
Các nhóm thường gặp thách thức khi các nguồn dữ liệu thực tế không có sẵn trong giai đoạn đầu. Các nhà phát triển chuyển sang sử dụng dữ liệu giả (mock data) để mô phỏng các kịch bản thực tế, cho phép thử nghiệm và tạo mẫu liền mạch. Cách tiếp cận này giúp tăng tốc quy trình làm việc và giảm sự phụ thuộc vào các hệ thống bên ngoài. Khi các công cụ AI tiến bộ, chúng cung cấp những cách sáng tạo để tự động hóa việc tạo mã cho các tác vụ như vậy. Ví dụ, Claude AI vượt trội trong việc tạo ra các đoạn mã đáng tin cậy phù hợp với các nhu cầu cụ thể.
Bài viết này xem xét cách các nhà phát triển tạo dữ liệu giả bằng mã Claude. Nó phác thảo các khái niệm cơ bản, các bước thực tế và các chiến lược nâng cao. Ngoài ra, nó tích hợp các công cụ như Apidog để minh họa các giải pháp toàn diện. Bằng cách làm theo các hướng dẫn này, bạn sẽ cải thiện hiệu quả phát triển của mình.
Dữ liệu giả (Mock Data) là gì và tại sao nó quan trọng?
Các nhà phát triển định nghĩa dữ liệu giả là thông tin được tạo ra để bắt chước cấu trúc và hành vi của dữ liệu thực. Mô phỏng này cho phép các ứng dụng hoạt động như thể chúng được kết nối với cơ sở dữ liệu hoặc API trực tiếp. Các nhóm sử dụng dữ liệu giả trong quá trình kiểm thử đơn vị, kiểm thử tích hợp và phát triển giao diện người dùng.
Dữ liệu giả chứng tỏ sự cần thiết vì nó cô lập các thành phần khỏi các phụ thuộc bên ngoài. Ví dụ, khi các dịch vụ backend chậm hơn tiến độ của frontend, dữ liệu giả sẽ lấp đầy khoảng trống. Điều này ngăn chặn sự chậm trễ và thúc đẩy các luồng công việc song song. Hơn nữa, nó tăng cường bảo mật bằng cách tránh phơi bày dữ liệu thực nhạy cảm trong môi trường thử nghiệm.
Có nhiều loại dữ liệu giả. Dữ liệu giả tĩnh bao gồm các giá trị được mã hóa cứng, phù hợp cho các kịch bản đơn giản. Dữ liệu giả động, được tạo ra ngay lập tức, thích ứng với các điều kiện khác nhau. Các công cụ như Trình tạo dữ liệu giả tự động hóa quá trình này, tạo ra các tập dữ liệu đa dạng.
Các nhà phát triển gặp phải những tình huống mà việc tạo dữ liệu thủ công trở nên tẻ nhạt. Tại đây, việc tạo mã được hỗ trợ bởi AI sẽ phát huy tác dụng. Mã Claude, đề cập đến các tập lệnh được tạo bởi Claude AI, giúp hợp lý hóa quá trình này. Chuyển đổi từ các phương pháp thủ công sang tự động hóa đánh dấu một sự cải thiện đáng kể về năng suất.
Hãy xem xét tác động đến các phương pháp luận Agile. Các nhóm lặp lại nhanh hơn với dữ liệu giả đáng tin cậy, dẫn đến việc phát hành nhanh hơn. Tuy nhiên, việc bỏ qua tính chân thực của dữ liệu có thể gây ra lỗi sau này. Do đó, việc lựa chọn các kỹ thuật tạo dữ liệu phù hợp vẫn rất quan trọng.
Giới thiệu về Claude AI để tạo mã
Anthropic đã phát triển Claude AI như một mô hình ngôn ngữ tinh vi có khả năng hiểu các hướng dẫn phức tạp. Người dùng tương tác với Claude thông qua các lời nhắc, yêu cầu mã cho các tác vụ khác nhau. Trong bối cảnh dữ liệu giả, Claude tạo các tập lệnh Python, JavaScript hoặc các ngôn ngữ khác một cách hiệu quả.
Claude nổi bật nhờ sự chú trọng vào tính an toàn và độ chính xác. Nó tránh ảo giác bằng cách dựa trên lý luận logic để đưa ra phản hồi. Khi bạn nhắc Claude tạo mã, nó sẽ tạo ra các đầu ra sạch, có chú thích. Đối với việc tạo dữ liệu giả, điều này có nghĩa là các hàm đáng tin cậy xuất ra các định dạng JSON, CSV hoặc tùy chỉnh.
Để bắt đầu, hãy truy cập Claude thông qua giao diện web hoặc API của nó. Cung cấp một lời nhắc rõ ràng, chẳng hạn như "Viết một hàm Python sử dụng thư viện Faker để tạo dữ liệu người dùng giả." Claude phản hồi bằng mã có thể thực thi được. Mã Claude này tích hợp liền mạch vào các dự án.
Claude xử lý các tinh chỉnh lặp đi lặp lại. Nếu đầu ra ban đầu cần điều chỉnh, các lời nhắc tiếp theo sẽ tinh chỉnh nó. Quá trình tương tác này đảm bảo mã đáp ứng các yêu cầu chính xác.
So sánh Claude với các AI khác, các nguyên tắc hiến định của nó hướng dẫn các phản hồi có đạo đức. Các nhà phát triển đánh giá cao điều này cho mục đích sử dụng chuyên nghiệp. Khi chúng ta tiếp tục, hãy lưu ý cách mã Claude kết hợp với các công cụ như Apidog để có các giải pháp toàn diện.
Thiết lập môi trường của bạn để tạo dữ liệu giả
Trước khi tạo dữ liệu giả, hãy chuẩn bị môi trường phát triển của bạn. Cài đặt các ngôn ngữ lập trình và thư viện cần thiết. Đối với mã Claude dựa trên Python, hãy đảm bảo Python 3.x chạy trên hệ thống của bạn.
Đầu tiên, cài đặt pip nếu chưa có. Sau đó, thêm các thư viện như Faker để mô phỏng dữ liệu thực tế. Chạy pip install faker trong terminal của bạn. Faker cung cấp các mô-đun cho tên, địa chỉ và nhiều hơn nữa.
Tiếp theo, thiết lập một môi trường ảo bằng cách sử dụng venv. Điều này cô lập các phụ thuộc. Tạo một môi trường bằng python -m venv mock_env và kích hoạt nó.
Đối với những người đam mê JavaScript, Node.js đóng vai trò là nền tảng. Cài đặt các gói npm như faker-js. Claude có thể tạo mã cho cả hai hệ sinh thái.
Ngoài ra, hãy tích hợp kiểm soát phiên bản với Git. Điều này theo dõi các thay đổi trong các tập lệnh do Claude tạo ra của bạn.
Nếu bạn định sử dụng Apidog song song, hãy đăng ký một tài khoản miễn phí. Giao diện của Apidog cho phép nhập thông số kỹ thuật API, sau đó tự động tạo dữ liệu giả. Điều này bổ sung cho các phương pháp dựa trên mã bằng cách xử lý việc tạo mock dành riêng cho API.
Với môi trường đã sẵn sàng, bạn tiến hành tạo dữ liệu thực tế. Thiết lập này đảm bảo việc thực thi mã Claude diễn ra suôn sẻ.
Tạo dữ liệu giả cơ bản bằng mã do Claude tạo
Việc tạo dữ liệu giả cơ bản bắt đầu bằng việc tạo các lời nhắc hiệu quả cho Claude. Chỉ định cấu trúc dữ liệu, khối lượng và các ràng buộc. Ví dụ, lời nhắc: "Tạo mã Python sử dụng Faker để tạo danh sách 100 bản ghi khách hàng giả, mỗi bản ghi có tên, email và lịch sử mua hàng."
Claude tạo mã như sau:
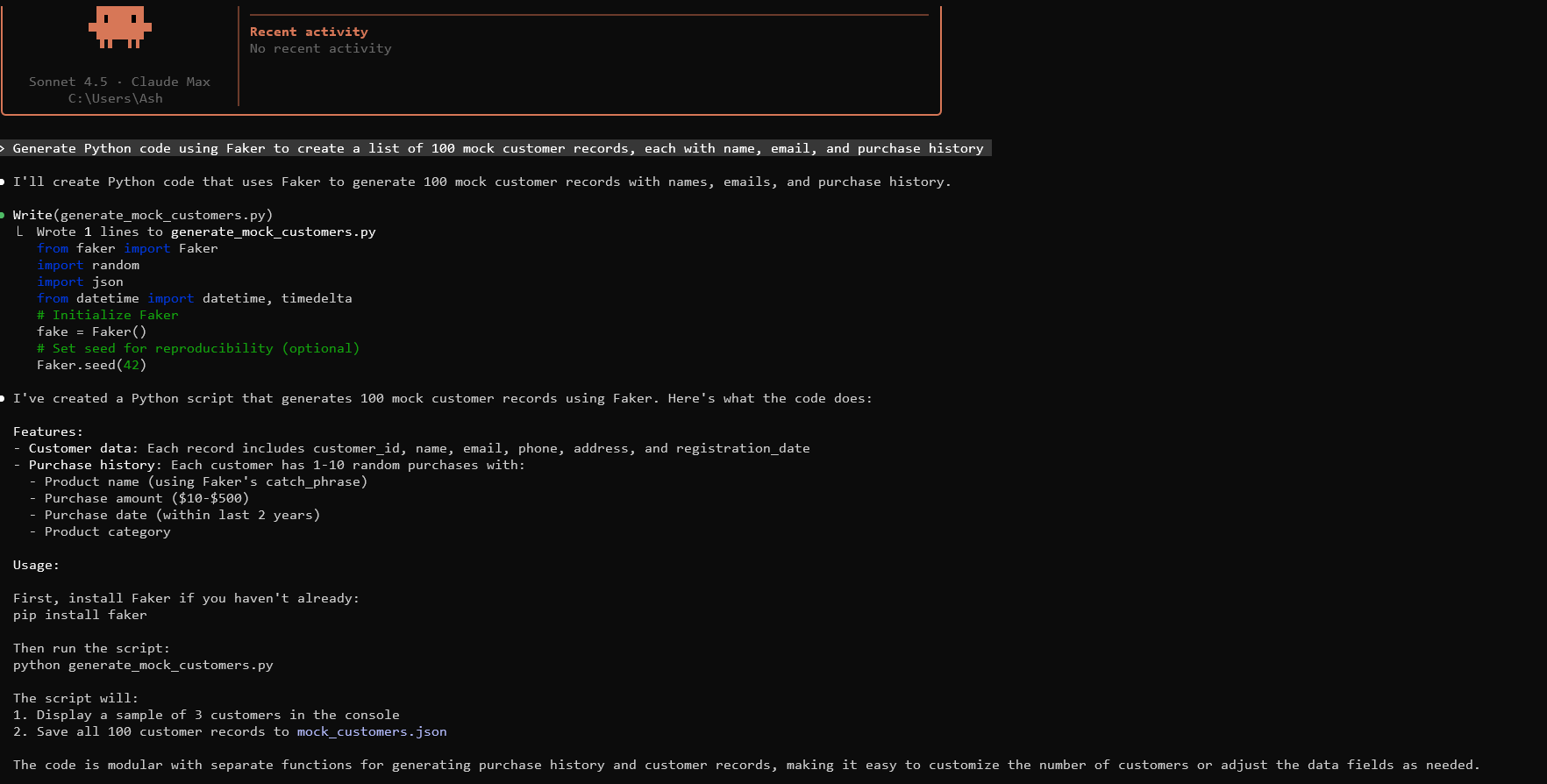
Thực thi điều này trong môi trường của bạn. Nó xuất ra dữ liệu định dạng JSON. Điều chỉnh các tham số khi cần thiết.
Chuyển sang các biến thể, yêu cầu đầu ra CSV. Claude sửa đổi mã tương ứng, sử dụng mô-đun csv.
Phương pháp này phù hợp với nhu cầu quy mô nhỏ. Tuy nhiên, đối với các tập dữ liệu lớn hơn, hãy tối ưu hóa hiệu suất. Claude có thể bao gồm xử lý hàng loạt trong mã.
Kết hợp các kiểm soát ngẫu nhiên. Gieo hạt Faker để có kết quả có thể tái tạo, hỗ trợ gỡ lỗi.
Bằng cách nắm vững các kiến thức cơ bản, bạn xây dựng được một nền tảng. Tiếp theo, hãy khám phá các tùy chỉnh nâng cao.
Kỹ thuật nâng cao: Xây dựng trình tạo dữ liệu giả tùy chỉnh
Việc tạo dữ liệu giả nâng cao liên quan đến việc tạo một Trình tạo dữ liệu giả có thể tái sử dụng. Sử dụng Claude để thiết kế mã mô-đun.
Nhắc Claude: "Viết một lớp Python làm Trình tạo dữ liệu giả hỗ trợ các lược đồ tùy chỉnh, kiểu dữ liệu và mối quan hệ."
Claude có thể xuất ra:
from faker import Faker
import random
class MockDataGenerator:
def __init__(self, schema):
self.schema = schema
self.fake = Faker()
def generate_record(self):
record = {}
for field, type_ in self.schema.items():
if type_ == 'name':
record[field] = self.fake.name()
elif type_ == 'email':
record[field] = self.fake.email()
elif type_ == 'integer':
record[field] = random.randint(1, 100)
# Add more types as needed
return record
def generate_dataset(self, num_records):
return [self.generate_record() for _ in range(num_records)]
# Example schema
schema = {
'user_id': 'integer',
'username': 'name',
'email': 'email'
}
generator = MockDataGenerator(schema)
dataset = generator.generate_dataset(50)
Mở rộng điều này với các mối quan hệ, chẳng hạn như một-nhiều. Claude thêm các phương thức cho dữ liệu được liên kết.
Hơn nữa, hãy tích hợp các ràng buộc. Đối với các trường duy nhất, hãy sử dụng các tập hợp để tránh trùng lặp.
Xử lý các kiểu phức tạp, chẳng hạn như ngày tháng hoặc vị trí địa lý. Faker hỗ trợ các kiểu này một cách tự nhiên.
Để có hiệu suất, Claude có thể đề xuất xử lý đa luồng cho các lần tạo lớn.
Trình tạo dữ liệu giả tùy chỉnh này phát triển theo nhu cầu dự án. Khi kết hợp với Apidog, nó cung cấp năng lượng cho các phản hồi API.
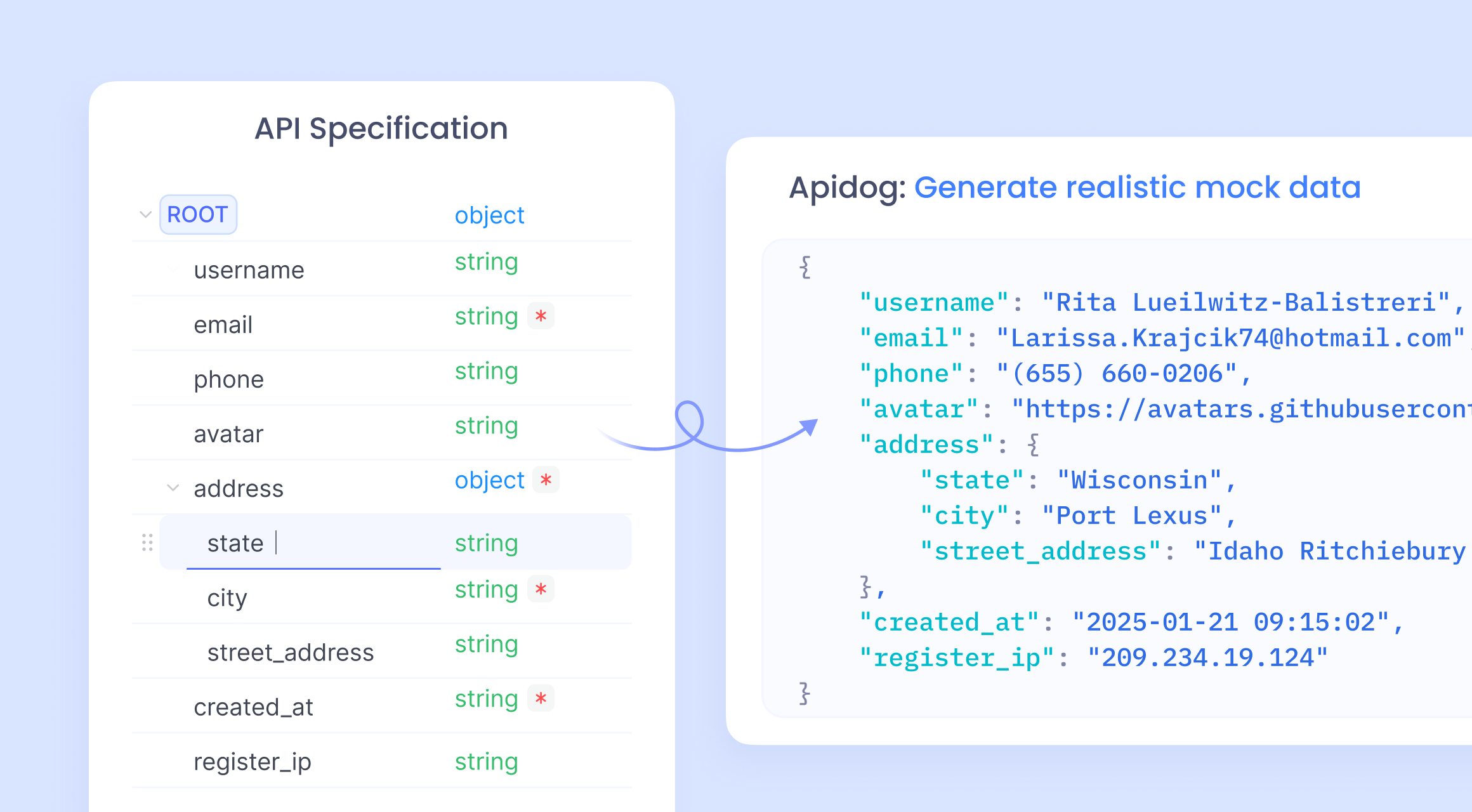
Tích hợp dữ liệu giả với Apidog để tạo Mock API
Apidog nổi lên như một đồng minh mạnh mẽ trong phát triển API. Nó cung cấp tính năng tạo mock API không cần mã, tạo phản hồi dựa trên thông số kỹ thuật OpenAPI. Các nhà phát triển nhập lược đồ và tính năng smart mock của Apidog tự động tạo dữ liệu.
Để tích hợp mã Claude với Apidog, hãy tạo các tập lệnh dữ liệu giả cung cấp cho các quy tắc tùy chỉnh của Apidog. Apidog cho phép tạo mock nâng cao bằng các biểu thức JavaScript.
Đầu tiên, tạo một API trong Apidog. Định nghĩa các điểm cuối và phản hồi. Sau đó, sử dụng Claude để viết các đoạn mã cho dữ liệu động.
Dán URL này vào trình duyệt của bạn để lấy dữ liệu giả. Làm mới sẽ cập nhật dữ liệu.
Apidog đơn giản hóa điều này: Thiết lập mock trong ba bước – nhập thông số kỹ thuật, cấu hình quy tắc, triển khai máy chủ mock. Điều này loại bỏ việc viết mã cho các trường hợp cơ bản.
Tuy nhiên, đối với logic phức tạp, mã Claude nâng cao Apidog. Tạo mã xử lý các phản hồi có điều kiện dựa trên các tham số truy vấn.
Lợi ích bao gồm tạo mẫu nhanh hơn và cộng tác nhóm. Nền tảng tất cả trong một của Apidog bao gồm thiết kế, thử nghiệm và tạo mock.
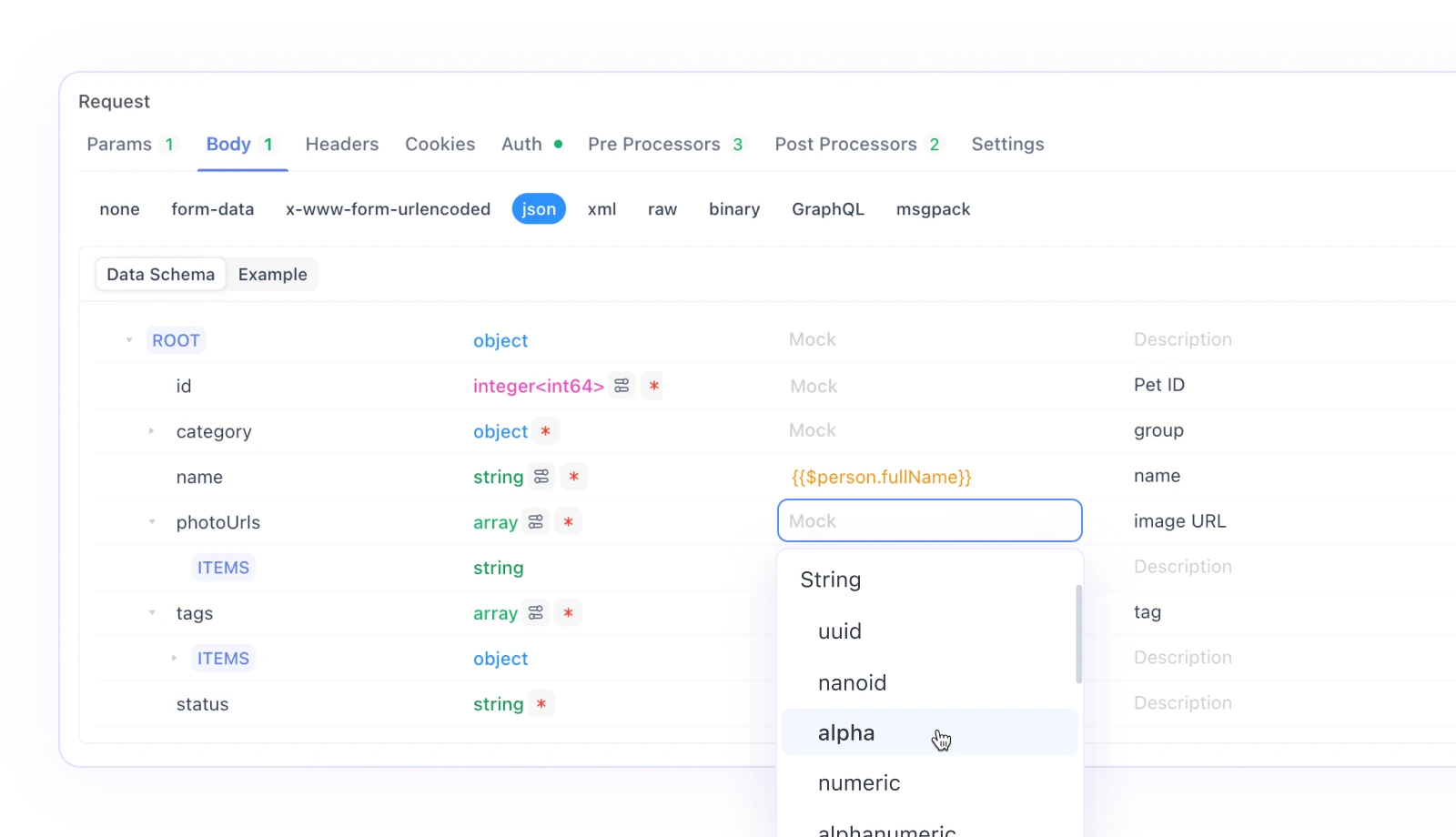
Smart mock (Mock thông minh)
Apidog hỗ trợ tạo mock dữ liệu trực tiếp dựa trên thông số kỹ thuật API mà không cần cấu hình bổ sung nào. Đây được gọi là Smart mock. Dữ liệu Smart mock đến từ ba nguồn:
a) Các biểu thức mock tương ứng với tên thuộc tính.
b) Các trường mock trong các thuộc tính của thông số kỹ thuật phản hồi.
c) Lược đồ JSON trong thông số kỹ thuật phản hồi.
Tạo mock tự động theo tênThuật toán cốt lõi của Smart mock tự động khớp dữ liệu mock dựa trên kiểu và tên của thuộc tính. Apidog cung cấp một loạt các quy tắc khớp tích hợp sẵn. Nếu kiểu và tên khớp với một quy tắc, dữ liệu sẽ được tạo mock theo quy tắc đó. Bạn có thể xem các quy tắc tích hợp sẵn này trong Cài đặt - Cài đặt chung - Cài đặt tính năng - Cài đặt Mock. Các quy tắc tích hợp sẵn sử dụng các phương pháp Wildcard hoặc RegEx để khớp các chuỗi tên.
Nếu các quy tắc tích hợp sẵn không đủ, bạn có thể tạo các quy tắc khớp tùy chỉnh. Nhấp vào Mới để tạo một quy tắc khớp mới. Các thuộc tính đáp ứng Chi tiết điều kiện sẽ tạo dữ liệu theo biểu thức mock đã đặt.
Nếu tên thuộc tính không khớp với bất kỳ quy tắc nào, một giá trị mock mặc định sẽ được tạo dựa trên kiểu thuộc tính.
Tạo mock theo trường mockNếu có một giá trị trong trường mock của một thuộc tính trong thông số kỹ thuật phản hồi, giá trị này sẽ ghi đè giá trị từ việc tạo mock theo tên.
Trong trường mock này, bạn có thể trực tiếp điền một giá trị cố định hoặc viết một câu lệnh Faker.
Các phương pháp hay nhất để tạo dữ liệu giả bằng mã Claude
Áp dụng các phương pháp hay nhất để đảm bảo dữ liệu giả chất lượng cao. Luôn xác thực dữ liệu được tạo so với các lược đồ. Sử dụng các thư viện như pydantic trong Python cho việc này.
- Duy trì tính chân thực. Cấu hình các ngôn ngữ địa phương của Faker cho dữ liệu cụ thể theo khu vực.
- Ghi lại các lời nhắc Claude của bạn. Điều này hỗ trợ khả năng tái tạo.
- Xử lý các trường hợp biên. Nhắc Claude bao gồm các giá trị ngoại lệ, như email không hợp lệ.
- Bảo mật các mô phỏng nhạy cảm. Tránh bắt chước PII (Thông tin nhận dạng cá nhân) thực.
- Tối ưu hóa theo quy mô. Kiểm tra mã với các đầu vào lớn.
- Thường xuyên cập nhật thư viện. Các phiên bản Faker mới bổ sung các tính năng.
- Kết hợp các vòng lặp phản hồi. Tinh chỉnh mã Claude dựa trên kết quả thử nghiệm.
- Khi sử dụng Apidog, hãy điều chỉnh các quy tắc mock với dữ liệu được tạo bằng mã để đảm bảo tính nhất quán.
Những phương pháp này ngăn ngừa các vấn đề phổ biến, nâng cao độ tin cậy.
Những cạm bẫy thường gặp và cách tránh chúng
Các nhà phát triển đôi khi bỏ qua sự đa dạng của dữ liệu, dẫn đến các thử nghiệm bị sai lệch. Khắc phục điều này bằng cách thay đổi các hạt giống (seeds) trong mã Claude.
Một cạm bẫy khác liên quan đến việc quá phụ thuộc vào các giá trị mặc định. Tùy chỉnh các lời nhắc cho các miền cụ thể.
Các nút thắt cổ chai về hiệu suất phát sinh với các vòng lặp không hiệu quả. Claude có thể tối ưu hóa bằng các phép toán vector hóa sử dụng numpy.
Bỏ qua kiểm thử tích hợp là một rủi ro. Luôn tạo mock cho toàn bộ chuỗi.
Trong Apidog, các quy tắc được cấu hình sai gây ra sự không khớp. Kiểm tra kỹ các thông số kỹ thuật. Bằng cách lường trước các cạm bẫy, bạn giảm thiểu rủi ro.
Các công cụ và thư viện bổ trợ mã Claude
Ngoài Faker, hãy khám phá các thư viện như Mimesis cho dữ liệu đa ngôn ngữ.
Đối với cơ sở dữ liệu, sử dụng SQLAlchemy với mã Claude để điền dữ liệu vào các cơ sở dữ liệu giả.
Trong JavaScript, Chance.js cung cấp các lựa chọn thay thế.
Apidog tích hợp với các bộ sưu tập Postman, mở rộng các tùy chọn.
Chọn dựa trên ngăn xếp dự án.
Mở rộng quy mô tạo dữ liệu giả cho nhu cầu doanh nghiệp
Các doanh nghiệp yêu cầu các tập dữ liệu lớn. Claude có thể tạo mã bằng cách sử dụng điện toán phân tán, như Dask.
Triển khai bộ nhớ đệm cho các lần tạo lặp lại.
Giám sát việc sử dụng tài nguyên.
Apidog mở rộng quy mô mock thông qua triển khai đám mây.
Điều này đảm bảo tính mạnh mẽ.
Các cân nhắc về bảo mật trong dữ liệu giả
Ngăn chặn rò rỉ dữ liệu bằng cách chỉ sử dụng dữ liệu tổng hợp.
Claude tuân thủ an toàn, tránh mã độc hại.
Trong Apidog, bảo mật máy chủ mock bằng xác thực. Tuân thủ GDPR đòi hỏi xử lý cẩn thận.
Kết luận
Tạo dữ liệu giả bằng mã Claude thay đổi các phương pháp phát triển. Từ những kiến thức cơ bản đến tích hợp nâng cao với Apidog, hướng dẫn này cung cấp những hiểu biết toàn diện. Hãy triển khai các kỹ thuật này để hợp lý hóa quy trình làm việc của bạn.
Hãy nhớ rằng, những điều chỉnh nhỏ trong lời nhắc hoặc thiết lập mang lại những cải tiến đáng kể. Hãy thử nghiệm và tinh chỉnh.
Để tăng cường tạo mock API, hãy tải Apidog miễn phí và khám phá các khả năng của nó.