
Các mô hình gpt-oss-safeguard từ OpenAI đáp ứng nhu cầu này bằng cách cho phép suy luận dựa trên chính sách cho các tác vụ phân loại. Các kỹ sư tích hợp các mô hình này để phân loại nội dung do người dùng tạo, phát hiện vi phạm và duy trì tính toàn vẹn của nền tảng.
nút
Tìm hiểu GPT-OSS-Safeguard: Các tính năng và khả năng
Các kỹ sư của OpenAI đã phát triển gpt-oss-safeguard dưới dạng các mô hình suy luận mã nguồn mở được điều chỉnh để phân loại an toàn. Họ tinh chỉnh các mô hình này từ nền tảng gpt-oss, phát hành chúng theo giấy phép Apache 2.0. Các nhà phát triển tải xuống các mô hình từ Hugging Face và triển khai chúng một cách tự do. Dòng sản phẩm bao gồm gpt-oss-safeguard-20b và gpt-oss-safeguard-120b, trong đó các con số cho biết quy mô tham số.
Các mô hình này xử lý hai đầu vào chính: một chính sách do nhà phát triển định nghĩa và nội dung cần đánh giá. Hệ thống áp dụng suy luận chuỗi tư duy để diễn giải chính sách và phân loại nội dung. Ví dụ, nó xác định xem một tin nhắn người dùng có vi phạm các quy tắc về gian lận trong diễn đàn trò chơi hay không. Cách tiếp cận này cho phép cập nhật chính sách động mà không cần đào tạo lại, điều mà các bộ phân loại truyền thống yêu cầu.
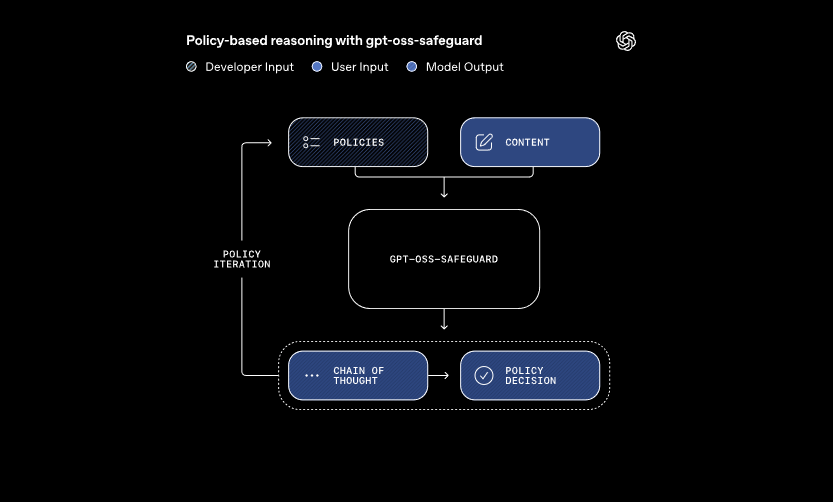
Hơn nữa, gpt-oss-safeguard hỗ trợ nhiều chính sách đồng thời. Các nhà phát triển đưa nhiều quy tắc vào một lệnh gọi suy luận duy nhất và mô hình đánh giá nội dung dựa trên tất cả các quy tắc đó. Khả năng này hợp lý hóa quy trình làm việc cho các nền tảng xử lý các rủi ro đa dạng, chẳng hạn như thông tin sai lệch hoặc lời nói có hại. Tuy nhiên, hiệu suất có thể giảm nhẹ khi thêm các chính sách, vì vậy các nhóm cần kiểm tra cấu hình kỹ lưỡng.
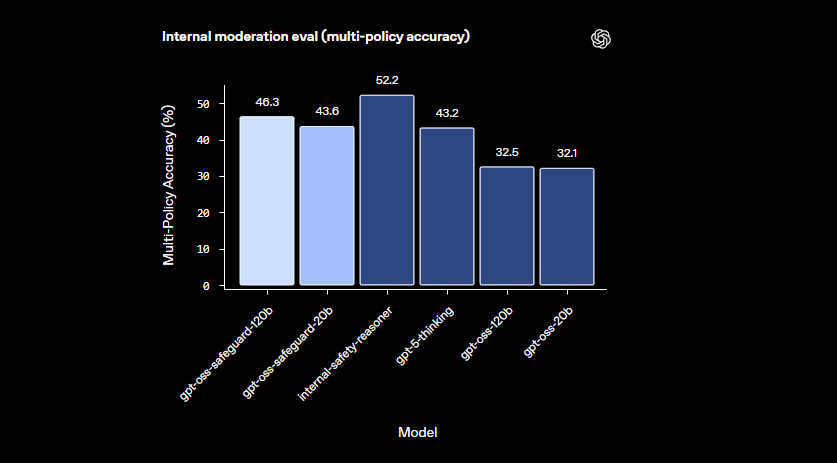
Các mô hình này vượt trội trong các lĩnh vực tinh tế mà các bộ phân loại nhỏ hơn gặp khó khăn. Chúng xử lý các mối nguy hại mới nổi bằng cách nhanh chóng thích ứng với các chính sách đã sửa đổi. Ngoài ra, đầu ra chuỗi tư duy cung cấp sự minh bạch—các nhà phát triển xem xét dấu vết suy luận để kiểm tra các quyết định. Tính năng này chứng tỏ giá trị to lớn đối với các nhóm tuân thủ yêu cầu AI có thể giải thích được.
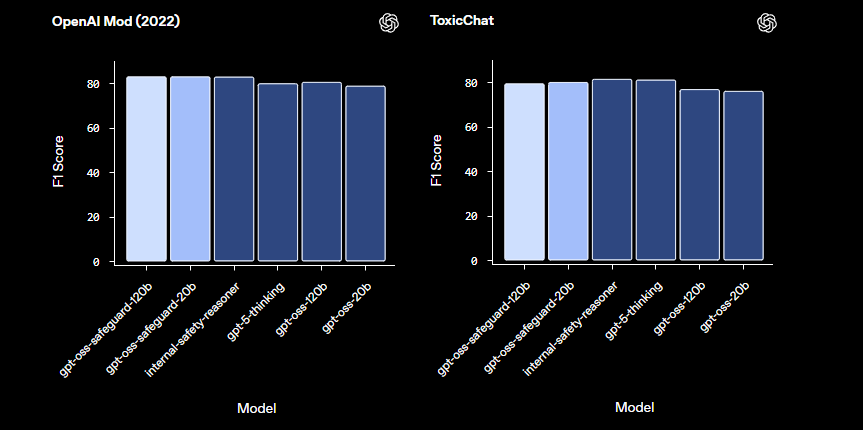
So với các mô hình an toàn được xây dựng sẵn như LlamaGuard, gpt-oss-safeguard cung cấp khả năng tùy chỉnh cao hơn. Nó tránh các phân loại cố định, trao quyền cho các tổ chức để xác định ngưỡng của riêng họ. Do đó, việc tích hợp phù hợp với các kỹ sư Trust & Safety xây dựng các quy trình kiểm duyệt có thể mở rộng. Bây giờ chúng ta đã nắm được các nguyên tắc cơ bản, hãy tiến hành thiết lập môi trường.
Thiết lập môi trường của bạn để truy cập API GPT-OSS-Safeguard
Các nhà phát triển bắt đầu bằng cách chuẩn bị hệ thống của họ để chạy gpt-oss-safeguard. Vì các mô hình là mã nguồn mở, bạn triển khai chúng cục bộ hoặc thông qua các nhà cung cấp dịch vụ lưu trữ. Tính linh hoạt này phù hợp với nhiều thiết lập phần cứng khác nhau, từ máy cá nhân đến máy chủ đám mây.
Đầu tiên, cài đặt các phụ thuộc cần thiết. Python 3.10 trở lên đóng vai trò là nền tảng. Sử dụng pip để thêm các thư viện như Hugging Face Transformers: pip install transformers. Để suy luận tăng tốc, hãy bao gồm torch với hỗ trợ CUDA nếu bạn sở hữu GPU tương thích. Các kỹ sư có phần cứng NVIDIA cho phép điều này để xử lý nhanh hơn.
Tiếp theo, tải xuống các mô hình từ Hugging Face. Truy cập bộ sưu tập. Chọn gpt-oss-safeguard-20b cho nhu cầu tài nguyên nhẹ hơn hoặc gpt-oss-safeguard-120b để có độ chính xác vượt trội. Lệnh transformers-cli download openai/gpt-oss-safeguard-20b truy xuất các tệp.
Để hiển thị API, hãy chạy một máy chủ cục bộ. Các công cụ như vLLM xử lý việc này một cách hiệu quả. Cài đặt vLLM bằng pip install vllm. Sau đó, khởi chạy máy chủ: vllm serve openai/gpt-oss-safeguard-20b. Lệnh này khởi động một điểm cuối tương thích với OpenAI tại http://localhost:8000/v1. Tương tự, Ollama đơn giản hóa việc triển khai: ollama run gpt-oss-safeguard:20b. Nó cung cấp các API REST để tích hợp.
Để kiểm tra cục bộ, LM Studio cung cấp giao diện thân thiện với người dùng. Thực thi lms get openai/gpt-oss-safeguard-20b để tìm nạp mô hình. Phần mềm mô phỏng API Chat Completions của OpenAI, cho phép chuyển đổi mã liền mạch sang sản xuất.
Các tùy chọn lưu trữ loại bỏ các lo ngại về phần cứng. Các nhà cung cấp như Groq hỗ trợ gpt-oss-safeguard-20b thông qua API của họ. Đăng ký tại https://console.groq.com, tạo khóa API và nhắm mục tiêu mô hình trong các yêu cầu. Giá bắt đầu từ 0,075 đô la cho mỗi triệu token đầu vào. OpenRouter cũng lưu trữ nó.
Sau khi thiết lập, hãy xác minh cài đặt. Gửi một yêu cầu kiểm tra qua curl: curl http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" -d '{"model": "openai/gpt-oss-safeguard-20b", "messages": [{"role": "system", "content": "Test policy"}, {"role": "user", "content": "Test content"}]}'. Một phản hồi thành công xác nhận sự sẵn sàng. Với môi trường đã được cấu hình, bạn sẽ tạo các chính sách tiếp theo.
Xây dựng các chính sách hiệu quả cho GPT-OSS-Safeguard
Các chính sách tạo thành xương sống của các hoạt động gpt-oss-safeguard. Các nhà phát triển viết chúng dưới dạng các lời nhắc có cấu trúc hướng dẫn phân loại. Một chính sách được thiết kế tốt sẽ tối đa hóa sức mạnh suy luận của mô hình, đảm bảo đầu ra chính xác và có thể giải thích được.
Cấu trúc chính sách của bạn với các phần riêng biệt. Bắt đầu với Hướng dẫn, chỉ định các nhiệm vụ của mô hình. Ví dụ, chỉ dẫn nó phân loại nội dung là vi phạm (1) hoặc an toàn (0). Tiếp theo là Định nghĩa, làm rõ các thuật ngữ chính như "ngôn ngữ phi nhân tính". Sau đó, phác thảo Tiêu chí cho các vi phạm và nội dung an toàn. Cuối cùng, bao gồm Ví dụ—cung cấp 4-6 trường hợp ranh giới được gắn nhãn tương ứng.
Sử dụng thể chủ động trong các chính sách: "Gắn cờ nội dung thúc đẩy bạo lực" thay vì các lựa chọn thay thế bị động. Giữ ngôn ngữ chính xác; tránh các mơ hồ như "thường không an toàn". Nếu có xung đột giữa các quy tắc, hãy xác định rõ ràng quyền ưu tiên. Đối với các kịch bản đa chính sách, hãy nối chúng trong thông báo hệ thống.
Kiểm soát độ sâu suy luận thông qua tham số "reasoning_effort": đặt nó thành "high" cho các trường hợp phức tạp hoặc "low" để tăng tốc độ. Định dạng hài hòa, được tích hợp trong gpt-oss-safeguard, tách biệt suy luận khỏi đầu ra cuối cùng. Điều này đảm bảo phản hồi API rõ ràng trong khi vẫn giữ được dấu vết kiểm toán.
Tối ưu hóa độ dài chính sách khoảng 400-600 token. Các chính sách ngắn hơn có nguy cơ đơn giản hóa quá mức, trong khi các chính sách dài hơn có thể làm mô hình bối rối. Kiểm tra lặp đi lặp lại: phân loại nội dung mẫu và tinh chỉnh dựa trên đầu ra. Các công cụ như bộ đếm token trong Hugging Face hỗ trợ ở đây.
Đối với định dạng đầu ra, chọn nhị phân để đơn giản: Trả về chính xác 0 hoặc 1. Thêm lý do cho độ sâu: {"violation": 1, "rationale": "Giải thích ở đây"}. Cấu trúc JSON này tích hợp dễ dàng với các hệ thống hạ nguồn. Khi bạn tinh chỉnh các chính sách, hãy chuyển sang triển khai API.
Triển khai các lệnh gọi API với GPT-OSS-Safeguard
Các nhà phát triển tương tác với gpt-oss-safeguard thông qua các điểm cuối tương thích với OpenAI. Dù cục bộ hay được lưu trữ, quy trình này tuân theo các mẫu hoàn thành trò chuyện tiêu chuẩn.
Chuẩn bị máy khách của bạn. Trong Python, nhập OpenAI: from openai import OpenAI. Khởi tạo với URL cơ sở và khóa: client = OpenAI(base_url="http://localhost:8000/v1", api_key="dummy") cho cục bộ, hoặc các giá trị cụ thể của nhà cung cấp.
Xây dựng tin nhắn. Vai trò hệ thống giữ chính sách: {"role": "system", "content": "Chính sách chi tiết của bạn ở đây"}. Vai trò người dùng chứa nội dung: {"role": "user", "content": "Nội dung cần phân loại"}.
Gọi API: completion = client.chat.completions.create(model="openai/gpt-oss-safeguard-20b", messages=messages, max_tokens=500, temperature=0.0). Nhiệt độ ở 0 đảm bảo đầu ra xác định cho các tác vụ an toàn.
Phân tích phản hồi: result = completion.choices[0].message.content. Đối với đầu ra có cấu trúc, sử dụng phân tích cú pháp JSON. Groq nâng cao điều này với bộ nhớ đệm lời nhắc—tái sử dụng các chính sách giữa các lệnh gọi để giảm chi phí 50%.
Xử lý phát trực tuyến để phản hồi theo thời gian thực: đặt stream=True và lặp lại các đoạn. Điều này phù hợp với việc kiểm duyệt khối lượng lớn.
Tích hợp các công cụ nếu cần, mặc dù gpt-oss-safeguard tập trung vào phân loại. Định nghĩa các hàm trong tham số tools cho các khả năng mở rộng, như tìm nạp dữ liệu bên ngoài.
Giám sát việc sử dụng token: đầu vào bao gồm chính sách cộng với nội dung, đầu ra thêm suy luận. Giới hạn max_tokens để ngăn tràn. Với các lệnh gọi đã thành thạo, hãy khám phá các ví dụ.
Các tính năng nâng cao trong API GPT-OSS-Safeguard
gpt-oss-safeguard cung cấp các công cụ nâng cao để kiểm soát tinh tế. Bộ nhớ đệm lời nhắc trên Groq tái sử dụng các chính sách, giảm độ trễ và chi phí.
Điều chỉnh reasoning_effort trong thông báo hệ thống: "Reasoning: high" để phân tích sâu. Điều này xử lý nội dung mơ hồ tốt hơn.
Tận dụng cửa sổ ngữ cảnh 128k cho các cuộc trò chuyện hoặc tài liệu dài. Cung cấp toàn bộ cuộc trò chuyện để phân loại toàn diện.
Tích hợp với các hệ thống lớn hơn: Đưa đầu ra vào hàng đợi leo thang hoặc ghi nhật ký. Sử dụng webhook để cảnh báo theo thời gian thực.
Tinh chỉnh thêm nếu cần, mặc dù cơ sở xuất sắc trong việc tuân thủ chính sách. Kết hợp với các mô hình nhỏ hơn để lọc trước, tối ưu hóa tính toán.
Vấn đề bảo mật: Bảo mật khóa API và giám sát các cuộc tấn công prompt injection. Xác thực đầu vào để ngăn chặn khai thác.
Khả năng mở rộng: Triển khai trên các cụm với vLLM để có thông lượng cao. Các nhà cung cấp như Groq cung cấp hơn 1000 token/giây.
Những tính năng này nâng gpt-oss-safeguard từ một bộ phân loại cơ bản lên thành một công cụ doanh nghiệp. Tuy nhiên, hãy tuân thủ các phương pháp hay nhất để có kết quả tối ưu.
Các phương pháp hay nhất và tối ưu hóa cho GPT-OSS-Safeguard
Các kỹ sư tối ưu hóa gpt-oss-safeguard bằng cách lặp lại các chính sách. Kiểm tra với các tập dữ liệu đa dạng, đo lường độ chính xác thông qua các chỉ số như điểm F1.
Cân bằng kích thước mô hình: Sử dụng 20b cho tốc độ, 120b cho độ chính xác. Lượng tử hóa trọng số để giảm dung lượng bộ nhớ.
Giám sát hiệu suất: Ghi lại dấu vết suy luận để kiểm toán. Điều chỉnh nhiệt độ tối thiểu—0.0 phù hợp với nhu cầu xác định.
Xử lý các hạn chế: Mô hình có thể gặp khó khăn với các lĩnh vực chuyên biệt cao; bổ sung bằng dữ liệu miền.
Đảm bảo sử dụng có đạo đức: Căn chỉnh các chính sách với các quy định. Tránh thiên vị bằng cách đa dạng hóa các ví dụ.
Cập nhật thường xuyên: Khi OpenAI phát triển gpt-oss-safeguard, hãy kết hợp các cải tiến.
Quản lý chi phí: Đối với các API được lưu trữ, theo dõi chi tiêu token. Triển khai cục bộ giảm thiểu chi phí.
Bằng cách áp dụng các phương pháp này, bạn tối đa hóa hiệu quả. Tóm lại, gpt-oss-safeguard trao quyền cho các hệ thống an toàn mạnh mẽ.
Kết luận: Tích hợp GPT-OSS-Safeguard vào quy trình làm việc của bạn
Các nhà phát triển khai thác gpt-oss-safeguard để xây dựng các bộ phân loại an toàn có khả năng thích ứng. Từ thiết lập đến sử dụng nâng cao, hướng dẫn này trang bị cho bạn kiến thức kỹ thuật. Triển khai các chính sách, thực hiện các lệnh gọi API và tối ưu hóa cho nhu cầu của bạn. Khi các nền tảng phát triển, gpt-oss-safeguard thích ứng liền mạch, đảm bảo môi trường an toàn.
nút