
Các kỹ sư và nhà phát triển luôn tìm kiếm các mô hình hiệu quả mang lại hiệu suất cao mà không đòi hỏi tài nguyên quá mức. GLM-4.7-Flash nổi lên như một lựa chọn hấp dẫn trong bối cảnh này. Mô hình Mixture-of-Experts (MoE) 30B-A3B này, được phát triển bởi Zhipu AI (Z.ai), nổi bật nhờ sự cân bằng giữa sức mạnh và hiệu quả. Nó vượt trội trong các tiêu chuẩn mã hóa, tác vụ suy luận và tích hợp công cụ, khiến nó phù hợp cho các kịch bản triển khai cục bộ.
Chạy GLM-4.7-Flash cục bộ trao quyền cho người dùng duy trì quyền riêng tư dữ liệu, giảm độ trễ và tùy chỉnh tích hợp. Các công cụ như Ollama, LM Studio và Hugging Face đơn giản hóa quá trình này.
Khi bạn tiếp tục với hướng dẫn này, bạn sẽ có được những hiểu biết thực tế về cách cài đặt và sử dụng. Đầu tiên, hãy xem xét các yêu cầu nền tảng của hệ thống.
GLM-4.7-Flash là gì và tại sao nên sử dụng cục bộ?
GLM-4.7-Flash đại diện cho một bước tiến trong các mô hình ngôn ngữ mã nguồn mở. Được xây dựng trên kiến trúc glm4_moe_lite, nó sử dụng các kiểu tensor BF16 và F32 theo giấy phép MIT. Bài báo của mô hình, "GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models," trình bày chi tiết quá trình huấn luyện của nó để sử dụng công cụ và suy luận, dựa trên arXiv:2508.06471.
Các tính năng chính bao gồm hỗ trợ tiếng Anh và tiếng Trung, tạo văn bản và các tác vụ hội thoại. Nó xử lý các đầu vào đa phương thức dưới dạng văn bản nhưng chỉ tập trung vào đầu ra văn bản. Những hạn chế phát sinh từ quy mô của nó—mặc dù hiệu quả, nhưng nó có thể không sánh kịp với các mô hình lớn hơn trong các lĩnh vực chuyên biệt nếu không được tinh chỉnh. Chi tiết dữ liệu huấn luyện vẫn chưa được tiết lộ, nhưng các đánh giá xác nhận lợi thế của nó trong các kịch bản mã hóa và tác nhân.
Người dùng chọn chạy cục bộ để tránh chi phí API. Z.ai cung cấp một bậc miễn phí cho GLM-4.7-Flash thông qua nền tảng của họ, nhưng việc triển khai cục bộ loại bỏ sự phụ thuộc vào các dịch vụ bên ngoài. Cách tiếp cận này phù hợp với các nhà phát triển xây dựng ứng dụng tùy chỉnh, các nhà nghiên cứu thử nghiệm giả thuyết hoặc các doanh nghiệp ưu tiên bảo mật. Ví dụ, bạn kiểm soát mức lượng tử hóa để phù hợp với các hạn chế phần cứng, đảm bảo hiệu suất tối ưu.
Yêu cầu hệ thống để chạy GLM-4.7-Flash cục bộ
Phần cứng đóng một vai trò quan trọng trong suy luận mô hình. GLM-4.7-Flash yêu cầu ít nhất 16 GB bộ nhớ hệ thống cho các hoạt động cơ bản, theo hướng dẫn của LM Studio. Tuy nhiên, tăng tốc GPU giúp tăng tốc độ đáng kể.
Đối với các biến thể Ollama:
- q4_K_M: 19 GB VRAM
- q8_0: 32 GB VRAM
- bf16: 60 GB VRAM
Hugging Face khuyến nghị sử dụng torch.bfloat16 để đạt hiệu quả, yêu cầu GPU NVIDIA tương thích (kiến trúc Ampere hoặc mới hơn). Suy luận chỉ dùng CPU vẫn hoạt động nhưng chậm lại đáng kể đối với các ngữ cảnh lớn.
Các điều kiện tiên quyết về phần mềm bao gồm Python 3.8+, pip và Git. Các framework như Transformers đòi hỏi cài đặt bổ sung. Đảm bảo hệ điều hành của bạn hỗ trợ CUDA để sử dụng GPU—Ubuntu 20.04 hoặc Windows với WSL2 hoạt động tốt.
Nếu tài nguyên không đủ, lượng tử hóa sẽ giảm mức sử dụng bộ nhớ. Các công cụ như llama.cpp hoặc Unsloth cung cấp các phiên bản 4-bit hoặc 2-bit, giảm yêu cầu xuống 15-20 GB VRAM. Tính linh hoạt này cho phép triển khai trên phần cứng tiêu dùng như RTX 4090.
Với các yêu cầu đã được đáp ứng, hãy khám phá các phương pháp cài đặt. Bắt đầu với Ollama vì sự đơn giản của nó.
Cách cài đặt và sử dụng GLM-4.7-Flash với Ollama
Ollama cung cấp một nền tảng dễ tiếp cận để chạy các mô hình lớn cục bộ. Nó tự động quản lý lượng tử hóa và phục vụ API.
Đầu tiên, cài đặt Ollama. Tải xuống tệp thực thi cho hệ điều hành của bạn và chạy nó.

Xác minh cài đặt bằng ollama --version, đảm bảo phiên bản 0.14.3 trở lên, vì GLM-4.7-Flash yêu cầu điều này.

Tiếp theo, kéo mô hình: thực thi ollama pull glm-4.7-flash.

Chọn các biến thể như glm-4.7-flash:q4_K_M để sử dụng bộ nhớ thấp hơn. Lệnh này tải xuống khoảng 19 GB cho phiên bản q4.
Chạy mô hình một cách tương tác: gõ ollama run glm-4.7-flash. Nhập các câu lệnh như "Generate Python code for a Fibonacci sequence." (Tạo mã Python cho dãy Fibonacci.) Mô hình phản hồi bằng các đầu ra có lý lẽ, tận dụng sức mạnh mã hóa của nó.
Để truy cập bằng chương trình, hãy sử dụng API. Gửi yêu cầu curl:
curl http://localhost:11434/api/chat -d '{
"model": "glm-4.7-flash",
"messages": [{"role": "user", "content": "Explain quantum computing basics."}]
}'
Điều này trả về JSON với phản hồi. Trong Python, tích hợp với thư viện ollama:
from ollama import chat
response = chat(
model='glm-4.7-flash',
messages=[{'role': 'user', 'content': 'Solve this math problem: 2x + 3 = 7'}]
)
print(response['message']['content'])
JavaScript cũng tương tự với gói npm ollama.
Tùy chỉnh cấu hình bằng cách chỉnh sửa Modelfile. Đặt `temperature` thành 0.7 cho đầu ra xác định trong các tác vụ mã hóa. Chế độ mới nhất của Ollama tìm nạp các bài đăng gần đây nếu cần, nhưng ở đây chúng ta tập trung vào suy luận cục bộ.
Phương pháp này phù hợp cho các thiết lập nhanh chóng. Tuy nhiên, đối với giao diện đồ họa, hãy chuyển sang LM Studio.
Thiết lập GLM-4.7-Flash trong LM Studio
LM Studio cung cấp giao diện đồ họa người dùng (GUI) thân thiện để quản lý mô hình. Tải xuống và cài đặt.
Tìm kiếm "zai-org/glm-4.7-flash" trong trung tâm mô hình. Chọn một phiên bản lượng tử hóa—MLX-4bit, 6bit, hoặc 8bit—từ các kho Hugging Face liên kết. Quá trình tải xuống hoàn tất trong ứng dụng.
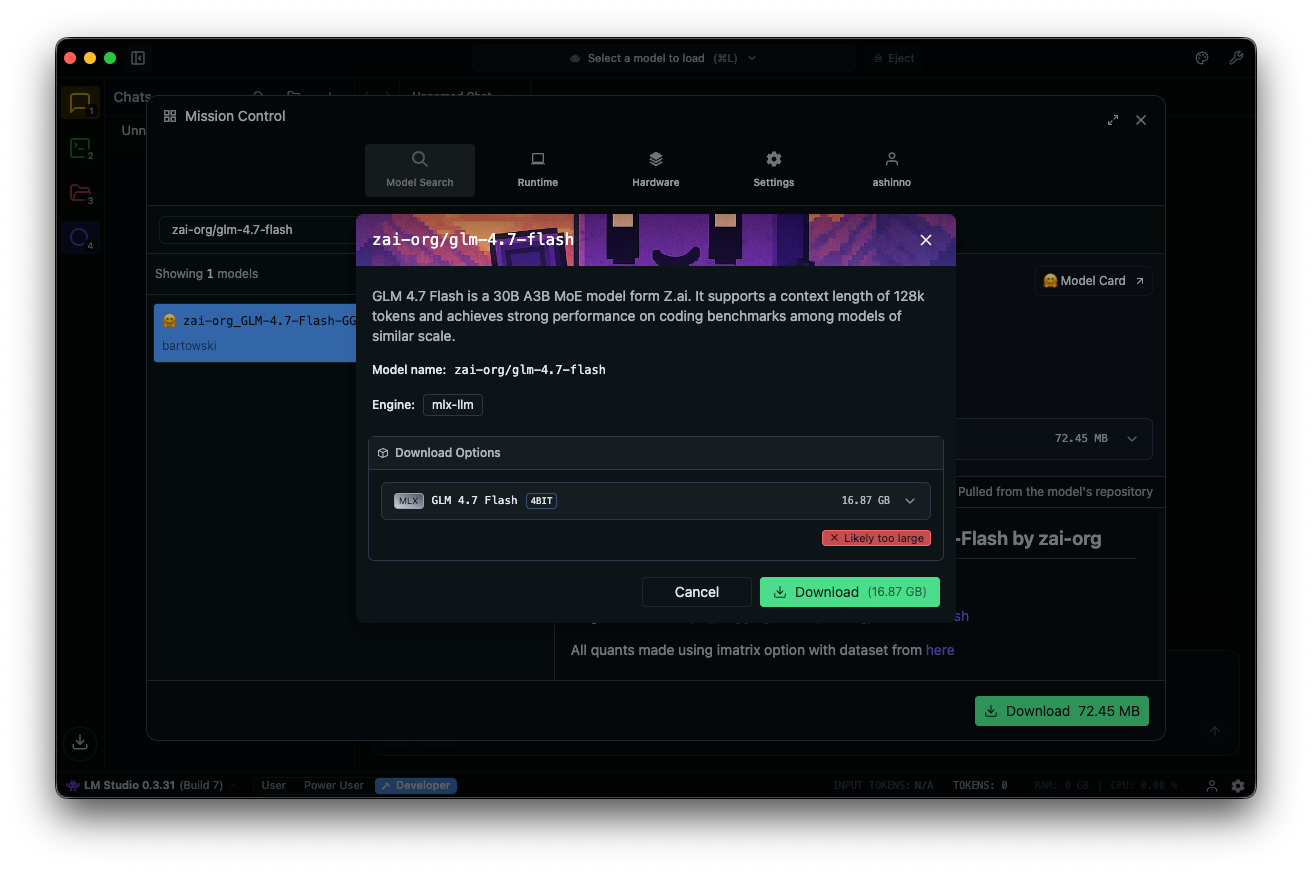
Tải mô hình: điều hướng đến giao diện trò chuyện, chọn GLM-4.7-Flash và điều chỉnh các thông số. Bật tư duy (mặc định: true) để suy luận từng bước. Đặt `temperature` thành 1, `top_k` thành 50, `top_p` thành 0.95 và tắt `repeat penalty`.
Thử nghiệm với các câu lệnh: "Design a REST API for user authentication." (Thiết kế một REST API cho xác thực người dùng.) LM Studio hiển thị đầu ra với tốc độ token, hỗ trợ tinh chỉnh hiệu suất.
Các trường tùy chỉnh như `clear_thinking` (mặc định: false) quản lý lịch sử. Đối với các mô hình MoE, hãy theo dõi các chuyên gia đang hoạt động—A3B có nghĩa là ba chuyên gia hoạt động mỗi lần truyền tiến, tối ưu hóa hiệu quả.
LM Studio hỗ trợ các liên kết sâu để truy cập trực tiếp mô hình. Nếu có vấn đề phát sinh, hãy kiểm tra bộ nhớ hệ thống—tối thiểu 16 GB sẽ ngăn chặn sự cố.
Công cụ này rất xuất sắc cho việc thử nghiệm. Để viết script nâng cao, hãy tích hợp với Hugging Face.
Sử dụng GLM-4.7-Flash với Hugging Face Transformers
Hugging Face cung cấp các thư viện mạnh mẽ để kiểm soát chi tiết. Cài đặt Transformers từ nhánh chính:
pip install git+https://github.com/huggingface/transformers.git
Tải mô hình:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
MODEL_PATH = "zai-org/GLM-4.7-Flash"
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH)
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
torch_dtype=torch.bfloat16,
device_map="auto"
)
Chuẩn bị đầu vào:
messages = [{"role": "user", "content": "Write a function to sort an array."}]
inputs = tokenizer.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
)
inputs = inputs.to(model.device)
Tạo:
generated_ids = model.generate(**inputs, max_new_tokens=512, do_sample=False)
output = tokenizer.decode(generated_ids[0][inputs['input_ids'].shape[1]:])
print(output)
Thiết lập này hỗ trợ lượng tử hóa thông qua bitsandbytes để giảm VRAM. Thêm `load_in_4bit=True` khi tải mô hình.
Để phục vụ, hãy sử dụng vLLM hoặc SGLang. Cài đặt vLLM:
pip install -U vllm --pre --index-url https://pypi.org/simple --extra-index-url https://wheels.vllm.ai/nightly
Chạy một máy chủ:
python -m vllm.entrypoints.openai.api_server --model zai-org/GLM-4.7-Flash
Truy cập thông qua các điểm cuối tương thích OpenAI. SGLang yêu cầu cài đặt từ mã nguồn và thực hiện các bước tương tự.
Các framework này cho phép triển khai cấp độ sản xuất. Bây giờ, hãy xem xét thử nghiệm API với Apidog.
Tích hợp Apidog để kiểm thử API với GLM-4.7-Flash cục bộ
Khi bạn đã triển khai GLM-4.7-Flash thông qua Ollama hoặc vLLM, hãy kiểm tra các điểm cuối một cách hiệu quả. Apidog, một nền tảng API tất cả trong một, tạo điều kiện thuận lợi cho việc này.
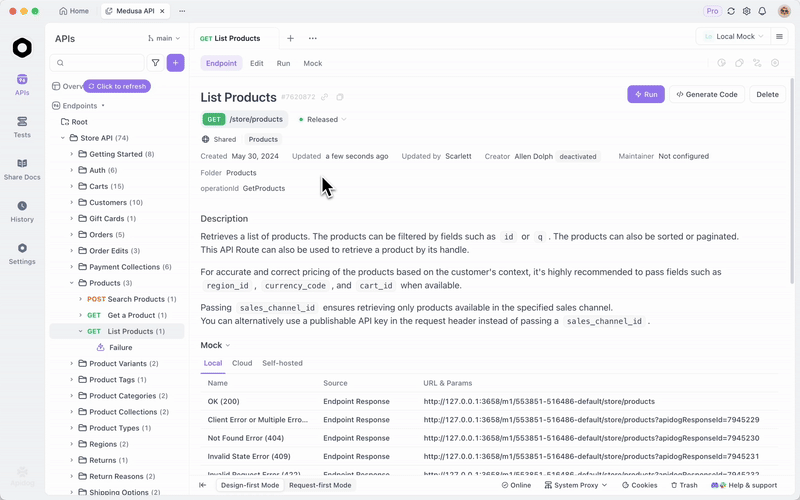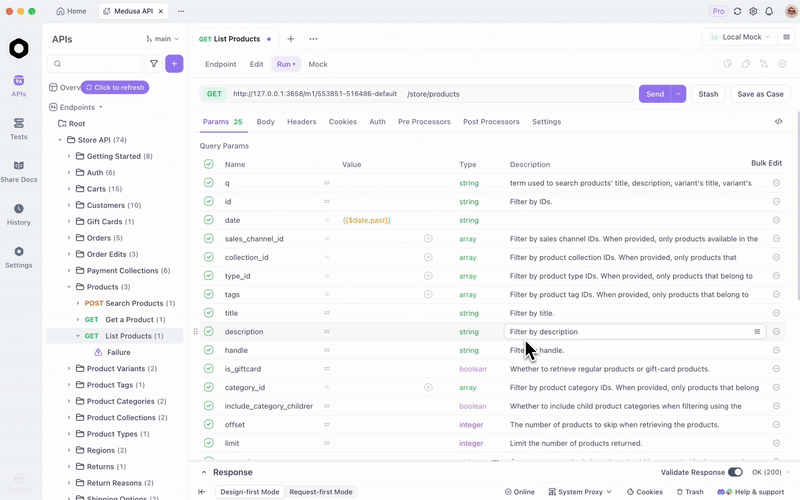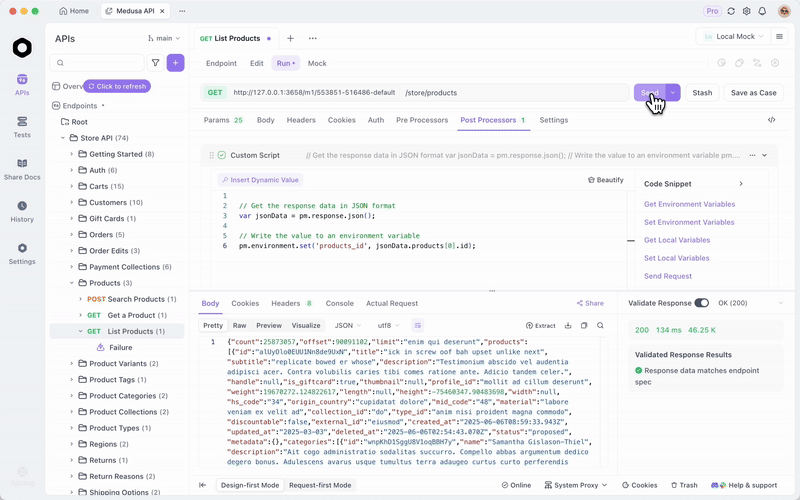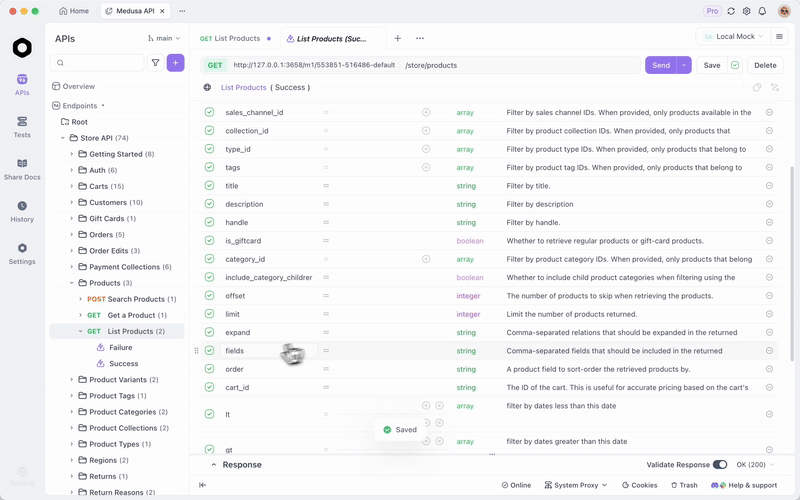
Tải Apidog miễn phí. Nó hỗ trợ các tính năng AI bằng cách cấu hình mô hình cục bộ của bạn làm nhà cung cấp—sử dụng khóa API nếu có thể, hoặc các điểm cuối trực tiếp.
MCP Server của Apidog tích hợp với các IDE như Cursor, sử dụng các đặc tả API để tạo mã. Điều này liên kết trở lại với khả năng mã hóa của GLM-4.7-Flash—kiểm tra trực tiếp các đầu ra tác nhân.
Ví dụ, truy vấn máy chủ cục bộ của bạn và xác thực các phản hồi. Điều này đảm bảo độ tin cậy trong các ứng dụng.
Xây dựng trên những điều cơ bản, hãy tiến tới tối ưu hóa.
Mẹo nâng cao để tối ưu hóa hiệu suất GLM-4.7-Flash
Tinh chỉnh các thông số cho từng tác vụ. Đặt `temperature` thành 0.7 cho mã hóa, 1.0 cho viết sáng tạo. Sử dụng `top_p` 0.95 để cân bằng sự đa dạng.
Lượng tử hóa thêm với định dạng GGUF thông qua llama.cpp. Biên dịch llama.cpp với CUDA, sau đó chuyển đổi:
./llama-gguf-split --model GLM-4.7-Flash.gguf
Chạy với `--jinja` để hỗ trợ mẫu.
Xử lý ngữ cảnh dài: Chia nhỏ đầu vào nếu vượt quá 128K. Bật tư duy cho các truy vấn phức tạp.
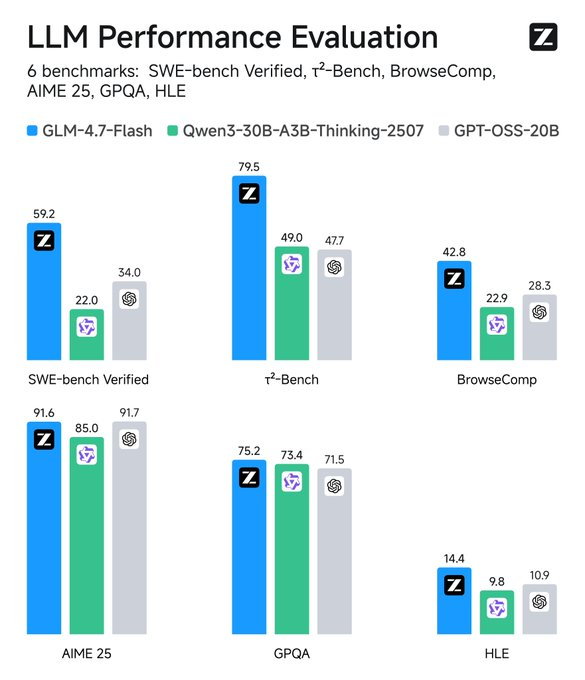
Theo dõi các chỉ số: Các công cụ như TensorBoard theo dõi độ trễ. So sánh với các tiêu chuẩn—GLM-4.7-Flash vượt trội so với các đối thủ trong SWE-bench tới 37.2 điểm.
Tích hợp công cụ: Thêm lời gọi hàm vào các câu lệnh để có hành vi tác nhân.
Bảo mật: Chạy trong môi trường cô lập để ngăn chặn rò rỉ dữ liệu.
Những chiến lược này tối đa hóa tiện ích. Tiếp theo hãy suy nghĩ về các ứng dụng.
Khắc phục sự cố thường gặp
Gặp lỗi hết bộ nhớ? Giảm kích thước lô (batch size) hoặc lượng tử hóa thấp hơn.
Suy luận chậm? Nâng cấp GPU hoặc sử dụng các framework nhanh hơn như vLLM.
Sự cố tương thích? Cập nhật Transformers lên nhánh chính.
Nếu Ollama gặp lỗi, hãy kiểm tra tính khả dụng của cổng 11434.
LM Studio bị treo? Xác minh tính toàn vẹn của mô hình.
Giải quyết những vấn đề này một cách chủ động.
Kết luận: Nâng tầm quy trình làm việc của bạn với GLM-4.7-Flash
Chạy GLM-4.7-Flash cục bộ mở khóa các khả năng AI mạnh mẽ. Từ sự dễ dàng của Ollama đến tính linh hoạt của Hugging Face, có rất nhiều lựa chọn. Tích hợp Apidog để quản lý API liền mạch—tải xuống miễn phí để nâng cao thiết lập của bạn.
Khi công nghệ phát triển, các mô hình như thế này kết nối hiệu suất và khả năng tiếp cận. Thực hiện các bước này, và bạn sẽ đạt được các triển khai AI hiệu quả, riêng tư. Những điều chỉnh nhỏ về thông số hoặc công cụ mang lại những cải tiến đáng kể, biến các tác vụ thường ngày thành các quy trình tinh gọn.