
Bạn muốn tăng cường quy trình làm việc mã hóa của mình với GPT-OSS, mô hình mã nguồn mở của Open AI, ngay bên trong Claude Code? Bạn sắp có một trải nghiệm tuyệt vời! Ra mắt vào tháng 8 năm 2025, GPT-OSS (phiên bản 20B hoặc 120B) là một công cụ mạnh mẽ cho việc viết mã và suy luận, và bạn có thể kết hợp nó với giao diện CLI bóng bẩy của Claude Code để có các thiết lập miễn phí hoặc chi phí thấp. Trong hướng dẫn đàm thoại này, chúng tôi sẽ chỉ cho bạn ba cách để tích hợp GPT-OSS với Claude Code bằng cách sử dụng Hugging Face, OpenRouter hoặc LiteLLM. Hãy cùng tìm hiểu và đưa trợ thủ mã hóa AI của bạn vào hoạt động!
Bạn muốn một nền tảng tích hợp, tất cả trong một để Đội ngũ phát triển của bạn làm việc cùng nhau với năng suất tối đa?
Apidog đáp ứng mọi yêu cầu của bạn và thay thế Postman với mức giá phải chăng hơn nhiều!
GPT-OSS là gì và tại sao nên sử dụng nó với Claude Code?
GPT-OSS là dòng mô hình mã nguồn mở của Open AI, với các biến thể 20B và 120B mang lại hiệu suất vượt trội cho các tác vụ mã hóa, suy luận và tác nhân. Với cửa sổ ngữ cảnh 128K token và giấy phép Apache 2.0, nó hoàn hảo cho các nhà phát triển muốn có sự linh hoạt và kiểm soát. Claude Code, công cụ CLI của Anthropic (phiên bản 0.5.3+), là một công cụ được các nhà phát triển yêu thích nhờ khả năng mã hóa đàm thoại. Bằng cách định tuyến Claude Code tới GPT-OSS thông qua các API tương thích với OpenAI, bạn có thể tận hưởng giao diện quen thuộc của Claude trong khi tận dụng sức mạnh mã nguồn mở của GPT-OSS—mà không phải trả phí đăng ký của Anthropic. Sẵn sàng thực hiện chưa? Hãy cùng khám phá các tùy chọn thiết lập!

Điều kiện tiên quyết để sử dụng GPT-OSS với Claude Code
Trước khi bắt đầu, hãy đảm bảo bạn có:
- Claude Code ≥ 0.5.3: Kiểm tra bằng
claude --version. Cài đặt quapip install claude-codehoặc cập nhật bằngpip install --upgrade claude-code. - Tài khoản Hugging Face: Đăng ký tại huggingface.co và tạo mã thông báo đọc/ghi (Cài đặt > Mã thông báo truy cập).
- Khóa API OpenRouter: Tùy chọn, cho Đường dẫn B. Lấy một khóa tại openrouter.ai.
- Python 3.10+ và Docker: Dành cho các thiết lập cục bộ hoặc LiteLLM (Đường dẫn C).
- Kiến thức CLI cơ bản: Quen thuộc với các biến môi trường và lệnh terminal sẽ hữu ích.
Đường dẫn A: Tự lưu trữ GPT-OSS trên Hugging Face
Muốn kiểm soát hoàn toàn? Lưu trữ GPT-OSS trên các Điểm cuối suy luận của Hugging Face để có một thiết lập riêng tư, có thể mở rộng. Đây là cách thực hiện:
Bước 1: Lấy mô hình
- Truy cập kho lưu trữ GPT-OSS trên Hugging Face (openai/gpt-oss-20b hoặc openai/gpt-oss-120b).
- Chấp nhận giấy phép Apache 2.0 để truy cập mô hình.
- Ngoài ra, hãy thử Qwen3-Coder-480B-A35B-Instruct (Qwen/Qwen3-Coder-480B-A35B-Instruct) cho một mô hình tập trung vào mã hóa (sử dụng phiên bản GGUF cho phần cứng nhẹ hơn).
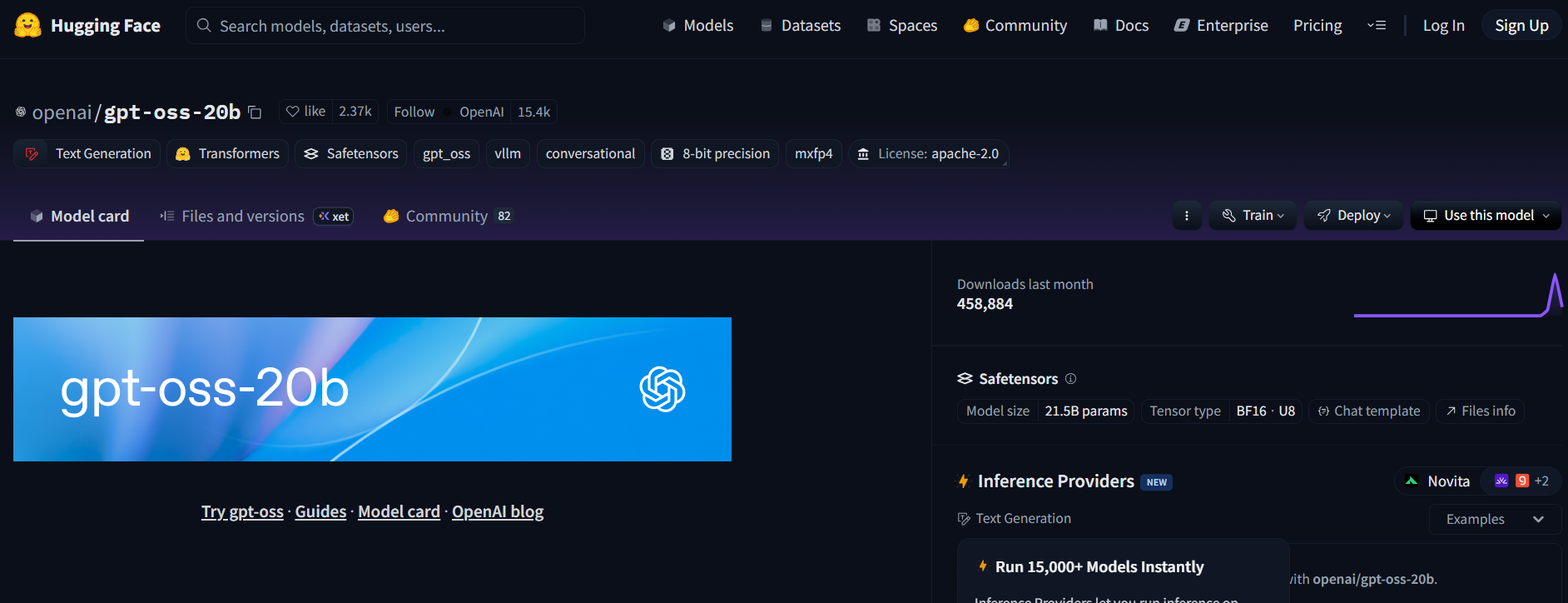
Bước 2: Triển khai một điểm cuối suy luận tạo văn bản
- Trên trang mô hình, nhấp vào Deploy (Triển khai) > Inference Endpoint (Điểm cuối suy luận).
- Chọn mẫu Text Generation Inference (TGI) (≥ v1.4.0).
- Bật khả năng tương thích OpenAI bằng cách chọn Enable OpenAI compatibility (Bật khả năng tương thích OpenAI) hoặc thêm
--enable-openaitrong cài đặt nâng cao. - Chọn phần cứng: A10G hoặc CPU cho 20B, A100 cho 120B. Tạo điểm cuối.
Bước 3: Thu thập thông tin xác thực
- Khi trạng thái điểm cuối là Running (Đang chạy), sao chép:
- ENDPOINT_URL: Có dạng
https://<your-endpoint>.us-east-1.aws.endpoints.huggingface.cloud. - HF_API_TOKEN: Mã thông báo Hugging Face của bạn từ Cài đặt > Mã thông báo truy cập.
2. Ghi lại ID mô hình (ví dụ: gpt-oss-20b hoặc gpt-oss-120b).
Bước 4: Cấu hình Claude Code
- Đặt các biến môi trường trong terminal của bạn:
export ANTHROPIC_BASE_URL="https://<your-endpoint>.us-east-1.aws.endpoints.huggingface.cloud"
export ANTHROPIC_AUTH_TOKEN="hf_xxxxxxxxxxxxxxxxx"
export ANTHROPIC_MODEL="gpt-oss-20b" # hoặc gpt-oss-120b
Thay thế <your-endpoint> và hf_xxxxxxxxxxxxxxxxx bằng các giá trị của bạn.
2. Kiểm tra thiết lập:
claude --model gpt-oss-20b
Claude Code định tuyến đến điểm cuối GPT-OSS của bạn, truyền phát phản hồi qua API /v1/chat/completions của TGI, mô phỏng lược đồ của OpenAI.
Bước 5: Lưu ý về chi phí và khả năng mở rộng
- Chi phí Hugging Face: Các điểm cuối suy luận tự động mở rộng quy mô, vì vậy hãy theo dõi việc sử dụng để tránh đốt cháy tín dụng. A10G có giá khoảng 0,60 USD/giờ, A100 khoảng 3 USD/giờ.
- Tùy chọn cục bộ: Để không mất chi phí đám mây, hãy chạy TGI cục bộ với Docker:
docker run --name tgi -p 8080:80 -e HF_TOKEN=hf_xxxxxxxxxxxxxxxxx ghcr.io/huggingface/text-generation-inference:latest --model-id openai/gpt-oss-20b --enable-openai
Sau đó đặt ANTHROPIC_BASE_URL="http://localhost:8080".
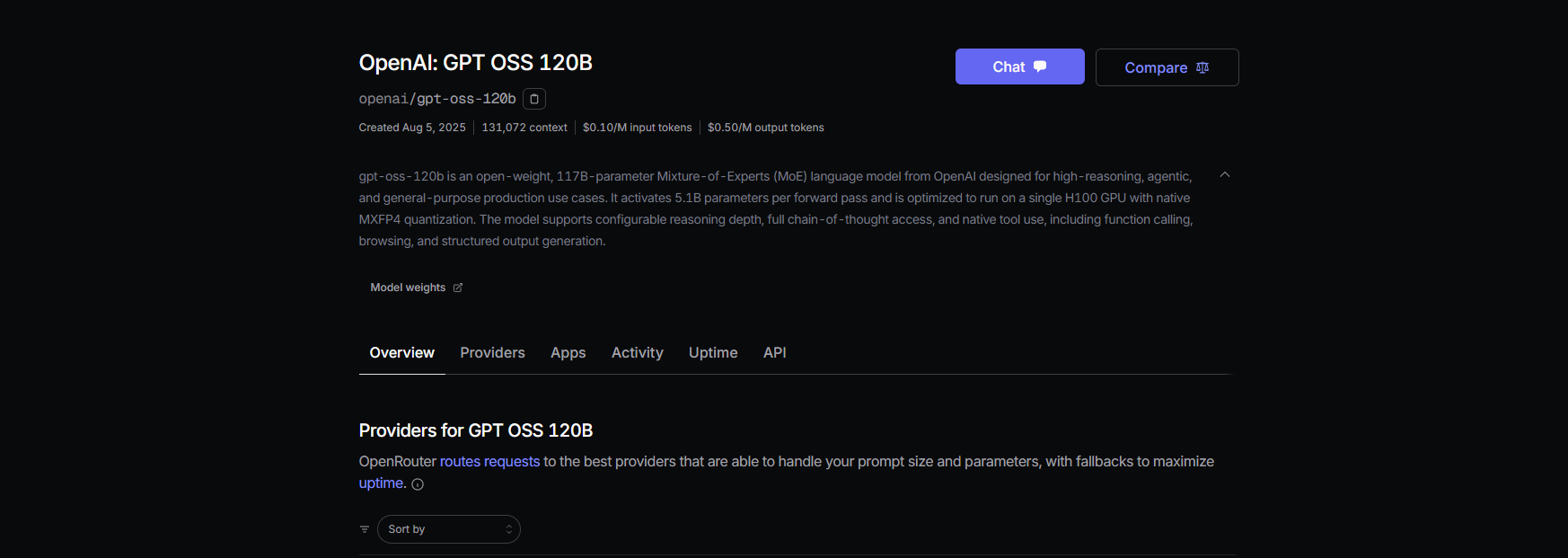
Đường dẫn B: Proxy GPT-OSS qua OpenRouter
Không có DevOps? Không vấn đề gì! Sử dụng OpenRouter để truy cập GPT-OSS với thiết lập tối thiểu. Nó nhanh chóng và xử lý thanh toán cho bạn.
Bước 1: Đăng ký và chọn một mô hình
- Đăng ký tại openrouter.ai và sao chép khóa API của bạn từ phần Keys (Khóa).
- Chọn một slug mô hình:
openai/gpt-oss-20bopenai/gpt-oss-120bqwen/qwen3-coder-480b(cho mô hình coder của Qwen)
Bước 2: Cấu hình Claude Code
- Đặt các biến môi trường:
export ANTHROPIC_BASE_URL="https://openrouter.ai/api/v1"
export ANTHROPIC_AUTH_TOKEN="or_xxxxxxxxx"
export ANTHROPIC_MODEL="openai/gpt-oss-20b"
Thay thế or_xxxxxxxxx bằng khóa API OpenRouter của bạn.
2. Kiểm tra:
claude --model openai/gpt-oss-20b
Claude Code kết nối với GPT-OSS qua API hợp nhất của OpenRouter, với hỗ trợ truyền phát và dự phòng.
Bước 3: Lưu ý về chi phí
- Giá OpenRouter: Khoảng 0,50 USD/triệu token đầu vào, khoảng 2,00 USD/triệu token đầu ra cho GPT-OSS-120B, rẻ hơn đáng kể so với các mô hình độc quyền như GPT-4 (khoảng 20,00 USD/triệu).
- Thanh toán: OpenRouter quản lý việc sử dụng, vì vậy bạn chỉ trả tiền cho những gì bạn sử dụng.
Đường dẫn C: Sử dụng LiteLLM cho các nhóm mô hình hỗn hợp
Bạn muốn sử dụng đồng thời các mô hình GPT-OSS, Qwen và Anthropic trong một quy trình làm việc? LiteLLM hoạt động như một proxy để hoán đổi nóng các mô hình một cách liền mạch.
Bước 1: Cài đặt và cấu hình LiteLLM
- Cài đặt LiteLLM:
pip install litellm
2. Tạo một tệp cấu hình (litellm.yaml):
model_list:
- model_name: gpt-oss-20b
litellm_params:
model: openai/gpt-oss-20b
api_key: or_xxxxxxxxx # Khóa OpenRouter
api_base: https://openrouter.ai/api/v1
- model_name: qwen3-coder
litellm_params:
model: openrouter/qwen/qwen3-coder
api_key: or_xxxxxxxxx
api_base: https://openrouter.ai/api/v1
Thay thế or_xxxxxxxxx bằng khóa OpenRouter của bạn.
3. Khởi động proxy:
litellm --config litellm.yaml
Bước 2: Trỏ Claude Code tới LiteLLM
- Đặt các biến môi trường:
export ANTHROPIC_BASE_URL="http://localhost:4000"
export ANTHROPIC_AUTH_TOKEN="litellm_master"
export ANTHROPIC_MODEL="gpt-oss-20b"
2. Kiểm tra:
claude --model gpt-oss-20b
LiteLLM định tuyến các yêu cầu tới GPT-OSS qua OpenRouter, với tính năng ghi nhật ký chi phí và định tuyến xáo trộn đơn giản để đảm bảo độ tin cậy.
Bước 3: Lưu ý
- Tránh định tuyến độ trễ: Sử dụng chế độ xáo trộn đơn giản trong LiteLLM để ngăn ngừa sự cố với các mô hình Anthropic.
- Theo dõi chi phí: LiteLLM ghi lại việc sử dụng để đảm bảo tính minh bạch.
Kiểm tra GPT-OSS với Claude Code
Hãy đảm bảo GPT-OSS đang hoạt động! Mở Claude Code và thử các lệnh sau:
Tạo mã:
claude --model gpt-oss-20b "Write a Python REST API with Flask"
Mong đợi một phản hồi như sau:
from flask import Flask, jsonify
app = Flask(__name__)
@app.route('/api', methods=['GET'])
def get_data():
return jsonify({"message": "Hello from GPT-OSS!"})
if __name__ == '__main__':
app.run(debug=True)
Phân tích codebase:
claude --model gpt-oss-20b "Summarize src/server.js"
GPT-OSS tận dụng cửa sổ ngữ cảnh 128K của nó để phân tích tệp JavaScript của bạn và trả về một bản tóm tắt.
Gỡ lỗi:
claude --model gpt-oss-20b "Debug this buggy Python code: [paste code]"
Với tỷ lệ vượt qua HumanEval 87,3%, GPT-OSS sẽ phát hiện và sửa lỗi một cách chính xác.
Mẹo khắc phục sự cố
- Lỗi 404 trên /v1/chat/completions? Đảm bảo
--enable-openaiđang hoạt động trong TGI (Đường dẫn A) hoặc kiểm tra tính khả dụng của mô hình OpenRouter (Đường dẫn B). - Phản hồi trống? Xác minh
ANTHROPIC_MODELkhớp với slug (ví dụ:gpt-oss-20b). - Lỗi 400 sau khi hoán đổi mô hình? Sử dụng định tuyến xáo trộn đơn giản trong LiteLLM (Đường dẫn C).
- Token đầu tiên chậm? Làm nóng các điểm cuối Hugging Face bằng một lời nhắc nhỏ sau khi thu nhỏ về không.
- Claude Code bị lỗi? Cập nhật lên ≥ 0.5.3 và đảm bảo các biến môi trường được đặt đúng.
Tại sao nên sử dụng GPT-OSS với Claude Code?
Kết hợp GPT-OSS với Claude Code là ước mơ của mọi nhà phát triển. Bạn sẽ nhận được:
- Tiết kiệm chi phí: 0,50 USD/triệu token đầu vào của OpenRouter vượt trội so với các mô hình độc quyền, và các thiết lập TGI cục bộ là miễn phí sau chi phí phần cứng.
- Sức mạnh mã nguồn mở: Giấy phép Apache 2.0 của GPT-OSS cho phép bạn tùy chỉnh hoặc triển khai riêng tư.
- Quy trình làm việc liền mạch: CLI của Claude Code mang lại cảm giác như đang trò chuyện với một người bạn lập trình, trong khi GPT-OSS xử lý các tác vụ nặng nhọc với điểm MMLU 94,2% và AIME 96,6%.
- Linh hoạt: Hoán đổi giữa các mô hình GPT-OSS, Qwen hoặc Anthropic bằng LiteLLM hoặc OpenRouter.
Người dùng đang ca ngợi khả năng mã hóa của GPT-OSS, gọi nó là “một con quái vật thân thiện với ngân sách cho các dự án đa tệp.” Dù bạn tự lưu trữ hay proxy qua OpenRouter, thiết lập này giúp giữ chi phí thấp và năng suất cao.
Kết luận
Giờ đây bạn đã sẵn sàng sử dụng GPT-OSS với Claude Code! Dù bạn tự lưu trữ trên Hugging Face, proxy qua OpenRouter hay sử dụng LiteLLM để quản lý mô hình, bạn đều có một thiết lập mã hóa mạnh mẽ, hiệu quả về chi phí. Từ việc tạo API REST đến gỡ lỗi mã, GPT-OSS đều đáp ứng, và Claude Code giúp mọi thứ trở nên dễ dàng. Hãy dùng thử, chia sẻ các lời nhắc yêu thích của bạn trong phần bình luận và hãy cùng nhau tìm hiểu sâu hơn về mã hóa AI!
Bạn muốn một nền tảng tích hợp, tất cả trong một để Đội ngũ phát triển của bạn làm việc cùng nhau với năng suất tối đa?
Apidog đáp ứng mọi yêu cầu của bạn và thay thế Postman với mức giá phải chăng hơn nhiều!