
Chào các tín đồ AI! Hãy sẵn sàng vì Open AI vừa tung ra một tin chấn động với mô hình mã nguồn mở mới của họ, GPT-OSS-120B, và nó đang thu hút sự chú ý trong cộng đồng AI. Được phát hành theo giấy phép Apache 2.0, cỗ máy mạnh mẽ này được thiết kế cho các tác vụ suy luận, lập trình và tác nhân, tất cả đều chạy trên một GPU duy nhất. Trong hướng dẫn này, chúng ta sẽ đi sâu vào những gì làm nên sự đặc biệt của GPT-OSS-120B, các điểm chuẩn xuất sắc, giá cả phải chăng và cách bạn có thể sử dụng nó thông qua API OpenRouter. Hãy cùng khám phá viên ngọc quý mã nguồn mở này và bắt đầu lập trình với nó ngay lập tức!
Bạn muốn một nền tảng tích hợp, tất cả trong một để Nhóm Phát triển của bạn làm việc cùng nhau với năng suất tối đa?
Apidog đáp ứng mọi yêu cầu của bạn và thay thế Postman với mức giá phải chăng hơn nhiều!
GPT-OSS-120B là gì?
GPT-OSS-120B của Open AI là một mô hình ngôn ngữ 117 tỷ tham số (với 5,1 tỷ tham số hoạt động trên mỗi token) thuộc dòng GPT-OSS mã nguồn mở mới của họ, cùng với GPT-OSS-20B nhỏ hơn. Được phát hành vào ngày 5 tháng 8 năm 2025, đây là một mô hình Mixture-of-Experts (MoE) được tối ưu hóa cho hiệu quả, chạy trên một GPU NVIDIA H100 duy nhất hoặc thậm chí trên phần cứng tiêu dùng với lượng tử hóa MXFP4. Nó được xây dựng cho các tác vụ như suy luận phức tạp, tạo mã và sử dụng công cụ, với cửa sổ ngữ cảnh token khổng lồ 128K — tương đương 300–400 trang văn bản! Theo giấy phép Apache 2.0, bạn có thể tùy chỉnh, triển khai hoặc thậm chí thương mại hóa nó, biến nó thành giấc mơ cho các nhà phát triển và doanh nghiệp khao khát sự kiểm soát và quyền riêng tư.

Điểm chuẩn: GPT-OSS-120B hoạt động như thế nào?
GPT-OSS-120B không hề kém cạnh về hiệu suất. Các điểm chuẩn của Open AI cho thấy nó là một đối thủ đáng gờm so với các mô hình độc quyền như o4-mini của chính họ và thậm chí cả Claude 3.5 Sonnet. Dưới đây là thông tin chi tiết:
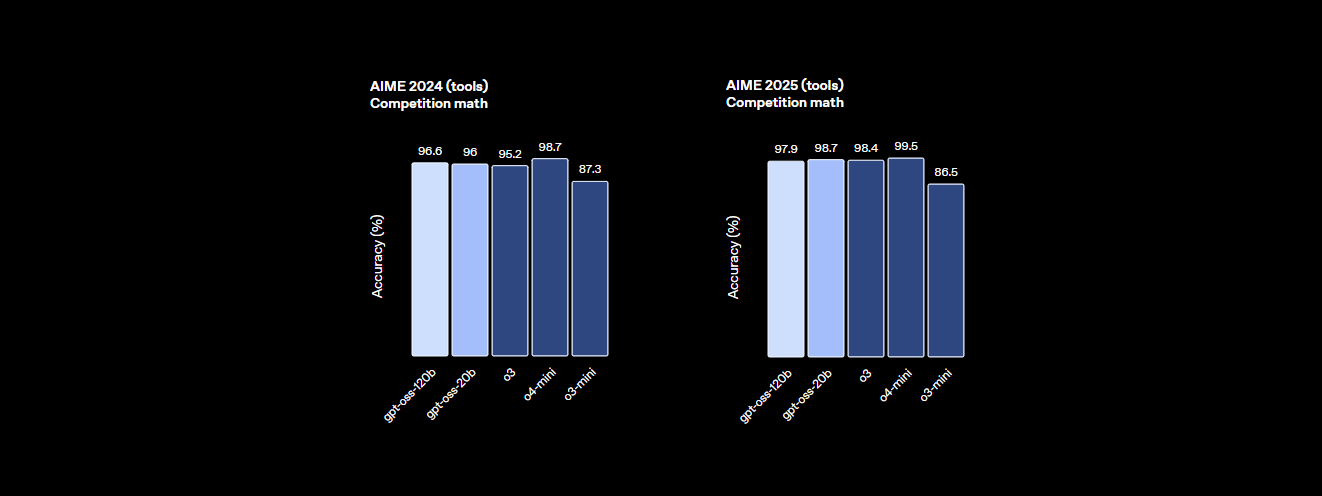
- Khả năng suy luận: Nó đạt 94,2% trên MMLU (Hiểu ngôn ngữ đa tác vụ lớn), chỉ kém 95,1% của GPT-4, và đạt 96,6% trong các cuộc thi toán AIME, vượt trội hơn nhiều mô hình đóng.
- Năng lực lập trình: Trên Codeforces, nó tự hào có xếp hạng Elo 2622, và đạt tỷ lệ vượt qua 87,3% trên HumanEval để tạo mã, biến nó thành người bạn tốt nhất của lập trình viên.
- Sức khỏe và Sử dụng công cụ: Nó vượt qua o4-mini trên HealthBench cho các truy vấn liên quan đến sức khỏe và xuất sắc trong các tác vụ tác nhân như TauBench, nhờ khả năng suy luận chuỗi tư duy (CoT) và gọi công cụ của nó.
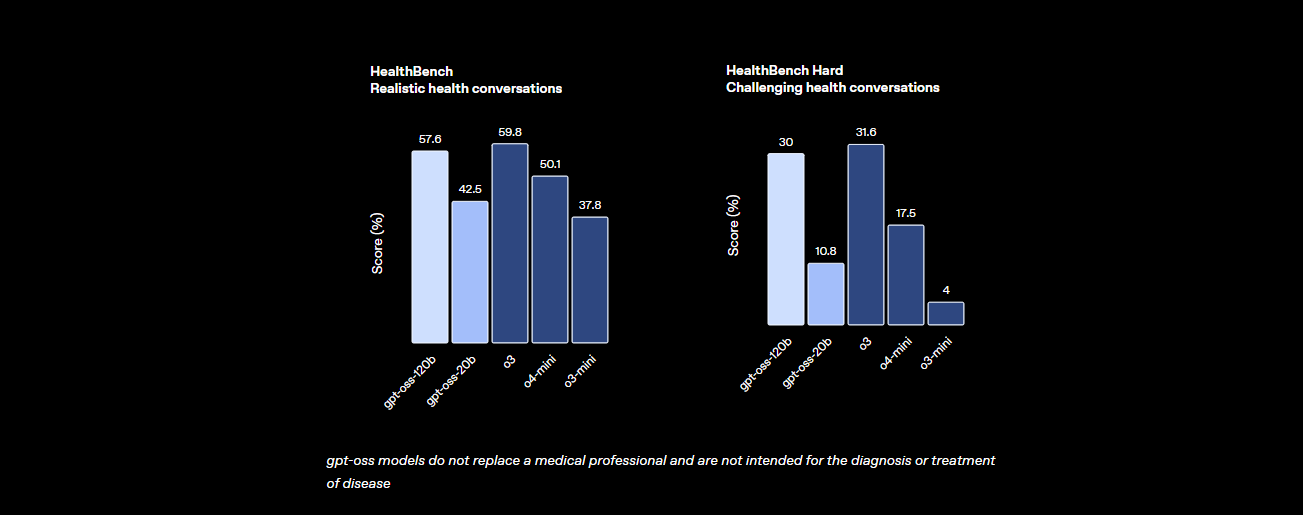
- Tốc độ: Trên GPU H100, nó xử lý 45 token mỗi giây, với các nhà cung cấp như Cerebras đạt tới 3.000 token/giây cho các nhu cầu khối lượng lớn. OpenRouter cung cấp ~500 token/giây, vượt trội hơn nhiều mô hình đóng.
Những số liệu thống kê này cho thấy GPT-OSS-120B gần như ngang bằng với các mô hình độc quyền hàng đầu trong khi vẫn là mã nguồn mở và có thể tùy chỉnh. Nó là một con quái vật trong toán học, lập trình và giải quyết vấn đề nói chung, với tính an toàn được tích hợp thông qua việc tinh chỉnh đối kháng để giữ rủi ro ở mức thấp.
Giá cả: Phải chăng và minh bạch
Một trong những điểm tốt nhất của GPT-OSS-120B? Nó tiết kiệm chi phí, đặc biệt so với các mô hình độc quyền. Dưới đây là cách nó được phân chia giữa các nhà cung cấp lớn, dựa trên dữ liệu gần đây cho cửa sổ ngữ cảnh 131K:
- Triển khai cục bộ: Chạy nó trên phần cứng của riêng bạn (ví dụ: GPU H100 hoặc thiết lập VRAM 80GB) mà không tốn chi phí API. Một thiết lập GMKTEC EVO-X2 có giá khoảng €2000 và sử dụng dưới 200W, hoàn hảo cho các công ty nhỏ ưu tiên quyền riêng tư.
- Baseten: $0,10/M token đầu vào, $0,50/M token đầu ra. Độ trễ: 0,20s, Thông lượng: 491,1 token/giây. Đầu ra tối đa: 131K token.
- Fireworks: $0,15/M đầu vào, $0,60/M đầu ra. Độ trễ: 0,56s, Thông lượng: 258,9 token/giây. Đầu ra tối đa: 33K token.
- Together: $0,15/M đầu vào, $0,60/M đầu ra. Độ trễ: 0,28s, Thông lượng: 131,1 token/giây. Đầu ra tối đa: 131K token.
- Parasail: $0,15/M đầu vào, $0,60/M đầu ra (lượng tử hóa FP4). Độ trễ: 0,40s, Thông lượng: 94,3 token/giây. Đầu ra tối đa: 131K token.
- Groq: $0,15/M đầu vào, $0,75/M đầu ra. Độ trễ: 0,24s, Thông lượng: 1.065 token/giây. Đầu ra tối đa: 33K token.
- Cerebras: $0,25/M đầu vào, $0,69/M đầu ra. Độ trễ: 0,42s, Thông lượng: 1.515 token/giây. Đầu ra tối đa: 33K token. Lý tưởng cho các nhu cầu tốc độ cao, đạt tới 3.000 token/giây trong một số thiết lập.
Với GPT-OSS-120B, bạn có được hiệu suất cao với một phần nhỏ chi phí của GPT-4 (khoảng $20,00/M token), với các nhà cung cấp như Groq và Cerebras cung cấp thông lượng cực nhanh cho các ứng dụng thời gian thực.
Cách sử dụng GPT-OSS-120B với Cline qua OpenRouter
Bạn muốn khai thác sức mạnh của GPT-OSS-120B cho các dự án lập trình của mình? Mặc dù Claude Desktop và Claude Code không hỗ trợ tích hợp trực tiếp với các mô hình OpenAI như GPT-OSS-120B do chúng phụ thuộc vào hệ sinh thái của Anthropic, bạn có thể dễ dàng sử dụng mô hình này với Cline, một tiện ích mở rộng VS Code miễn phí, mã nguồn mở, thông qua API OpenRouter. Ngoài ra, Cursor gần đây đã hạn chế tùy chọn Mang Khóa Riêng Của Bạn (BYOK) cho người dùng không phải Pro, khóa các tính năng như chế độ Agent và Edit đằng sau gói đăng ký $20/tháng, khiến Cline trở thành một lựa chọn thay thế linh hoạt hơn cho người dùng BYOK. Dưới đây là cách thiết lập GPT-OSS-120B với Cline và OpenRouter, từng bước một.
Bước 1: Lấy Khóa API OpenRouter
- Đăng ký với OpenRouter:
- Truy cập openrouter.ai và tạo một tài khoản miễn phí bằng Google hoặc GitHub.
2. Tìm GPT-OSS-120B:
- Trong tab Mô hình, tìm kiếm “gpt-oss-120b” và chọn nó.
3. Tạo Khóa API:
- Đi tới phần Khóa, nhấp vào Tạo Khóa API, đặt tên cho nó (ví dụ: “GPT-OSS-Cursor”), và sao chép nó. Lưu trữ nó một cách an toàn
Bước 2: Sử dụng Cline trong VS Code với BYOK
Để truy cập BYOK không hạn chế, Cline (một tiện ích mở rộng VS Code mã nguồn mở) là một lựa chọn thay thế Cursor tuyệt vời. Nó hỗ trợ GPT-OSS-120B thông qua OpenRouter mà không bị khóa tính năng. Dưới đây là cách thiết lập:
- Cài đặt Cline:
- Mở VS Code (code.visualstudio.com).
- Đi tới bảng Tiện ích mở rộng (
Ctrl+Shift+XhoặcCmd+Shift+X). - Tìm kiếm “Cline” và cài đặt nó (bởi nickbaumann98, github.com/cline/cline).
2. Cấu hình OpenRouter:
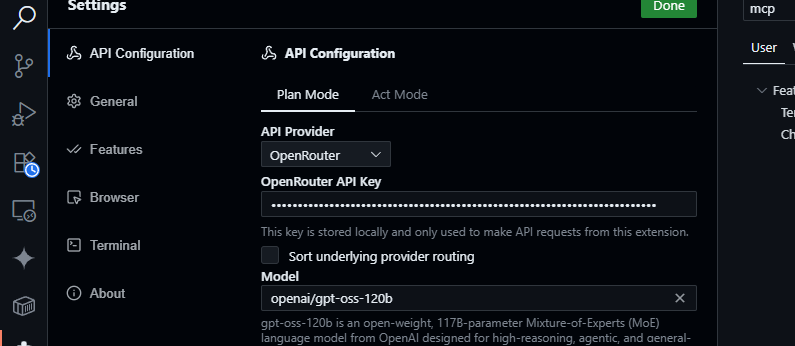
- Mở bảng Cline (nhấp vào biểu tượng Cline trong Thanh Hoạt động).
- Nhấp vào biểu tượng bánh răng trong bảng Cline.
- Chọn OpenRouter làm nhà cung cấp.
- Dán khóa API OpenRouter của bạn.
- Chọn
openai/gpt-oss-120blàm mô hình.
3. Lưu và Kiểm tra:
- Lưu cài đặt. Trong bảng trò chuyện Cline, hãy thử:
Tạo một hàm JavaScript để phân tích cú pháp dữ liệu JSON.
- Mong đợi một phản hồi như:
function parseJSON(data) {
try {
return JSON.parse(data);
} catch (e) {
console.error("Invalid JSON:", e.message);
return null;
}
}
- Kiểm tra các truy vấn cơ sở mã:
Tóm tắt src/api/server.js
- Cline sẽ phân tích dự án của bạn và trả về một bản tóm tắt, tận dụng cửa sổ ngữ cảnh 128K của GPT-OSS-120B.
Tại sao nên chọn Cline thay vì Cursor hoặc Claude?
- Không tích hợp Claude: Claude Desktop và Claude Code bị khóa với các mô hình của Anthropic (ví dụ: Claude 3.5 Sonnet) và không hỗ trợ các mô hình OpenAI như GPT-OSS-120B do các hạn chế về hệ sinh thái.
- Hạn chế BYOK của Cursor: Lệnh cấm BYOK gần đây của Cursor đối với người dùng không phải Pro có nghĩa là bạn không thể truy cập các chế độ Agent hoặc Edit nếu không có gói đăng ký $20/tháng, ngay cả khi có khóa API OpenRouter hợp lệ. Cline không có giới hạn nào như vậy, cung cấp quyền truy cập đầy đủ tính năng miễn phí với khóa API của bạn.
- Quyền riêng tư và Kiểm soát: Cline gửi yêu cầu trực tiếp đến OpenRouter, bỏ qua các máy chủ bên thứ ba (không giống như định tuyến AWS của Cursor), tăng cường quyền riêng tư.
Mẹo khắc phục sự cố
- Khóa API không hợp lệ? Xác minh khóa của bạn trong bảng điều khiển của OpenRouter và đảm bảo nó đang hoạt động.
- Mô hình không khả dụng? Kiểm tra danh sách mô hình của OpenRouter cho openai/gpt-oss-120b. Nếu thiếu, hãy thử các nhà cung cấp như Fireworks AI hoặc liên hệ với bộ phận hỗ trợ của OpenRouter.
- Phản hồi chậm? Đảm bảo internet của bạn ổn định. Để có hiệu suất nhanh hơn, hãy xem xét các mô hình nhẹ hơn như GPT-OSS-20B.
- Lỗi Cline? Cập nhật Cline qua bảng Tiện ích mở rộng và kiểm tra nhật ký trong bảng Output của VS Code.
Tại sao nên sử dụng GPT-OSS-120B?
Mô hình GPT-OSS-120B là một yếu tố thay đổi cuộc chơi cho các nhà phát triển và doanh nghiệp, mang đến sự kết hợp hấp dẫn giữa hiệu suất, tính linh hoạt và hiệu quả chi phí. Dưới đây là lý do tại sao nó nổi bật:
- Tự do mã nguồn mở: Được cấp phép theo Apache 2.0, bạn có thể tinh chỉnh, triển khai hoặc thương mại hóa GPT-OSS-120B mà không bị hạn chế, mang lại cho bạn toàn quyền kiểm soát các quy trình làm việc AI của mình.
- Tiết kiệm chi phí: Chạy nó cục bộ trên một GPU H100 duy nhất hoặc phần cứng tiêu dùng (VRAM 80GB) mà không tốn chi phí API. Qua OpenRouter, giá cả rất cạnh tranh ở mức khoảng $0,50/M token đầu vào và khoảng $2,00/M token đầu ra, chỉ bằng một phần nhỏ chi phí của GPT-4 (khoảng $20,00/M token), mang lại khoản tiết kiệm lên tới 90% cho người dùng nặng. Các nhà cung cấp khác như Groq ($0,15/M đầu vào, $0,75/M đầu ra) và Cerebras ($0,25/M đầu vào, $0,69/M đầu ra) cũng giữ chi phí thấp.
- Hiệu suất: Nó đạt gần như ngang bằng với o4-mini của OpenAI, đạt 94,2% trên MMLU, 96,6% trên toán AIME và 87,3% trên HumanEval cho lập trình. Cửa sổ ngữ cảnh 128K token của nó (300–400 trang) xử lý các cơ sở mã hoặc tài liệu lớn một cách dễ dàng.
- Suy luận chuỗi tư duy (CoT): Tính minh bạch CoT đầy đủ của mô hình cho phép bạn xem quá trình suy luận từng bước của nó, giúp dễ dàng gỡ lỗi đầu ra và phát hiện các sai lệch hoặc lỗi. Bạn có thể điều chỉnh mức độ nỗ lực suy luận (thấp, trung bình, cao) thông qua các lời nhắc hệ thống (ví dụ: “Reasoning: high”) cho các tác vụ như toán học phức tạp hoặc lập trình, cân bằng tốc độ và chiều sâu. Thiết kế CoT không giám sát này hỗ trợ các nhà nghiên cứu trong việc giám sát hành vi của mô hình mà không cần giám sát trực tiếp, nâng cao niềm tin và sự an toàn.
- Khả năng tác nhân: Hỗ trợ gốc cho việc sử dụng công cụ, như duyệt web và thực thi mã Python, làm cho nó lý tưởng cho các quy trình làm việc tác nhân. Nó có thể xâu chuỗi nhiều lệnh gọi công cụ (ví dụ: 28 tìm kiếm web liên tiếp trong một bản demo) cho các tác vụ phức tạp như tổng hợp dữ liệu hoặc tự động hóa.
- Quyền riêng tư: Lưu trữ nó tại chỗ (ví dụ: qua Dell Enterprise Hub) để kiểm soát dữ liệu hoàn toàn, hoàn hảo cho các doanh nghiệp hoặc người dùng quan tâm đến quyền riêng tư.
- Tính linh hoạt: Tương thích với OpenRouter, Fireworks AI, Cerebras và các thiết lập cục bộ như Ollama hoặc LM Studio, nó chạy trên nhiều phần cứng khác nhau, từ GPU RTX đến Apple Silicon.
Sự bàn tán trong cộng đồng trên X làm nổi bật tốc độ của nó (lên tới 1.515 token/giây trên Cerebras) và năng lực lập trình, với các nhà phát triển yêu thích khả năng xử lý các dự án đa tệp và tính chất mã nguồn mở của nó để tùy chỉnh. Cho dù bạn đang xây dựng các tác nhân AI hay tinh chỉnh cho các tác vụ chuyên biệt, GPT-OSS-120B mang lại giá trị vô song.
Kết luận
GPT-OSS-120B của Open AI là một mô hình mã nguồn mở mang tính cách mạng, kết hợp hiệu suất hàng đầu với việc triển khai hiệu quả về chi phí. Các điểm chuẩn của nó cạnh tranh với các mô hình độc quyền, giá cả phải chăng và dễ dàng tích hợp với Cursor hoặc Cline thông qua API của OpenRouter. Cho dù bạn đang lập trình, gỡ lỗi hay suy luận các vấn đề phức tạp, mô hình này đều mang lại hiệu quả. Hãy dùng thử, thử nghiệm với cửa sổ ngữ cảnh 128K của nó và cho chúng tôi biết các trường hợp sử dụng thú vị của bạn trong phần bình luận — tôi rất muốn nghe!
Để biết thêm chi tiết, hãy xem kho lưu trữ tại github.com/openai/gpt-oss hoặc thông báo của Open AI tại openai.com.
Bạn muốn một nền tảng tích hợp, tất cả trong một để Nhóm Phát triển của bạn làm việc cùng nhau với năng suất tối đa?
Apidog đáp ứng mọi yêu cầu của bạn và thay thế Postman với mức giá phải chăng hơn nhiều!