
Hãy tưởng tượng bạn có khả năng trích xuất dữ liệu từ bất kỳ trang web nào và thu thập thông tin ở quy mô lớn - tất cả chỉ với vài dòng mã. Nghe có vẻ như phép thuật, đúng không? Vâng, Firecrawl biến điều này thành hiện thực.
Trong hướng dẫn dành cho người mới bắt đầu này, tôi sẽ hướng dẫn bạn mọi điều bạn cần biết về Firecrawl, từ cài đặt đến các kỹ thuật trích xuất dữ liệu nâng cao. Dù bạn là một nhà phát triển, nhà phân tích dữ liệu, hay chỉ đơn giản là tò mò về việc trích xuất dữ liệu từ web, hướng dẫn này sẽ giúp bạn bắt đầu với Firecrawl và tích hợp nó vào quy trình làm việc của bạn.

Firecrawl là gì?
Firecrawl là một công cụ trích xuất dữ liệu và thu thập web sáng tạo, chuyển đổi nội dung trang web thành các định dạng như markdown, HTML, và dữ liệu có cấu trúc. Điều này làm cho nó trở thành lựa chọn lý tưởng cho Mô Hình Ngôn Ngữ Lớn (LLMs) và các ứng dụng AI. Với Firecrawl, bạn có thể thu thập hiệu quả cả dữ liệu có cấu trúc và không có cấu trúc từ các trang web, đơn giản hóa quy trình phân tích dữ liệu của bạn.
Các Tính Năng Nổi Bật của Firecrawl
Crawl: Thu Thập Web Toàn Diện
Điểm cuối /crawl của Firecrawl cho phép bạn duyệt qua một trang web một cách đệ quy, trích xuất nội dung từ tất cả các trang phụ. Tính năng này rất phù hợp để khám phá và tổ chức một lượng lớn dữ liệu web, chuyển đổi nó thành các định dạng sẵn sàng cho LLM.
Scrape: Trích Xuất Dữ Liệu Đặc Thù
Sử dụng tính năng Scrape để trích xuất dữ liệu cụ thể từ một URL duy nhất. Firecrawl có thể cung cấp nội dung dưới nhiều định dạng khác nhau, bao gồm markdown, dữ liệu có cấu trúc, ảnh chụp màn hình và HTML. Điều này đặc biệt hữu ích cho việc trích xuất thông tin cụ thể từ các URL đã biết.
Map: Lập Bản Đồ Trang Web Nhanh Chóng
Tính năng Map nhanh chóng lấy tất cả các URL liên quan đến một trang web nhất định, cung cấp cái nhìn tổng quát về cấu trúc của nó. Điều này vô giá cho việc khám phá và tổ chức nội dung.
Extract: Chuyển Đổi Dữ Liệu Không Có Cấu Trúc Thành Định Dạng Có Cấu Trúc
Điểm cuối /extract là tính năng sử dụng AI của Firecrawl giúp đơn giản hóa quá trình thu thập dữ liệu có cấu trúc từ các trang web. Nó xử lý việc thu thập, phân tích và tổ chức dữ liệu thành định dạng có cấu trúc.
Bắt Đầu Với Firecrawl
Bước 1: Đăng Ký và Nhận API Key của Bạn
Truy cập trang web chính thức của Firecrawl và đăng ký tài khoản. Sau khi đăng nhập, hãy điều hướng đến bảng điều khiển của bạn để tìm API key của bạn.
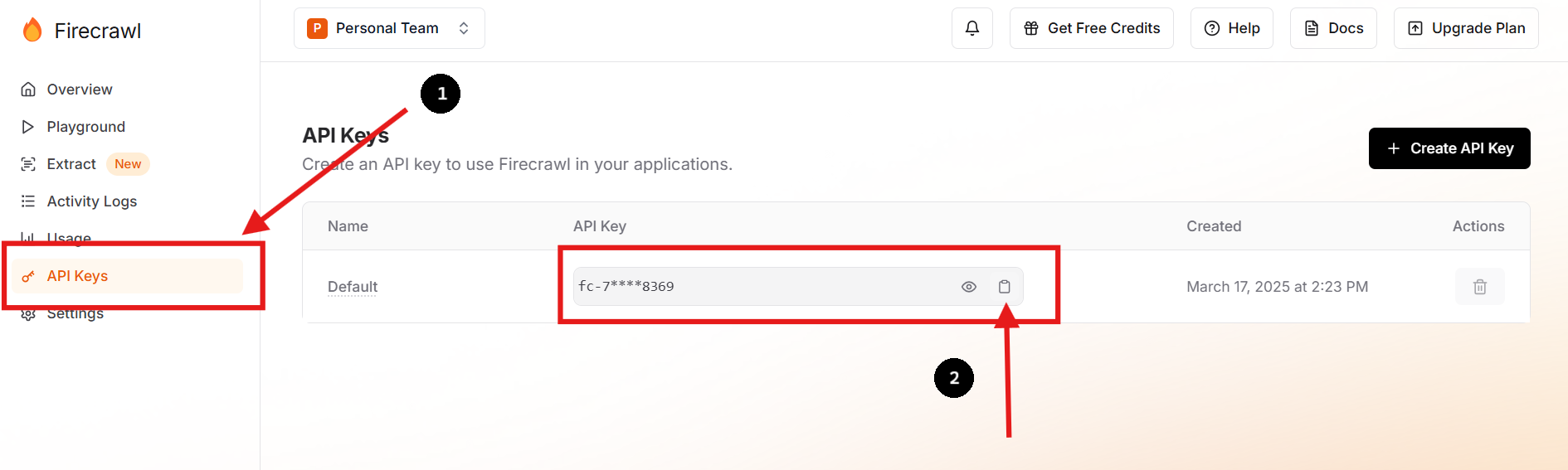
Bạn cũng có thể tạo một API key mới và xóa cái trước nếu bạn muốn hoặc cần làm điều đó.

Bước 2: Thiết Lập Môi Trường của Bạn
Trong thư mục dự án của bạn, tạo một tệp .env để lưu trữ API key của bạn một cách an toàn dưới dạng biến môi trường. Bạn có thể thực hiện điều này bằng cách chạy các lệnh sau trong terminal của bạn:
touch .env
echo "FIRECRAWL_API_KEY='fc-YOUR-KEY-HERE'" >> .envCách tiếp cận này giúp bảo vệ thông tin nhạy cảm ra khỏi mã nguồn chính, tăng cường bảo mật và đơn giản hóa việc quản lý cấu hình.
Bước 3: Cài Đặt Firecrawl SDK
Đối với người dùng Python, cài đặt Firecrawl SDK bằng cách sử dụng pip:
pip install firecrawl Bước 4: Sử Dụng Tính Năng "Scrape" Của Firecrawl
Dưới đây là một ví dụ đơn giản về cách trích xuất dữ liệu từ một trang web bằng Firecrawl SDK:
from firecrawl import FirecrawlApp
from dotenv import load_dotenv
import os
# Tải các biến môi trường từ tệp .env
load_dotenv()
# Khởi tạo FirecrawlApp với API key từ .env
app = FirecrawlApp(api_key=os.getenv("FIRECRAWL_API_KEY"))
# Định nghĩa URL để trích xuất
url = "https://www.python-unlimited.com/webscraping/hotels.php?page=1"
# Trích xuất dữ liệu từ trang web
response = app.scrape_url(url)
# In phản hồi
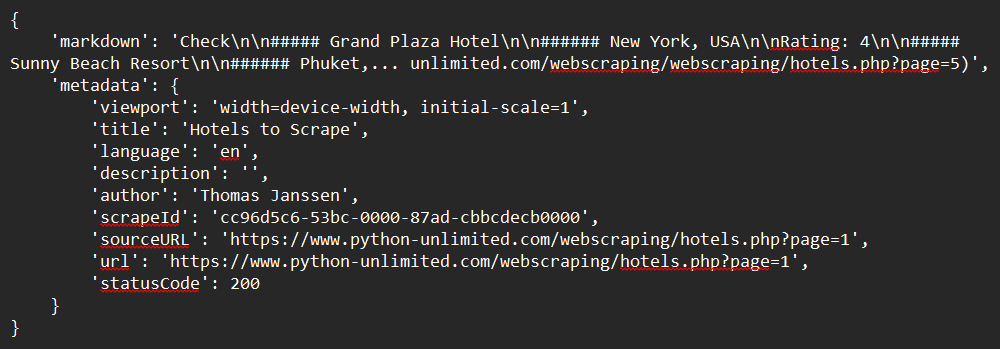
print(response)Kết quả mẫu:
Bước 5: Sử Dụng Tính Năng "Crawl" Của Firecrawl
Ở đây chúng ta sẽ xem một ví dụ đơn giản về cách thu thập dữ liệu từ một trang web bằng Firecrawl SDK:
from firecrawl import FirecrawlApp
from dotenv import load_dotenv
import os
# Tải các biến môi trường từ tệp .env
load_dotenv()
# Khởi tạo FirecrawlApp với API key từ .env
app = FirecrawlApp(api_key=os.getenv("FIRECRAWL_API_KEY"))
# Thu thập dữ liệu từ một trang web và ghi lại phản hồi:
crawl_status = app.crawl_url(
'https://www.python-unlimited.com/webscraping/hotels.php?page=1',
params={
'limit': 100,
'scrapeOptions': {'formats': ['markdown', 'html']}
},
poll_interval=30
)
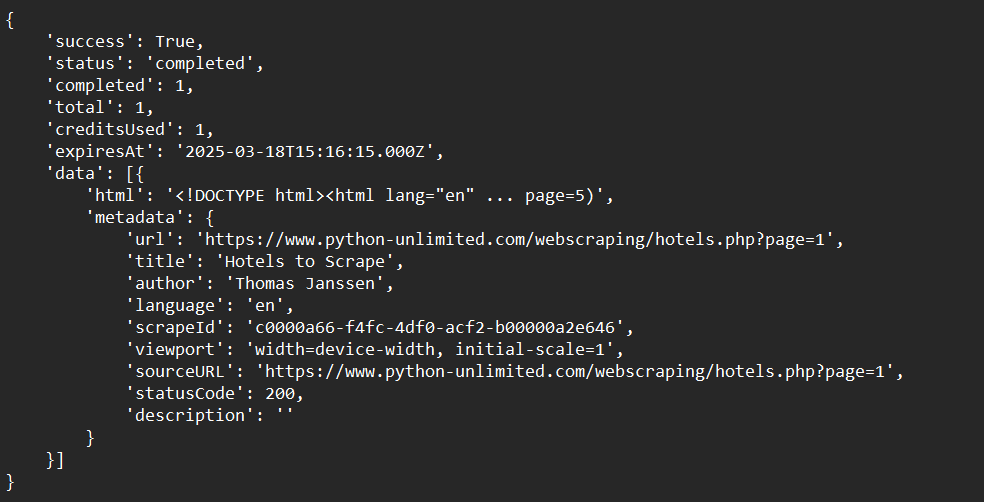
print(crawl_status)Kết quả mẫu:
Bước 6: Sử Dụng Tính Năng "Map" Của Firecrawl
Dưới đây là một ví dụ đơn giản về cách lập bản đồ dữ liệu trang web bằng Firecrawl SDK:
from firecrawl import FirecrawlApp
from dotenv import load_dotenv
import os
# Tải các biến môi trường từ tệp .env
load_dotenv()
# Khởi tạo FirecrawlApp với API key từ .env
app = FirecrawlApp(api_key=os.getenv("FIRECRAWL_API_KEY"))
# Lập bản đồ một trang web:
map_result = app.map_url('https://www.python-unlimited.com/webscraping/hotels.php?page=1')
print(map_result)Kết quả mẫu:

Bước 7: Sử Dụng Tính Năng "Extract" Của Firecrawl (Beta Mở)
Dưới đây là một ví dụ đơn giản về cách trích xuất dữ liệu trang web bằng Firecrawl SDK:
from firecrawl import FirecrawlApp
from pydantic import BaseModel, Field
from dotenv import load_dotenv
import os
# Tải các biến môi trường từ tệp .env
load_dotenv()
# Khởi tạo FirecrawlApp với API key từ .env
app = FirecrawlApp(api_key=os.getenv("FIRECRAWL_API_KEY"))
# Định nghĩa schema để trích xuất nội dung vào
class ExtractSchema(BaseModel):
company_mission: str
supports_sso: bool
is_open_source: bool
is_in_yc: bool
# Gọi hàm trích xuất và ghi lại phản hồi
response = app.extract([
'https://docs.firecrawl.dev/*',
'https://firecrawl.dev/',
'https://www.ycombinator.com/companies/'
], {
'prompt': "Trích xuất dữ liệu được cung cấp trong schema.",
'schema': ExtractSchema.model_json_schema()
})
# In phản hồi
print(response)Kết quả mẫu:
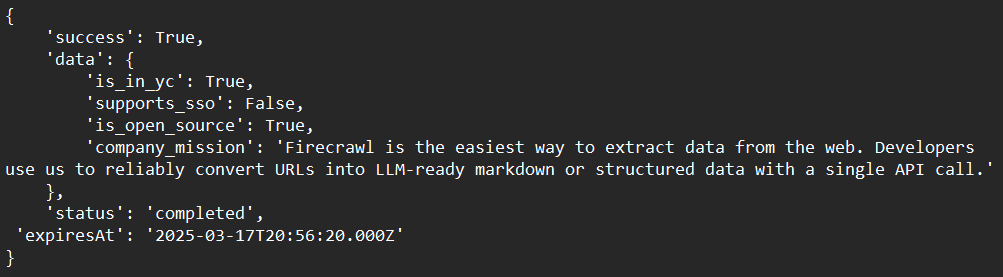
Các Kỹ Thuật Nâng Cao Với Firecrawl
Xử Lý Nội Dung Động
Firecrawl có thể xử lý nội dung động dựa trên JavaScript bằng cách sử dụng trình duyệt không đầu để render các trang trước khi trích xuất. Điều này đảm bảo bạn thu thập tất cả nội dung, ngay cả khi nó được tải động.
Vượt Qua Các Chướng Ngại Khi Trích Xuất Dữ Liệu Web
Sử dụng các tính năng tích hợp sẵn của Firecrawl để vượt qua các chướng ngại trích xuất dữ liệu web phổ biến, chẳng hạn như CAPTCHAs hoặc giới hạn tốc độ. Điều này liên quan đến việc xoay vòng các tác nhân người dùng và địa chỉ IP để mô phỏng lưu lượng tự nhiên.
Tích Hợp Với Các LLMs
Kết hợp Firecrawl với các LLMs như LangChain để xây dựng các quy trình AI mạnh mẽ. Ví dụ, bạn có thể sử dụng Firecrawl để thu thập dữ liệu và sau đó đưa vào một LLM cho các tác vụ phân tích hoặc tạo nội dung.
Khắc Phục Các Vấn Đề Thường Gặp
Vấn đề: "API Key Không Được Nhận Diện"
Giải pháp: Đảm bảo rằng API key của bạn được lưu trữ đúng cách dưới dạng biến môi trường hoặc trong tệp .env.
Vấn đề: "Thu Thập Quá Chậm"
Giải pháp: Sử dụng thu thập không đồng bộ để tăng tốc quá trình. Firecrawl hỗ trợ các yêu cầu đồng thời để cải thiện hiệu quả.
Vấn đề: "Nội Dung Không Được Trích Xuất Đúng Cách"
Giải pháp: Kiểm tra xem trang web có sử dụng nội dung động hay không. Nếu có, hãy đảm bảo Firecrawl được cấu hình để xử lý việc render JavaScript.
Kết Luận
Chúc mừng bạn đã hoàn thành hướng dẫn dành cho người mới bắt đầu này về Firecrawl! Chúng ta đã đề cập đến mọi điều bạn cần để bắt đầu - từ việc Firecrawl là gì, đến các hướng dẫn cài đặt chi tiết, ví dụ sử dụng và các tùy chọn tùy chỉnh nâng cao. Đến lúc này, bạn nên có một hiểu biết rõ ràng về cách:
- Thiết lập và cài đặt Firecrawl trong môi trường phát triển của bạn.
- Cấu hình và chạy Firecrawl để trích xuất, thu thập, lập bản đồ và truy xuất dữ liệu hiệu quả.
- Khắc phục sự cố cho các quy trình thu thập của bạn để đáp ứng các nhu cầu cụ thể của bạn.
Firecrawl là một công cụ vô cùng mạnh mẽ có thể đơn giản hóa đáng kể các quy trình trích xuất dữ liệu của bạn. Tính linh hoạt, hiệu quả và độ dễ dàng trong việc tích hợp của nó làm cho nó trở thành lựa chọn lý tưởng cho các thách thức thu thập web hiện đại.
Bây giờ đã đến lúc áp dụng các kỹ năng mới của bạn vào thực tiễn. Hãy bắt đầu thử nghiệm với các trang web khác nhau, điều chỉnh các parser của bạn và tích hợp với các công cụ bổ sung để tạo ra một giải pháp thực sự tùy chỉnh đáp ứng các yêu cầu độc đáo của bạn.
Bạn đã sẵn sàng để 10x quy trình trích xuất dữ liệu web của mình chưa? Tải xuống Apidog miễn phí hôm nay và khám phá cách nó có thể nâng cao tích hợp Firecrawl của bạn!