
Các nhà phát triển không ngừng tìm kiếm các mô hình ngôn ngữ mạnh mẽ mang lại hiệu suất vượt trội trên nhiều ứng dụng khác nhau. Zhipu AI giới thiệu GLM-4.6, một phiên bản cải tiến trong chuỗi GLM, đẩy xa giới hạn về khả năng trí tuệ nhân tạo. Mô hình này được xây dựng dựa trên các phiên bản trước đó bằng cách tích hợp những cải tiến đáng kể trong việc xử lý ngữ cảnh, suy luận và tính hữu dụng thực tế. Các kỹ sư tích hợp GLM-4.6 vào quy trình làm việc của họ để giải quyết các nhiệm vụ phức tạp, từ tạo mã đến sáng tạo nội dung, với hiệu quả và độ chính xác cao hơn.
Zhipu AI thiết kế GLM-4.6 như một phần của GLM Coding Plan, một dịch vụ dựa trên đăng ký với mức giá khởi điểm phải chăng. Người dùng truy cập mô hình này thông qua các công cụ tích hợp như Claude Code, Cline, OpenCode và các công cụ khác, cho phép phát triển được hỗ trợ bởi AI một cách liền mạch. Mô hình này vượt trội trong các tình huống thực tế, nơi nó xử lý các ngữ cảnh rộng lớn và tạo ra các kết quả đầu ra chất lượng cao. Hơn nữa, GLM-4.6 thể hiện hiệu suất vượt trội trong các thử nghiệm benchmark, cạnh tranh với các nhà lãnh đạo quốc tế như Claude Sonnet 4. Điều này định vị nó là lựa chọn hàng đầu cho các nhà phát triển ở Trung Quốc và hơn thế nữa, những người yêu cầu sự hỗ trợ AI đáng tin cậy.
Tải ứng dụng
Chuyển từ việc hiểu nền tảng của mô hình, hãy cùng xem xét các tính năng cốt lõi của nó và cách chúng mang lại lợi ích cho việc triển khai kỹ thuật.
GLM-4.6 là gì?
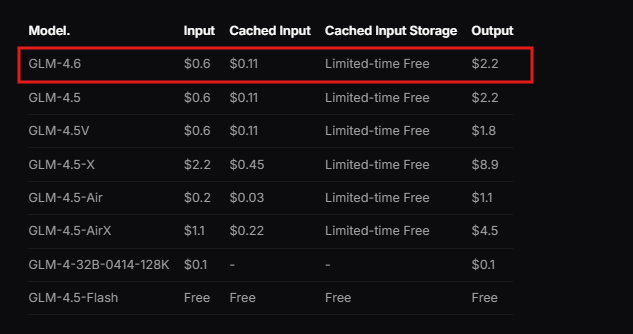
Zhipu AI phát triển GLM-4.6 như một mô hình ngôn ngữ lớn được tối ưu hóa cho nhiều nhiệm vụ kỹ thuật và sáng tạo. Mô hình này có kiến trúc Mixture of Experts (MoE) với 355 tỷ tham số, cho phép tính toán hiệu quả trong khi vẫn duy trì hiệu suất cao. Người dùng đánh giá cao cửa sổ ngữ cảnh mở rộng 200K token của nó, một nâng cấp đáng chú ý so với giới hạn 128K trong các phiên bản trước. Sự mở rộng này cho phép mô hình quản lý các tương tác phức tạp, dài hơi mà không làm mất đi tính mạch lạc.
Ngoài ra, GLM-4.6 hỗ trợ các phương thức nhập và xuất văn bản, làm cho nó trở nên linh hoạt cho các ứng dụng yêu cầu xử lý ngôn ngữ chính xác. Giới hạn token đầu ra tối đa đạt 128K, cung cấp đủ không gian cho các phản hồi chi tiết. Các nhà phát triển tận dụng các thông số kỹ thuật này để xây dựng các hệ thống xử lý dữ liệu lớn, chẳng hạn như phân tích tài liệu hoặc chuỗi suy luận nhiều bước.
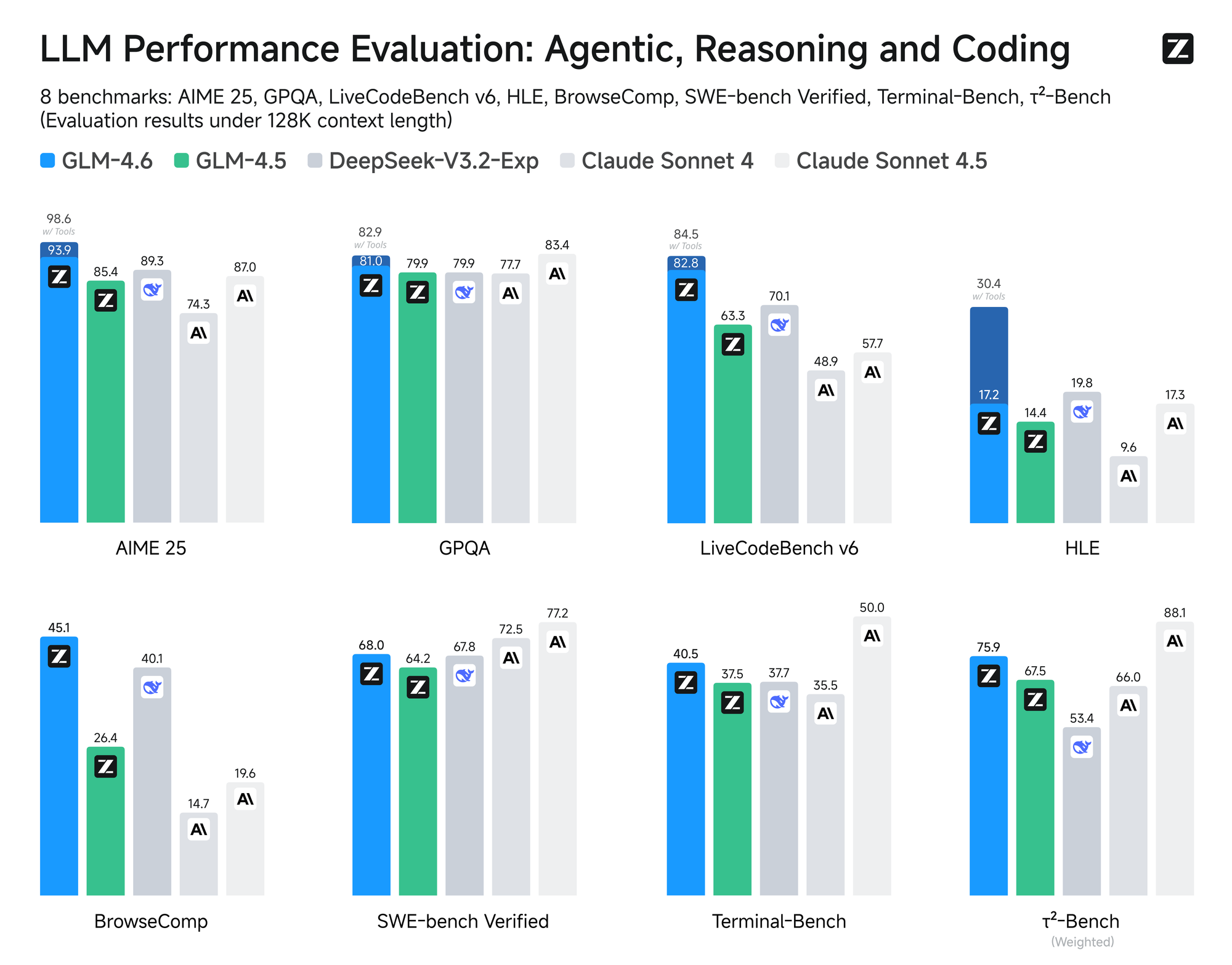
Mô hình trải qua quá trình đánh giá nghiêm ngặt trên tám benchmark uy tín, bao gồm AIME 25, GPQA, LCB v6, HLE và SWE-Bench Verified. Kết quả cho thấy GLM-4.6 hoạt động ngang bằng với các mô hình hàng đầu như Claude Sonnet 4 và 4.6. Chẳng hạn, trong các thử nghiệm mã hóa thực tế được thực hiện trong môi trường Claude Code, GLM-4.6 vượt trội hơn các đối thủ cạnh tranh trong 74 kịch bản thực tế. Nó đạt được điều này với hiệu quả tiêu thụ token cao hơn hơn 30%, giảm chi phí vận hành cho người dùng có khối lượng lớn.
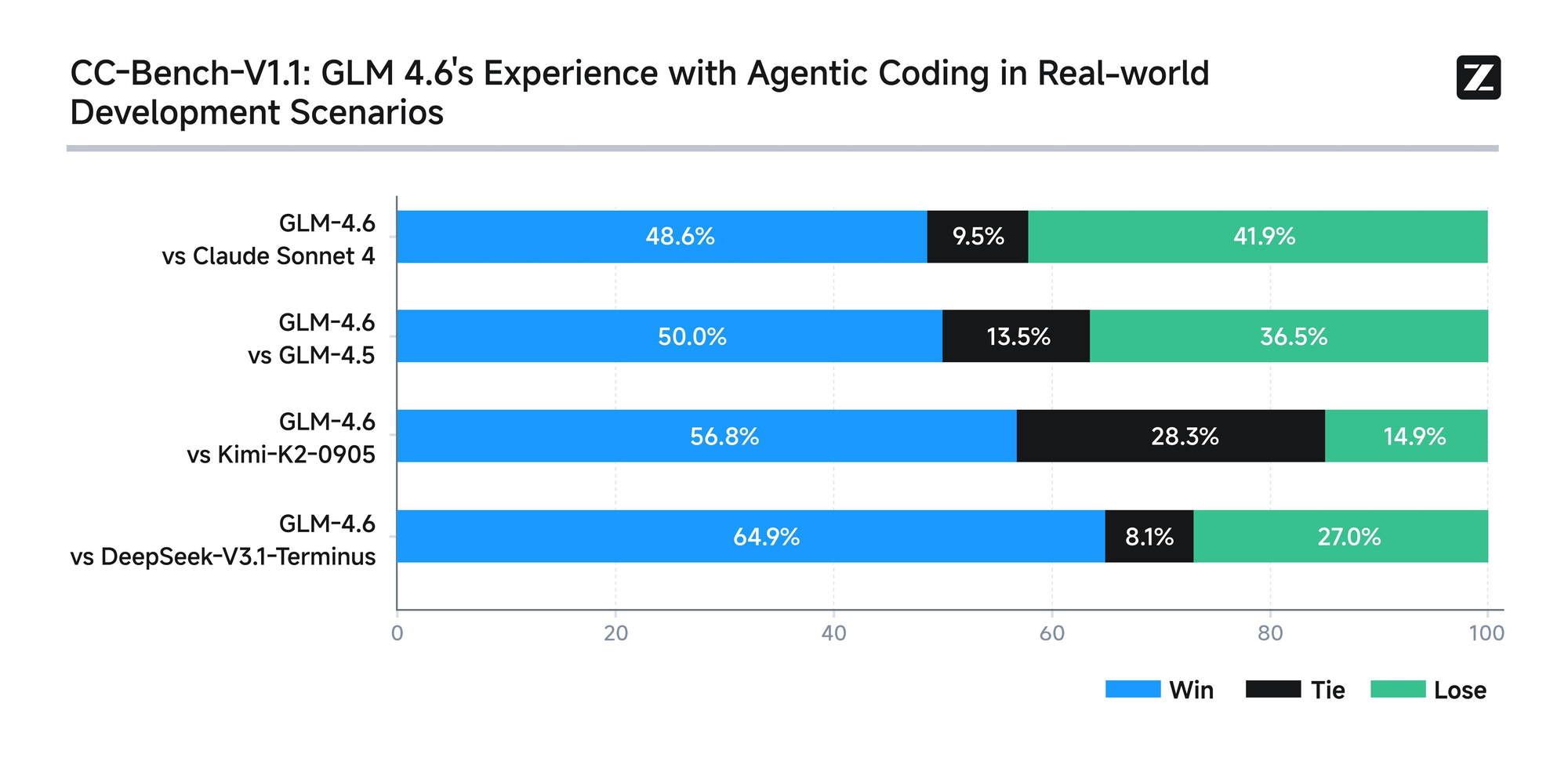
Hơn nữa, Zhipu AI cam kết minh bạch bằng cách công bố tất cả các câu hỏi kiểm tra và quỹ đạo tác nhân một cách công khai. Thực hành này cho phép các nhà phát triển xác minh các tuyên bố và tái tạo kết quả, thúc đẩy niềm tin vào công nghệ. GLM-4.6 cũng tích hợp khả năng suy luận nâng cao, hỗ trợ sử dụng công cụ trong quá trình suy luận. Tính năng này tăng cường tính hữu ích của nó trong các khuôn khổ tác nhân, nơi mô hình tự động lập kế hoạch và thực hiện các nhiệm vụ.
Ngoài việc mã hóa, GLM-4.6 còn tỏa sáng trong các lĩnh vực khác. Nó tinh chỉnh văn bản để phù hợp chặt chẽ với sở thích của con người, cải thiện phong cách, khả năng đọc và tính chân thực khi nhập vai. Trong các tác vụ dịch thuật, mô hình tối ưu hóa cho các ngôn ngữ nhỏ như tiếng Pháp, tiếng Nga, tiếng Nhật và tiếng Hàn, đảm bảo sự mạch lạc về ngữ nghĩa trong các ngữ cảnh không trang trọng. Những người sáng tạo nội dung sử dụng nó cho tiểu thuyết, kịch bản và viết quảng cáo, hưởng lợi từ việc mở rộng ngữ cảnh và sắc thái cảm xúc.
Phát triển nhân vật ảo thể hiện một thế mạnh khác, vì GLM-4.6 duy trì giọng điệu nhất quán trong các cuộc trò chuyện nhiều lượt. Điều này làm cho nó trở nên lý tưởng cho AI xã hội và nhân cách hóa thương hiệu. Trong tìm kiếm thông minh và nghiên cứu chuyên sâu, mô hình tăng cường khả năng hiểu ý định và tổng hợp kết quả, mang lại các đầu ra sâu sắc.
Nhìn chung, GLM-4.6 trao quyền cho các nhà phát triển tạo ra các ứng dụng thông minh hơn. Sự kết hợp giữa xử lý ngữ cảnh dài, sử dụng token hiệu quả và khả năng ứng dụng rộng rãi đã làm cho nó nổi bật trong lĩnh vực AI. Giờ đây, khi đã nắm bắt được bản chất của mô hình, chúng ta sẽ chuyển sang truy cập API của nó để triển khai thực tế.
Cách truy cập API GLM-4.6
Zhipu AI cung cấp quyền truy cập trực tiếp vào API GLM-4.6 thông qua nền tảng mở của họ. Các nhà phát triển bắt đầu bằng cách đăng ký tài khoản trên trang web của Zhipu AI, cụ thể tại open.bigmodel.cn hoặc z.ai. Quá trình này yêu cầu xác minh email hoặc số điện thoại để đảm bảo đăng ký an toàn.
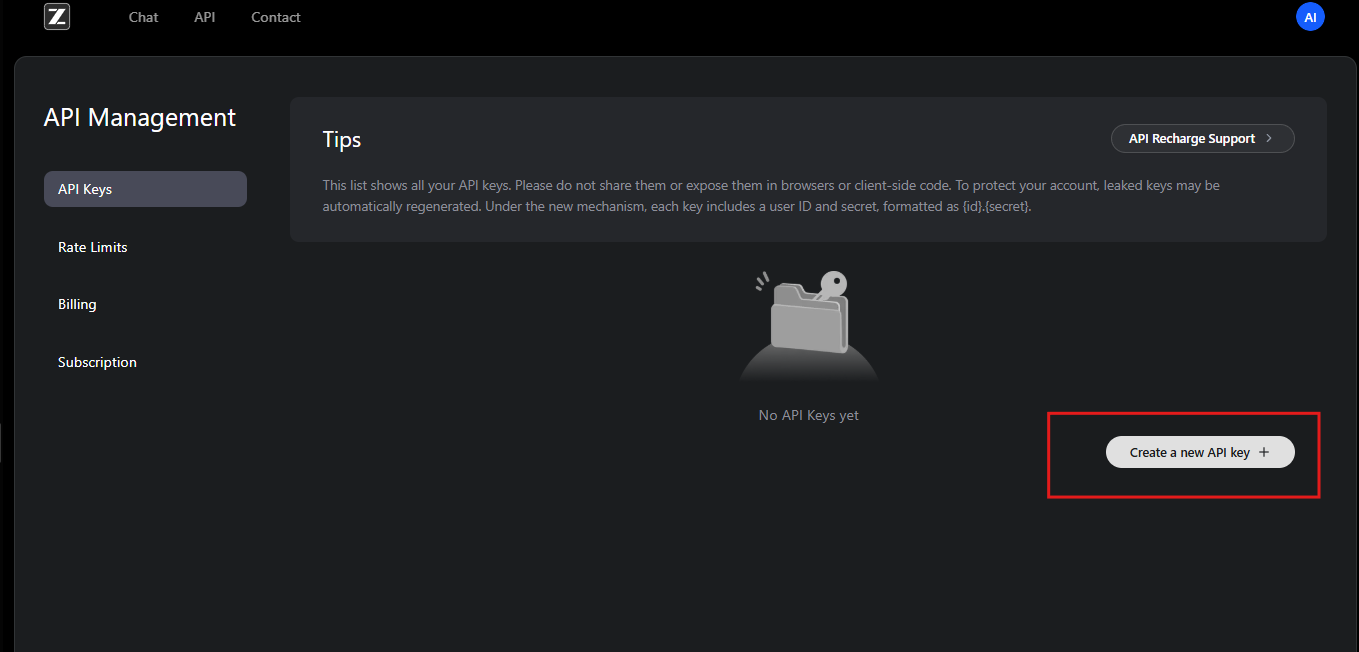
Sau khi đăng ký, người dùng đăng ký GLM Coding Plan. Gói này mở khóa GLM-4.6 và các mô hình liên quan. Người đăng ký có quyền truy cập vào bảng điều khiển API, nơi họ tạo khóa API. Các khóa này đóng vai trò là thông tin xác thực để xác thực các yêu cầu.
Ngoài ra, Zhipu AI cung cấp tài liệu, trong đó trình bày chi tiết các bước tích hợp. Các nhà phát triển xem xét tài liệu này để hiểu các điều kiện tiên quyết, chẳng hạn như môi trường lập trình tương thích. API tuân theo thiết kế RESTful, tương thích với các máy khách HTTP tiêu chuẩn.
Để bắt đầu, người dùng điều hướng đến phần quản lý API trong tài khoản của họ. Tại đây, họ tạo một khóa API mới và ghi lại giá trị của nó một cách an toàn. Zhipu AI khuyến nghị xoay vòng khóa định kỳ để đảm bảo bảo mật. Hơn nữa, nền tảng này cung cấp hạn mức sử dụng dựa trên các cấp độ đăng ký, ngăn chặn việc sử dụng quá mức.
Nếu các nhà phát triển gặp sự cố, nhóm hỗ trợ của Zhipu AI sẽ hỗ trợ qua email hoặc diễn đàn. Họ cũng cung cấp các tài nguyên cộng đồng để khắc phục các vấn đề truy cập phổ biến. Sau khi đã bảo mật quyền truy cập, bước tiếp theo là thiết lập xác thực để tương tác hiệu quả với API GLM-4.6.
Xác thực và thiết lập cho API GLM-4.6
Xác thực tạo thành xương sống của các tương tác API an toàn. Zhipu AI sử dụng xác thực Bearer token cho API GLM-4.6. Các nhà phát triển bao gồm khóa API trong tiêu đề Authorization của mỗi yêu cầu.
Để thiết lập, hãy cài đặt các thư viện cần thiết trong môi trường phát triển của bạn. Ví dụ, người dùng Python sử dụng thư viện requests. Bạn nhập nó và cấu hình tiêu đề như sau:
import requests
api_key = "your-api-key"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
Đoạn mã này chuẩn bị môi trường để gửi yêu cầu. Tương tự, trong JavaScript với Node.js, các nhà phát triển sử dụng API fetch hoặc thư viện axios. Họ đặt các tiêu đề trong đối tượng options.
Hơn nữa, hãy đảm bảo hệ thống của bạn đáp ứng các yêu cầu mạng. Điểm cuối API GLM-4.6 nằm tại https://api.z.ai/api/paas/v4/chat/completions. Kiểm tra kết nối bằng cách ping tên miền hoặc gửi một yêu cầu đơn giản.
Trong quá trình thiết lập, các nhà phát triển cấu hình các biến môi trường để lưu trữ khóa API một cách an toàn. Thực hành này tránh việc mã hóa cứng thông tin nhạy cảm trong các tập lệnh. Các công cụ như dotenv trong Python hoặc process.env trong Node.js tạo điều kiện thuận lợi cho việc này.
Nếu sử dụng proxy hoặc VPN, hãy xác minh rằng nó cho phép lưu lượng truy cập đến các máy chủ của Zhipu AI. Lỗi xác thực thường bắt nguồn từ định dạng khóa không chính xác hoặc gói đăng ký đã hết hạn. Zhipu AI ghi lại các lỗi trong phản hồi, giúp chẩn đoán vấn đề.
Sau khi được xác thực, các nhà phát triển tiếp tục khám phá các điểm cuối. Thiết lập này đảm bảo quyền truy cập đáng tin cậy, an toàn vào các khả năng của GLM-4.6.
Khám phá các điểm cuối API GLM-4.6
API GLM-4.6 tập trung vào một điểm cuối chính cho việc hoàn thành cuộc trò chuyện. Các nhà phát triển gửi yêu cầu POST đến https://api.z.ai/api/paas/v4/chat/completions để tạo phản hồi.
Điểm cuối này xử lý cả chế độ cơ bản và chế độ truyền trực tuyến (streaming). Ở chế độ cơ bản, máy chủ xử lý toàn bộ yêu cầu và trả về một phản hồi hoàn chỉnh. Tuy nhiên, chế độ truyền trực tuyến cung cấp đầu ra tăng dần, lý tưởng cho các ứng dụng thời gian thực.
Để gọi điểm cuối, hãy xây dựng một payload JSON với các tham số bắt buộc. Trường model chỉ định "glm-4.6". Mảng messages chứa các cặp vai trò-nội dung, mô phỏng các cuộc trò chuyện.
Ví dụ, một yêu cầu curl cơ bản trông như thế này:
curl -X POST "https://api.z.ai/api/paas/v4/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer your-api-key" \
-d '{
"model": "glm-4.6",
"messages": [
{"role": "user", "content": "Generate a Python function for sorting a list."}
]
}'
Máy chủ phản hồi bằng JSON chứa nội dung được tạo. Các nhà phát triển phân tích cú pháp này để trích xuất các tin nhắn của trợ lý.
Ngoài ra, điểm cuối hỗ trợ các tính năng nâng cao như các bước suy nghĩ. Đặt đối tượng thinking để bật suy luận chi tiết trong đầu ra.
Hiểu điểm cuối này cho phép các nhà phát triển xây dựng các hệ thống AI tương tác. Tiếp theo, chúng ta sẽ phân tích chi tiết các tham số yêu cầu.
Giải thích chi tiết các tham số yêu cầu của API GLM-4.6
Các tham số yêu cầu kiểm soát hành vi của API GLM-4.6. Tham số model bắt buộc là "glm-4.6" để chọn phiên bản cụ thể này.
Mảng messages điều khiển cuộc trò chuyện. Mỗi đối tượng bao gồm một vai trò – "user" cho đầu vào, "assistant" cho các phản hồi trước đó – và nội dung dưới dạng chuỗi văn bản. Các nhà phát triển cấu trúc các cuộc đối thoại nhiều lượt bằng cách xen kẽ các vai trò.
Hơn nữa, max_tokens giới hạn độ dài phản hồi, ngăn chặn đầu ra quá mức. Đặt nó thành 4096 để có kết quả cân bằng. Temperature điều chỉnh tính ngẫu nhiên; các giá trị thấp hơn như 0.6 mang lại kết quả xác định, trong khi các giá trị cao hơn khuyến khích sự sáng tạo.
Để truyền trực tuyến, hãy bao gồm "stream": true. Điều này thay đổi định dạng phản hồi thành dữ liệu theo khối.
Tham số thinking cho phép suy luận từng bước. Đặt "thinking": {"type": "enabled"} để bao gồm các suy nghĩ trung gian trong phản hồi.
Các tham số tùy chọn khác bao gồm top_p cho lấy mẫu hạt nhân và presence_penalty để ngăn chặn sự lặp lại. Các nhà phát triển điều chỉnh chúng dựa trên các trường hợp sử dụng.
Các tham số không hợp lệ sẽ kích hoạt phản hồi lỗi với các mã như 400 cho các yêu cầu không hợp lệ. Luôn xác thực các payload trước khi gửi.
Bằng cách nắm vững các tham số này, các nhà phát triển tùy chỉnh các lệnh gọi API GLM-4.6 để đạt hiệu suất tối ưu.
Xử lý phản hồi từ API GLM-4.6
Các phản hồi từ API GLM-4.6 đến dưới định dạng JSON. Các nhà phát triển phân tích cú pháp mảng choices để truy cập nội dung được tạo.
Ở chế độ cơ bản, phản hồi bao gồm:
{
"id": "chatcmpl-...",
"object": "chat.completion",
"created": 1694123456,
"model": "glm-4.6",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Your generated text here."
},
"finish_reason": "stop"
}
]
}
Trích xuất trường content để sử dụng trong các ứng dụng.
Ở chế độ truyền trực tuyến, các phản hồi được truyền dưới dạng Server-Sent Events (SSE). Mỗi khối tuân theo:
data: {"id":"chatcmpl-...","choices":[{"delta":{"content":" partial text"}}]}
Các nhà phát triển tích lũy các deltas để xây dựng đầu ra hoàn chỉnh.
Xử lý lỗi bao gồm việc kiểm tra mã trạng thái. Mã 401 cho biết lỗi xác thực, trong khi 429 báo hiệu giới hạn tốc độ.
Ghi nhật ký phản hồi để gỡ lỗi. Cách tiếp cận này đảm bảo tích hợp mạnh mẽ với API GLM-4.6.
Ví dụ mã để tích hợp API GLM-4.6
Các nhà phát triển triển khai API GLM-4.6 bằng nhiều ngôn ngữ khác nhau. Trong Python, sử dụng requests cho một lệnh gọi cơ bản:
import requests
import json
url = "https://api.z.ai/api/paas/v4/chat/completions"
payload = {
"model": "glm-4.6",
"messages": [{"role": "user", "content": "Explain quantum computing."}],
"max_tokens": 500,
"temperature": 0.7
}
headers = {
"Authorization": "Bearer your-api-key",
"Content-Type": "application/json"
}
response = requests.post(url, data=json.dumps(payload), headers=headers)
print(response.json()["choices"][0]["message"]["content"])
Đoạn mã này gửi một truy vấn và in phản hồi.
Trong JavaScript với Node.js:
const fetch = require('node-fetch');
const url = 'https://api.z.ai/api/paas/v4/chat/completions';
const payload = {
model: 'glm-4.6',
messages: [{ role: 'user', content: 'Write a haiku about AI.' }],
max_tokens: 100
};
const headers = {
'Authorization': 'Bearer your-api-key',
'Content-Type': 'application/json'
};
fetch(url, {
method: 'POST',
body: JSON.stringify(payload),
headers
})
.then(res => res.json())
.then(data => console.log(data.choices[0].message.content));
Để truyền trực tuyến trong Python, hãy sử dụng các thư viện phân tích cú pháp SSE như sseclient.
Những ví dụ này minh họa việc tích hợp thực tế, cho phép các nhà phát triển tạo nguyên mẫu nhanh chóng.
Sử dụng Apidog để kiểm thử API GLM-4.6
Apidog là một công cụ tuyệt vời để kiểm thử API GLM-4.6. Nền tảng tất cả trong một này cho phép các nhà phát triển thiết kế, gỡ lỗi, giả lập và tự động hóa các tương tác API.
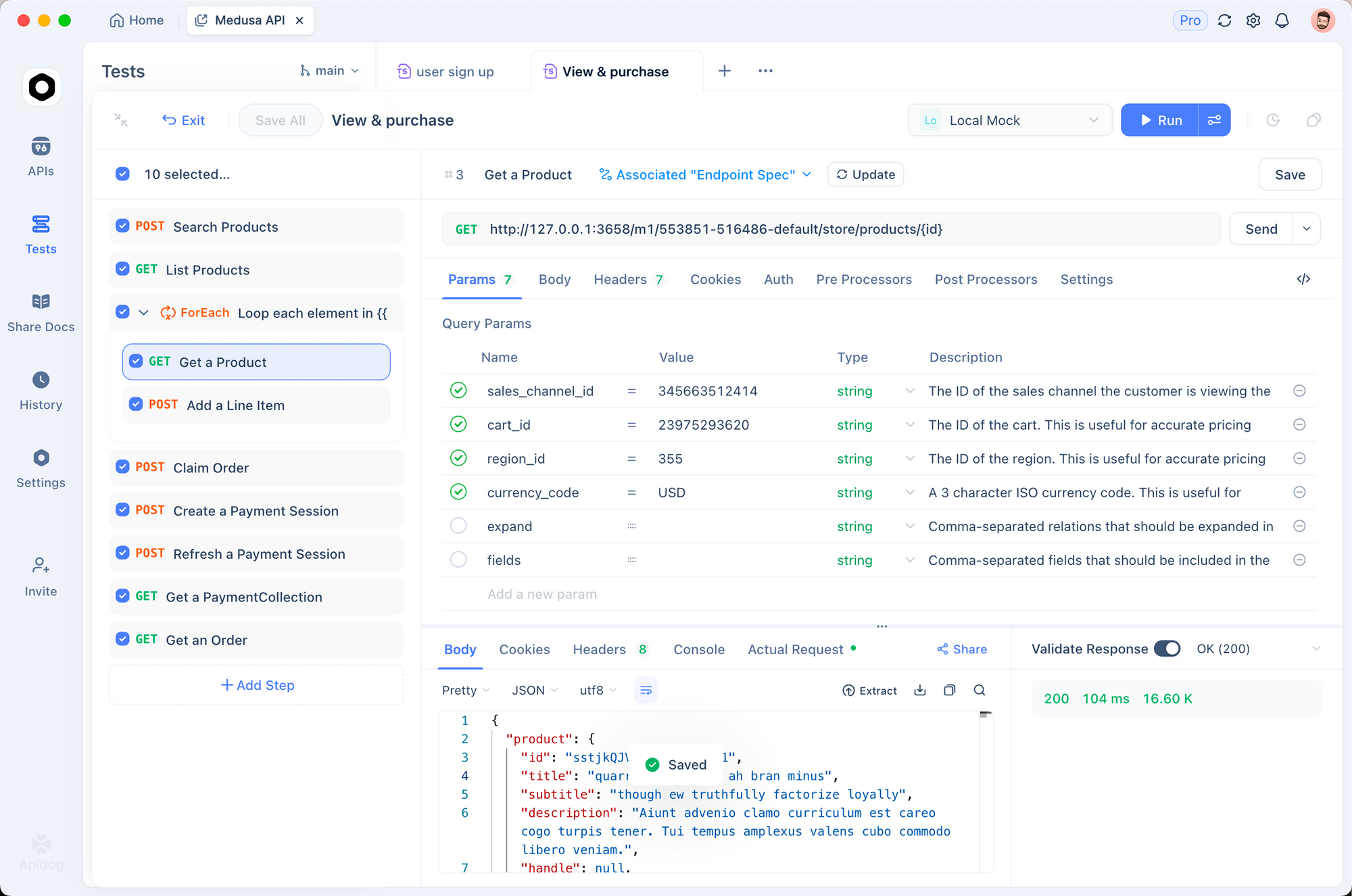
Bắt đầu bằng cách tải xuống Apidog từ apidog.com và tạo một dự án. Nhập điểm cuối API GLM-4.6 bằng cách thêm một API mới với URL https://api.z.ai/api/paas/v4/chat/completions.
Đặt xác thực trong phần tiêu đề của Apidog, thêm "Authorization: Bearer your-api-key". Cấu hình phần thân yêu cầu với các tham số JSON như model và messages.
Apidog cho phép gửi yêu cầu và xem phản hồi trong một giao diện thân thiện với người dùng. Các nhà phát triển kiểm tra các biến thể bằng cách sao chép yêu cầu và điều chỉnh các tham số.
Hơn nữa, tự động hóa các thử nghiệm bằng cách tạo các kịch bản trong Apidog. Xác định các khẳng định để xác thực nội dung phản hồi, đảm bảo API GLM-4.6 hoạt động như mong đợi.
Các máy chủ giả lập trong Apidog mô phỏng các phản hồi để phát triển ngoại tuyến. Tính năng này tăng tốc tạo nguyên mẫu mà không cần gọi API trực tiếp.

Bằng cách tích hợp Apidog, các nhà phát triển hợp lý hóa quy trình làm việc API GLM-4.6, giảm lỗi và tăng tốc triển khai.
Các thực tiễn tốt nhất và giới hạn tốc độ cho API GLM-4.6
Tuân thủ các thực tiễn tốt nhất sẽ tối đa hóa tiềm năng của API GLM-4.6. Các nhà phát triển theo dõi việc sử dụng để duy trì trong giới hạn tốc độ, thường được xác định bằng số token mỗi phút hoặc số yêu cầu mỗi ngày dựa trên gói đăng ký.
Thực hiện exponential backoff cho các lần thử lại khi gặp lỗi như 429. Điều này ngăn chặn việc làm quá tải máy chủ.
Tối ưu hóa các lời nhắc để rõ ràng nhằm cải thiện chất lượng phản hồi. Sử dụng các tin nhắn hệ thống để thiết lập ngữ cảnh, hướng dẫn mô hình một cách hiệu quả.
Bảo mật khóa API trong môi trường sản xuất. Tránh để lộ chúng trong mã phía máy khách.
Ghi nhật ký các tương tác để kiểm tra và phân tích hiệu suất. Dữ liệu này cung cấp thông tin cho các cải tiến.
Xử lý các trường hợp biên, chẳng hạn như phản hồi trống hoặc hết thời gian chờ, bằng các cơ chế dự phòng.
Zhipu AI cập nhật giới hạn tốc độ trong tài liệu; hãy kiểm tra thường xuyên.
Tuân thủ các thực tiễn này đảm bảo việc sử dụng API GLM-4.6 hiệu quả và đáng tin cậy.
Sử dụng nâng cao API GLM-4.6
Người dùng nâng cao khám phá tính năng truyền trực tuyến cho các ứng dụng tương tác. Đặt "stream": true và xử lý các khối dữ liệu theo thời gian thực.
Tích hợp các công cụ bằng cách bao gồm các lệnh gọi hàm trong tin nhắn. GLM-4.6 hỗ trợ gọi công cụ, cho phép các tác nhân thực hiện các hành động bên ngoài.
Ví dụ, định nghĩa các công cụ trong payload:
"tools": [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather",
"parameters": {...}
}
}
]
Mô hình phản hồi bằng các lệnh gọi công cụ nếu cần.
Tinh chỉnh temperature cho các tác vụ cụ thể; thấp cho các truy vấn thực tế, cao cho các truy vấn sáng tạo.
Kết hợp với ngữ cảnh dài để tóm tắt tài liệu. Đưa các văn bản lớn vào tin nhắn.
Tích hợp vào các framework tác nhân như LangChain cho các quy trình làm việc phức tạp.
Những kỹ thuật này mở khóa toàn bộ tiềm năng của GLM-4.6 trong các hệ thống phức tạp.
Kết luận
API GLM-4.6 mang đến cho các nhà phát triển một công cụ mạnh mẽ để đổi mới AI. Bằng cách làm theo hướng dẫn này, bạn có thể tích hợp nó một cách liền mạch vào các dự án. Hãy thử nghiệm các tính năng, kiểm thử bằng Apidog và áp dụng các thực tiễn tốt nhất để thành công. Zhipu AI tiếp tục phát triển GLM-4.6, hứa hẹn những khả năng thậm chí còn lớn hơn trong tương lai.
Tải ứng dụng