
Các nhà phát triển không ngừng tìm kiếm các công cụ mạnh mẽ để xây dựng ứng dụng thông minh. OpenAI đáp ứng nhu cầu này với việc phát hành GPT-OSS, một loạt các mô hình ngôn ngữ mã nguồn mở (open-weight) cung cấp khả năng suy luận nâng cao. Các mô hình này, bao gồm gpt-oss-120b và gpt-oss-20b, cho phép tùy chỉnh và triển khai trong nhiều môi trường khác nhau. Người dùng truy cập chúng thông qua các API được cung cấp bởi các nền tảng lưu trữ, cho phép tích hợp liền mạch vào các dự án.
Để bắt đầu làm việc với API GPT-OSS, các nhà phát triển có thể truy cập thông qua các nhà cung cấp như OpenRouter hoặc Together AI. Các nền tảng này lưu trữ các mô hình và cung cấp các điểm cuối tiêu chuẩn tương thích với định dạng API của OpenAI. Khả năng tương thích này giúp đơn giản hóa việc di chuyển từ các mô hình độc quyền.
GPT-OSS là gì? Các tính năng và khả năng chính
OpenAI thiết kế GPT-OSS như một họ mô hình Mixture-of-Experts (MoE). Kiến trúc này chỉ kích hoạt một tập hợp con các tham số trên mỗi token, giúp tăng cường hiệu quả. Ví dụ, gpt-oss-120b có tổng cộng 117 tỷ tham số nhưng chỉ kích hoạt 5,1 tỷ trên mỗi token. Tương tự, gpt-oss-20b sử dụng 21 tỷ tham số với 3,6 tỷ hoạt động.
Các mô hình sử dụng cấu trúc dựa trên Transformer với các lớp chú ý (attention layers) dày đặc và thưa thớt xen kẽ. Chúng tích hợp Rotary Positional Embeddings (RoPE) để xử lý các ngữ cảnh dài lên đến 128.000 token. Các nhà phát triển được hưởng lợi từ điều này trong các ứng dụng yêu cầu đầu vào lớn, chẳng hạn như tóm tắt tài liệu.
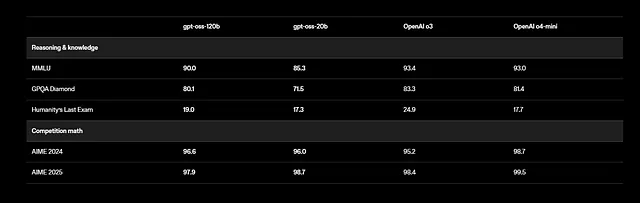
Hơn nữa, GPT-OSS hỗ trợ các tác vụ đa ngôn ngữ, mặc dù việc đào tạo tập trung vào tiếng Anh với trọng tâm là dữ liệu STEM và mã hóa. Các điểm chuẩn cho thấy kết quả ấn tượng: gpt-oss-120b đạt 94,2% trên MMLU (Massive Multitask Language Understanding) và 96,6% trên AIME (American Invitational Mathematics Examination). Nó vượt trội hơn các mô hình như o4-mini trong các truy vấn liên quan đến sức khỏe và toán học thi đấu.
Các nhà phát triển sử dụng các tính năng gọi công cụ (tool calling), nơi mô hình gọi các hàm bên ngoài như tìm kiếm web hoặc thực thi mã. Khả năng tác nhân này cho phép xây dựng các hệ thống tự chủ. Ví dụ, mô hình chuỗi nhiều lệnh gọi công cụ trong một phản hồi duy nhất để giải quyết vấn đề từng bước một.
Ngoài ra, các mô hình tuân thủ giấy phép Apache 2.0, cho phép sửa đổi và triển khai miễn phí. OpenAI cung cấp trọng số trên Hugging Face, được lượng tử hóa ở định dạng MXFP4 để giảm mức sử dụng bộ nhớ. Người dùng có thể chạy chúng cục bộ hoặc thông qua các nhà cung cấp dịch vụ đám mây.
Tuy nhiên, các cân nhắc về an toàn vẫn được áp dụng. OpenAI tiến hành đánh giá theo Khung Chuẩn bị (Preparedness Framework) của mình, kiểm tra các rủi ro như thông tin sai lệch. Các nhà phát triển thực hiện các biện pháp bảo vệ, chẳng hạn như lọc đầu ra, để giảm thiểu các vấn đề.
Về bản chất, GPT-OSS kết hợp sức mạnh với khả năng tiếp cận. Bản chất mở của nó khuyến khích sự đóng góp của cộng đồng, dẫn đến những cải tiến nhanh chóng. Tiếp theo, hãy xác định các nhà cung cấp cung cấp quyền truy cập API vào các mô hình này.
Chọn nhà cung cấp để truy cập API GPT-OSS
Một số nền tảng lưu trữ các mô hình GPT-OSS và cung cấp các điểm cuối API. Các nhà phát triển lựa chọn dựa trên các nhu cầu như tốc độ, chi phí và khả năng mở rộng. Ví dụ, OpenRouter cung cấp gpt-oss-120b với mức giá cạnh tranh và tích hợp dễ dàng.
Together AI cung cấp một tùy chọn khác, nhấn mạnh việc triển khai sẵn sàng cho doanh nghiệp. Nó hỗ trợ mô hình thông qua điểm cuối /v1/chat/completions, tương thích với các client của OpenAI. Các nhà phát triển gửi các tải trọng JSON chỉ định tin nhắn, max_tokens và temperature.
Hơn nữa, Fireworks AI và Cerebras cung cấp khả năng suy luận tốc độ cao. Cerebras đạt tới 3.000 token mỗi giây, lý tưởng cho các ứng dụng thời gian thực. Giá cả khác nhau: OpenRouter tính phí khoảng 0,15 đô la cho mỗi triệu token đầu vào, trong khi Together AI cung cấp mức giá tương tự với chiết khấu theo khối lượng.
Các nhà phát triển cũng cân nhắc việc tự lưu trữ để bảo mật. Các công cụ như vLLM hoặc Ollama cho phép chạy GPT-OSS trên các máy chủ cục bộ, hiển thị một API. Ví dụ, vLLM phục vụ mô hình với các tuyến đường tương thích với OpenAI, chỉ yêu cầu một lệnh duy nhất để bắt đầu.
Tuy nhiên, các nhà cung cấp dịch vụ đám mây giúp đơn giản hóa việc mở rộng quy mô. AWS, Azure và Vercel tích hợp GPT-OSS thông qua quan hệ đối tác với OpenAI. Các tùy chọn này tự động xử lý cân bằng tải và tự động mở rộng quy mô.
Ngoài ra, hãy đánh giá độ trễ. gpt-oss-20b phù hợp với các thiết bị biên có yêu cầu thấp hơn, trong khi gpt-oss-120b yêu cầu GPU như NVIDIA H100. Các nhà cung cấp tối ưu hóa cho phần cứng, đảm bảo hiệu suất nhất quán.
Tóm lại, nhà cung cấp phù hợp sẽ phù hợp với mục tiêu dự án. Sau khi đã chọn, hãy tiến hành lấy thông tin xác thực API.
Lấy quyền truy cập API và thiết lập môi trường của bạn
Các nhà phát triển bắt đầu bằng cách đăng ký trên trang web của nhà cung cấp. Đối với OpenRouter, truy cập openrouter.ai, tạo tài khoản và điều hướng đến phần Khóa (Keys). Tạo một khóa API mới, đặt tên để dễ tham chiếu và sao chép nó một cách an toàn.
Tiếp theo, cài đặt các thư viện client. Trong Python, sử dụng pip để thêm openai: pip install openai. Cấu hình client với URL cơ sở và khóa. Ví dụ:
from openai import OpenAI
client = OpenAI(
base_url="https://openrouter.ai/api/v1",
api_key="your_api_key_here"
)
Thiết lập này cho phép gửi yêu cầu đến các mô hình gpt-oss.
Hơn nữa, đối với Together AI, sử dụng SDK của họ: pip install together. Khởi tạo với:
import together
together.api_key = "your_together_api_key"
Kiểm tra kết nối bằng cách liệt kê các mô hình hoặc gửi một truy vấn đơn giản.
Tuy nhiên, hãy xác minh phần cứng nếu tự lưu trữ. Tải trọng số từ Hugging Face: huggingface-cli download openai/gpt-oss-120b. Sau đó, sử dụng vLLM để phục vụ: vllm serve openai/gpt-oss-120b.
Ngoài ra, đặt các biến môi trường để bảo mật. Lưu khóa trong các tệp .env và tải chúng bằng thư viện dotenv.
Trong trường hợp có vấn đề, hãy kiểm tra tài liệu của nhà cung cấp để biết giới hạn tốc độ hoặc lỗi xác thực. Việc chuẩn bị này đảm bảo tương tác API suôn sẻ.
Thực hiện cuộc gọi API đầu tiên của bạn tới GPT-OSS
Các nhà phát triển tạo các yêu cầu bằng cách sử dụng điểm cuối hoàn thành cuộc trò chuyện (chat completions). Chỉ định mô hình, chẳng hạn như "openai/gpt-oss-120b", trong tải trọng.
Đối với một cuộc gọi cơ bản, hãy chuẩn bị tin nhắn dưới dạng danh sách các từ điển. Mỗi tin nhắn bao gồm vai trò (hệ thống, người dùng, trợ lý) và nội dung.
Đây là một ví dụ trong Python:
completion = client.chat.completions.create(
model="openai/gpt-oss-120b",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain quantum superposition."}
],
max_tokens=200,
temperature=0.7
)
print(completion.choices[0].message.content)
Điều này tạo ra một phản hồi giải thích khái niệm một cách kỹ thuật.
Hơn nữa, điều chỉnh các tham số để kiểm soát. Nhiệt độ (Temperature) ảnh hưởng đến sự sáng tạo – giá trị thấp hơn tạo ra đầu ra xác định. Top_p giới hạn việc lấy mẫu token, trong khi presence_penalty ngăn chặn sự lặp lại.
Tiếp theo, tích hợp tính năng gọi công cụ. Định nghĩa các công cụ trong yêu cầu:
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string", "description": "The city and state, e.g. San Francisco, CA"},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]}
},
"required": ["location"]
}
}
}
]
completion = client.chat.completions.create(
model="openai/gpt-oss-120b",
messages=[{"role": "user", "content": "What's the weather like in Boston?"}],
tools=tools,
tool_choice="auto"
)
Mô hình phản hồi bằng một lệnh gọi công cụ, mà các nhà phát triển thực thi và đưa trở lại.
Tuy nhiên, hãy xử lý các phản hồi một cách cẩn thận. Phân tích cú pháp JSON để lấy nội dung, finish_reason và các số liệu thống kê sử dụng như số lượng token.
Ngoài ra, đối với chuỗi suy nghĩ (chain-of-thought), hãy nhắc với "Think step by step." Đặt mức độ nỗ lực suy luận trong tin nhắn hệ thống: "reasoning_effort: medium".
Thử nghiệm với gpt-oss-20b để kiểm thử nhanh hơn: Thay thế tên mô hình trong các cuộc gọi.
Trong các tình huống nâng cao, truyền phát phản hồi bằng cách sử dụng stream=True để có đầu ra thời gian thực.
Các bước này xây dựng các kỹ năng nền tảng. Bây giờ, hãy tích hợp các công cụ kiểm thử như Apidog.
Tích hợp Apidog để kiểm thử API GPT-OSS hiệu quả
Đầu tiên, cài đặt Apidog từ trang web của họ. Tạo một dự án mới và thêm một điểm cuối API, chẳng hạn như https://openrouter.ai/api/v1/chat/completions.
Tiếp theo, cấu hình các tiêu đề (headers): Thêm Authorization với token Bearer và Content-Type là application/json.
Hơn nữa, xây dựng phần thân yêu cầu (request body). Sử dụng trình chỉnh sửa JSON của Apidog để nhập mô hình, tin nhắn và các tham số. Ví dụ, kiểm thử một cuộc gọi gpt-oss để tạo mã.
Apidog trực quan hóa các phản hồi, làm nổi bật các lỗi hoặc thành công. Nó hỗ trợ các biến môi trường để chuyển đổi khóa API giữa các nhà cung cấp.
Tuy nhiên, hãy tận dụng các bộ sưu tập (collections) để tổ chức các bài kiểm thử. Nhóm các truy vấn GPT-OSS theo nhiệm vụ, như suy luận hoặc sử dụng công cụ, và chạy chúng theo lô.
Ngoài ra, Apidog tạo các đoạn mã trong các ngôn ngữ như Python hoặc cURL từ các yêu cầu của bạn, giúp tăng tốc quá trình phát triển.
Để cộng tác, chia sẻ dự án với các nhóm. Điều này đảm bảo kiểm thử nhất quán các tích hợp gpt-oss.
Trong thực tế, sử dụng Apidog để giám sát việc sử dụng token và tối ưu hóa các lời nhắc (prompts), giúp giảm chi phí.
Nhìn chung, Apidog nâng cao năng suất khi làm việc với API GPT-OSS.
Sử dụng nâng cao: Tinh chỉnh và triển khai
Các nhà phát triển tinh chỉnh GPT-OSS cho các lĩnh vực cụ thể. Sử dụng thư viện transformers của Hugging Face để tải trọng số và đào tạo trên các bộ dữ liệu tùy chỉnh.
Ví dụ, chuẩn bị dữ liệu ở định dạng JSONL với các cặp prompt-completion. Chạy các tập lệnh tinh chỉnh từ kho lưu trữ GitHub.
Hơn nữa, triển khai các mô hình đã tinh chỉnh thông qua vLLM để phục vụ API. Điều này hỗ trợ tải sản xuất với các tính năng như batching động.
Tiếp theo, khám phá các tiện ích mở rộng đa phương thức. Mặc dù tập trung vào văn bản, hãy tích hợp với các mô hình thị giác cho các ứng dụng lai.
Tuy nhiên, hãy theo dõi tình trạng overfitting trong quá trình tinh chỉnh. Sử dụng tập hợp xác thực và dừng sớm.
Ngoài ra, mở rộng quy mô với suy luận phân tán trên các cụm. Các nhà cung cấp như AWS cung cấp các tùy chọn được quản lý.
Trong các thiết lập tác nhân, chuỗi GPT-OSS với các API bên ngoài cho các quy trình làm việc như nghiên cứu tự động.
Các kỹ thuật này mở rộng khả năng vượt ra ngoài các cuộc gọi cơ bản.
Các phương pháp hay nhất, hạn chế và khắc phục sự cố
Các nhà phát triển tuân theo các phương pháp hay nhất để đạt được kết quả tối ưu. Tạo các lời nhắc rõ ràng, sử dụng các ví dụ ít shot (few-shot examples) và lặp lại dựa trên đầu ra.
Hơn nữa, hãy tôn trọng giới hạn tốc độ – kiểm tra bảng điều khiển của nhà cung cấp để tránh bị điều tiết.
Tuy nhiên, hãy thừa nhận các hạn chế: GPT-OSS có thể bị ảo giác, vì vậy hãy xác thực các phản hồi quan trọng. Nó thiếu các cập nhật kiến thức thời gian thực.
Ngoài ra, bảo mật khóa API và ghi nhật ký sử dụng để kiểm soát chi phí.
Khắc phục sự cố bằng cách xem xét các mã lỗi; 401 cho biết xác thực không hợp lệ, 429 có nghĩa là đạt giới hạn tốc độ.
Tóm lại, hãy tuân thủ các hướng dẫn này để có hiệu suất đáng tin cậy.
Kết luận: Nâng cao dự án của bạn với API GPT-OSS
Các nhà phát triển giờ đây đã có trong tay các công cụ để tích hợp GPT-OSS một cách hiệu quả. Từ thiết lập đến các tính năng nâng cao, hướng dẫn này trang bị cho bạn để thành công. Hãy thử nghiệm, tinh chỉnh và đổi mới với gpt-oss và Apidog để tạo ra các giải pháp AI có tác động.