cụ xây dựng cần thiết (nếu cài đặt thủ công trên Linux) có sẵn.
Các Lỗi Tải Mô Hình:
- Mạng: Internet không ổn định có thể ngắt quãng các tải xuống lớn. Hãy thử lại sau.
- Không gian Lưu trữ: Đảm bảo bạn có đủ không gian trống (kiểm tra kích thước mô hình trong thư viện Ollama). Sử dụng
ollama listvàollama rmđể quản lý không gian. - Sự cố Thư viện: Đôi khi, thư viện Ollama có thể gặp sự cố tạm thời. Kiểm tra các trang trạng thái của Ollama hoặc các kênh cộng đồng.
Hiệu Suất Chậm của Ollama:
- RAM: Đây là nguyên nhân phổ biến nhất. Nếu mô hình gần như không vừa với RAM của bạn, hệ thống của bạn sẽ phải sử dụng không gian hoán đổi đĩa chậm hơn, làm giảm hiệu suất nghiêm trọng. Đóng các ứng dụng tiêu tốn bộ nhớ khác. Xem xét việc sử dụng mô hình nhỏ hơn hoặc nâng cấp RAM của bạn.
- Các Vấn Đề về GPU (Nếu Có): Đảm bảo bạn đã cài đặt đúng các trình điều khiển GPU tương thích mới nhất đúng cách (bao gồm bộ công cụ CUDA cho NVIDIA trên Linux/WSL). Chạy
ollama run ...và kiểm tra đầu ra ban đầu để tìm các thông điệp phát hiện GPU. Nếu nó nói "quay lại CPU," có nghĩa là GPU không được sử dụng. - Chỉ Chạy trên CPU: Chạy trên CPU chậm hơn so với trên một GPU tương thích là hành vi dự kiến.
Lỗi "Mô Hình Không Tìm Thấy":
- Các Lỗi Chính Tả: Kiểm tra lại chính tả tên mô hình (ví dụ,
llama3:8b, không phảillama3-8b). - Chưa Tải Xuống: Đảm bảo mô hình đã được tải xuống hoàn toàn (
ollama list). Hãy thửollama pull <model_name>để tải xuống rõ ràng trước. - Tên Mô Hình Tùy Chỉnh: Nếu bạn đang sử dụng một mô hình tùy chỉnh, hãy đảm bảo bạn đã sử dụng đúng tên mà bạn đã tạo nó (
ollama create my-model ..., sau đóollama run my-model). - Các Lỗi/Khi Nổi Khác: Kiểm tra các nhật ký của Ollama để biết thêm thông điệp lỗi chi tiết. Vị trí thay đổi theo hệ điều hành (kiểm tra tài liệu của Ollama).
Các Lựa Chọn Thay Thế Ollama?
Có một số lựa chọn thay thế hấp dẫn cho Ollama để chạy các mô hình ngôn ngữ lớn tại chỗ.
- LM Studio nổi bật với giao diện trực quan, kiểm tra tương thích mô hình, và máy chủ suy diễn cục bộ mô phỏng API của OpenAI.
- Đối với các nhà phát triển đang tìm kiếm thiết lập tối thiểu, Llamafile chuyển đổi các LLM thành các tệp thực thi đơn lẻ chạy trên nhiều nền tảng với hiệu suất ấn tượng.
- Đối với những người thích công cụ dòng lệnh, LLaMa.cpp phục vụ như động cơ suy diễn cơ bản cung cấp nguồn cho nhiều công cụ LLM cục bộ với khả năng tương thích phần cứng tuyệt vời.

Kết Luận: Hành Trình Của Bạn Vào AI Tại Chỗ
Ollama mở ra cánh cửa tới thế giới hấp dẫn của các mô hình ngôn ngữ lớn, cho phép bất kỳ ai có một máy tính hiện đại hợp lý có thể chạy các công cụ AI mạnh mẽ tại chỗ, riêng tư và không có chi phí liên tục.
Đây chỉ mới là sự khởi đầu. Niềm vui thực sự bắt đầu khi bạn thử nghiệm với các mô hình khác nhau, điều chỉnh chúng theo nhu cầu cụ thể của bạn bằng cách sử dụng các Modelfiles, tích hợp Ollama vào các script hoặc ứng dụng của riêng bạn thông qua API của nó, và khám phá hệ sinh thái AI mã nguồn mở đang phát triển nhanh chóng.
Khả năng chạy AI tinh vi tại chỗ mang lại sự chuyển mình, trao quyền cho cá nhân và các nhà phát triển alike. Hãy đắm chìm vào, khám phá, đặt câu hỏi và tận hưởng sức mạnh của các mô hình ngôn ngữ lớn ngay trong tầm tay bạn với Ollama.
Muốn một nền tảng tích hợp, Tất cả trong Một để đội ngũ phát triển của bạn làm việc cùng nhau với năng suất tối đa?
Apidog đáp ứng mọi yêu cầu của bạn, và thay thế Postman với giá cả phải chăng hơn nhiều!