
Các nhà phát triển liên tục tìm kiếm những cách hiệu quả để tích hợp các mô hình AI tiên tiến vào ứng dụng. API Gemini 3 Flash cung cấp một lựa chọn mạnh mẽ, cân bằng giữa trí thông minh cao với tốc độ và hiệu quả chi phí.
Google tiếp tục phát triển các sản phẩm AI tạo sinh của mình. Ngoài ra, mô hình Gemini 3 Flash nổi bật trong dòng sản phẩm hiện tại. Các kỹ sư truy cập nó thông qua API Gemini, cho phép tạo mẫu nhanh chóng và triển khai sản xuất.
Lấy Khóa API Gemini của bạn
Bạn bắt đầu bằng việc lấy một khóa API. Đầu tiên, truy cập Google AI Studio tại aistudio.google.com. Đăng nhập bằng tài khoản Google của bạn nếu cần. Tiếp theo, chọn mô hình xem trước Gemini 3 Flash từ các tùy chọn có sẵn. Sau đó, nhấp vào tùy chọn để tạo khóa API.
Google cung cấp khóa này ngay lập tức. Hơn nữa, hãy lưu trữ nó một cách an toàn—coi nó là thông tin đăng nhập nhạy cảm. Bạn sử dụng nó trong tiêu đề x-goog-api-key cho tất cả các yêu cầu. Ngoài ra, hãy đặt nó làm biến môi trường để thuận tiện trong các tập lệnh.
Nếu không có khóa hợp lệ, các yêu cầu sẽ thất bại ngay lập tức với lỗi xác thực. Do đó, hãy xác minh chức năng khóa sớm bằng cách thử nghiệm trong giao diện tương tác của Google AI Studio.
Hiểu về Các Khả năng của Gemini 3 Flash
Gemini 3 Flash cung cấp trí thông minh cấp Pro với tốc độ Flash. Cụ thể, ID mô hình vẫn là gemini-3-flash-preview trong giai đoạn xem trước. Nó hỗ trợ cửa sổ ngữ cảnh đầu vào khổng lồ 1.048.576 token và giới hạn đầu ra 65.536 token.
Hơn nữa, nó xử lý hiệu quả các đầu vào đa phương thức. Bạn cung cấp văn bản, hình ảnh, video, âm thanh và PDF. Đầu ra chủ yếu là văn bản, với các tùy chọn cho JSON có cấu trúc thông qua thực thi lược đồ.
Các tính năng chính bao gồm kiểm soát khả năng suy luận tích hợp. Các nhà phát triển điều chỉnh độ sâu suy nghĩ bằng cách sử dụng tham số thinking_level: tối thiểu (minimal), thấp (low), trung bình (medium) hoặc cao (high) (mặc định). Mức cao (High) tối đa hóa chất lượng suy luận, trong khi các mức thấp hơn ưu tiên độ trễ cho các kịch bản thông lượng cao.
Ngoài ra, hãy kiểm soát độ phân giải phương tiện cho các tác vụ thị giác. Các tùy chọn dao động từ thấp (low) đến siêu cao (ultra_high), ảnh hưởng đến mức tiêu thụ token trên mỗi khung hình hoặc hình ảnh. Hãy chọn phù hợp—cao (high) cho hình ảnh chi tiết, trung bình (medium) cho tài liệu.
Mô hình tích hợp các công cụ như làm nền bằng Google Search, thực thi mã và gọi hàm. Tuy nhiên, nó không bao gồm tạo hình ảnh và một số công cụ robot tiên tiến nhất định.
Giá của API Gemini 3 Flash
Quản lý chi phí rất quan trọng trong việc tích hợp API. Gemini 3 Flash hoạt động theo mô hình trả tiền theo mức sử dụng. Token đầu vào có giá 0,50 đô la cho mỗi triệu, trong khi token đầu ra (bao gồm cả token suy nghĩ) có giá 3 đô la cho mỗi triệu.
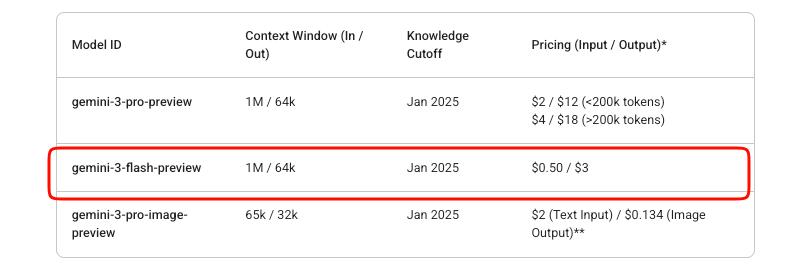
Google cung cấp thử nghiệm miễn phí trong AI Studio. Tuy nhiên, việc sử dụng API sản xuất sẽ phát sinh phí sau khi tính năng thanh toán được bật. Không có gói miễn phí nào tồn tại ngoài các bản dùng thử Studio cho mô hình xem trước này.
Bộ nhớ đệm ngữ cảnh và xử lý hàng loạt giúp tối ưu hóa chi phí hơn nữa. Bộ nhớ đệm làm giảm việc xử lý token dư thừa cho các ngữ cảnh lặp lại. API hàng loạt phù hợp với các công việc có khối lượng lớn không đồng bộ.
Giám sát mức sử dụng thông qua các bảng điều khiển Google Cloud Billing. Các đợt tăng đột biến thường xuất phát từ cài đặt media_resolution cao hoặc suy luận mở rộng.
Thực hiện Yêu cầu API đầu tiên của bạn
Bạn bắt đầu với việc tạo văn bản đơn giản. Điểm cuối là https://generativelanguage.googleapis.com/v1beta/models/gemini-3-flash-preview:generateContent.
Xây dựng một yêu cầu POST. Bao gồm khóa API của bạn trong tiêu đề. Phần thân chứa nội dung dưới dạng một mảng các đối tượng role-part.
Đây là một ví dụ cURL cơ bản:
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3-flash-preview:generateContent" \
-H "x-goog-api-key: YOUR_API_KEY" \
-H "Content-Type: application/json" \
-X POST \
-d '{
"contents": [{
"parts": [{"text": "Explain quantum entanglement briefly."}]
}]
}'
Phản hồi trả về các ứng cử viên với các phần văn bản. Ngoài ra, hãy xử lý siêu dữ liệu sử dụng để đếm token.
Đối với các phản hồi dạng streaming, hãy sử dụng điểm cuối :streamGenerateContent. Điều này tạo ra kết quả từng phần một cách tăng dần, cải thiện độ trễ cảm nhận được trong các ứng dụng.
Tích hợp với các SDK chính thức
Google duy trì các SDK giúp đơn giản hóa tương tác. Cài đặt gói Python thông qua pip install google-generativeai.
import google.generativeai as genai
genai.configure(api_key="YOUR_API_KEY")
model = genai.GenerativeModel("gemini-3-flash-preview")
response = model.generate_content("Summarize recent AI advancements.")
print(response.text)
SDK tự động quản lý chữ ký suy nghĩ cho các cuộc trò chuyện đa lượt và sử dụng công cụ. Do đó, nên ưu tiên sử dụng SDK hơn là HTTP thô cho mã sản xuất.
Người dùng Node.js truy cập sự tiện lợi tương tự thông qua @google/generative-ai.
Xử lý Đầu vào Đa phương thức
Gemini 3 Flash vượt trội trong việc xử lý đa phương thức. Tải lên tệp hoặc cung cấp URI dữ liệu nội tuyến.
model = genai.GenerativeModel("gemini-3-flash-preview")
image = genai.upload_file("diagram.png")
response = model.generate_content(["Describe this image in detail.", image])
print(response.text)
Điều chỉnh media_resolution trong cấu hình tạo để tối ưu hóa token:
generation_config = {
"media_resolution": "media_resolution_high"
}
Video và PDF tuân theo các mẫu tương tự. Hơn nữa, hãy kết hợp nhiều phương thức trong một yêu cầu cho các tác vụ phân tích phức tạp.
Tính năng Nâng cao: Mức độ Suy nghĩ và Công cụ
Kiểm soát suy luận một cách rõ ràng. Đặt thinking_level thành "low" để có phản hồi nhanh:
"generationConfig": {
"thinking_level": "low"
}
Mức độ suy nghĩ cao cho phép xử lý chuỗi suy nghĩ sâu hơn bên trong.
Bật các công cụ như gọi hàm. Định nghĩa các hàm trong yêu cầu; mô hình sẽ trả về các lệnh gọi khi thích hợp.
Đầu ra có cấu trúc thực thi các lược đồ JSON:
"generationConfig": {
"response_mime_type": "application/json",
"response_schema": {...}
}
Kết hợp những điều này cho các quy trình làm việc theo tác nhân. Ví dụ, làm nền cho các phản hồi bằng tìm kiếm thời gian thực.
Kiểm thử và Gỡ lỗi với Apidog
Kiểm thử hiệu quả đảm bảo các tích hợp đáng tin cậy. Apidog nổi lên như một công cụ mạnh mẽ cho mục đích này. Nó kết hợp thiết kế API, gỡ lỗi, giả lập (mocking) và kiểm thử tự động trong một nền tảng duy nhất.
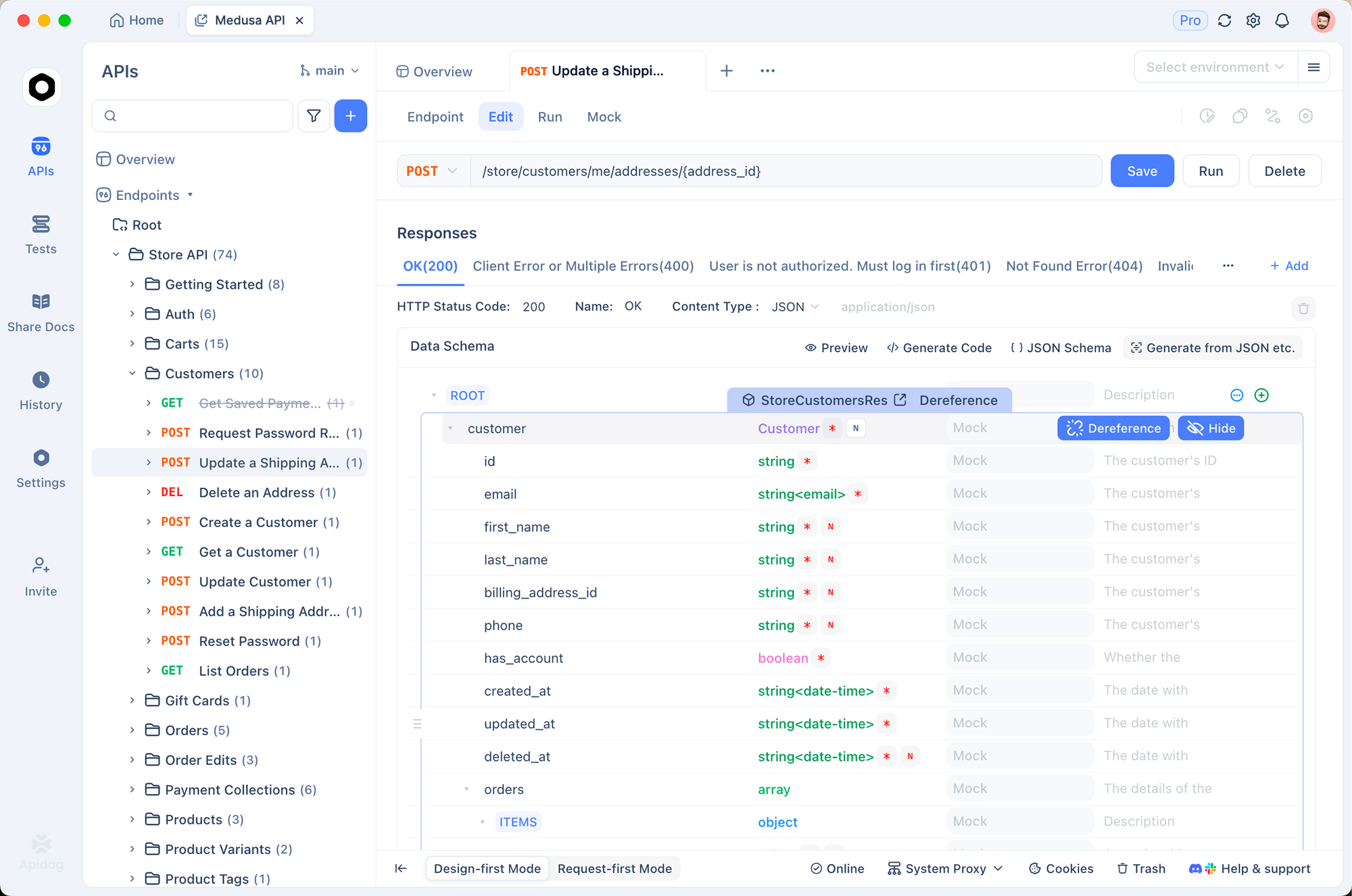
Đầu tiên, nhập điểm cuối Gemini vào Apidog. Tạo một yêu cầu mới trỏ đến phương thức generateContent. Lưu trữ khóa API của bạn dưới dạng biến môi trường—Apidog hỗ trợ nhiều môi trường cho dev, staging và prod.
Gửi yêu cầu trực quan. Apidog hiển thị phản hồi rõ ràng, làm nổi bật việc sử dụng token và các lỗi. Ngoài ra, hãy thiết lập các xác nhận để tự động xác thực cấu trúc phản hồi.
Đối với các cuộc trò chuyện đa lượt, duy trì lịch sử cuộc trò chuyện trên các yêu cầu bằng cách sử dụng tập lệnh hoặc biến của Apidog. Điều này mô phỏng các phiên người dùng thực một cách hiệu quả.
Apidog cũng tạo ra các máy chủ giả lập. Mô phỏng phản hồi Gemini trong quá trình phát triển frontend mà không tiêu tốn hạn mức.
Hơn nữa, tự động hóa các bộ kiểm thử. Định nghĩa các kịch bản bao gồm các mức độ suy nghĩ khác nhau, đầu vào đa phương thức và các trường hợp lỗi. Chạy chúng trong các quy trình CI/CD.
Nhiều nhà phát triển thấy Apidog giảm đáng kể thời gian gỡ lỗi so với cURL thô hoặc các client cơ bản. Giao diện trực quan của nó xử lý các phần thân JSON phức tạp một cách dễ dàng.
Các Thực hành Tốt nhất cho Sử dụng trong Sản xuất
Thực hiện logic thử lại với tạm dừng theo cấp số nhân (exponential backoff). Giới hạn tốc độ áp dụng, đặc biệt trong giai đoạn xem trước.
Lưu trữ ngữ cảnh vào bộ nhớ đệm nếu có thể để giảm thiểu token. Sử dụng chữ ký suy nghĩ một cách chính xác trong các yêu cầu thô để tránh lỗi xác thực.
Giám sát chi phí chủ động. Ghi lại số lượng token đầu vào/đầu ra trên mỗi yêu cầu.
Giữ nhiệt độ ở mức mặc định 1.0—các sai lệch làm giảm hiệu suất suy luận.
Cuối cùng, hãy cập nhật thông qua tài liệu chính thức. Các mô hình xem trước có thể phát triển; hãy lập kế hoạch cho những thay đổi đột phá tiềm ẩn.
Kết luận
Bây giờ bạn đã có kiến thức để tích hợp Gemini 3 Flash một cách hiệu quả. Bắt đầu với các yêu cầu đơn giản, sau đó mở rộng sang các ứng dụng đa phương thức và tăng cường công cụ. Tận dụng các công cụ như Apidog để hợp lý hóa quy trình làm việc phát triển.
Gemini 3 Flash trao quyền cho các nhà phát triển tạo ra các hệ thống thông minh, phản hồi nhanh với chi phí phải chăng. Hãy thử nghiệm tự do trong AI Studio, sau đó chuyển sang API để triển khai.